데이터
방송콘텐츠 대화체 음성인식 데이터
방송콘텐츠 대화체 음성인식 데이터 아이콘 이미지
분야한국어유형텍스트
구축년도 : 2022 갱신년월 : 2023-11 조회수 : 2,488 다운로드 : 156 용량 : 558.15 GB
링크 : https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=71314
소개
방송콘텐츠 상에서 한국인 대화체의 음성인식(STT) 기술 및 문맥을 이해하는 언어처리 기술 개발을 위한 인공지능 학습용 데이터로서 8개 카테고리, 대화체 음성인식, 문장별 의도 인공지능 학습용으로 정제된 7,000시간의 음성 데이터
구축목적
방송에서의 자연스러운 환경의 일상적인 대화체, 문장별 의도 분류, 카테고리 분류 서비스를 위한 고품질 방송콘텐츠 음성인식 데이터 확보로 화자를 더 잘 이해하는 지능화 혁신 서비스 기반 마련
샘플데이터 포맷 예시
파일명: A220002
녹음일자: 2021.10.08
원자료 유형: 라디오
방송사: TBS
카테고리: 교양
방송 제목: 경제발전소 박연미입니다
화자 규모: 5
원문
- {16.43513} 한국경제신문 홀길동 기자가 정리했습니다.
- {19.16923} 안녕하세요.
- {20.36159} 네 안녕하세요.
- {21.80111} 네 고길동 청장이 십일월 둘째 주부터는 위드 코로나 시작할 수 있다 처음으로 얘기를 했군요.```
## 라벨링후
```**0001**
- {11.70049} 매일 아침 쏟아지는 경제뉴스 (십 분만)/(10분만) 투자하면 충분히 따라잡을 수 있습니다. | [약속]
- {16.43513} 한국경제신문 @이름1 기자가 정리했습니다. | [단순 진술]
- {19.16923} 안녕하세요. | [첫인사]
**0002**
- {20.36159} 네 안녕하세요. | [첫인사]
**0001**
- {21.80111} 네 @이름2 청장이 (십일월)/(11월) 둘째 주부터는 위드 코로나 시작할 수 있다 처음으로 얘기를 했군요. | [단순 진술]JSON 형식
{
"id": "A220002.1.1.4",
"speaker_id": "0001",
"start": 11.700,
"end": 16.435,
"form": "매일 아침 쏟아지는 경제뉴스 (십 분만)/(10분만) 투자하면 충분히 따라잡을 수 있습니다.",
"original_form": "매일 아침 쏟아지는 경제뉴스 십 분만 투자하면 충분히 따라잡을 수 있습니다.",
"hangeulToEnglish": null,
"hangeulToNumber": [
{
"id": 1,
"hangeul": "십 분만",
"number": "10분만",
"begin": 17,
"end": 20
}
],
"term": null,
"intent": ["약속"],
"endpoint": null,
"summary": null
}데이터 특성
30분에서 50분가량의 굉장히 긴 음성 wav파일과
5어절씩 묶어서 라벨링 된 json 데이터
라벨링 데이터는 id, 화자, 내용, 의도, 음성 시작 지점 및 끝지점, 한글과 숫자 언어사전 등으로 구성되어 있다.
데이터 포맷 예시
먼저 음성파일 중 'A220001.wav'데이터의 구성을 살펴보려고 한다. A220001의 음성길이는 2959sec(49.3MIN)으로 굉장히 긴 파일임을 확인할 수 있다.
너무 긴 음성데이터는 특징을 추출하기 어려우므로 라벨링 된 시작지점과 끝지점 만큼 음성파일을 분할하여 적정한 길이의 음성파일로 변환한다.
!pip install soundfile matplotlib librosa transformers gradioimport json
import librosa
import soundfile as sf
# JSON 파일 로딩
with open('A220001.json', 'r', encoding='utf-8') as f:
data = json.load(f)
# 음성 파일 로딩
audio_path = 'A220001.wav'
y, sr = librosa.load(audio_path, sr=None) # 오디오 전체를 로드음성데이터 분석
음성파일의 특징을 확인하기 위해
라벨링 데이터에서 음성데이터가 어떻게 구성되어 있는지 알아본다.
