Xie, Qizhe, et al. "Unsupervised data augmentation for consistency training." arXiv preprint arXiv:1904.12848 (2019).
Abstract
준지도학습(Semi-supervised learning)이 데이터셋의 labeled data가 부족할 때, 모델의 성능을 향상시키는 데 역할을 수행하고 있다.
본 연구에서는
- Unlabeled data를 효과적으로 noise로써 사용할 수 있는지를 보인다.
- 좋은 성능의 데이터 증강(data augmentation) 방법으로 생성된 데이터들이 준지도학습에서 중요한 역할을 수행할 수 있음을 보인다.
RandAugment와 Back-translation 같은 더 발전한 데이터 증강 방법으로 눈에 띄는 향상을 볼 수 있었다. 전이학습(Transfer learning)과도 잘 조합될 수 있었다.
1. Introduction
딥 러닝은 근본적으로 많은 양의 labeled data가 필요하다.
준지도학습(Semi-supervised learning; SSL)은 이러한 약점을 해결하기 위한 방법을 연구해왔다. 최근에는 일반적으로 unlabeled data의 데이터 일관성(consistency)를 찾는 학습에 기반한 연구들이 각광받고 있다.
Prior works for Consistency
이전 연구들은 모델의 입력(Input space)이나 잠재 공간(hidden states)에 noise를 부여하고 모델을 강건하게 하는 방법을 연구해왔다.
하지만 Gaussian Noise를 첨부하거나 Drop-out을 적용하여 noise를 부여하는 등 다소 "약한(weak)" 변화(translation)를 주는 것이 대표적이었다.
Contributions
본 연구에서는 데이터 일관성(consistency)를 학습함에 있어 노이즈 삽입(noise injection)의 역할을 탐구하고, 지도학습에서 사용되었던 더 나은 데이터 증강 방법(advanced data augmentation)들을 준지도학습에도 적용할 수 있는지 관찰한다.
더 나은 데이터 증강 방법을 준지도학습의 데이터 일관성 학습에 사용한다는 것을 강조하기 위해 방법론을 "Unsupervised Data Augmentation; UDA"라고 명명했다.
- 지도학습에서 사용되던 state-of-the-art 데이터 증강 방법들을 준지도학습의 데이터 일관성(consistency)를 학습하는 데에도 우수한 역할을 할 수 있음을 보인다.
- UDA가 훨씬 더 많은 labeled data를 사용해 학습하는 지도학습에 비해서도 이를 뛰어넘는 성능을 가진다는 것을 보인다.
- UDA는 전이학습(transfer learning)에도 잘 결합될 수 있으며, ImageNet과 같은 거대한 데이터셋에서도 효과적일 수 있다.
- UDA가 성능을 향상시킬 수 있는 이론적 근거에 대한 연구를 소개한다.
2. Unsupervised Data Augmentation (UDA)
2.1. Background: Supervised Data Augmentation
데이터 증강은 데이터의 레이블은 바꾸지 않으면서 샘플에 변환을 거쳐 새롭고 진짜처럼 보이는 학습 데이터를 만드는 것을 목적으로 한다.
이미지 데이터에는 이미지의 회전, 확대 등이 있고 텍스트 데이터의 경우 paraphrasing이 있다.
2.2. Unsupervised Data Augmentation
일반적인 최근의 연구들은 모델의 smoothness를 향상시키기 위해 데이터에 noise injection을 가해 데이터의 consistency를 학습하는 방향을 가지고 있었다.
하지만, 본 연구진은 다양하고, 더 발전된 형태의 데이터 증강 방법들이 지도학습 환경에서 상당한 성능 향상을 가져왔기 때문에 데이터 증강 방법이 만들어낸 데이터를 noise로써 준지도학습에 사용하면 성능 향상을 가져올 것이라 기대했다.
기존의 데이터 consistency를 학습하는 방향과 데이터 증강을 통해 만든 데이터셋을 noise로써 활용하는 방향을 동시에 모두 최적화할 수 있는 방법을 제안한다. 수식적으로는 아래와 같이 표현할 수 있다.
left term은 지도학습의 cross entropy를 의미하고, right term은 비지도학습의 consistency loss를 의미한다. parameter 를 통해 둘의 비율을 조정할 수 있다.
2.3. Augmentation Strategies for Different Tasks
다양한 task에 맞게 본 연구에서 사용한 데이터 증강 방법은 아래와 같다.
-
RandAugment for Image Classification
- AutoAugment라는 데이터 증강 방법에 영감을 얻어 RandAugment로 개조했다.
- AutoAugment란, Python Image Library (PIL)에서 모든 변환 방법들을 조합해 최적의 이미지 변환 방법을 찾아 변형시켜 데이터 증강에 사용하는 방법이다.
