[paper-review] Sequence-to-Sequence Domain Adaptation Network for Robust Text Image Recognition
Paper Review
Zhang, Yaping, et al. "Sequence-to-sequence domain adaptation network for robust text image recognition." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
Abstract
기존 Domain Adatation 문제에서 Visual 데이터 영역에 대한 발전은 이미지를 전체적으로(global) 바라보는 방향으로 발전해왔으며, 다양한 문자의 형태에 대한 sequential한 텍스트 이미지 분야에는 맞지 않는 방향이었다.
- Sequence-to-Sequence domain adaptation network (SSDAN)의 제안.
- Gated Attention Similarity (GAS) unit을 도입하여 이미지 전체에 대한 분석보다 character-level의 특징 공간을 "집중(attend)"하는 모델을 구현.
1. Introduction

그림 1 처럼 다양한 형태의 텍스트 분포에 강건한(robust) 텍스트 인식 모델을 설계하는 것은 어려운 문제이다.
이러한 문제점을 대응하기 위한 labeled data의 수집은 비용적/시간적으로 어려운 일이다.
Domain adaptation을 통해 이를 완화하는 것이 가장 효과적인 방법이지만, 기존 domain adaptation 방법들은 전역적인(global) 특징 표현에만 국한되어 왔다.
텍스트 이미지는 일정한 크기를 가지는 것이 아닌 텍스트 길이에 따라 가변적인 시퀀스 데이터이기 때문에 이에 적용하는 것에는 무리가 있다.
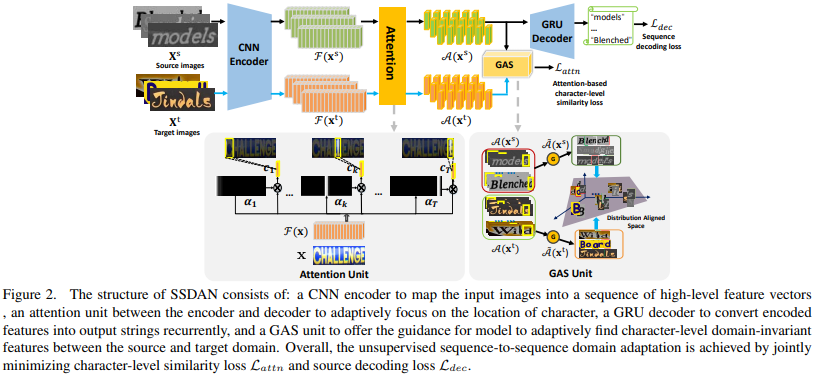
Sequence-to-Sequence domain adaptation network (SSDAN)
- 시퀀스 데이터를 처리하기 위한 어텐션(attention) 기반의 encoder-decoder 모델.
- Gated Attention Similarity (GAS) unit을 도입하여 각 문자마다(character-level)의 특징 유사도를 계산.
- GAS unit을 통해 원본(source) 도메인과 목표(target) 도메인에 공통적으로 포함되고, 도메인에 변화하지 않는(domain-invariant) 특징들을 학습할 수 있음.
2. Related Work
Text Recognition Methods. 딥 러닝 방법을 통해 이미지에서 텍스트를 인식하는 문제를 상당부분 발전했지만 그 범위가 제한적이고 다양한 데이터를 다룰 수 있는 강건한 모델을 설계하지는 못했다.
이전의 텍스트 인식 모델들은 촬영 방향에 따른 공간적인 왜곡(affine distortion)에 대한 대응만이 연구되어왔다.
Domain Adaptation for Text Recognition. 시각(Visual) 도메인에 대한 Domain Adaptation을 위한 연구가 많이 진행되어왔다. 그러나 이러한 연구들은 이미지를 전역적으로(globally) 다루기 때문에 각 문자들이 지역적으로(locally) 나열되어있는(sequentially) 텍스트 이미지에 대한 적용은 어렵다.
3. Proposed Method
본 모델을 적용할 수 있는 데이터셋의 정의는 다음과 같다.
- 소스 도메인(source domain)
- 공간 에서 로 정의되며, 레이블을 로 가지는 데이터셋
- 에 대해, 로 정의되며, 각 는 텍스트 문자(character) 레이블이며, 는 텍스트의 길이이다.
