GBM : Gradient Boosting Machine
-
Classification 뿐만 아니라 Refression에서도 사용 가능
-
족보 : GBM -> XGB -> LGBM -> CATB -> NGB
머신러닝에서 Gradient Boosting 모델은 많은 발전을 이루어왔습니다. Adaboost, GBM, XGBoost, LightGBM, 그리고 CATBoost에 이어 더 진보한 모델들도 등장했습니다.
AdaBoost vs GBM
- Adaboost는 잘못 예측한 데이터에 가중치를 부여
- GBM은 잔차를 학습
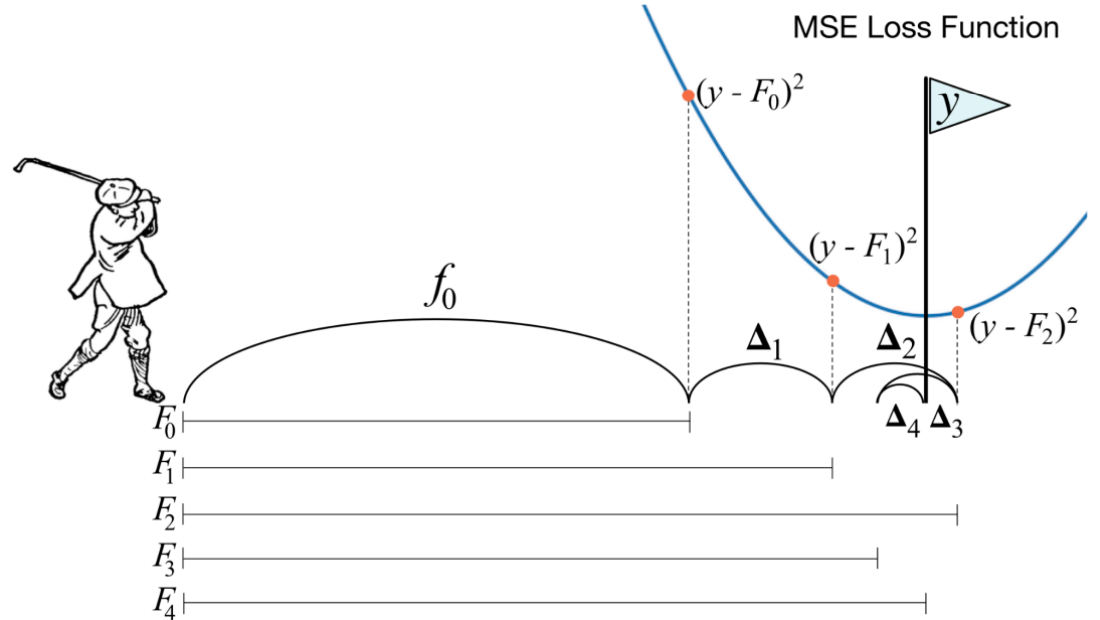
Gradient Boosting Maching
Main Idea : Residual to Zero
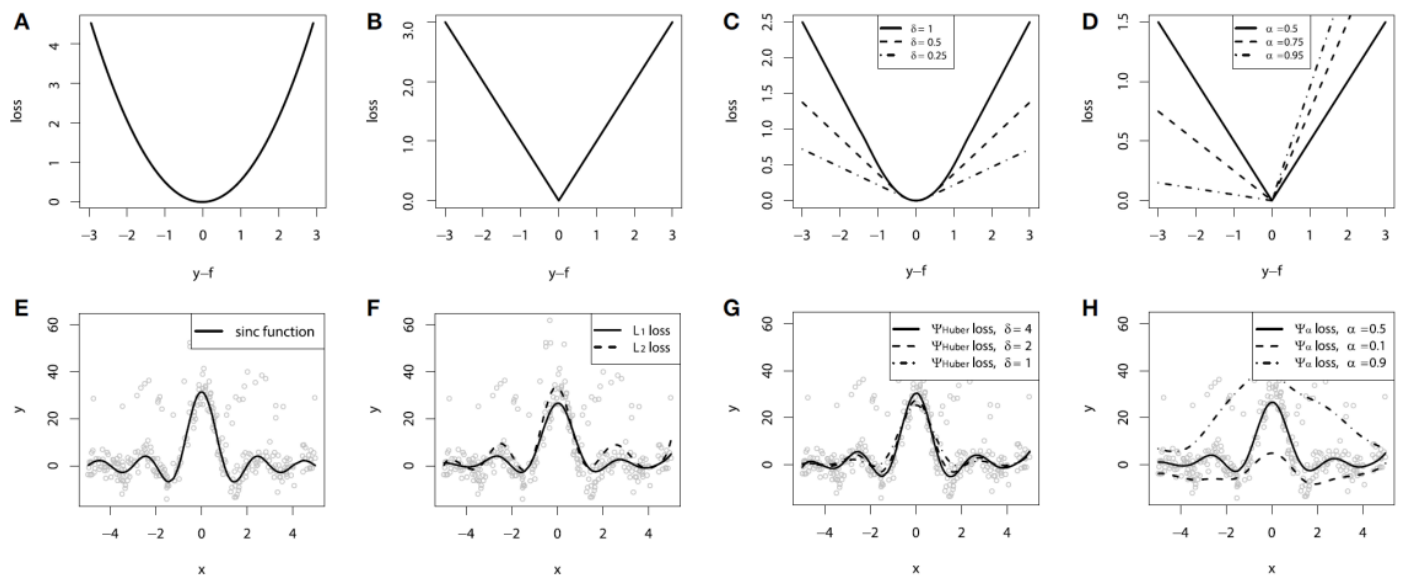
Loss Function for Regression