A220001.wav와 A220001.json을 불러서
- 먼저 라벨링데이터에서 'intent'를 추출하여 고유한 intent와 intent의 빈도를 확인했다.
# intent의 고유한 값들을 추출하고 전체 분포를 확인합니다.
intents = [utterance['intent'] for utterance in data['utterance'] if 'intent' in utterance]
flat_intents = [item for sublist in intents for item in sublist]
# 고유한 intent 값들과 각 intent의 출현 횟수를 확인
unique_intents = set(flat_intents)
intent_distribution = {intent: flat_intents.count(intent) for intent in unique_intents}
print(unique_intents)
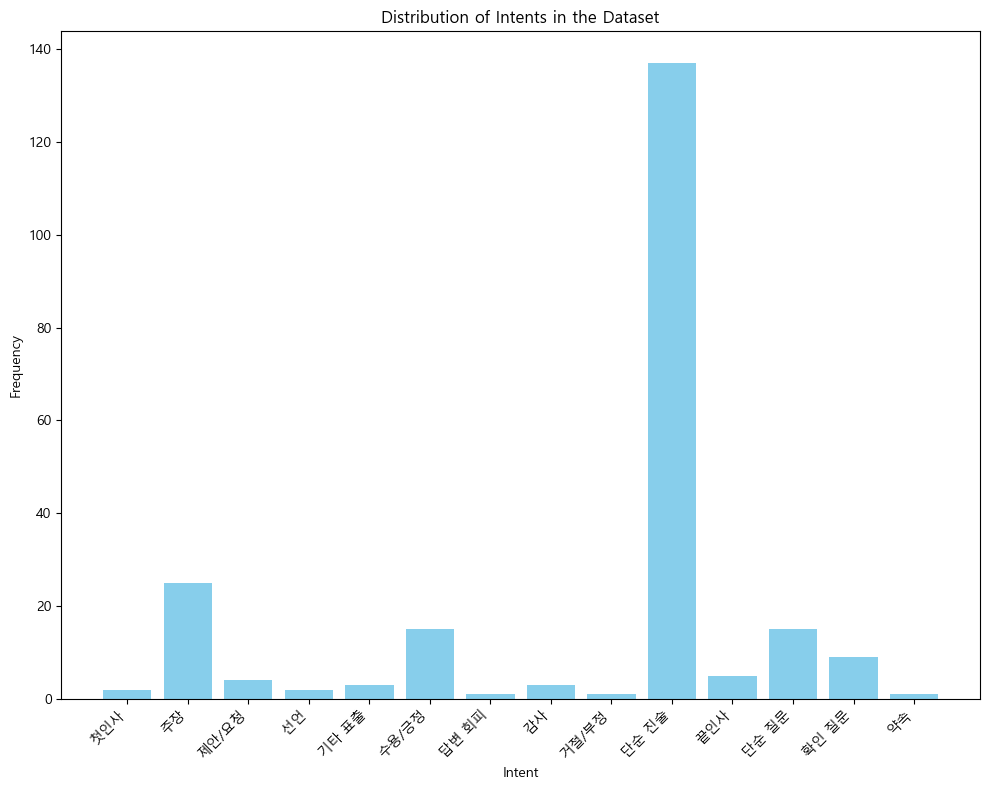
print(intent_distribution)분석결과 '단순 진술', '주장', '단순 질문', '수용/긍정' 순으로 음성데이터 내에 의도가 분포되있음을 확인할 수 있다.
