ML Advanced 부동산 실거래가 예측 모델링
Team 역할
팀장, 데이터 수집 및 모델 학습
- Geocoding
- 서울열린데이터광장 데이터 수집
- 한국은행경제통계시스템 데이터 수집
1. Competiton Info
Overview
- House Price Prediction서울의 아파트 실거래가 데이터를 기반으로 아파트 실거래가를 예측하는 대회
- 제공된 데이터뿐만 아니라 외부 데이터를 활용하는 경험
- 다양한 방법론을 실험해보면서 모델의 성능을 높이는 방법과 데이터를 분석을 경험
Timeline
- ex) July 9, 2024 - Start Date
- ex) July 19, 2024 - Final submission deadline
Evaluation
- RMSE (Root Mean Squared Error)
- Public / Private 는 같은 기간 내에서 무작위로 50% 선정

3. Data descrption
Dataset overview
Train Data
- Target : 부동산 실거래가
- Shape : (111822,52)
- Time : 200701 ~ 202306

Test Data
- Target : 부동산 실거래가
- Shape : (9272, 51)
- Time : 202307 ~ 202309

Extra Data
- 지하철역
- 버스정류장
EDA
- Describe your EDA process and step-by-step conclusion
| 항목 | 결측률 (%) |
|---|---|
| 시군구 | 0.000000 |
| 번지 | 0.020122 |
| 본번 | 0.006648 |
| 부번 | 0.006648 |
| 아파트명 | 0.189346 |
| 전용면적(㎡) | 0.000000 |
| 계약년월 | 0.000000 |
| 계약일 | 0.000000 |
| 층 | 0.000000 |