| Squared Loss | Absolute Loss | Huber Loss | Quantile Loss |
|---|---|---|---|
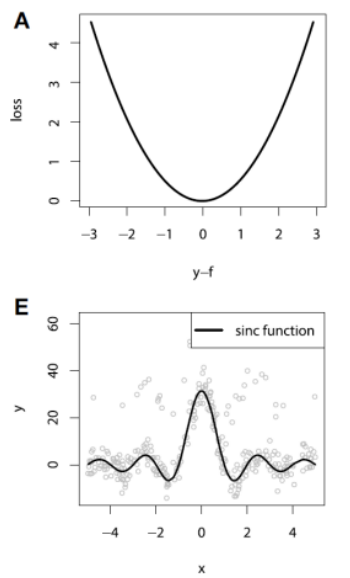 | 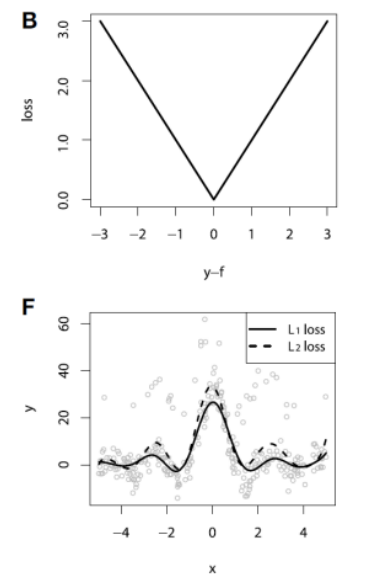 |  | 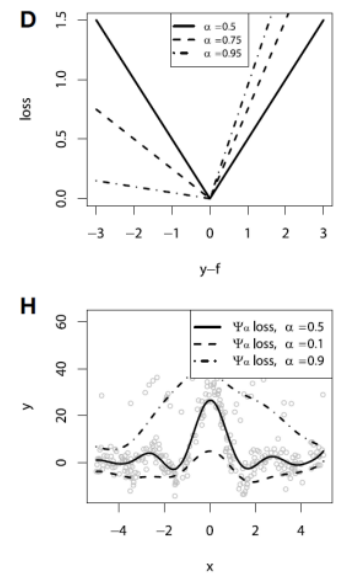 |
Loss Function for Regression

| Bernoulli Loss | Adaboost Loss |
|---|---|
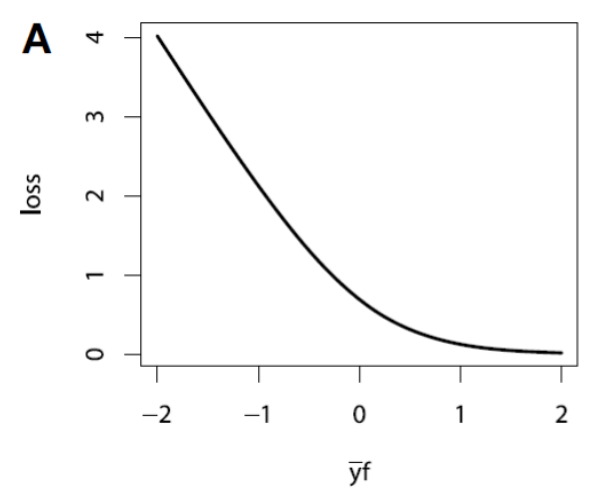 | 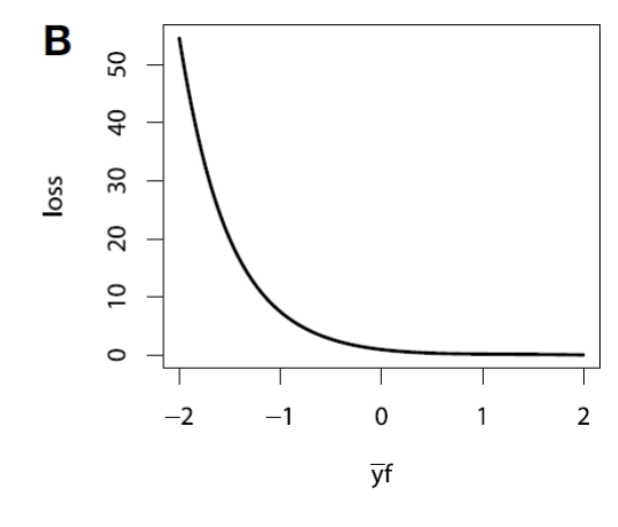 |
Gradient Decent
- Gradient Descent 활용 Loss Function을 Minimize 함
Overfitting 방지
