
14주차
Going deeper의 마지막 주차이다.
하루에 한 노드씩 보기가 슬슬 버거워 질 때 즈음 going deeper가
마무리 돼서 다행이라고 생각했다.
CV에서 사용되는 대부분의 task는 다뤄본 것 같아서 나름 뿌듯하기도 했다.
그럼에도 해당 task를 완벽하게 다룰 줄 모르기 때문에 더욱더 공부해야 겠다고 다짐했다.
14주차 task
- 행동 스티커 만들기 - keypoint detection
- multi-modal 생성형 AI - Stable diffusion
keypoint detection이라고 하면, 말 그대로 keypoint를 탐지하는 것이다.
예를 들어 human pose estimation(관절) 등이 있다.
다음으로 multi-modal은 AI에서는 다양한 데이터 형식을 의미한다.
즉, text to image, image to text 등과 같이 다른 데이터 형식으로 모델의 결과를 보여주는 것을 의미한다.
이번 Going deeper에서는 이 두 task에 대해 다뤄보았다.
1. 행동 스티커 만들기 - keypoint detection
이번 프로젝트의 목표는 사람의 행동을 추정하는 것이다.
Human pose estimation(HPE) task이다.
HPE는 크게 2가지로 나뉜다.
- 2D HPE
- 3D HPE
2D HPE는 2D에서 2차원 좌표(x,y)를 찾는 것이고,
3D HPE는 2D에서 3차원 좌표(x,y,z)를 찾는 것이다.
이번 포스팅에서는 2D HPE를 기준으로 다룬다.
이를 다루는 방법은 top-down, bottom-up 이렇게 두 가지가 있다.

top-down 방식은 모든 사람의 정확한 keypoint를 찾기위해 object detection을 사용한다. 이후 detect된 객체를 crop한 이미지내에서 keypoint를 찾아내어 표현한다.
다만 detector가 선행되어야 하고 모든 사람마다 detection 알고리즘을 적용 해야하기 때문에 사람이 많이 등장할 때는 느리다는 단점이 있다.
bottom-up 방식은 detector가 없고 keypoint를 먼저 검출한다. 예를 들어 손목에 해당하는 모든 점들을 검출하는 식이다. 이후 한 사람에 대한 keypoint를 clustering해서 표현한다.
이는 detector가 필요없기 때문에 다수의 사람이 영상에 등장하더라도 속도가 크게 저하되지 않는다는 장점이 있다. 다만 clustering 방식에서 top-down에 비해 keypoint 검출 범위가 넓어지기 때문에 성능면에서 크게 저하된다는 단점이 있다.
얼마나 정확해야 하는지, 데이터에 사람이 얼마나 구성되어 있는지 등에 따라서 필요한 알고리즘을 사용한다.
detection에 대해 배워봤으니, top-down방식을 사용하여 HPE를 수행해보았다!
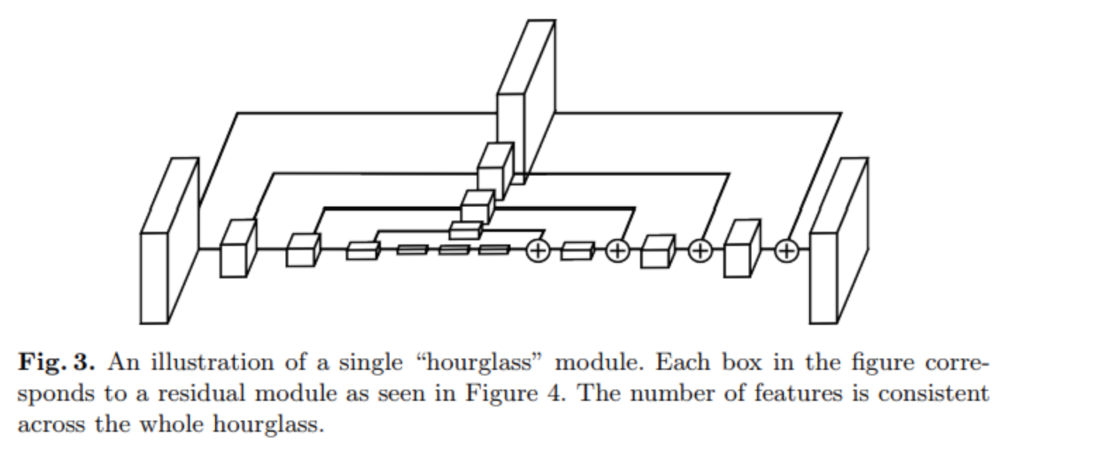
이를 수행하기 위해 Stacked Hourglass Network 모델을 사용했다.
Stacked Hourglass Network 이전에도 pose estimation을 위한 모델은 다양하게 등장했고 발전해왔다. 다만 이번 포스팅에서는 Stacked Hourglass Network만 다루도록 하겠다.
Stacked Hourglass network
StackedHourglassNetwork의 기본 구조는 모래시계 같은 모양으로 만들어져 있다. Convlayer와 pooling으로 이미지(또는 feature)를 인코딩하고upsampling layer를 통해 feature map의 크기를 키우는 방향으로decoding한다.featuremap 크기가 작아졌다 커지는 구조여서 hourglass 라고 표현한다(모래시계 형태).
기존방법들과의 가장 큰 차이점은 다음과 같다.
- feature map upsampling
- residual connection
pooling으로 image의 global feature를 찾고 upsampling으로 local feature를 고려하는 아이디어가 hourglass의 핵심이다.
이전에 downsampling 되는 feature map을 upsample layer에서 residual connet함으로서 이를 가능하게 했다.
자세한 코드는 아래 깃허브 링크를 참고해주세요!
human pose estimation
2. multi-modal 생성형 AI - Stable diffusion
멀티모달 생성형 AI는 요즘 매우 인기있고 핫한 인공지능 분야이다. 지금 AI 열풍을 불러온 장본인이기도 하다. text to image, image to video 등등의 멀티모달 생성형 AI가 계속해서 등장하고 발전하고 있는 중이다.
그 중에서 이번에는 stable diffusion 모델을 사용하여 text to image 모델을 사용해보고 적용해보는 시간을 가졌다.
해당 내용은 지금 계속 공부중이므로 나중에 기회가 되면 보다 세부적인 내용으로 정리하도록 하겠다.
깃허브 링크: stable diffusion 실습