| 건축년도 | 0.000000 |
| 도로명 | 0.000000 |
| 해제사유발생일 | 99.450844 |
| 등기신청일자 | 98.508724 |
| 거래유형 | 96.308552 |
| 중개사소재지 | 96.624306 |
| k-단지분류(아파트,주상복합등등) | 77.765949 |
| k-전화번호 | 77.728452 |
| k-팩스번호 | 77.949887 |
| 단지소개기존clob | 93.871433 |
| k-세대타입(분양형태) | 77.664184 |
| k-관리방식 | 77.664184 |
| k-복도유형 | 77.693348 |
| k-난방방식 | 77.664184 |
| k-전체동수 | 77.760098 |
| k-전체세대수 | 77.664184 |
| k-건설사(시공사) | 77.798215 |
| k-시행사 | 77.815678 |
| k-사용검사일-사용승인일 | 77.676062 |
| k-연면적 | 77.664184 |
| k-주거전용면적 | 77.668173 |
| k-관리비부과면적 | 77.664184 |
| k-전용면적별세대현황(60㎡이하) | 77.668173 |
| k-전용면적별세대현황(60㎡~85㎡이하) | 77.668173 |
| k-85㎡~135㎡이하 | 77.668173 |
| k-135㎡초과 | 99.970836 |
| k-홈페이지 | 89.843843 |
| k-등록일자 | 98.962143 |
| k-수정일자 | 77.668173 |
| 고용보험관리번호 | 81.620592 |
| 경비비관리형태 | 77.791478 |
| 세대전기계약방법 | 78.485392 |
| 청소비관리형태 | 77.808321 |
| 건축면적 | 77.677835 |
| 주차대수 | 77.677658 |
| 기타/의무/임대/임의=1/2/3/4 | 77.664184 |
| 단지승인일 | 77.728806 |
| 사용허가여부 | 77.664184 |