- 타겟 도메인(target domain)
- 공간 에서 로 정의되며, 레이블이 없는 데이터셋
소스 도메인으로 모델을 학습시키고 레이블이 없어 학습할 수 없는 타겟 도메인에도 적용하고자 함.
3.1 Attentive Text Recognition
Attentive text recognition은 시퀀스 텍스트 이미지 에서 인코딩된 일련의 특징 맵(feature maps)과 그의 레이블 를 짝짓는 과정(mapping)이다.
Attentive text recognition의 구성은 아래와 같다.
- 하나의 CNN encoder가 입력 이미지의 시각적 표현을 encode한다.
- encoder와 decoder 사이에 어텐션 모델은 앞에서 인코딩된 특징 시퀀스의 "attention"할 부분을 학습한다.
- GRU decoder가 각 스텝을 거치며 결과 값(character symbol)을 하나씩 생성해낸다.
CNN Encoder. CNN encoder 는 입력 이미지 (를 크기로 가짐)를 소스 도메인이나 타겟 도메인으로부터 받아, 크기의 특징 맵을 계산한다.
이 특징 맵은 다시 개로 쪼개진다.() 결과적으로 입력 이미지는 CNN encoder를 거쳐 아래와 같이 재구성된다.
Attention. CNN encoder가 공간정보를 살펴볼 수 있다고 해도, 그 텍스트 이미지의 특정 문자의 특정 위치를 정확하게 결정할 수 없다. 여기서 어텐션 모델이 도입되어 텍스트 이미지의 어떤 부분이 디코딩될 문자(character)와 연관이 있는지 살핀다.
그림 2에서 나타나는 것처럼, 어텐션은 전체 -step 중 번째 step에서 의 레이블 와 가장 연관 있다고 할 때, context vector 는 아래와 같이 정의된다.
어텐션 가중치(attention weight) 는 아래와 같이 계산된다.
attention score 는 텍스트 이미지의 번째 문자를 예측할 때 "attention"할 영역이 중 번째 sub-region일 확률을 나타낸다. 이 때 attention score는 과거 연구의 실험적인 결과에 따라 아래와 같이했다.
GRU Decoder. GRU decoder는 입력 이미지를 통해 문자열을 예측하는데 사용되며, Gated Recurrent unit (GRU) 신경망을 사용했다. GRU는 context vector , 이전 상태(state) , 이전 단계의 예측 character 을 사용해 새로운 번째 hidden state를 만든다.
이 다음 현재 예측할 character symbol 는 아래와 같이 계산된다.
는 softmax 활성화함수(activation function)를 나타낸다.
- : mapping matrices, 학습을 통해 가중치가 수정된다.
- : embedding matrix
- : character label 의 one-hot vector
마지막으로 전체 문자열 시퀀스 레이블 의 확률 값은 아래와 같이 각 label의 곱으로 나타난다.
는 입력 텍스트 이미지 에 대한 attended character-level 특징 맵으로 생각할 수 있다.
3.2. Gated Attention Similarity Unit
위에서도 언급했듯이 텍스트 이미지는 길이가 다양하게 주어지기 때문에 전역적인 이미지 판단으로는 텍스트 인식을 할 수 없다.
여기에 Gated Attention Similarity (GAS) unit을 도입해 길이가 다양하게 변하는 텍스트 이미지를 문자 수준(character-level)의 features로 분해할 것이다.
이를 통해 소스 도메인과 타겟 도메인은 character-level에서 같은 레이블 공간을 공유할 것이다. 그림 2의 아래 이미지로 이해를 도울 수 있다.
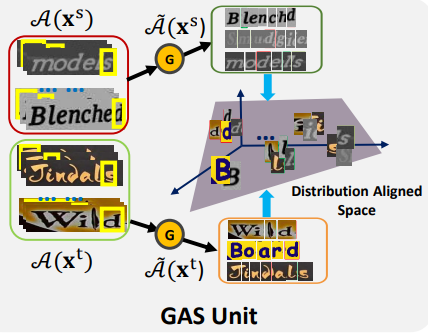
동일한 알파벳은 도메인에 관계없이 동일한 feature 공간을 공유하는 것을 볼 수 있다.
attention 매커니즘에서 올바른 sub-region을 "attend"하지 않을 경우를 대비하여 gate 메커니즘을 도입해 올바른 attention context vector를 선택한다.