{'첫인사', '주장', '제안/요청', '선언', '기타 표출', '수용/긍정', '답변 회피', '감사', '거절/부정', '단순 진술', '끝인사', '단순 질문', '확인 질문', '약속'}
{'첫인사': 2, '주장': 25, '제안/요청': 4, '선언': 2, '기타 표출': 3, '수용/긍정': 15, '답변 회피': 1, '감사': 3, '거절/부정': 1, '단순 진술': 137, '끝인사': 5, '단순 질문': 15, '확인 질문': 9, '약속': 1}import matplotlib.pyplot as plt
# 데이터를 그래프로 표시
plt.rc('font', family='Malgun Gothic')
plt.rcParams['axes.unicode_minus'] =False
plt.figure(figsize=(10, 8))
plt.bar(intent_distribution.keys(), intent_distribution.values(), color='skyblue')
plt.xlabel('Intent')
plt.ylabel('Frequency')
plt.title('Distribution of Intents in the Dataset')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()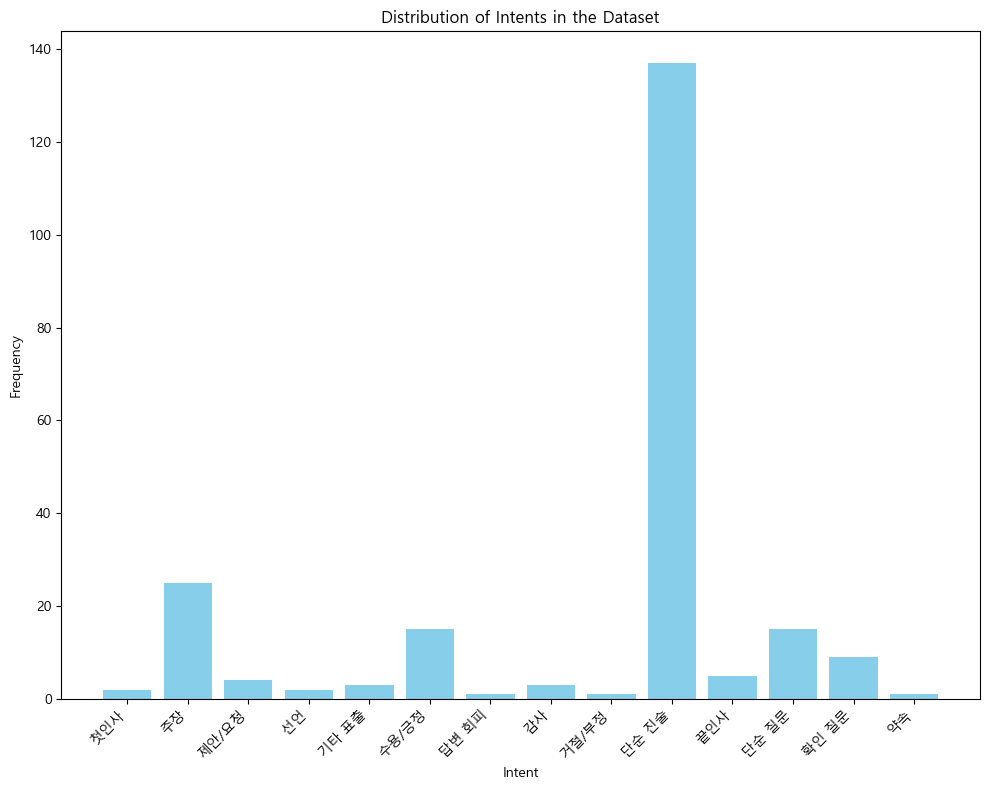
특히 '단순 진술'의 경우 다른 '의도' 데이터 대비 압도적으로 많은 빈도로 라벨링되어 있음을 확인할 수 있다.
먼저 Open Korea Text 기반의 형태소 분석기를 통해 json 데이터의 'Original_form'에 대해 토큰화를 진행하였다.
발화 내용
발화의도에 이어 발화 내용은 어떤 텍스트로 이루어져 있는지 살펴보고자 한다.
분석을 위해 konlpy 라이브러리를 통해 라벨링된 대화내용을 형태소단위로 토큰화할 필요가 있다.