| 관리비 업로드 | 77.664184 |
| 좌표X | 77.673669 |
| 좌표Y | 77.673669 |
| 단지신청일 | 77.669680 |
| target | 0.821917 |
| is_test | 0.000000 |
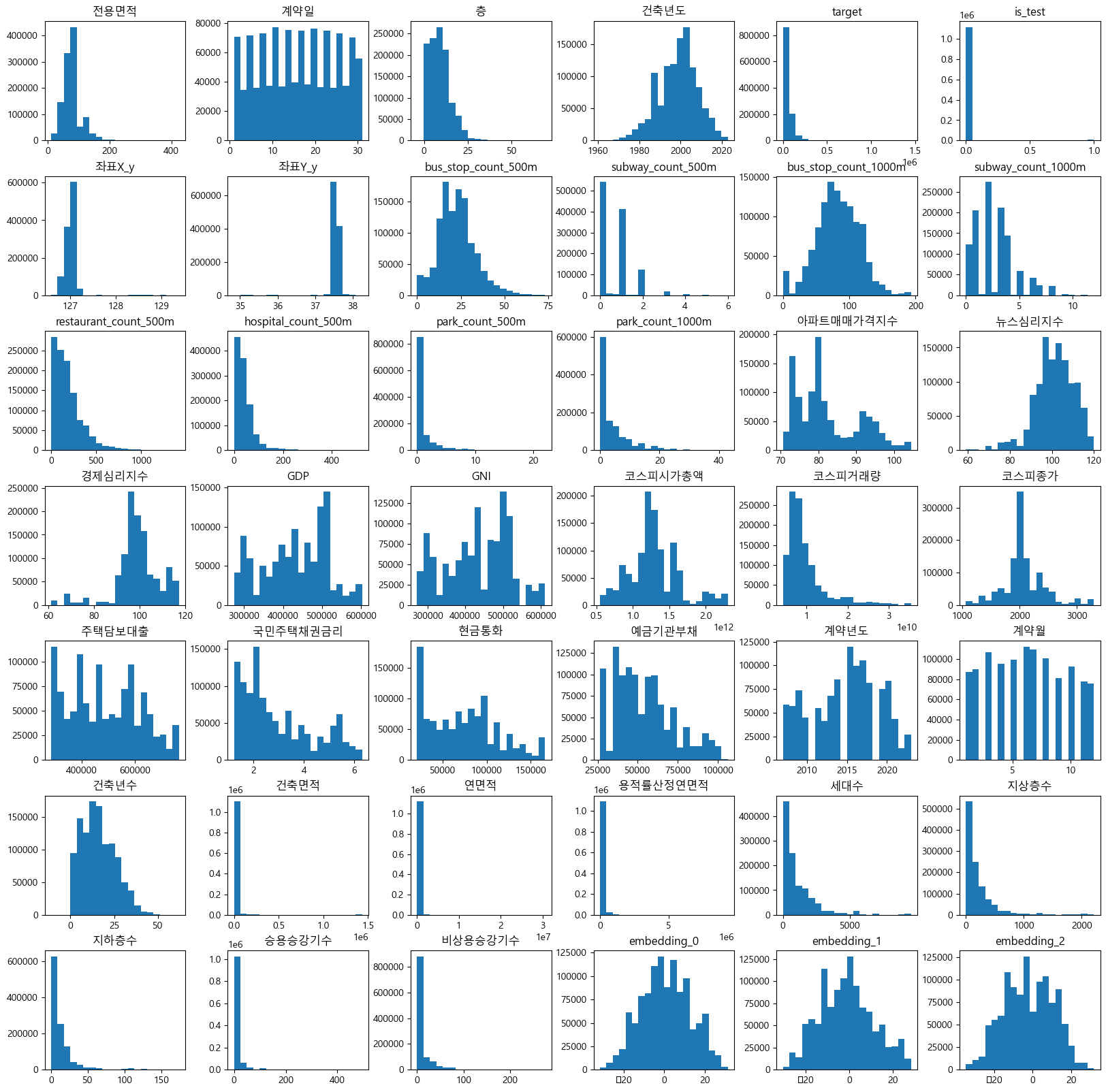
결측치가 매우 많은 데이터셋의 모습 -> 외부데이터를 통해 파생변수의 생성이 필요
좌표 X와 좌표 Y colum의 결측치를 Geocoding을 통해 채워넣기
브이월드



서울열린데이터광장

한국은행경제통계시스템
Feature engineering
파생변수 생성
- 시군구 Feature에 대해 '구', '동' 변수를 추출하여 Label Encoding
- 계약년월 Feature에 대해 계약년도, 계약월 feature 생성
- 계약년도 - 건축년도 = 아파트 년수 Feature 생성
- 도로명 주소에 대해 Ko-GPT2 기반의 문장 Encoding 을 통해 786개의 벡터열을 생성하고 T-SNE로 축소하여 3개의 Enbedding Vector를 생성
외부데이터 활용
을 통해 외부데이터를 끌어와서 도로명주소와 계약년월 데이터를 기반으로 결합
X, Y 좌표를 활용해서 아파트 주변 버스, 지하철, 음싞점, 병원, 공원에 대해 500m, 1000m 내에 위치한 숫자를 변수로 생성
결합한 데이터셋
| 번호 | 열 이름 |
|---|---|
| 1 | 아파트명 |
| 2 | 전용면적 |
| 3 | 계약일 |
| 4 | 층 |
| 5 | 건축년도 |
| 6 | target |
| 7 | 좌표X_y |
| 8 | 좌표Y_y |
| 9 | bus_stop_count_500m |
| 10 | subway_count_500m |
| 11 | bus_stop_count_1000m |
| 12 | subway_count_1000m |