임계값 와 함께 adaption gate 함수 를 도입해 올바른 context vector 를 "attend"하고 있는지 판단한다.
마지막으로 adaptation gate 함수 집합 를 통해 attention context vector 집합을 업데이트한다.
는 행렬의 요소 곱을 나타낸다. 이면 현재 context vector 는 새로운 context vector 집합에 더해지지 않을 것이다.
gated attention similarity loss 을 도입하여 소스 도메인과 타겟 도메인의 character-level feature 집합의 분포거리를 최소화하도록 학습할 것이다.
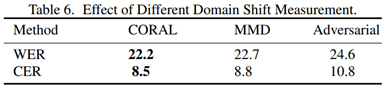
라고 표기된 분포 거리 측정 방법은 (1) MMD, (2) CORAL, (3) adversarial loss 등 많은 선택지가 있지만 실험적으로 CORAL 방법이 사용되었다.
3.3. Overall Objective Function
먼저 label이 잘 지정되어 있는 소스 도메인 데이터를 사용해서 올바르게 텍스트를 인식하도록 한다.
위 만 사용해서 학습하면 소스 도메인에 과적합되며, 타겟 도메인은 사용하지 않는 경우이다.
따라서 위에서 정의한 gated attention similarity loss function을 가져와 최종 목적함수를 아래와 같이 정의하였다.
는 두 손실 함수의 균형을 조정할 수 있는 hyper-parameter이다.
4. Experiments
Dataset. 아래 데이터셋은 모두 타겟 도메인으로 사용되었다.
ICDAR-2003: 860개의 cropped scene text imageICDAR-2013: 857개의 cropped scene text imageStreet View Text (SVT): Google Street View에서 수집한 670개의 scene text image, label이 없는 test dataset이다.IIIT5K-words (IIITK-5K): 인터넷에서 수집한 3000개의 scene text image, label이 없는 test dataset이다.IAM: 손 글씨 영어 text image,train:validation:test = 46945:7554:20306 (words)로 구성되어 있다.CROHME 2014: 손 글씨 수학 수식 image,train:validation = 8836:986
4.1. Comparison with Existing Methods
- SSDAN-base : GAS 유닛을 제거한 모델, 이를 통해 GAS 유닛의 효과를 보려고 한다.
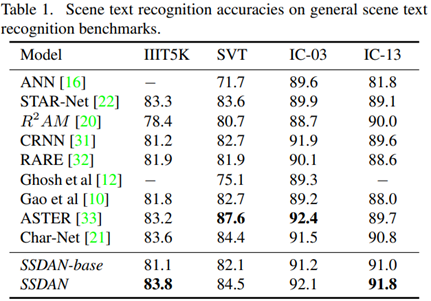
Results on Scene Text.
해당 실험에서 소스 도메인은 거대한 합성 데이터셋인 MJSYNTH를 사용했다.
일부 데이터셋에 대해 최고의 성능을 발휘하지는 못했지만 여러 도메인에 강건한 모델을 설계하고자하는 저자들의 연구 방향과 다르다는 점을 고려했을 때, 괜찮을 결과이다.
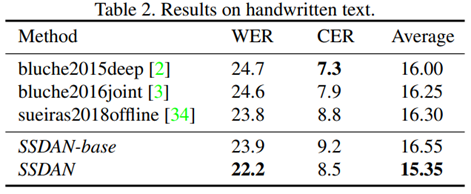
Results on Handwritten Text.
해당 실험에서 IAM데이터셋을 사용했고, 적당히 나누어 소스 도메인과 타겟 도메인으로 사용했다.
각 도메인의 데이터셋은 손 글씨를 적는 사람이 달랐으며, 그에 따라 손 글씨의 스타일도 차이가 있었다.
Results on Handwritten Mathematical Expression.
해당 실험에서 수식 인식은 문자를 인식하는 것 뿐만 아니라 수식의 구조를 담고 있는 LaTeX 형식도 예측해야 하기 때문에 훨씬 어려운 task이다.
CROHME 2014를 나누어 소스 도메인, 타겟 도메인으로 했다.
