[paper-review] Generative adversarial networks with mixture of t-distributions noise for diverse image generation
Paper Review
Sun, Jinxuan, et al. "Generative adversarial networks with mixture of t-distributions noise for diverse image generation." Neural Networks 122 (2020): 374-381.
Abstract
큰 이미지 생성을 위한 t-GANs라는 새로운 모델의 제안
- t-GANs의 잠재(latent) 생성공간은 t분포의 조합이 사용된다.
- 생성된 이미지의 다양성을 향상시키기 위해, 각각 노이즈 벡터와 "class codewords"가 t-GANs의 Generator의 입력에 연결된다.
- Discriminator의 "classification loss"가 Generator와 Discriminator의 성능 향상을 위해 두 모델에 전달된다.
- t-GANs와 함께 pixelCNN 및 GAN-based 모델들을 비교, 분석했다.
실험적 결과는 t-GANs이 눈에 띄게 pixelCNN이나 GAN-based 모델들에 비해 다양한 이미지 생성에 좋은 모습을 보였다.
1. Introduction
이미지 생성에 관한 연구는 50년도 전에도 이루어져왔다. 지금까지 이미지 생성의 방법론은 크게 두 가지로 나눌 수 있다.
- 이미지를 픽셀마다 하나씩 하나씩 생성하는 방법.
- 픽셀 단위로 하나씩 생성하는 방법은 근본적으로 심층 신경망에 기반함.
- 픽셀을 하나씩 생성하기 때문에, 시간적 소요가 크다.
- 잠재 공간을 나타내는 통계적 확률을 이용해 전체 이미지를 생성하는 방법.
- 암묵적인 이미지의 잠재분포를 추정해야함.
- 이 방법은 대표적으로 GAN이 이끌고 있다.
- 하지만 GAN은 쉽게 mode collapse에 빠지는 문제를 가지고 있으며, 생성된 이미지가 다양하지 않게 생성되는 문제를 초래하게 된다.
- 무엇보다 GAN은 모델의 안정성을 위해 많은 양의 학습 데이터를 필요로 한다.
- DCGAN, ACGAN, DeLiGAN등의 GAN의 파생 모델이 제안되었지만, 이들은 모델의 다양성을 반영하지 못했다.
model architecture
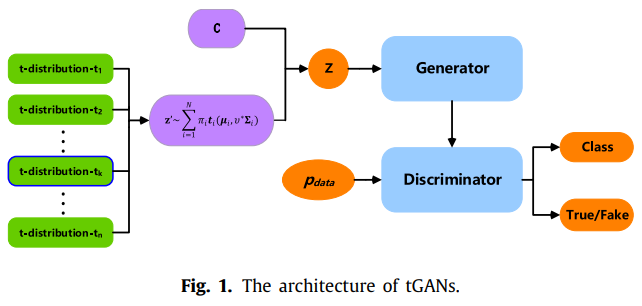
- 본 논문에서 다양한 이미지의 생성을 위해 t-GANs을 제안한다. 이 때, t-GANs의 노이즈 벡터는 생성 이미지의 다양성을 향상시킬 수 있도록 t분포의 조합으로 사용했다.
- 각 class에서의 생성된 이미지를 다양하게 할 수 있는 "class codewords"는 Generator의 입력에 연결되었다(Concatenated).
- 추가적으로 "classification loss"를 추가해 Generator와 Discriminator의 성능 향상을 도모했다.
motivations
- 머신러닝 분야에서 t분포를 사용한 많은 모델들이 일반적으로 가우시안 분포를 사용한 모델들에 비해 좀 더 나은 결과를 보였다.
- 실험적으로 나타난 모델의 성능과 t분포가 가지고 있는 분포의 꼬리가 길다는 특성에서 영감을 얻을 수 있었다.
results
"inception score"는 생성된 이미지의 퀄리티를 측정할 때 널리 사용되는 척도이다.
