
1. 설치 및 환경 설정
pip install langchain
2. Model I/O (전체 구조)
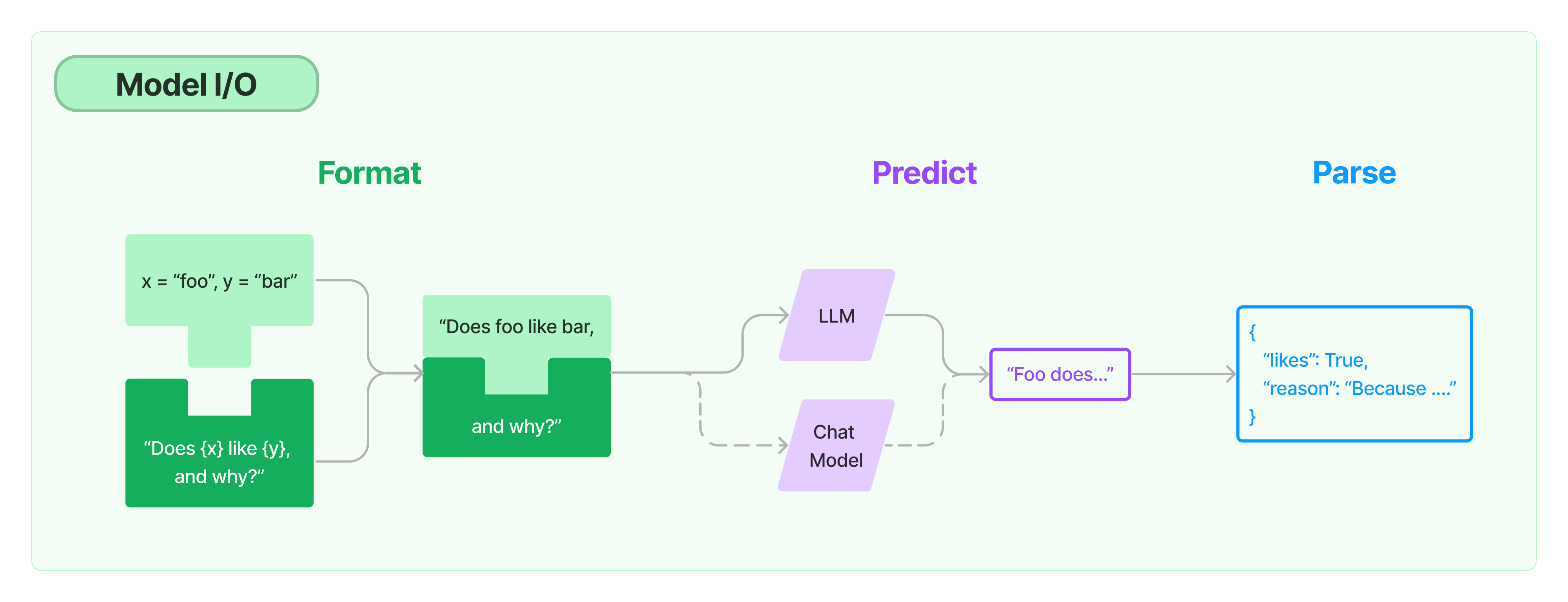
Prompts(초록색): 입력 템플릿화, 동적으로 선택, and 모델 입력 관리Language models(보라색): 공통 인터페이스를 통해 언어 모델을 호출합니다.Output parsers(파란색): 모델 출력에서 정보 추출
=> 해당 파트에서는 Language models를 다룬다.
3. LLM(Large Language Models)
- 기본 설정
pip install openai
- API 키 등록
export OPENAI_API_KEY="..."import os os.environ["OPENAI_API_KEY"] = "..."# 원인을 모르겠지만 테스트 했을 때 안됨. 시도해보고 안되면 위의 방법을 해볼 것 from langchain.llms import OpenAI llm = OpenAI(openai_api_key="...")