- Gradient Descent를 활용하면서 GBM 모델에 overfitting 문제가 생길 수 있음
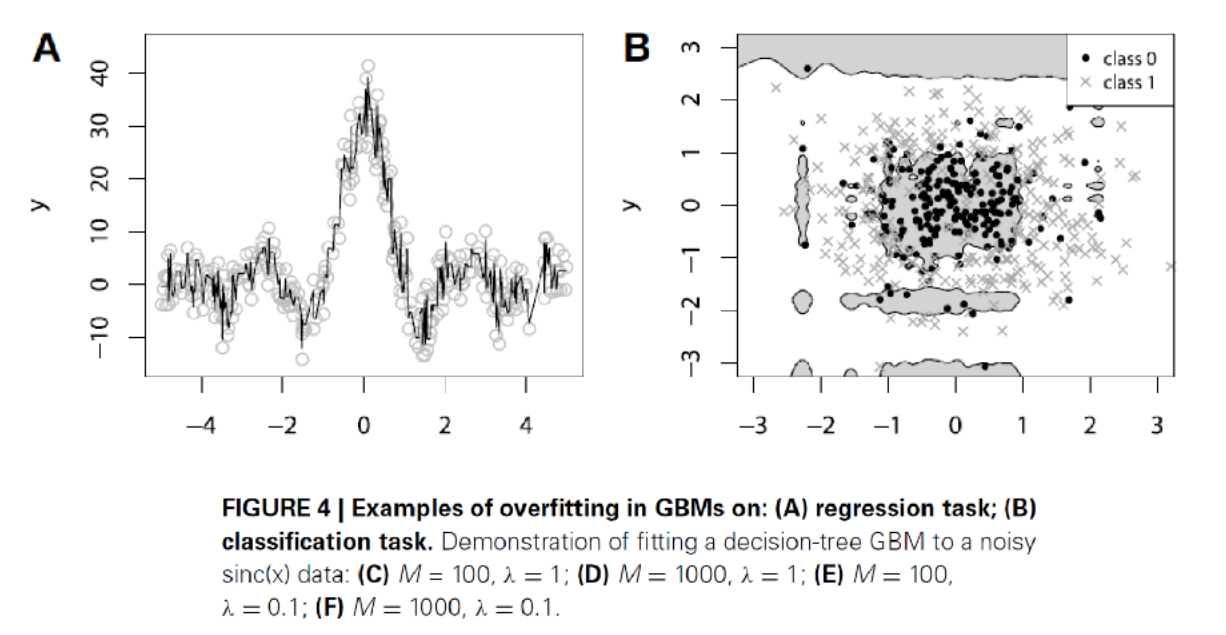
Subsampling : 복원추출이 아닌 just sampling하여 iteration마다 data를 sampling 하게 한다.
bagging : bootstrap + Aggregating도 가능함
Shrinkage
-
Using for Reduction/Shrinking the impact of each additional fitted base-leaners (Penalty Term이랑 비슷한 개념, 조금만 반영하기 !)
-
Better to improve a model by taking many small steps than by taking fewer large steps
-
추가로 장착된 각 base-leaners의 영향을 감소/축소하는 데 사용(벌점 용어 이랑 비슷한 개념, 조금만 반영하기!)