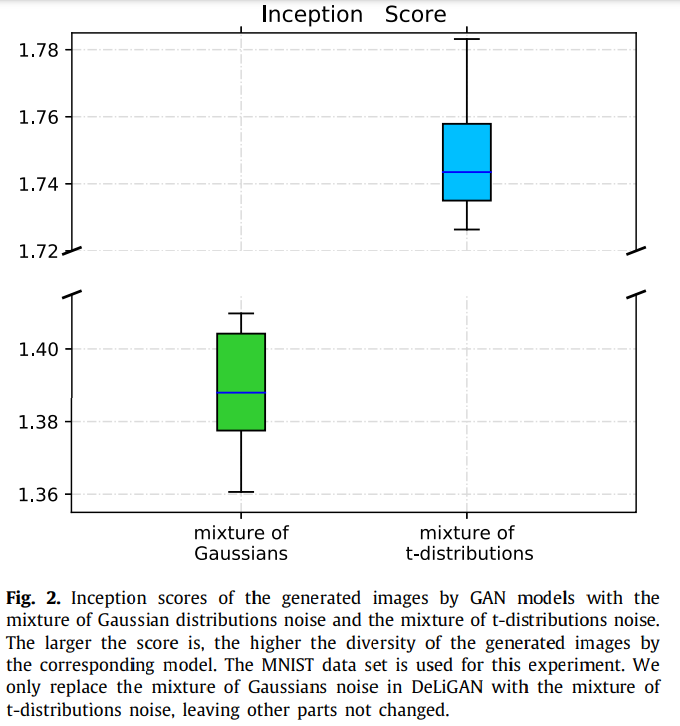
t분포의 조합을 노이즈로 사용한 모델에서 inception score가 높은 경향을 볼 수 있다.
따라서 이미지의 다양성 측면에서 t-GANs이 우수하다고 볼 수 있다.
2. Related work
2.1. Pixel by pixel approaches for image generation
대부분 예전의 이미지 생성 방식은 픽셀 단위로 생성하고 예측하는 방식을 기반하고 있음. 그러나 이 방식은 픽셀과 픽셀 간의 연관성을 전혀 반영하지 못했다.
최근 심층 신경망의 발전으로 pixelCNN, pixelRNN과 같은 전체 픽셀간의 상호 관계를 반영하는 픽셀 단위 생성모델이 발전하게 되었다.
이러한 방법은 많은 학습 시간이 필요하며 생성된 이미지의 퀄리티 역시 떨어진다.
2.2. GAN-based models for image generation
최초의 GAN이 만든 이미지는 조악하고, 알아보기 힘드며, mode collapse에 쉽게 빠져버린다.
이를 해결하기 위한 GAN의 여러 확장판들이 제안되었다.
- DCGAN, GAN의 생성 퀄리티의 향상, 학습의 안정을 위한 convolutional 신경망을 GAN에 조합했다. 많은 학습 데이터를 필요로 한다.
- ACGAN, 생성된 이미지의 레이블 일관성을 위해 보조 분류기(auxiliary classifier)를 붙혔다.
- DeLiGAN 및 Gaussian mixture GAN, 가우시안 분포의 조합을 잠재 노이즈 공간으로 했으며, 이미지의 다양성을 향상하는데 목표를 두었다.
3. GANs with mixture of t-distributions noise (t-GANs)
3.1. Mixture of t-distributions noise for diverse image generation
t분포의 조합으로 노이즈 벡터를 샘플링하는 것을 제안한다. 다 변량 t분포의 확률 밀도 함수는 다음과 같이 정의할 수 있다.
a mixture of t-distribution에서 노이즈 벡터를 얻어내기 위해 먼저 임의의 t분포를 하나 선택하고 그 t분포에서 차원의 벡터를 샘플링한다.
최종적으로 얻을 수 있는 잠재 노이즈 분포 는 다음과 같이 할 수 있다.
Fig 2.에서 t분포의 사용이 다양성의 측면에서 더 나은 모습을 볼 수 있다.
3.2. Class codewords of each class
생성된 이미지의 다양성을 위해 class codeword를 각 노이즈 벡터에 연결했다.
번째 클래스를 위한 class codeword를 다음과 같은 차원의 벡터 라고 하면, 이 는 평균 이고 표준편차 인 가우시안 분포에서 샘플링된다.
이렇게 사용된 class codeword는 각 클래스에서 생성된 이미지의 다양성을 증대 시킨다.
최종 Generator에는 노이즈 벡터 와 가 결합되어 사용된다: .
따라서 각각 손실함수는 다음과 같이 정의할 수 있다.
3.3. Classification loss on the generator and discriminator
클래스 정보를 담고 있는 code classword를 입력에 추가했기 때문에, tGANs의 분류기에 보조 분류기 를 추가 할 수 있다.
이 보조 분류기는 feature extraction layer 뒤쪽에 위치하여, 계산 부담을 덜어줄 것이다.
의 손실함수는 다음과 같다.
는 입력에서 붙여주었던 class codeword가 의도한 클래스의 분포를 제대로 생성하고 있는지 검사하는 역할을 수행하게 된다.
이 를 Generator, Discriminator의 손실함수에 더해주어 는 최소화하고, 는 최대화하도록 최적화했다.
는 trade-off factor.
보조 분류기의 추가 정보는 Generator와 Discriminator에 추가적인 정보를 제공하여 다양한 이미지 생성에 대한 성능을 끌어올릴 수 있었다.