3-1. 기본 함수 call, generate
-
뒤에 내용이 해당 함수들을 활용하므로 간다한 예제로 어떤 값을 받을 수 있는지 감을 잡는 파트.
-
__call__- 예제
from langchain.llms import OpenAI llm = OpenAI(openai_api_key="...") llm("Tell me a joke") # 출력 : 'Why did the chicken cross the road?\n\nTo get to the other side.' -
generate- 예제
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"]*15) len(llm_result.generations) #"Tell me a joke" 답변 * 15 + "Tell me a poem" 답변 * 15 = 30 llm_result.llm_output ''' 출력 {'token_usage': {'completion_tokens': 3903, 'total_tokens': 4023, 'prompt_tokens': 120}} '''
3-2. Async API
-
agenerate이 메서드를 사용하여 OpenAI LLM을 비동기식으로 호출 할 수 있습니다 -
예제
import time import asyncio from langchain.llms import OpenAI def generate_serially(): llm = OpenAI(temperature=0.9) for _ in range(10): resp = llm.generate(["Hello, how are you?"]) print(resp.generations[0][0].text) async def async_generate(llm): resp = await llm.agenerate(["Hello, how are you?"]) print(resp.generations[0][0].text) async def generate_concurrently(): llm = OpenAI(temperature=0.9) tasks = [async_generate(llm) for _ in range(10)] await asyncio.gather(*tasks) s = time.perf_counter() # If running this outside of Jupyter, use asyncio.run(generate_concurrently()) await generate_concurrently() elapsed = time.perf_counter() - s print("\033[1m" + f"Concurrent executed in {elapsed:0.2f} seconds." + "\033[0m") s = time.perf_counter() generate_serially() elapsed = time.perf_counter() - s print("\033[1m" + f"Serial executed in {elapsed:0.2f} seconds." + "\033[0m") -
async, await 사용은 fastAPI를 활용해본 사람이라면 익숙할 것 같다.
-
async def get_burgers(number: int): #Do some asynchronous stuff to create the burgers return burgers #This is not asynchronous def get_sequential_burgers(number: int): #Do some sequential stuff to create the burgers return burgers @app.get('/burgers') async def read_burgers(): burgers = await get_burgers(2) return burgers
3-3. Custom LLM, Fake LLM, Human input LLM
- 예시가 너무 간단함. 이런것이 있다는 것 정도 알아둘 것 -> 이후에 필요하다면 문서 활용
- Custom LLM
from langchain.llms.base import LLMLLM을 상속받아 새로운 클래스를 만듬._call함수 재정의
- Fake LLM
- 테스트에 사용할 수 있는 Fake LLM 클래스. 이를 통해 LLM에 대한 호출을 모의하고 LLM이 특정 방식으로 응답하는 경우 발생하는 상황을 시뮬레이션할 수 있다.
from langchain.llms.fake import FakeListLLM- 아래 함수와 같이 사용
from langchain.agents import load_tools from langchain.agents import initialize_agent from langchain.agents import AgentType
- Human input LLM
- 테스트, 디버깅 또는 교육 목적으로 사용할 수 있는 Human LLM 클래스를 제공. 이를 통해 LLM에 대한 호출을 모의하고 인간이 프롬프트를 수신한 경우 응답하는 방식을 시뮬레이션할 수 있다.