-
큰 단계를 적게 밟는 것보다 작은 단계를 많이 밟아 모형을 개선하는 것이 더 좋습니다
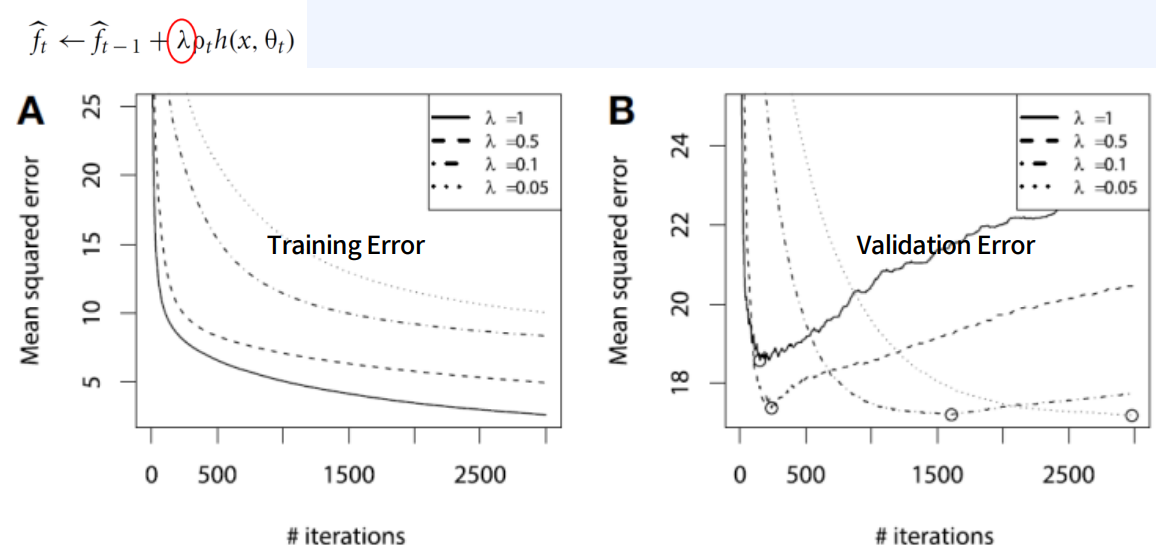
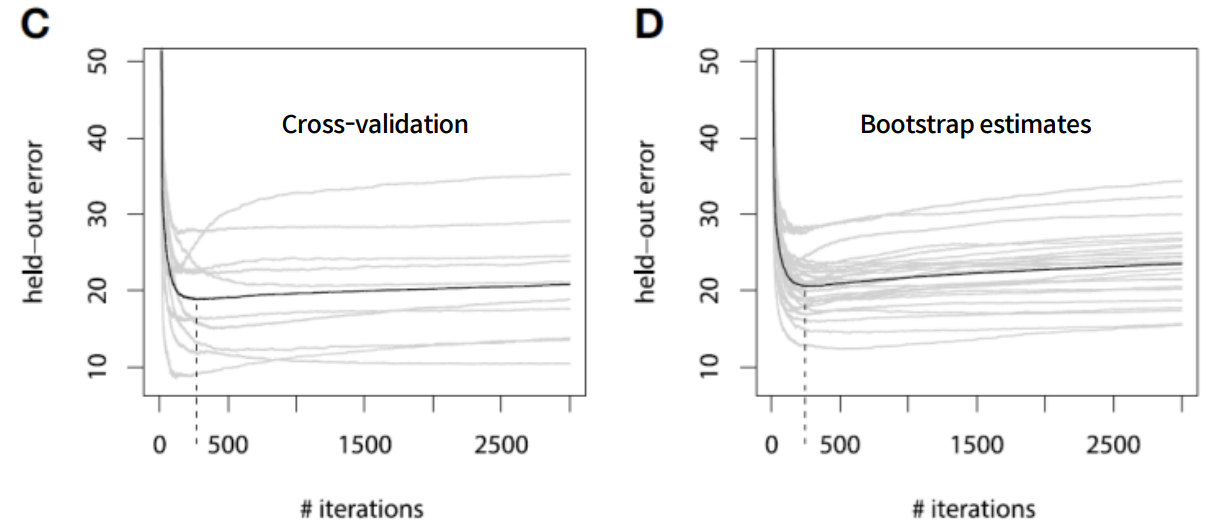
Early Stopping
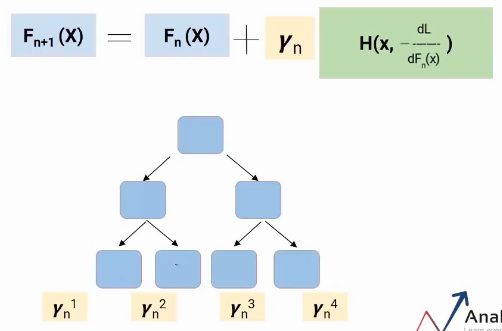
Feature Importance Score
- 𝑰𝒏𝒇𝒍𝒖𝒆𝒏𝒄𝒆𝒋(𝑻) : Single Tree인 T의 j 번째 Feature
※ L이 Terminal nodes라고 가정 했을 때 L-1 splits, IG : Information Gain
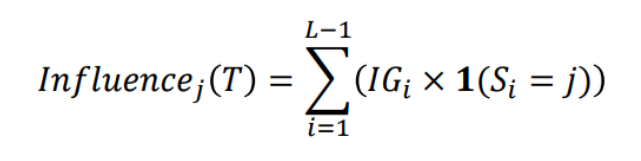
※ Feature importance of GBM
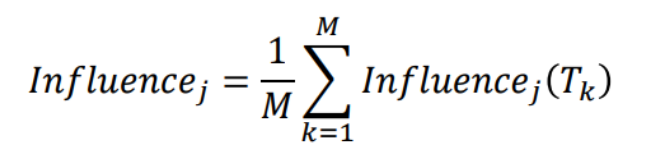
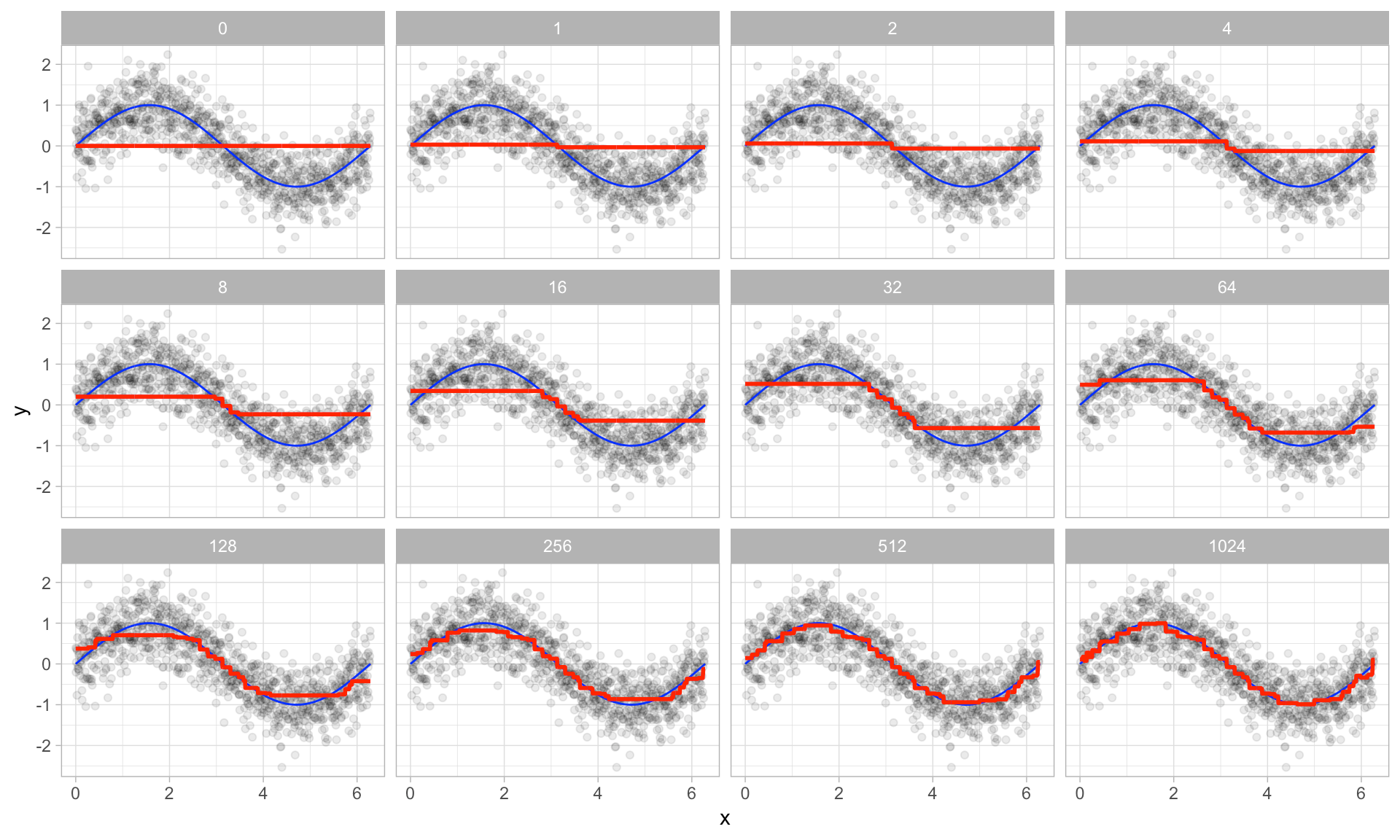
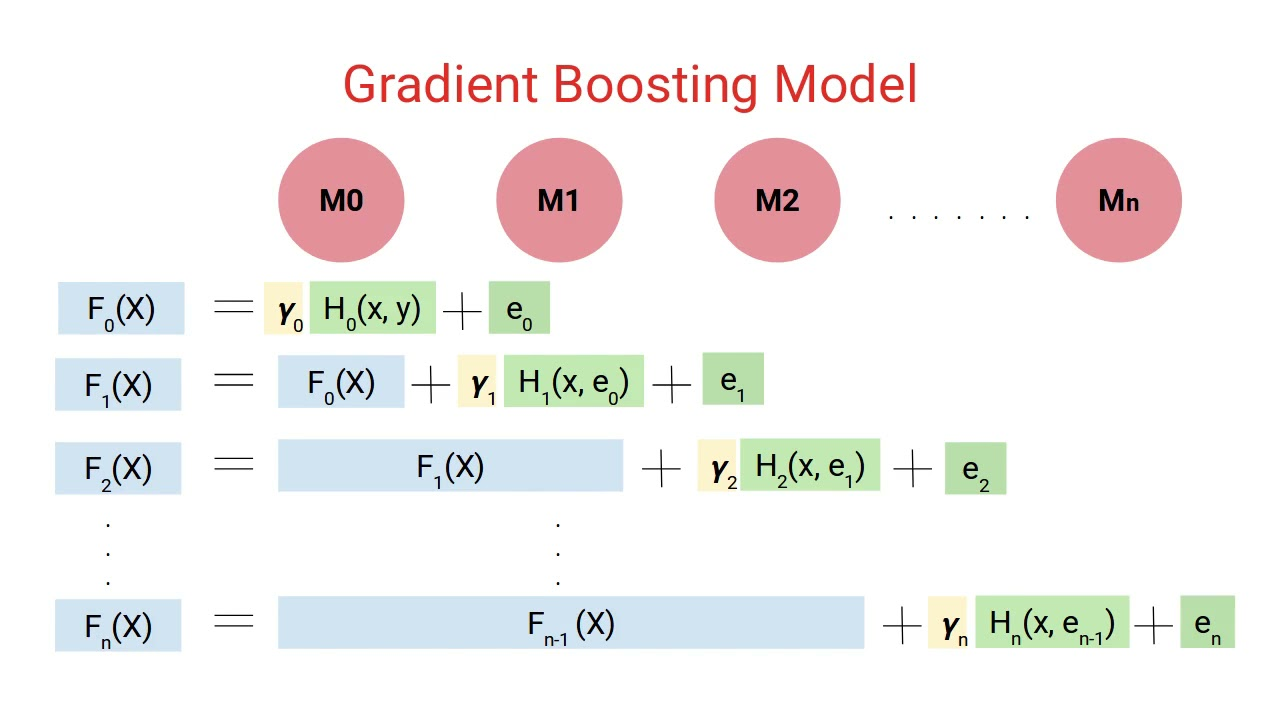
GBM의 Step

Step1
- Tree가 아닌 하나의 Single Leaf 부터 시작함 -> 이 leaf는 Target(Y)에 대한 초기 추정값
- Target(Y)의 초기 추정값은 모든 Target의 평균 값으로 Setting 함