- RandAugment에선 최적의 이미지 변환 방법을 찾는 대신 균일하게 랜덤 샘플링(uniformly sample)하여 데이터 증강에 사용한다.
- 최적의 이미지 변환 방법을 찾을 시간을 사용하지 않아 더 빠르게 작동할 수 있다.
-
Back-translation for Text Classification
- 임의의 샘플 문장 를 A언어에서 B언어로 번역한 다음 다시 A언어로 번역해 새로운 데이터를 얻는 방식이다.
- 이를 통해 원본 문장의 의미를 보존하면서 다양한 paraphrasing을 얻을 수 있다.
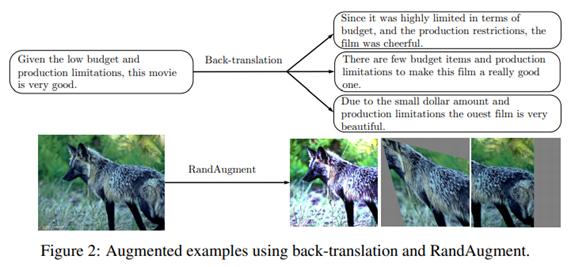
-
Word replacing with TF-IDF for Text Classification
- Back-translation이 문장의 감정 상태(semantics of a sentence)를 잘 보존할 수 있지만 DBPedia 데이터셋과 같은 주제 분류 task에서는 적합하지 않은 방법이다.
- 몇몇 핵심단어들이 주제에 대한 상당한 정보량을 가지고 있다.
- 여기에 TF-IDF를 이용해 높은 TF-IDF 점수를 가지는 단어들은 그대로 두고, 낮은 TF-IDF 점수를 가지는 단어들은 주제에 대한 정보량을 더 많이 가지고 있는 단어로 대체하는 방식을 사용했다.TF(단어 빈도, term frequency)는 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값으로, 이 값이 높을수록 문서에서 중요하다고 생각할 수 있다. 하지만 단어 자체가 문서군 내에서 자주 사용 되는 경우, 이것은 그 단어가 흔하게 등장한다는 것을 의미한다. 이것을 DF(문서 빈도, document frequency)라고 하며, 이 값의 역수를 IDF(역문서 빈도, inverse document frequency)라고 한다. TF-IDF는 TF와 IDF를 곱한 값이다. - Wikipedia
4. Experiments
Language datasets
- IMDb
- Yelp-2, Yelp-5
- Amazon-2, Amazon-5
- DBPedia
Vision datasets
- CIFAR-10
- SVHN (Street View House Numbers)
- ImageNet
4.1. Correlation between Supervised and Semi-supervised Performances
먼저 UDA가 지도학습과 준지도학습에 모두 사용되었을 때, 모두 성능향상을 가져올 수 있는지 검증하기 위해, CIFAR-10과 Yelp-5에 대한 실험을 진행했다.
CIFAR-10에서는 이미지 Crop, Flip, Cutout등의 변형과 RandAugment 변형을 비교했다.
Yelp-5에서는 Switchout[1]과 Back-translation을 비교했다.
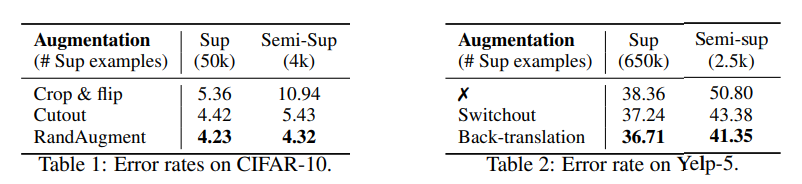
지도학습과 준지도학습에서 모두 성능향상을 관찰할 수 있었다. 이 결과를 통해 "강한(strong)" 데이터 증강 방법이 준지도학습에서도 사용될 수 있음을 알 수 있다.[1]
4.2. Algorithm Comparison on Vision Semi-supervised Learning Benchmarks
다른 현존하는 준지도학습 알고리즘에 비해 UDA가 더 나은 성능을 보이는지 실험했다.
이를 위해 준지도학습의 벤치마크로 가장 널리 사용되는 CIFAR-10과 SVHN에 실험했다.
Vary the size of labeled data.
Wide-ResNet-28-2를 기초 모델로 하고, 데이터 사이즈에 대한 비교이다.