| 13 | restaurant_count_500m |
| 14 | hospital_count_500m |
| 15 | park_count_500m |
| 16 | park_count_1000m |
| 17 | 아파트매매가격지수 |
| 18 | 뉴스심리지수 |
| 19 | 경제심리지수 |
| 20 | GDP |
| 21 | GNI |
| 22 | 코스피시가총액 |
| 23 | 코스피거래량 |
| 24 | 코스피종가 |
| 25 | 주택담보대출 |
| 26 | 국민주택채권금리 |
| 27 | 현금통화 |
| 28 | 예금기관부채 |
| 29 | 구 |
| 30 | 동 |
| 31 | 계약년도 |
| 32 | 계약월 |
| 33 | 건축년수 |
| 34 | 건축면적 |
| 35 | 연면적 |
| 36 | 용적률산정연면적 |
| 37 | 세대수 |
| 38 | 지상층수 |
| 39 | 지하층수 |
| 40 | 승용승강기수 |
| 41 | 비상용승강기수 |
| 42 | embedding_0 |
| 43 | embedding_1 |
| 44 | embedding_2 |
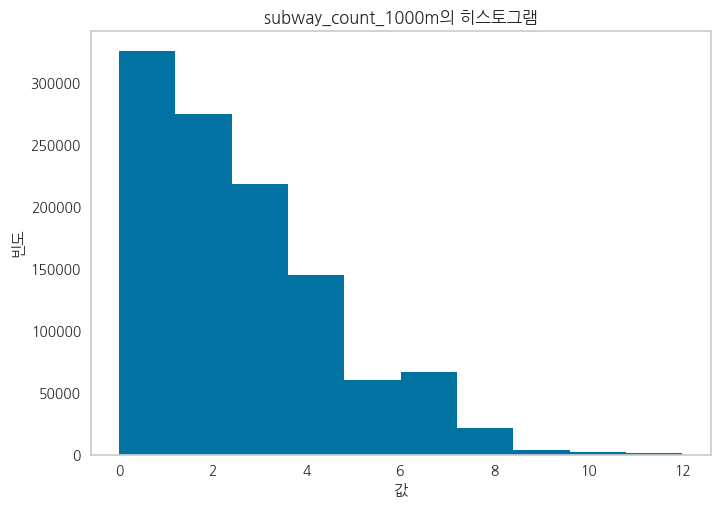
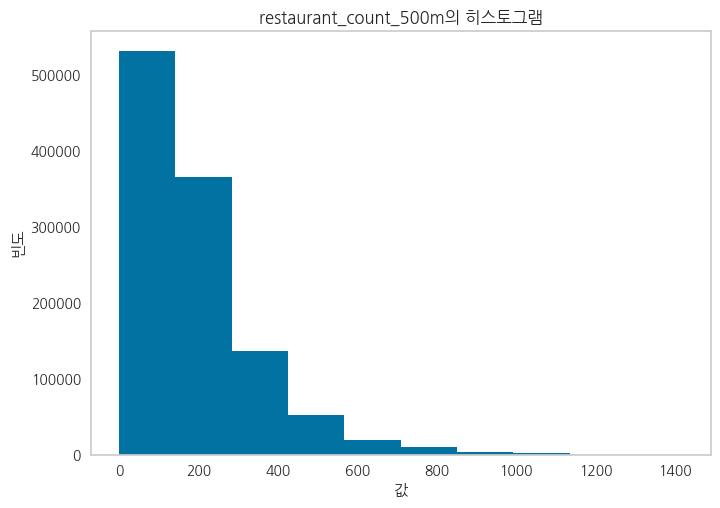
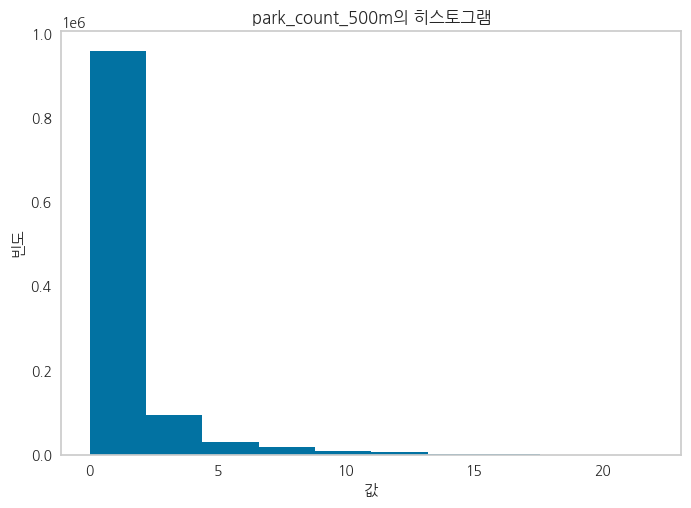
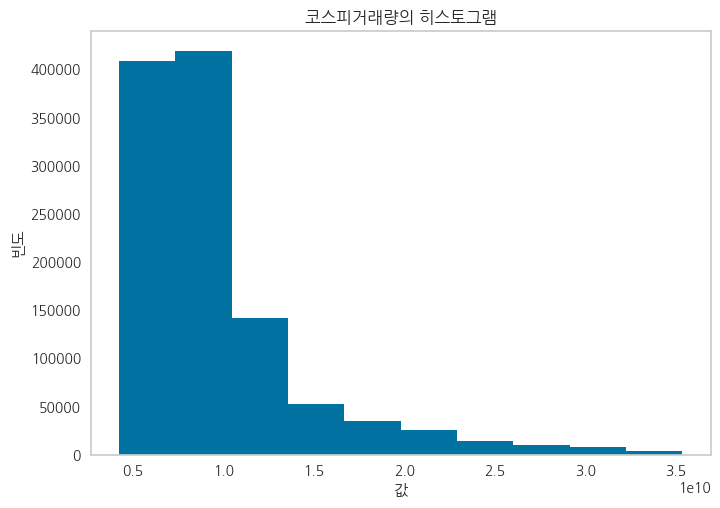
Feature들 중에서 죄편향된 데이터들에 대해 Log1p를 취해준 파생변수를 생성
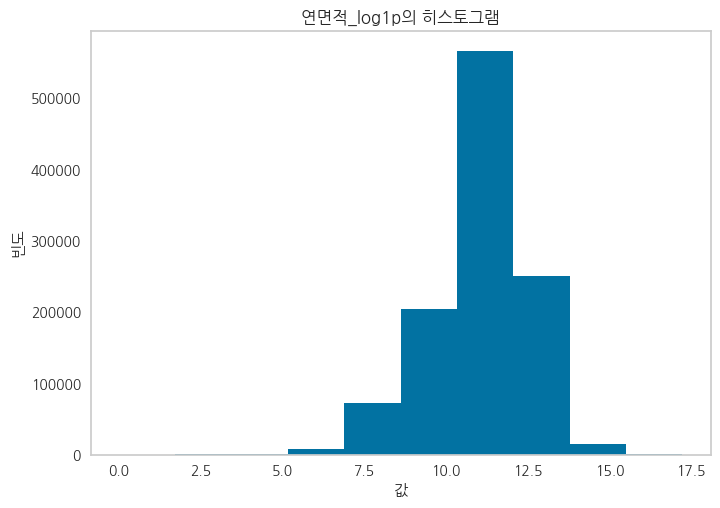
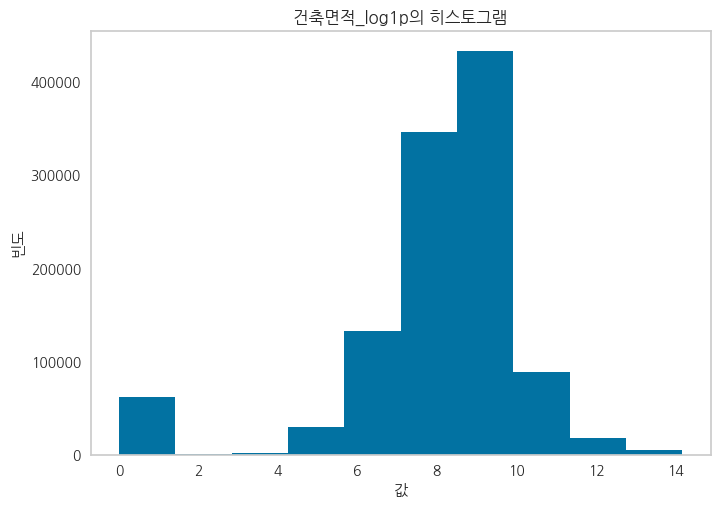
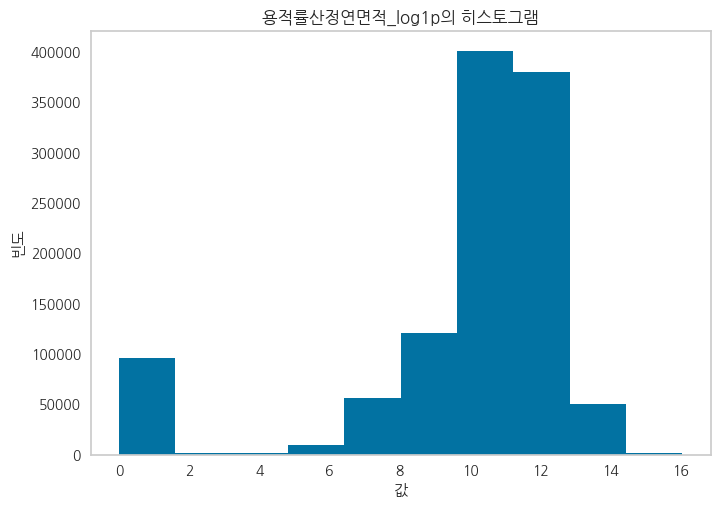
정규분포에 가깝게 변환하여 파생변수를 생성
Target 인코딩
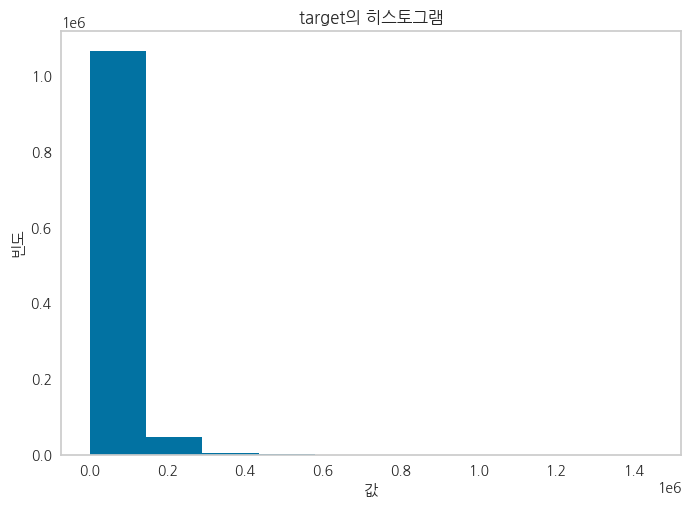