Step2
- Residual(잔차)을 예측하는 Decision Tree 를 Modeling함
- Terminal Node에 두 개 이상의 Residual 값이 있는 경우 평균으로 치환하여 넣어주게 됨
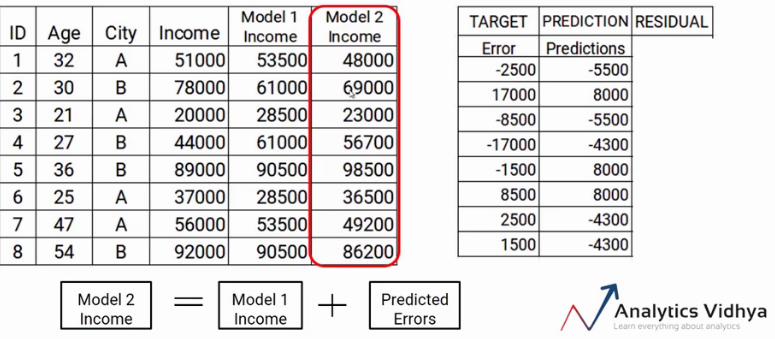
Step3
- Average Weight(Single Leaf) + Predicted Residual
- 이렇게 하게 되면 1개의 Tree로 Residual이 거의 0으로 수렴하기 때문에 Overfitting이 일어날 수 있음
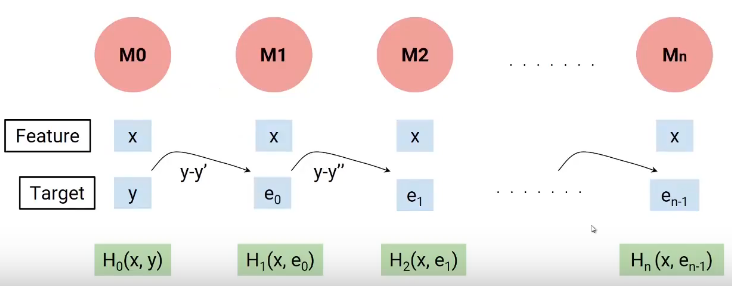
Step4
- Overfitting을 방지하기 위해 Shrinkage(Learning Rate)을 사용함 -> 학습한 Residual을 조금씩만 반영하겠다는 의미 (Penalty 개념)
- Shrinkage(Learning Rate) = 0~1
Loss Function
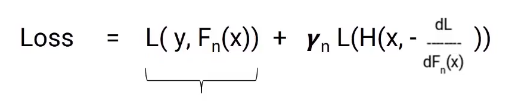
Gradient Boosting Decision Tree
다양한 분류모델
1. NGBoost (Natural Gradient Boosting)