import json
from konlpy.tag import Okt
# Okt 객체 생성
okt = Okt()
# 발화 데이터에서 각 텍스트를 토큰화
tokens_list = []
for utterance in data['utterance']:
original_text = utterance['original_form'] # 원본 텍스트 사용
tokens = okt.morphs(original_text) # 형태소 단위로 토큰화
tokens_list.append(tokens)
# 토큰화 결과 출력
print(tokens_list[:5]) # 처음 5개 발화의 토큰화 결과 출력[['꽤', '긴', '연휴', '인데', '직장', '으로', '돌아갈', '생각', '하면', '좀', '아쉬운', '시간', '이지만', '또', '투자자', '들', '은', '고', '사이', '에', '한국', '장이', '쉬어가니까', '너무', '너무', '손', '이', '간질간질', '해서', '미국', '장', '에', '투자', '를', '더', '늘린다', '이런', '얘기', '도', '있더군요', '.'], ['간밤', '뉴욕', '증시', '는', '중국', '의', '부동산', '그룹', '&', 'company', '-', 'name', '1', '&', '그룹', '이', '파산할', '수', '있다', '이', '소식', '에', '번지', '면서', '휘청', '했습니다', '.'], ['뭐', '~', '이', '것', '때문', '만은', '아니고요', '.'], ['미국', '의', '긴축', '에', '&', 'company', '-', 'name', '1', '&', '그룹', '이', '한', '수', '얹었다', '이렇게', '표현', '할', '수', '있겠는데', '홍콩', '증시', '도', '굉장히', '어려웠고요', '.'], ['중국', '증시', '는', '중추절', '연휴', '였는데', '우리', '추석', '연휴', '기간', '에도', '주목', '해야', '할', '것', '들', '은', '분명히', '있을', '겁니다', '.']]다만 이렇게 토큰화된 텍스트데이터는 시각적으로 확인하기 어려움으로
matplotlib과 wordcloud를 통해 시각화를 진행하였다.
import matplotlib.pyplot as plt
from collections import Counter
from wordcloud import WordCloud
# 단어 빈도 계산
word_counts = Counter([token for sublist in tokens_list for token in sublist])
# 워드 클라우드 생성
wordcloud = WordCloud(font_path='Pretendard-Bold.ttf', width = 800, height = 400, background_color ='white').generate_from_frequencies(word_counts)
# 워드 클라우드 시각화
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # 축 표시 제거
plt.show()
# 바 차트로 단어 빈도수 시각화
top_words = word_counts.most_common(10) # 가장 빈번한 10개 단어
words, counts = zip(*top_words)
plt.figure(figsize=(10, 5))
plt.bar(words, counts, color='blue')
plt.xlabel('Words')
plt.ylabel('Frequency')
plt.title('Top 10 Words in the Dataset')
plt.xticks(rotation=45)
plt.show()
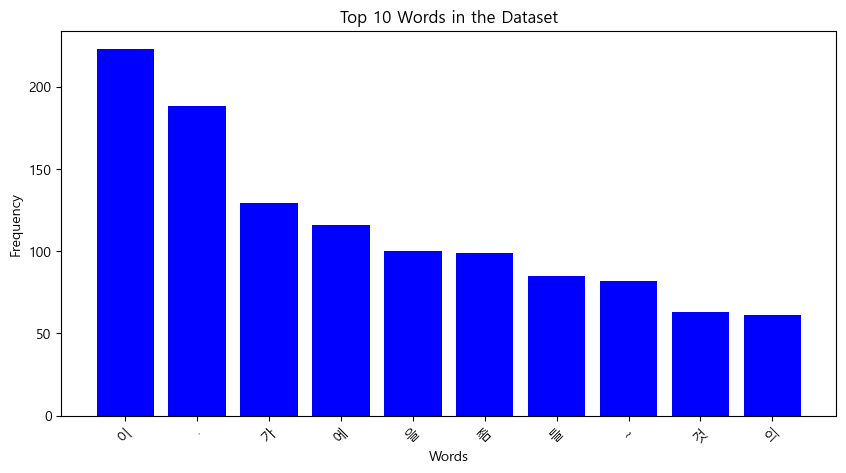
형태소 분석결과 '이', '.', '가', '에', '을', '좀', '들', '~'과 같은 조사 및 특수문자가 토큰화시에 매우 높은 빈도로 나타남을 확인할 수 있다.
이를 통해서 올바른 모델확습을 위해서는 특수문자에 대한 불용어 처리가 필요함을 확인할 수 있다.