타겟인 실거래가격이 좌편향된 데이터임을 확인
np.log1p 를 통해서 타겟데이터를 인코딩
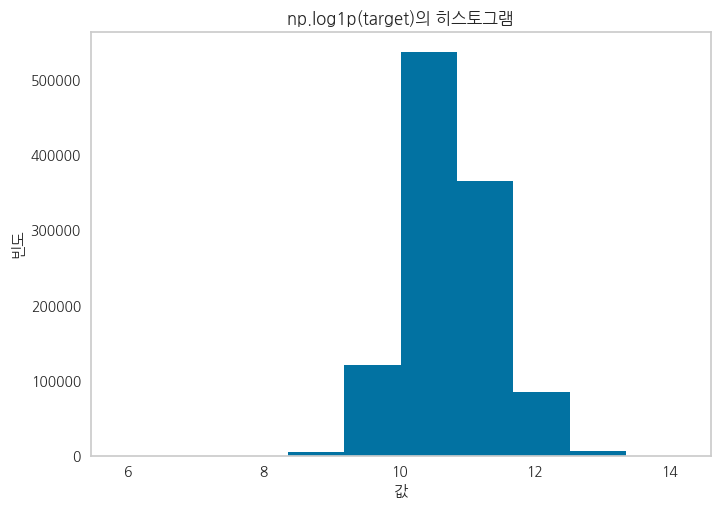
타겟 데이터의 분포를 변형
4. Modeling
Model descrition
최종학습 데이터셋
| 번호 | 열 이름 |
|----|------------------------------|
| 1 | 아파트명 |
| 2 | 전용면적 |
| 3 | 계약일 |
| 4 | 층 |
| 5 | 건축년도 |
| 6 | target |
| 7 | 좌표X_y |
| 8 | 좌표Y_y |
| 9 | bus_stop_count_500m |
| 10 | subway_count_500m |
| 11 | bus_stop_count_1000m |
| 12 | subway_count_1000m |
| 13 | restaurant_count_500m |
| 14 | hospital_count_500m |
| 15 | park_count_500m |
| 16 | park_count_1000m |
| 17 | 아파트매매가격지수 |
| 18 | 뉴스심리지수 |
| 19 | 경제심리지수 |
| 20 | GDP |
| 21 | GNI |
| 22 | 코스피시가총액 |
| 23 | 코스피거래량 |
| 24 | 코스피종가 |
| 25 | 주택담보대출 |
| 26 | 국민주택채권금리 |
| 27 | 현금통화 |
| 28 | 예금기관부채 |
| 29 | 구 |
| 30 | 동 |
| 31 | 계약년도 |
| 32 | 계약월 |
| 33 | 건축년수 |
| 34 | 건축면적 |
| 35 | 연면적 |
| 36 | 용적률산정연면적 |
| 37 | 세대수 |
| 38 | 지상층수 |
| 39 | 지하층수 |
| 40 | 승용승강기수 |
| 41 | 비상용승강기수 |
| 42 | embedding_0 |
| 43 | embedding_1 |