- 특징: NGBoost는 분포 예측(Probabilistic Prediction)을 위해 설계된 부스팅 알고리즘입니다. NGBoost는 점 예측(point prediction) 대신 확률 분포를 예측합니다. 이를 통해 예측 불확실성을 정량화할 수 있습니다.
- 장점: 예측의 불확실성을 포함한 출력이 가능하며, 다양한 손실 함수와 확률 분포를 쉽게 적용할 수 있습니다.
2. Optuna
- 특징: Optuna는 하이퍼파라미터 최적화를 위한 소프트웨어 프레임워크입니다. 부스팅 모델과 결합하여 더 나은 성능을 끌어낼 수 있습니다.
- 장점: 사용자 정의 목적 함수를 최적화하고, 베이지안 최적화 방법을 사용하여 효율적으로 최적의 하이퍼파라미터를 찾습니다.
3. CatBoost의 최신 버전
- 특징: CatBoost는 카테고리형 데이터를 처리하는 데 특화된 부스팅 알고리즘입니다. 최신 버전은 더 나은 성능과 안정성을 제공하며, CPU 및 GPU 병렬 처리를 최적화합니다.
- 장점: 데이터 전처리 과정이 줄어들고, 높은 정확도와 빠른 학습 속도를 제공합니다.
4. TF-Boost
- 특징: TF-Boost는 TensorFlow를 기반으로 한 부스팅 알고리즘입니다. TensorFlow의 강력한 딥러닝 기능을 부스팅 모델에 통합하여 더 높은 성능을 발휘합니다.