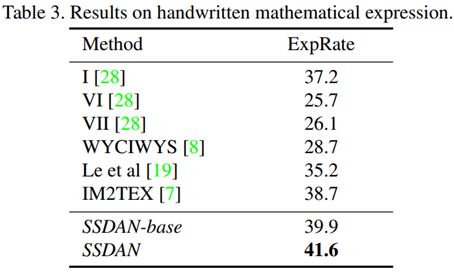
4.2. Ablation Study
SSDAN 모델을 구성하는 구성 요소들이 어떠한 역할을 하고 있는지 분석하고 hyper-parameter를 조정해가면서 그 효과를 탐구했다.
Comparison to Standard Domain Adaptation. CNN Encoder와 GAS 유닛에 변화를 주며 그 결과를 관찰했다.
- CNN Encoder: VGG, ResNet, DenseNet
- GAS unit: 유/무
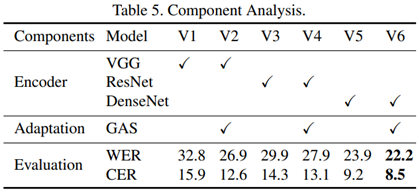
대체적으로 GAS 유닛을 가진 모델에 성능이 좋고, DenseNet을 CNN Encoder로 사용할 때 성능이 좋았다.
Effect of Different Domain Shift Measurement. 3.2.장에서 사용하는 소스 도메인과 타겟 도메인 사이의 분포 거리를 측정하는 방법에 따른 모델의 성능을 분석한다.
- Distribution measurement: CORAL, MMD, Adversarial loss
Parameter Sensitive Analysis. hyper-parameter 와 를 조정하며 모델의 성능을 관찰한다.
- :
- :
이면 sequence domain adaptation을 사용하지 않는 SSDAN-base와 같은 상태가 된다.
이면 gate함수는 작동하지 않고 "attention"정보를 활용하지 못할 것이다.
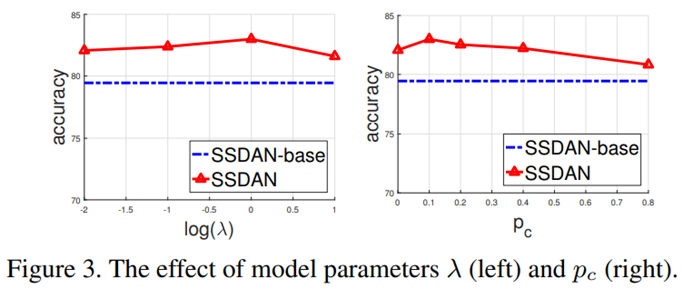
그림 3은 일 때 값의 변화에 따른 결과이다. gate함수가 전체적인 성능에 기여하는 바가 크다고 볼 수 있다.
Visualization. IAM데이터셋에 대한 인식 결과를 시각화한다. 시각화 결과를 통해 모델이 어디를 "attend"하는지 확인할 수 있다.

Effect of Sunsupervised Data. hyper-parameter를 고정하고 labeled data와 unlabeled data의 수를 다르게 하면서 결과를 분석했다.
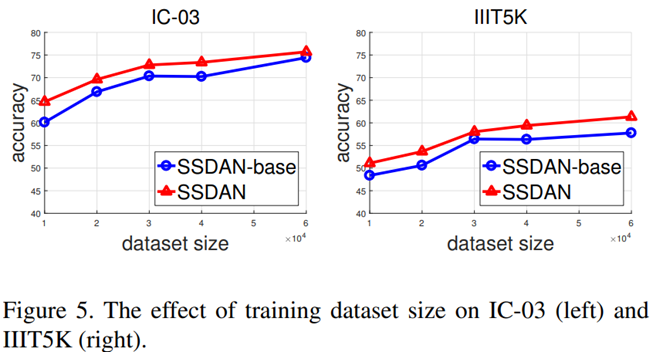
labeled data의 수가 많을 수록 성능은 더 높았다.
하지만, labeled data의 수가 작을 때에도 의미있는 성능 향상을 볼 수 있다는 점을 강조하고 싶다.
5. Conclusion
- 강건한 텍스트 이미지 인식 모델, SSDAN을 소개.
- 시퀀스 형태의 텍스트 이미지 인식과 Domain adaptation 분야를 연결.
- scene text, 손 글씨, 수학 수식 분야와 같은 넓은 분야로 일반화.