| 44 | embedding_2 |
| 45 | bus_stop_count_500m_log1p |
| 46 | subway_count_500m_log1p |
| 47 | bus_stop_count_1000m_log1p |
| 48 | subway_count_1000m_log1p |
| 49 | restaurant_count_500m_log1p |
| 50 | hospital_count_500m_log1p |
| 51 | park_count_500m_log1p |
| 52 | park_count_1000m_log1p |
| 53 | GDP_log1p |
| 54 | GNI_log1p |
| 55 | 코스피시가총액_log1p |
| 56 | 코스피거래량_log1p |
| 57 | 코스피종가_log1p |
| 58 | 주택담보대출_log1p |
| 59 | 현금통화_log1p |
| 60 | 예금기관부채_log1p |
| 61 | 건축면적_log1p |
| 62 | 연면적_log1p |
| 63 | 용적률산정연면적_log1p |
| 64 | 세대수_log1p |
| 65 | 지상층수_log1p |
| 66 | 지하층수_log1p |
| 67 | 승용승강기수_log1p |
| 68 | 비상용승강기수_log1p |
Modeling Process
- Write model train and test process with capture
pycaret 라이브러리를 통해 데이터셋에 대해 AutoML을 진행
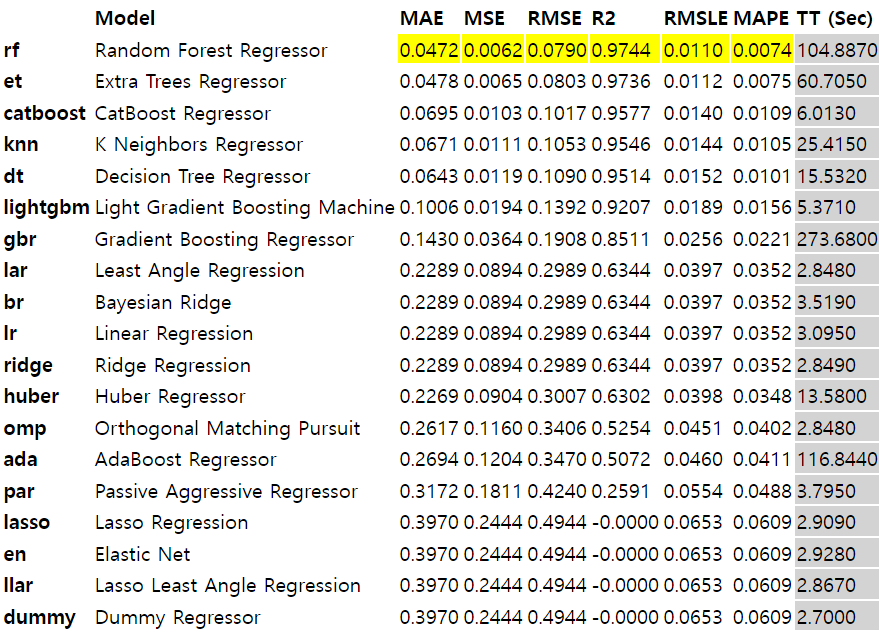
Random Forest Regressor
Extra Trees Regressor
CatBoost Regressor
가 좋은 성능을 보이는 것을 확인
optuna를 통해 각 모델에 대해 하이퍼파라미터를 튜닝
각 모델별로 모델을 생성하여 제출후 리더보드 성적을 확인