- 장점: 딥러닝과의 결합을 통해 복잡한 패턴을 학습할 수 있으며, 분산 학습 및 GPU 가속을 활용할 수 있습니다.
5. Blended Models (Ensemble of Ensembles)
- 특징: 여러 부스팅 모델을 결합하여 더 높은 성능을 도출하는 앙상블 방법입니다. 예를 들어, XGBoost, LightGBM, CatBoost의 예측 결과를 결합하여 최종 예측을 만듭니다.
- 장점: 다양한 모델의 장점을 결합하여 더 높은 정확도와 일반화 성능을 얻을 수 있습니다.
6. DeepGBM
- 특징: 딥러닝과 Gradient Boosting의 장점을 결합한 모델입니다. 신경망의 특성을 활용하여 복잡한 비선형 관계를 학습하면서도, Gradient Boosting의 강력한 성능을 유지합니다.
- 장점: 높은 표현력과 유연성을 제공하며, 구조적인 데이터뿐만 아니라 이미지, 텍스트 등 다양한 형태의 데이터를 처리할 수 있습니다.
7. HistGradientBoosting
- 특징: 사이킷런(sklearn)에서 제공하는 히스토그램 기반 Gradient Boosting 알고리즘입니다. LightGBM의 아이디어를 기반으로 하여 구현되었습니다.
- 장점: 매우 빠른 학습 속도를 제공하며, 큰 데이터셋에서도 효율적으로 작동합니다. 카테고리형 변수와 결측값 처리가 용이합니다.
