
13주차
Going deeper의 2부가 시작됐다..
12주차에 처음이자 마지막으로 있는 아이펠 방학을 지나고 맞이하는 2부여서
더 힘겹지만 열심히하려고 노력했다.
방학 때는 아이펠 내에서 취업에 대한 준비를 위해 개인적으로 찾아볼 수 있는 과제를 준다. 과제 수행을 위한 레퍼런스를 제공하여 취업에 대해 작게나마 고민하는 시간을 갖을 수 있어 좋았다. 방학 숙제의 개념으로 제공되지만 안해도 처벌(?)은 없다.
나는 개인적으로 잘 쉬어야 잘 공부한다는 마인드여서 실컷 놀고 왔다 ㅎㅎ
13주차 task
- End to End OCR
- 멀리 있는 사람도 스티커를 붙여주자 - Face detection
두 가지 task 모두 object detection의 개념이 공통적으로 들어가기 때문에 object detection 파트를 공부하는 것이 cv에서 큰 도움이 되는 것을 다시금 느끼게 되었다. object detection을 위한 다양한 모델이 제시되었지만 나는 one-stage 모델인 yolo 계열의 모델을 주로 공부했다! 나중에 기회가 되면 따로 포스팅을 해보겠다..
1. End to End OCR
이미지로부터 text detection + recognition을 한 번에 수행하는 모델을 구현하는 것이 이번 프로젝트의 목표이다.
-
text detection은 문장 단위 및 단어 단위의 text의 위치를 찾는 것이다.
따라서 기존의 객체 탐지를 위해 사용했던 object detection, segmentation 기법이 사용된다.
다양한 기법들이 text detection을 위해 사용되었지만 이를 일일히 소개하진 않고 'EASR:An Efficient and Accurate Scene Text Detector'라는 논문에서 소개된 표로 대충 이러한 게 있었구나 정도로 이해하면 된다.
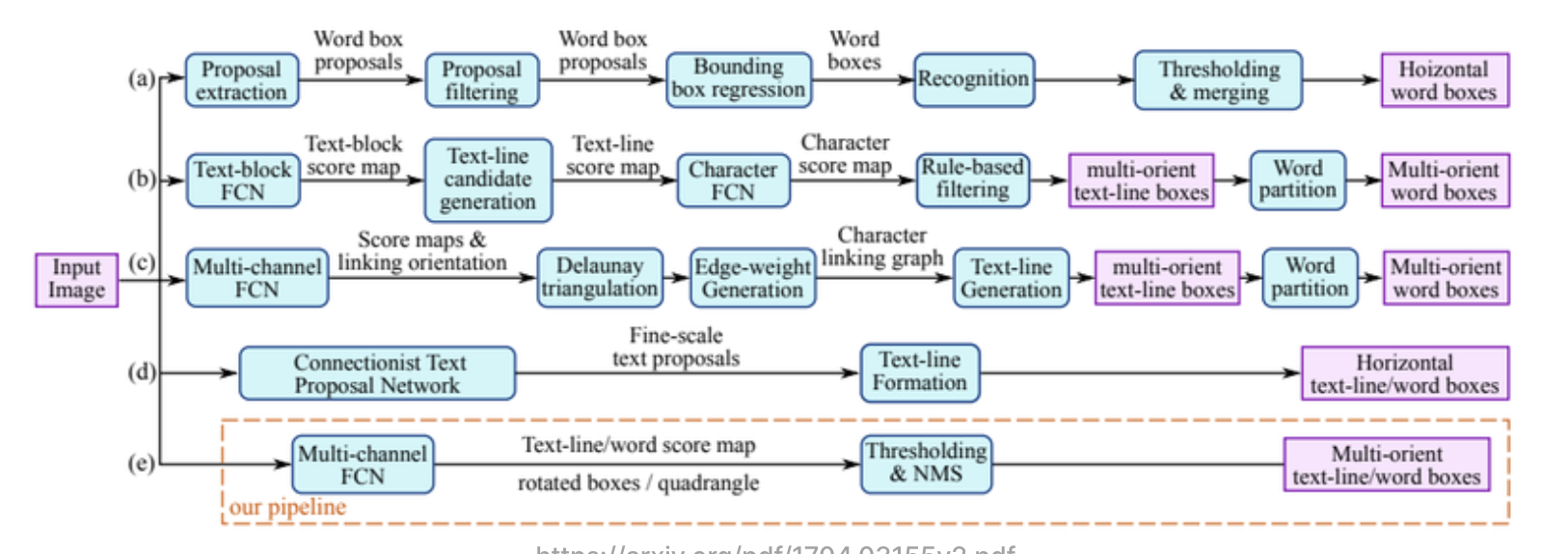
정리하자면, 단어 단위와 글자 단위의 탐지 기법이 조금 다른데
단어 단위의 탐지는 단어에 대한 bbox 추출을 위해 object detection의 Regression(anchor로 bounding box regression 수행)기반이,
글자 단위 탐지에는 글자 영역에 대한 segmentation 기반의 방법론을 사용한다고 한다.
최근에는 CRAFT, Pyramid mask Text detector 등의 모델을 사용하여 text detection을 수행한다고 한다. -
text recognition은 찾은 위치에 대한 text가 무엇인지 인식하는 것을 의미한다. 인식하는 것을 구현하기 위해서는 우선 unsegmented data에 대해 이해할 필요가 있다. unsegmented data는 말 그대로 segmentation이 되어있지 않은 데이터를 의미한다.
가령 이미지에서 "you"라는 단어는 "y","o","u"로 segmentation이 가능하여 각각 라벨링이 되어 있다면, 이는 segmented data가 될 것이다. 반대의 경우가 unsegmented data가 된다. 즉, 전체적인 라벨은 알지만 sequence를 이루는 부분들은 모르는 경우를 의미한다.(= segment되어 있지 않은 하위 데이터들 끼리 sequence를 이룬다.)
이러한 unsegmented data를 위해 CNN + RNN 모델을 같이 사용하는 방법을 고안해냈다. CNN은 강력한 image feature extractor이지만 추출된 특징으로 찾은 text가 무엇을 의미하는 지는 알 수가 없다. 반면 RNN은 강력한 sequence learner이지만, 데이터를 미리 segment 시켜야 하고, 아웃풋을 label sequence로 변환하는 사후 처리가 필요하다.
따라서 이 두 가지를 고려하여 추출된 feature를 map-to-sequence를 통해 sequence 형태의 feature로 변환한 후 다양한 길이의 input을 처리할 수 있는 RNN으로 넣는 CRNN 모델을 사용했다.
이 외에도 CTC loss를 사용하여 unsegmented data에 대해 어떤 문자일 확률이 높은지 추정하게 한다. CTC
Github: https://github.com/3n952/aiffel_6/tree/main/GD06
2. 멀리 있는 사람도 스티커를 붙여주자 - Face detection
이미지로부터 사람의 얼굴을 인식하고 특정 부위에 적용할 스티커를 탐지된 얼굴에 적용시켜보자는 것이 이번 프로젝트의 목표이다.
one-stage object detection 모델을 위주로 face detection에 적합한 모델을 선정하기 위해, yolo와 ssd 모델 구조에 대해 공부하는 시간이 되었다.
Github: https://github.com/3n952/aiffel_6/blob/main/GD07/GD07_main.ipynb
