Classification
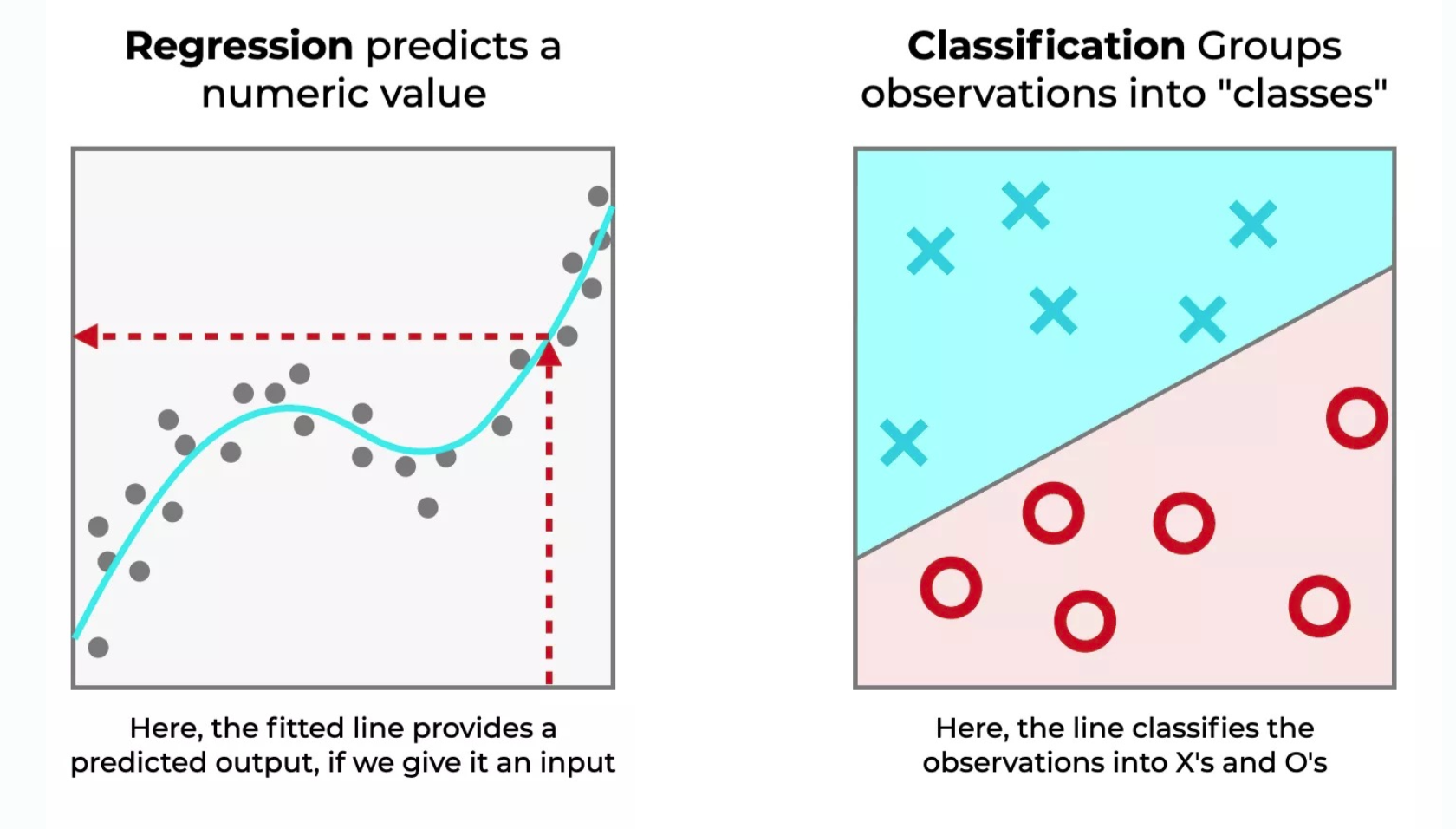
Classification is a process of categorizing a given set of data into classes.
It can be performed on both structured or unstructured data. The process starts with predicting the class of given data points. The classes are often referred to as target, label or categories.
분류란 주어진 데이터셋을 클래스로 분류하는 과정을 의미한다. 설계한 모델은 각 클래스에 대응하는 확률값을 가진다 (0~1).