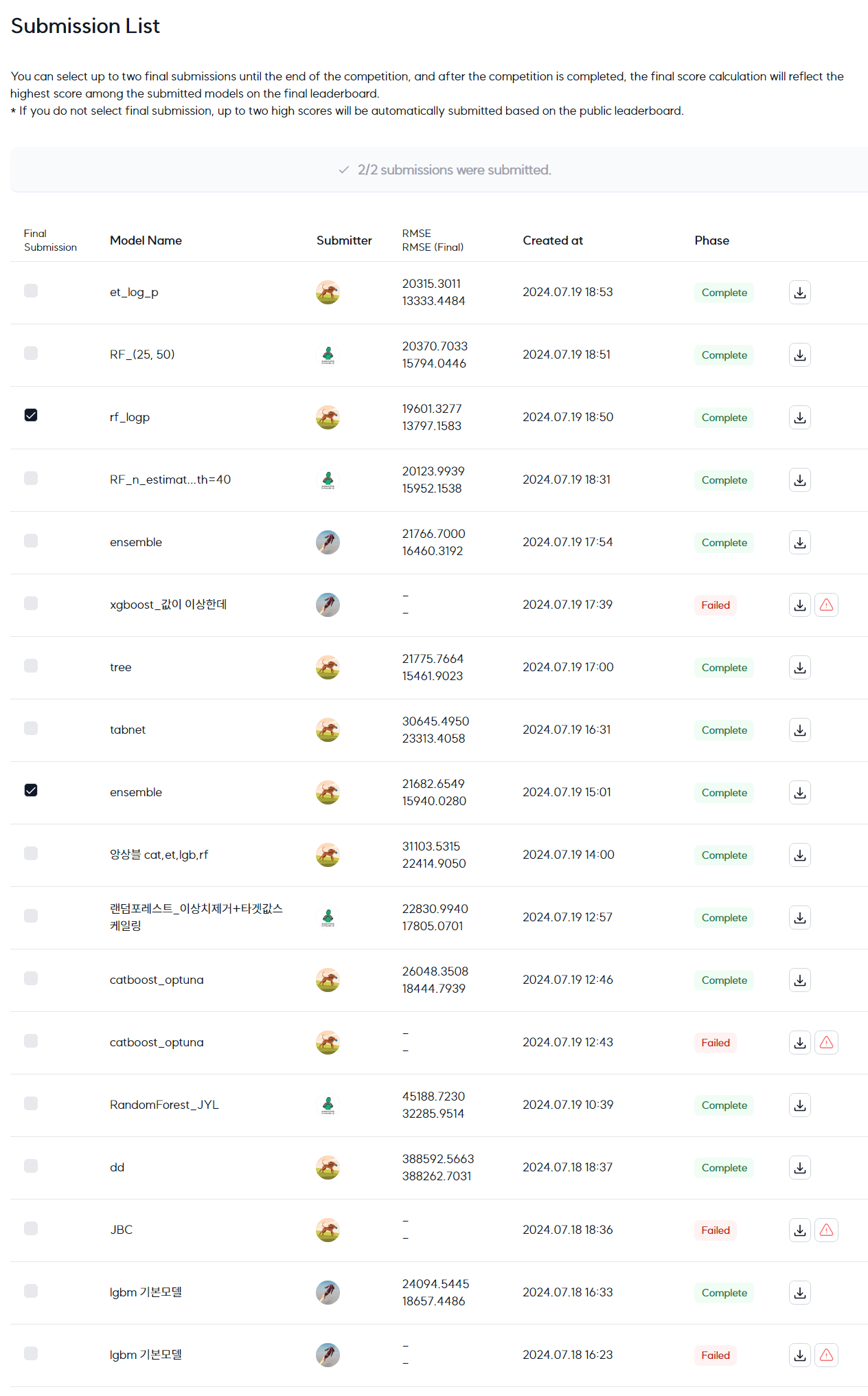
모델을 앙상블 한 것보다 Extra Trees Regressor 모델 단독으로 사용했을 때 가장 좋은 결과를 나타냄
5. Result
Feature Importance
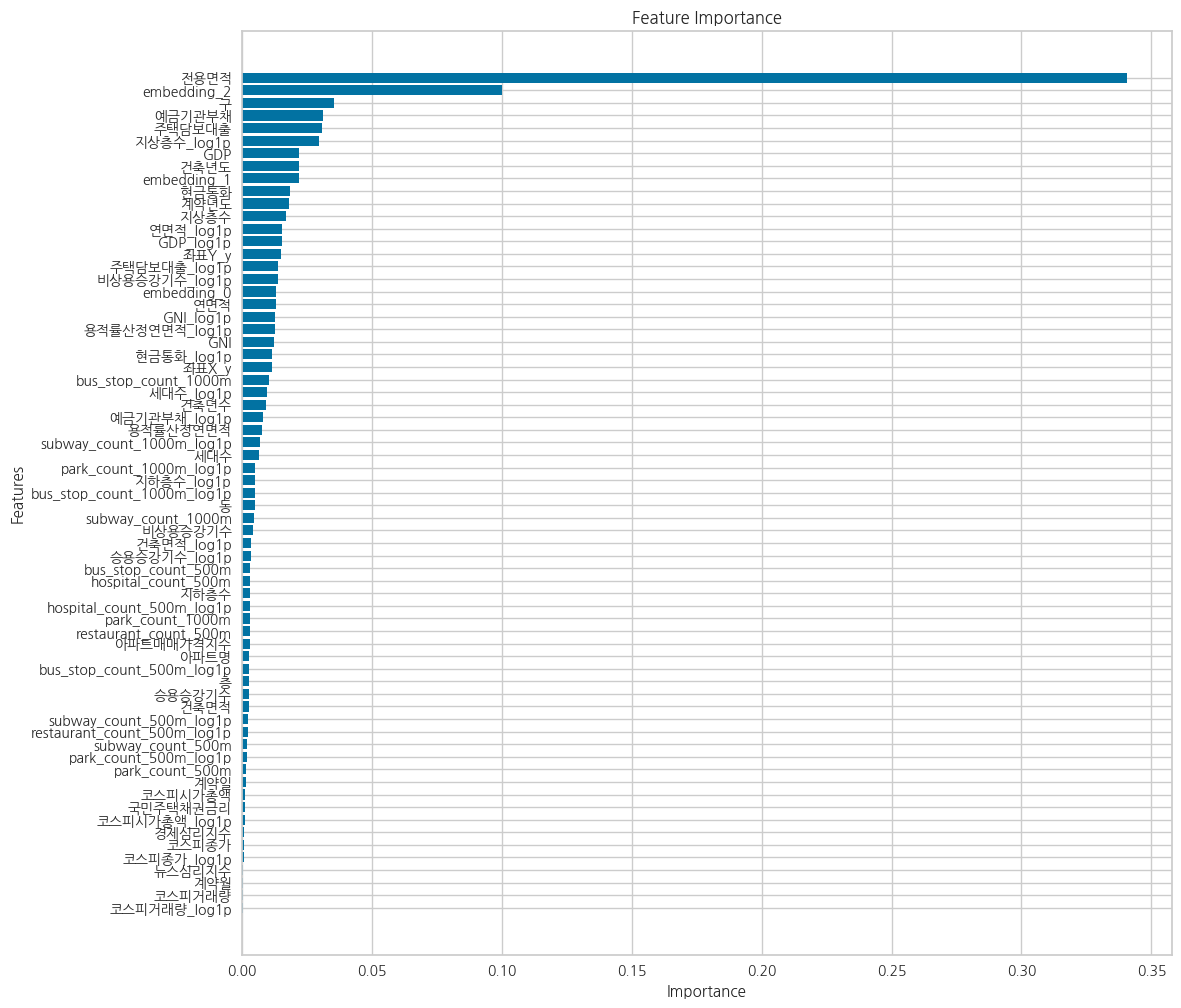
전용면적 , 구, 도로명 임베딩, 부채, 대출, 층수, GDP, 건축년도 데이터 등이 높은 중요도의 변수로 나타남
Leader Board
Public
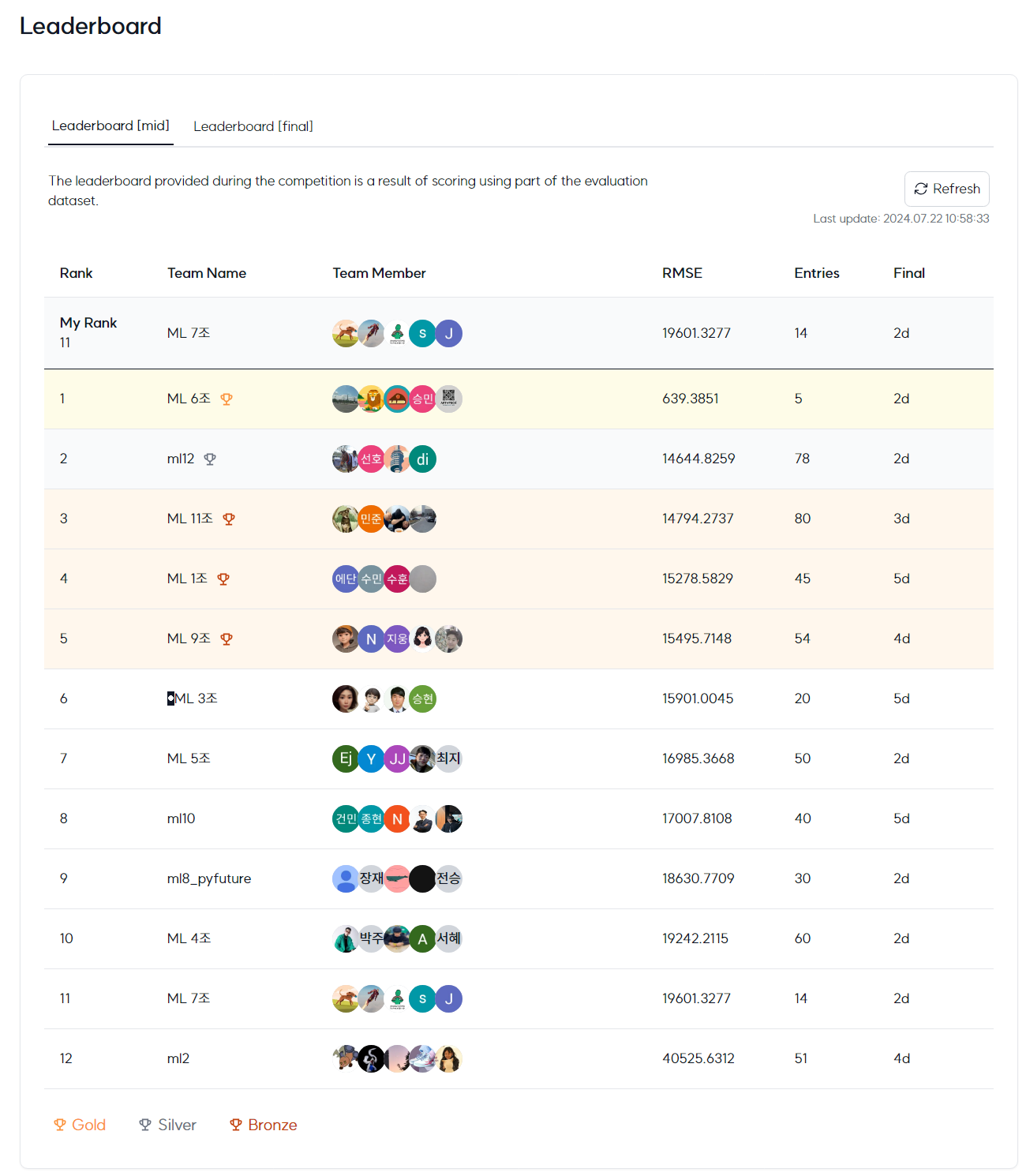
12조 중 11등
Private
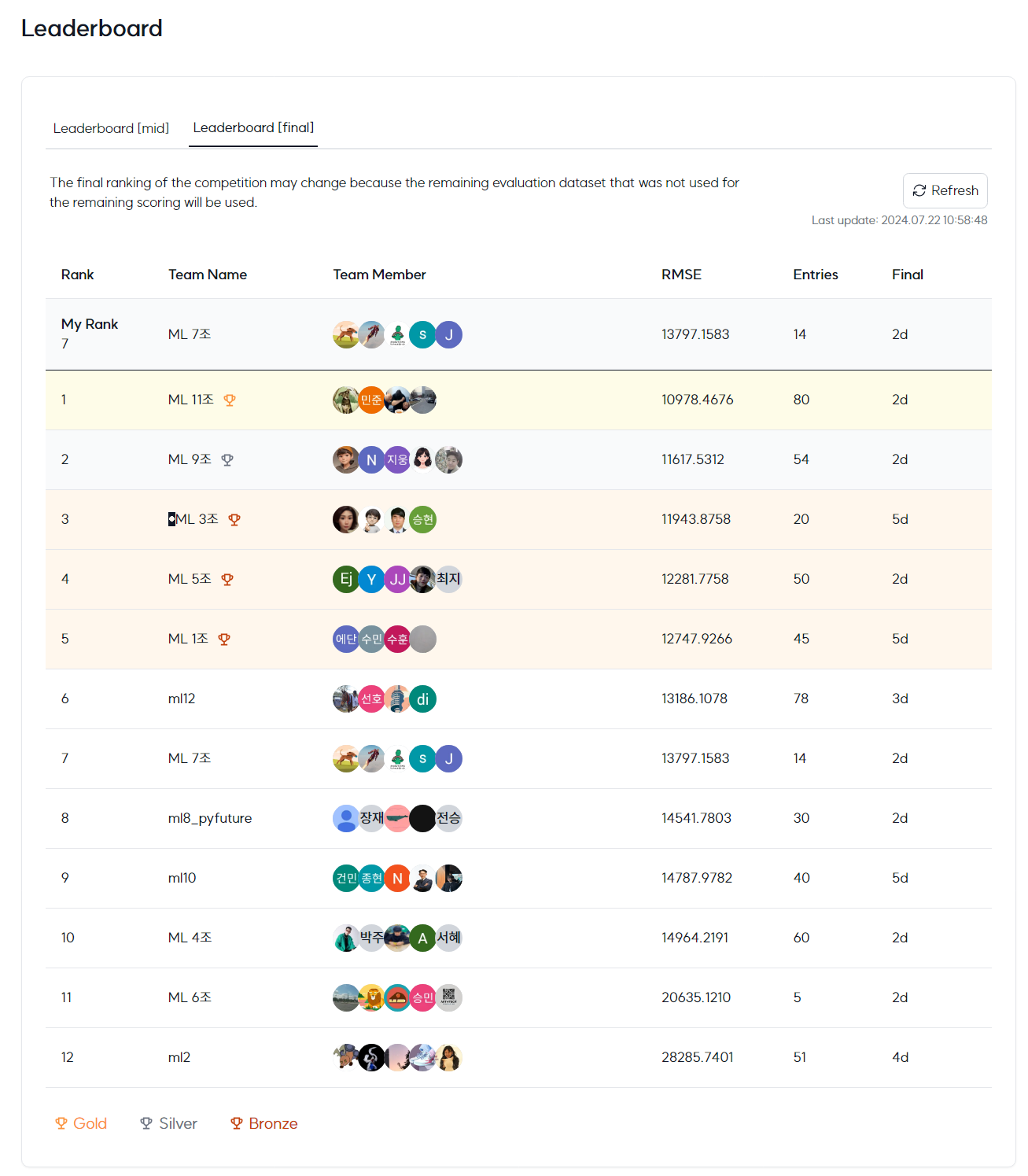
12조 중 7등
으로 Private에서의 일반화 성능이 더 뛰어나게 나온 것으로 확인
Presentation
경진대회 소감
이번 부동산 실거래가 예측 모델링 경진대회는 저에게 매우 값진 경험이었습니다. 다양한 데이터 소스와 모델링 기법을 활용해 실제 문제를 해결해보는 과정에서 많은 것을 배울 수 있었습니다.
데이터 수집 및 전처리의 중요성
처음 데이터를 수집하고 전처리하는 과정에서 많은 어려움이 있었습니다. 특히, 결측치가 많은 데이터셋을 다루면서 외부 데이터를 통해 파생 변수를 생성하는 과정은 매우 도전적이었습니다. 서울열린데이터광장과 한국은행경제통계시스템 등의 외부 데이터를 활용하여 기존 데이터셋을 보완하고, 지오코딩을 통해 좌표 데이터를 채워 넣는 작업은 데이터의 질을 높이는 데 큰 도움이 되었습니다.
피처 엔지니어링의 경험
피처 엔지니어링 과정에서 다양한 시도들을 해보았습니다. 계약년월, 건축년도를 바탕으로 아파트 년수 변수를 생성하고, 도로명 주소에 대해 Ko-GPT2를 활용한 문장 인코딩을 통해 임베딩 벡터를 생성하는 작업은 흥미로웠습니다. 또한, 주변 시설 정보(버스정류장, 지하철역, 음식점, 병원, 공원 등)를 활용하여 파생 변수를 만드는 과정에서 공간 데이터를 어떻게 활용할 수 있는지를 깊이 이해할 수 있었습니다.