- Gaussian noise를 입력에 추가하는 알고리즘, Virtual adversarial training (VAT)
- 준지도학습의 발전에 기여한 방법들을 조합하는 MixMatch[2] 방법
- UDA
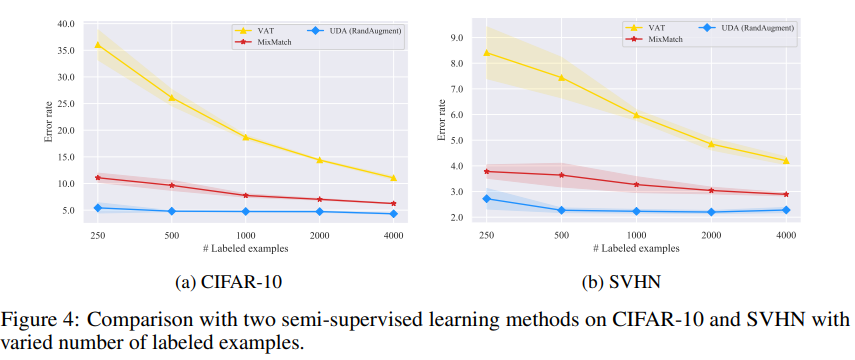
- UDA는 labeled data의 양이 증가함에 상관없이 다른 두 baseline 알고리즘을 뛰어넘는 성능을 보인다.
- VAT가 실제 labeled data의 양이 증가함에 따라 성능이 향상되는 것을 볼 때, VAT가 생성하는 노이즈의 한계를 뚜렸하게 볼 수 있다. 실제로, VAT가 생성하는 노이즈는 실존하지 않을 것 같은 인공적인 면을 많이 포함한다.
Vary model architecture.
다른 모델을 사용하여 사용하여 UDA의 성능 평가 비교
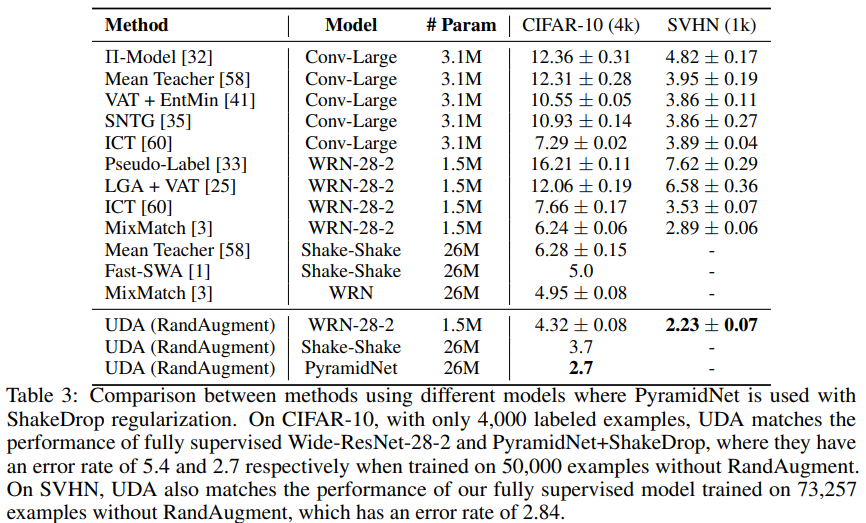
다른 모든 알고리즘들을 상당한 격차로 능가하고 있고, 10배나 더 많은 labeled data를 사용하는 지도학습의 성능과도 비슷한 수준의 성능을 보이고 있다.
4.3. Evaluation on Text Classification Datasets
언어 모델 도메인에서의 UDA 성능 평가, BERT와 같은 비지도 representation learning과의 조합이 가능한지를 판단하기 위한 실험 설계.
- random Transformer
- BERT_BASE
- BERT_LARGE
- BERT_FINETUNE: BERT_LARGE를 같은 도메인의 unlabeled data에 fine-tune한 모델
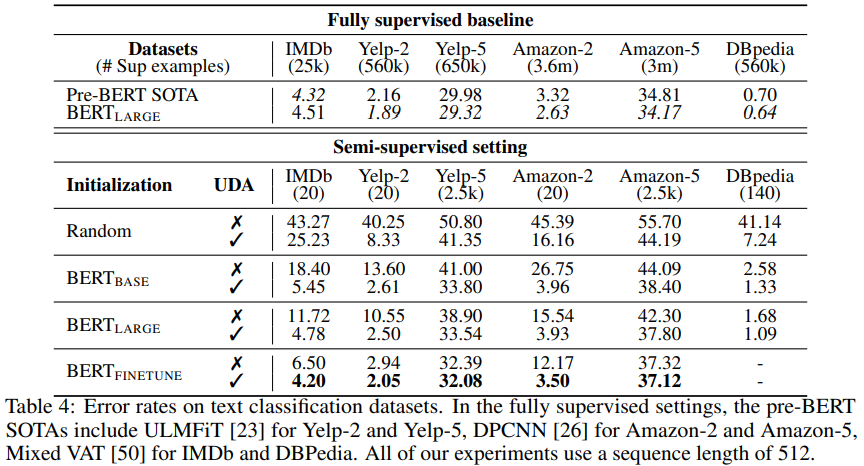
위 표는 아래와 같은 세 가지 시사점을 보여주고 있다.