4. Experiments
Dataset
- MNIST
- Fashion MNIST
- CIFAR-10
Metrics
- inception score,
- , 생성된 이미지
- , 가 각 클래스에 속할 확률을 반환하는 분류기의 예측 벡터 값
- , 생성된 이미지가 클래스 에 속할 확률, 가 낮은 엔트로피를 가질 수록 서로 다른 클래스들 간에 다양한 분포를 나타낸다.
- , 클래스 의 사전 확률, 가 높은 엔트로피를 가질 수록 생성된 이미지의 클래스를 잘 분류하지 못한다는 의미
- 와 의 엔트로피 차이를 척도로 하는 방법
- modified inception score,
- , 클래스 에 속하는 샘플 하나
- , inception model을 통과한 output
두 inception score는 이미지의 다양성을 중점으로 할 수 있는 평가 척도이다.
4.1. Comparison with pixelCNN

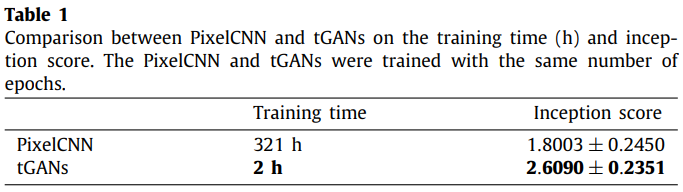
t-GANs이 훨씬 더 낮은 학습 시간을 가지고 있음에도 훨씬 더 높은 inception score를 기록했다.
4.2. Experimental results obtained on the MNIST dataset


모든 모델들이 동일한 횟수로 학습했지만, 학습데이터의 양을 다르게 하였다.
- ACGAN, DCGAN: 모든 데이터셋
- GAN, DeLiGAN, tGANs: 500여 장
ACGAN과 DCGAN이 비교적 적은 데이터셋에 대해 충분히 학습이 이루어지지 않기 때문이다.
4.3. Experimental results obtained on the fashion MNIST dataset
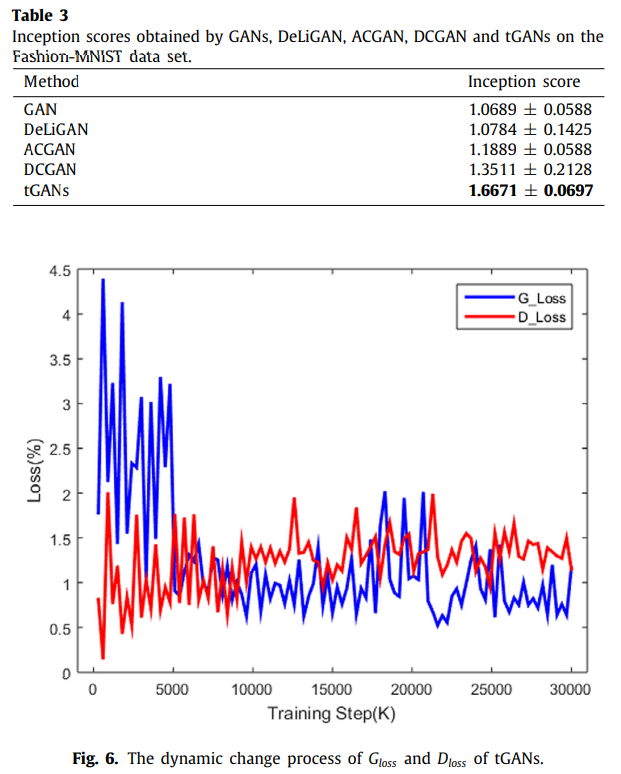
tGANs의 와 는 모두 대략 에 수렴하는 모습을 보였다.
특히 Generator는 약 7500회 정도부터 수렴되는 모습을 볼 수 있으며, 이는 GAN기반의 모델들이 일반적으로 1000~10000회의 학습 횟수를 가지는 것으로 보아, 이 최적화에 이르는 학습 횟수는 비교적 빠르다고 할 수 있다.
4.4. Experimental results obtained on the CIFAR-10 data set
GAN의 이미지 퀄리티는 매우 낮았기 때문에 결과를 비교하지 않았다.

tGANs이 비교적 다양한 클래스에서 좋은 modified inception score를 받았다.
5. Conclusion
- tGANs이라 불리는 새로운 모델의 제안.
- 모델의 입력으로 사용되는 노이즈 벡터에 클래스를 의미하는 "class codeword"를 결합해 같은 클래스 내에서의 이미지 다양성을 향상시킴.
- Generator와 Discriminator에 추가한 "classification loss"는 성능 향상에 도움을 주었음.