모델링 및 하이퍼파라미터 튜닝
모델링 과정에서는 PyCaret 라이브러리를 사용하여 다양한 모델을 자동으로 비교하고 최적의 모델을 찾는 방법을 사용했습니다. Random Forest Regressor, Extra Trees Regressor, CatBoost Regressor 모델이 우수한 성능을 보였고, Optuna를 통해 각 모델의 하이퍼파라미터를 튜닝하는 과정도 매우 유익했습니다. 최종적으로 Extra Trees Regressor 모델이 가장 좋은 성능을 보여주었고, 이를 통해 예측 정확도를 높일 수 있었습니다.
성과와 리더보드 결과
공공 리더보드에서는 12조 중 11등을 기록했지만, 프라이빗 리더보드에서는 12조 중 7등을 기록하며 일반화 성능이 더 뛰어남을 확인할 수 있었습니다. 이는 모델의 일반화 성능을 높이는 것이 중요함을 다시 한번 깨닫게 해주었습니다.
팀워크와 협업
이번 대회에서 팀원들과의 협업은 매우 중요했습니다. 데이터 수집, 전처리, 모델링 등 각 과정에서 역할을 분담하고, 서로의 의견을 공유하며 더 나은 결과를 도출할 수 있었습니다. 특히, 팀장의 리더십 아래 모든 팀원이 각자의 역할을 충실히 수행한 덕분에 성공적으로 프로젝트를 마칠 수 있었습니다.
마무리
경진대회를 통해 얻은 가장 큰 수확은 실제 문제를 해결하기 위한 데이터 분석과 모델링 과정을 체계적으로 경험해본 것입니다. 이 과정에서 겪은 어려움과 해결 방법들은 앞으로의 데이터 분석 및 모델링 작업에 큰 자산이 될 것입니다. 또한, 다양한 데이터 소스와 방법론을 활용하여 문제를 해결하는 경험은 매우 값진 교훈이었습니다.
이번 경험을 바탕으로 앞으로 더 나은 데이터 분석가로 성장할 수 있도록 노력하겠습니다. 이번 대회를 준비하고 진행하면서 도와주신 모든 분들께 감사드립니다.