품사분석
발화데이터에서 품사는 어떤 빈도로 나타나는지 확인하여 시각화를 진행했다.
import json
from konlpy.tag import Okt
import matplotlib.pyplot as plt
from collections import Counter
# Okt 객체 생성
okt = Okt()
# 발화 데이터에서 각 텍스트를 품사 태깅
pos_list = []
for utterance in data['utterance']:
original_text = utterance['original_form'] # 원본 텍스트 사용
pos_result = okt.pos(original_text) # 품사 태깅
pos_list.extend([pos for _, pos in pos_result]) # 태깅 결과에서 품사만 추출
# 품사별 빈도 계산
pos_counts = Counter(pos_list)
# 데이터를 그래프로 표시
plt.figure(figsize=(10, 8))
plt.bar(pos_counts.keys(), pos_counts.values(), color='skyblue')
plt.xlabel('Part of Speech')
plt.ylabel('Frequency')
plt.title('POS Tagging Frequency in the Dataset')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()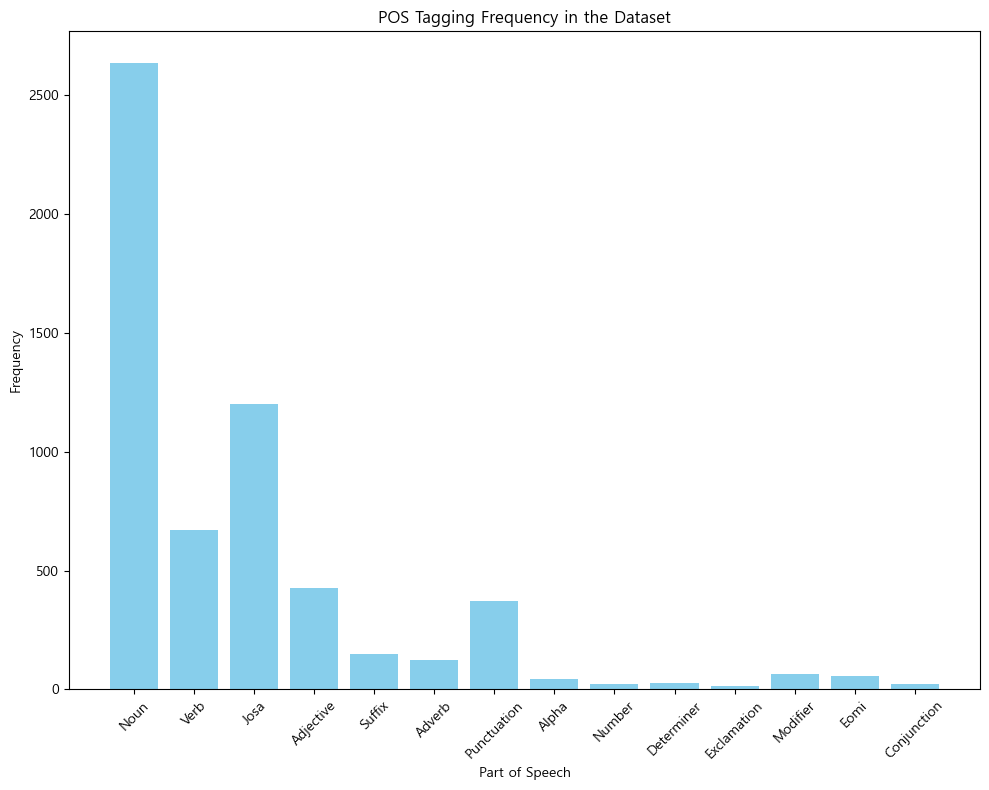
명사가 가장 많고, 그다음 조사, 그다음 동사와 형용사의 순서대로 품사의 빈도가 나열되었음을 확인했다.
음성데이터 시각화
파이썬 Librosa 패키지를 통해서 A220001.wav파일을 시각화하였다.