from langchain.llms.human import HumanInputLLM- 아래 함수와 같이 사용
from langchain.agents import load_tools from langchain.agents import initialize_agent from langchain.agents import AgentType
3-4. Caching
- 목적
- 동일한 완료를 여러 번 자주 요청하는 경우 LLM에 대한 API 호출 수를 줄임으로써 비용을 절약
- LLM 공급자에 대한 API 호출 수를 줄임으로써 애플리케이션 속도를 높힘
-
예제 기본 설정
import langchain from langchain.llms import OpenAI # To make the caching really obvious, lets use a slower model. llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2) -
In Memory Cache
-
from langchain.cache import InMemoryCache사용from langchain.cache import InMemoryCache langchain.llm_cache = InMemoryCache() # The first time, it is not yet in cache, so it should take longer llm.predict("Tell me a joke") # The second time it is, so it goes faster llm.predict("Tell me a joke") -
결과
첫 번째 CPU times: user 35.9 ms, sys: 28.6 ms, total: 64.6 ms Wall time: 4.83 s 두 번째 CPU times: user 238 µs, sys: 143 µs, total: 381 µs Wall time: 1.76 ms
-
-
SQLite Cache
- from langchain.cache import SQLiteCache
- DB에도 사용 가능
from langchain.cache import SQLiteCache langchain.llm_cache = SQLiteCache(database_path=".langchain.db")
3-5. 토큰 사용 추적
-
중요해 보임. 모델이 여러개거나 DB를 활용할 경우 비용이 어떻게 산출 되는 건지 모르겠음 -> 서비스를 운영한다면 금액 산정이 매우 중요하기 때문에 필수로 해봐야하는 것으로 보임.
-
기본 설정
from langchain.llms import OpenAI from langchain.callbacks import get_openai_callback -
예제
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2) with get_openai_callback() as cb: result = llm("Tell me a joke") print(cb) # 결과 Tokens Used: 42 Prompt Tokens: 4 Completion Tokens: 38 Successful Requests: 1 Total Cost (USD): $0.00084 -
agent 예제
from langchain.agents import load_tools from langchain.agents import initialize_agent from langchain.agents import AgentType from langchain.llms import OpenAI llm = OpenAI(temperature=0) tools = load_tools(["serpapi", "llm-math"], llm=llm) agent = initialize_agent( tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True ) with get_openai_callback() as cb: response = agent.run( "Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?" ) print(f"Total Tokens: {cb.total_tokens}") print(f"Prompt Tokens: {cb.prompt_tokens}") print(f"Completion Tokens: {cb.completion_tokens}") print(f"Total Cost (USD): ${cb.total_cost}") # 결과 Total Tokens: 1506 Prompt Tokens: 1350 Completion Tokens: 156 Total Cost (USD): $0.03012
4. Chat models
- 기본 설정
pip install openai
- API 키 등록
export OPENAI_API_KEY="..."import os os.environ["OPENAI_API_KEY"] = "..."# 원인을 모르겠지만 테스트 했을 때 안됨. 시도해보고 안되면 위의 방법을 해볼 것 from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(openai_api_key="...")
4-1. 기본 함수 call, generate
-
뒤에 내용이 해당 함수들을 활용하므로 간다한 예제로 어떤 값을 받을 수 있는지 감을 잡는 파트.
-
__call__- 예제
from langchain.schema import ( AIMessage, HumanMessage, SystemMessage ) chat([HumanMessage(content="Translate this sentence from English to French: I love programming.")]) # 출력 : AIMessage(content="J'aime programmer.", additional_kwargs={}) -
generate- 예제
batch_messages = [ [ SystemMessage(content="You are a helpful assistant that translates English to French."), HumanMessage(content="I love programming.") ], [ SystemMessage(content="You are a helpful assistant that translates English to French."), HumanMessage(content="I love artificial intelligence.") ], ] result = chat.generate(batch_messages) result ''' 출력 LLMResult(generations=[[ChatGeneration(text="J'aime programmer.", generation_info=None, message=AIMessage(content="J'aime programmer.", additional_kwargs={}))], [ChatGeneration(text="J'aime l'intelligence artificielle.", generation_info=None, message=AIMessage(content="J'aime l'intelligence artificielle.", additional_kwargs={}))]], llm_output={'token_usage': {'prompt_tokens': 57, 'completion_tokens': 20, 'total_tokens': 77}}) '''
4-3. Caching
- llm과 동일
4-4. LLM Chain
- LLMChain을 사용 가능하다는 것인데, 이후에 LLMChain을 제대로 사용해봐야 감이 올 것 같음.
chain = LLMChain(llm=chat, prompt=chat_prompt)
chain.run(input_language="English", output_language="French", text="I love programming.")5. 참조

도비의 양말을 찾아서