8. EFB (Exclusive Feature Bundling)
- 특징: LightGBM의 주요 기술 중 하나로, 상호 배타적인(Exclusive) 특징들을 번들링하여 모델 학습을 최적화합니다.
- 장점: 고차원의 데이터를 효율적으로 처리할 수 있으며, 메모리 사용량을 줄이고 학습 속도를 개선합니다.
9. TabNet
- 특징: TabNet은 테이블 형식의 데이터를 처리하는 데 특화된 딥러닝 모델입니다. Attention 메커니즘을 활용하여 중요한 특징을 선택하고 가중치를 부여합니다.
- 장점: 높은 설명력과 예측력을 제공하며, 데이터를 효율적으로 처리합니다. Feature Selection이 자동으로 이루어집니다.
10. SN-GM (Self-Normalizing Gradient Method)
- 특징: Gradient Boosting 알고리즘의 변형으로, 학습 과정에서 모델의 복잡성을 자동으로 조절합니다. 자체 정규화(Self-Normalization)를 통해 오버피팅을 방지합니다.
- 장점: 안정적인 학습 과정과 높은 일반화 성능을 제공합니다. 복잡한 하이퍼파라미터 튜닝이 필요하지 않습니다.
11. SNGP (Spectral Normalized Gaussian Process)
- 특징: 불확실성을 추정하는 Gaussian Process를 신경망과 결합한 모델입니다. 모델의 예측 신뢰도를 평가할 수 있습니다.
- 장점: 예측의 불확실성을 정량화할 수 있으며, 고차원 데이터에서도 높은 성능을 발휘합니다.
12. AutoML (Automated Machine Learning)
- 특징: AutoML은 머신러닝 모델의 선택, 하이퍼파라미터 튜닝, 피처 엔지니어링 등을 자동화하여 최적의 모델을 찾아주는 기술입니다. 대표적인 프레임워크로는 H2O.ai, Google AutoML, Auto-sklearn, TPOT 등이 있습니다.
- 장점: 머신러닝 전문가가 아니더라도 고성능 모델을 쉽게 만들 수 있으며, 모델 개발 시간을 크게 단축할 수 있습니다.
13. Wide & Deep Learning
- 특징: Google에서 제안한 모델로, 폭넓은 학습(Wide Learning)과 깊은 학습(Deep Learning)을 결합하여 강력한 성능을 발휘합니다. 폭넓은 학습은 선형 모델을 통해 메모리 기반의 피처를 학습하고, 깊은 학습은 신경망을 통해 복잡한 패턴을 학습합니다.
- 장점: 추천 시스템 및 클릭 예측과 같은 문제에서 높은 성능을 발휘하며, 넓은 범위의 피처와 깊은 피처의 조합을 효과적으로 학습할 수 있습니다.
14. Fastai
- 특징: PyTorch 기반의 고수준 딥러닝 라이브러리로, 복잡한 딥러닝 모델을 쉽게 구현할 수 있도록 도와줍니다. 다양한 데이터 타입과 모델 아키텍처를 지원합니다.
- 장점: 사용이 간편하고, 최첨단 딥러닝 기법들을 쉽게 활용할 수 있으며, 튜토리얼과 문서가 잘 갖추어져 있어 학습 곡선이 완만합니다.
15. TPOT (Tree-based Pipeline Optimization Tool)
- 특징: 유전 알고리즘을 사용하여 최적의 머신러닝 파이프라인을 자동으로 검색합니다. 피처 선택, 모델 선택, 하이퍼파라미터 튜닝 등을 포함한 전체 파이프라인을 자동화합니다.
- 장점: 자동화된 파이프라인 검색을 통해 높은 성능의 모델을 구축할 수 있으며, 다양한 모델과 파이프라인을 시도해볼 수 있습니다.
16. Stacking Ensemble
- 특징: 여러 개의 머신러닝 모델을 결합하여 성능을 향상시키는 방법입니다. 기본 모델(base model)들의 예측 결과를 다시 메타 모델(meta model)에 입력하여 최종 예측을 도출합니다.
- 장점: 다양한 모델의 장점을 결합하여 더 높은 예측 성능을 얻을 수 있으며, 일반화 성능을 향상시킵니다.
17. HyperOpt
- 특징: 하이퍼파라미터 최적화를 위한 라이브러리로, 베이지안 최적화 기법을 사용하여 효율적으로 최적의 하이퍼파라미터를 찾습니다.
- 장점: 검색 공간을 효과적으로 탐색하여 최적의 하이퍼파라미터 조합을 찾을 수 있으며, 다양한 머신러닝 프레임워크와 통합할 수 있습니다.

AI가 재밌는 걸