- 매우 적은 labeled data를 사용해도 지도학습 SOTA 모델에 비해 준수한 성능을 나타냈다. 특히 이진 분류(binary)의 task에선 labeled data 20개만 사용하고도 대등한 성능이었다.
- BERT_FINETUNE의 성능도 향상되는 것을 볼 때, UDA는 전이학습이나 representation learning을 보완할 수 있다.
- 다섯 가지 카테고리의 감정 분류 task에서 labeled data를 클래스 당 500개, 총 2500개를 사용한 UDA와 지도학습 SOTA 모델은 성능 격차를 꽤 많이 보이고 있다. 이 점은 향후 연구에서 더 나아질 여지가 될 수 있다.
4.4. Scalability Test on the ImageNet Dataset
다음으로 UDA가 더 규모가 크고 어려운 task에도 잘 동작할 수 있는지 평가한다.
ResNet-50의 모델로 ImageNet 데이터셋을 다뤄본다.
실험 환경 설정은 아래와 같이 두 가지로 나누었다.
- ImageNet의 labeled data를 10%만 사용하고 다른 데이터는 모두 레이블을 제거하여 사용한다. 따라서 여기에 사용하는 데이터는 모두 in-domain 데이터이다.
- ImageNet의 모든 데이터를 labeled data로 사용하고 JFT[3]를 통해 만든 130만 개의 이미지를 사용한다. 따라서 여기에 사용하는 unlabeled data는 모두 in-domain 데이터라고 볼 수 없다.
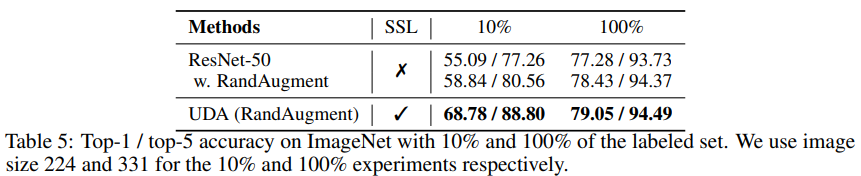
위에 나타난 실험결과를 통해 UDA는 데이터의 크기에서 뿐만 아니라 out-of-domain의 unlabeled data에 적용될 때에도 모델의 성능 향상에 기여할 수 있음을 알 수 있다.
5. Related Work
데이터 consistency의 학습을 위한 이전의 연구들은 "약한(weak)" 데이터 증강을 드물게 사용하고 있다.
- ICT[4]와 MixMatch 또한 준지도학습에서 flipping과 cropping과 같은 간단한 데이터 증강 방법을 혼합했다.
- Pseudo-ensemble은 Gaussian noise와 Drop-out을 통한 noise를 적용했다.
- VAT는 모델이 가장 민감하게 반응하는 입력 공간(input space)에서의 직접적인 변화를 주면서 실험했다.
- 입력 공간이나, hidden representations에서의 데이터 consistency를 활용하는 것과는 또 다르게, 모델 파라미터에서의 consistency를 활용하는 방향의 연구도 있었다: Mean Teacher, fast-Stochastic Weight Averaging, Smooth Neighbors on Teacher Graphs
6. Conclusion
- 본 논문에서 데이터 증강과 준지도학습이 잘 조합될 수 있음을 보이고 있다.
- 더 좋은 Advanced Data Augmentation일 수록 준지도학습에서도 눈에 띄는 결과를 가져올 수 있다.
- UDA는 다양한 분포와 진짜같은 noise를 생성하고 모델을 더 강건하게 할 수 있다.
- UDA가 향후 연구에 영감을 주어, 다른 task에 대한 지도학습에서의 더 좋은 Advanced 데이터 증강 방법을 준지도학습에서 시도해볼 수 있기를 바란다.
References
[1] Wang, Xinyi, et al. "Switchout: an efficient data augmentation algorithm for neural machine translation." arXiv preprint arXiv:1808.07512 (2018).
[2] Berthelot, David, et al. "Mixmatch: A holistic approach to semi-supervised learning." arXiv preprint arXiv:1905.02249 (2019).
[3] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[4] Verma, Vikas, et al. "Interpolation consistency training for semi-supervised learning." arXiv preprint arXiv:1903.03825 (2019).