예) {0: 과일, 1: 야채, 2. 곡물} {0.25, 0.5, 0.25}
Classification Algorithm
Logistic Regression
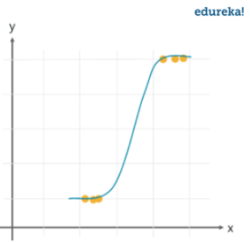
Independent Variable (입력)와 Dependent Variable (출력)의 관계를 정의하여, 2진분류를 하는 알고리즘.
Naive Bayes Classfier
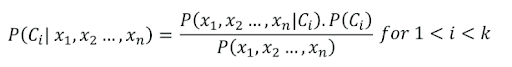
데이터의 모든 Feature는 서로 독립적이라는 가정하에 사용되는 분류 알고리즘이다. 조건부 확률 (B라는 사건이 주어졌을때, A라는 사건이 일어날 확률)에 기반하여, 입력 데이터의 클래스 확률을 분류한다.
다음은, P(Rain | Play Soccer) 축구를 하는날에, 비가 올 확률을 Bayes 정리로 구한 확률이다.

- 비가 올때 축구를 할 확률 : 0.28
- 축구를 할 확률 : 0.5
- 비가 올 확률 : 0.35
- 축구를 할때 비가 올 확률 : 0.2
다만, 서로간의 Feature는 반드시 독립적이어야 한다는 조건이 있다.
추후, 조건부 확률은, 최대 우도법 (Maximum Likelyhood)에서 같이 상세히 다뤄보자.
Stochastic Gradient Descent (SGD)
Stochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. differentiable or subdifferentiable). It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient (calculated from the entire data set) by an estimate thereof (calculated from a randomly selected subset of the data).
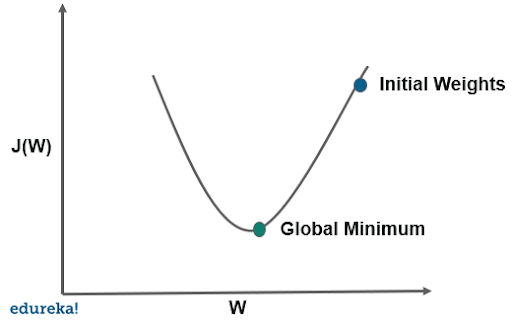
전체 데이터셋이 크고, 학습에 대한 시간적 효율/메모리 관리를 위해, 표본 샘플의 경사도를 구하여 오차함수를 최적화하는데 사용되는 알고리즘이다.
Local Minimum에 빠질 확률이 적고, 컴퓨터의 계산부담을 줄여주지만 Global Minimum에 도달하지 못할 가능성이 있다.
K-Nearest Neighbor
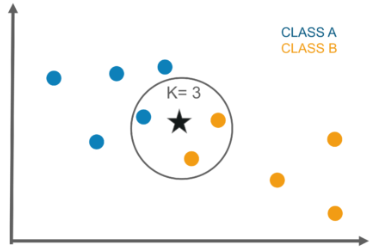
Lazy Learning의 일종으로, 모든 Training Data를 그래프에 저장하여 간단한 다수결로 (Majority Vote) 클래스를 결정한다.
범주를 결정 (K개의 이웃, e.g, K=3일때 Star는 B 클래스다)
Decision Tree
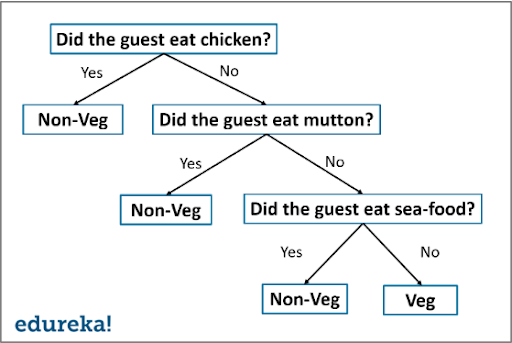
계층형 트리를 가지며, If-Then 규칙을 사용하여 데이터의 클래스를 분류한다. 오버 피팅등의 이슈 및 모델 성능의 일반화를 장담하기 어렵다.
Random Forest
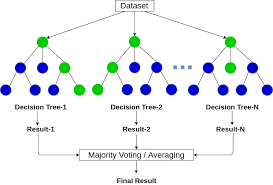
앙상블 학습의 일종으로 다수의 Decision Tree를 가지고 있으며, 일반 Decistion Tree에 비해 일반화 성능이 좋다.
다수의 Decision Tree로부터 평균 예측치를 출력후 클래스를 분류한다.