import librosa
array, sampling_rate = librosa.load("A220001.wav")
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate, color="blue")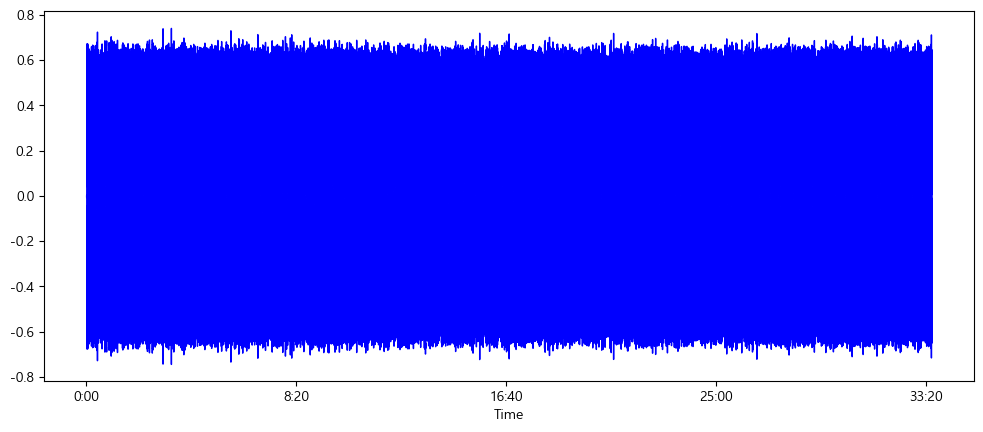
음성파일의 길이가 너무 긴 탓에 시각화 과정에서 특징이 제대로 표현되지 않는 모습을 확인할 수 있다.
이 파일로는 특징을 추출해내기 힘든 것으로 생각되며
json에 라벨링된 음성신호의 Start Point 및 End Point로 wav파일을 적절히 분할할 필요가 있다.
음성데이터 분할처리
라벨링 데이터에 포함된 'id', 'start', 'end' 데이터를 통해서 원본 wav파일을 분할하였다.
분할결과 하나의 wav파일이 총 210개의 세부 wav파일로 분할됨을 확인할 수 있었다.
# 발화 정보에 따라 음성 데이터 분할 및 저장
for utterance in data['utterance']:
data_id = utterance["id"]
start_sec = utterance['start']
end_sec = utterance['end']
data_intents = utterance['intent']
start_sample = int(start_sec * sr)
end_sample = int(end_sec * sr)
utterance_audio = y[start_sample:end_sample]
# 파일명 설정 (예: A220001.1.1.1.wav)
output_filename = f'data/{utterance["id"]}.wav'
sf.write(output_filename, utterance_audio, sr)
print(f'File saved: {output_filename}')분할된 wav파일 'A220001.1.1.1.wav'를 새롭게 불러와 시각화하였다.
import librosa
array, sampling_rate = librosa.load("data\A220001.1.1.1.wav")
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate, color="blue")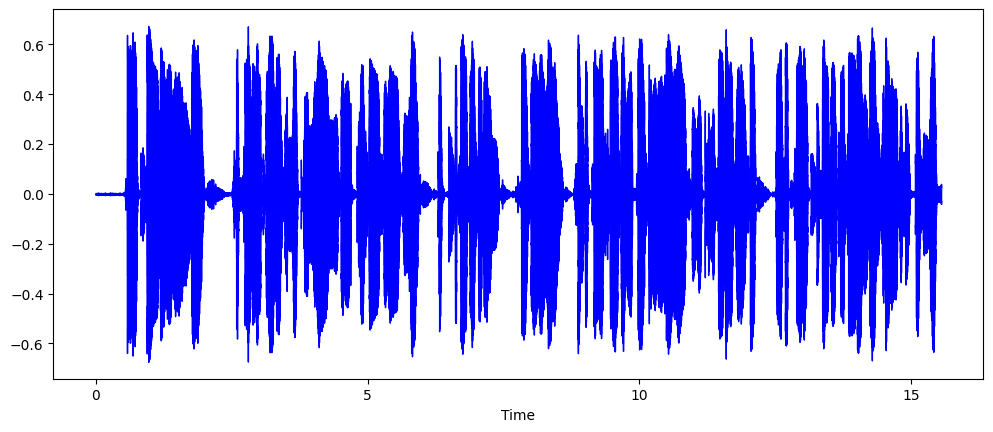
주파수 스펙트럼(frequency spectrum)
이산 푸리에 변환(DFT)을 사용하여 음성신호를 구성하고 있는 각각의 주파수들과 그 세기를 알 수 있다.
numpy의 rfft() 함수를 쓰면 DFT를 계산할 수 있는데, 이를 A220001.wav 파일의 소리에 적용시켜 주파수 스펙트럼을 그릴 수 있다.
앞에서부터 4096개의 데이터에 대해서만 적용하면 다음과 같다.
import numpy as np
dft_input = array[:4096]
# calculate the DFT
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# get the amplitude spectrum in decibels
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# get the frequency bins
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")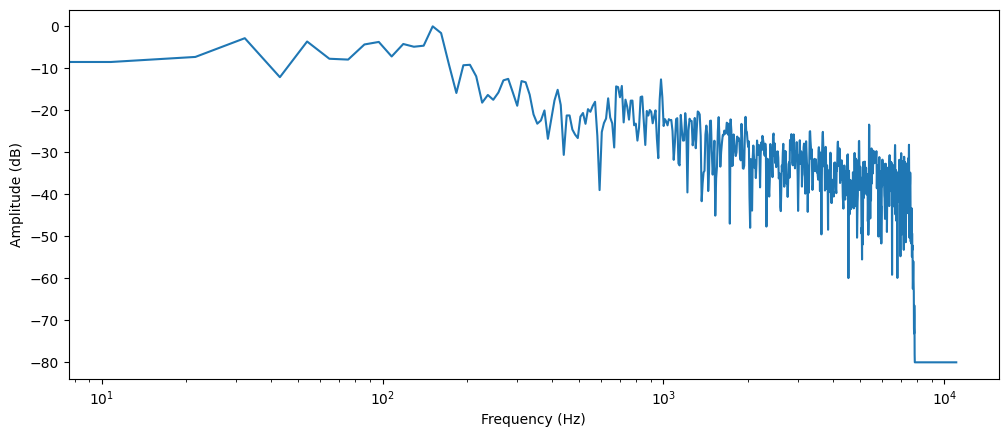
오디오 구간에 존재하는 다양한 주파수의 세기를 보여주고 있으며,
X축에 로그스케일로 주파수를, Y축엔 진폭인 주파수 스펙트럼 그래프를 확인할 수 있다.
스펙트로그램(spectrogram)
스펙트럼은 한 순간만의 주파수들을 보여준다.
따라서 시간을 작은 구간들로 나누어 DFT를 적용하고, 그 결과인 스펙트럼들을 쌓아 스펙트로그램을 만들어야 한다.
스펙트로그램은 오디오 신호의 주파수를 시간에 따라 변화하는 형태로 그린다.
이를 통해 시간, 주파수, 진폭을 그래프에서 한눈에 볼 수 있다.
이 계산을 수행하는 알고리즘을 STFT(Short Time Fourier Transform)라 한다.
librosa의 stft()와 specshow() 함수를 이용해 트럼펫 소리의 스펙트로그램을 그려보자.
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()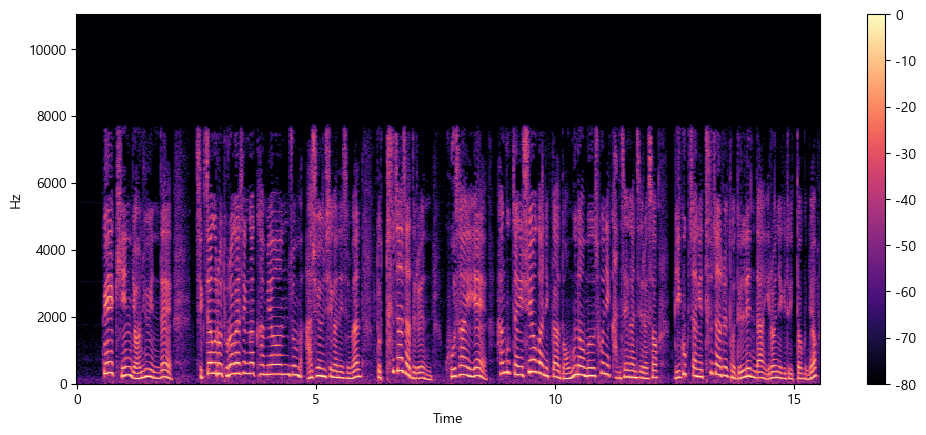
이 그래프에서 X축은 파형 그래프처럼 시간을 나타내며 Y축은 주파수를 Hz 단위로 나타낸다. 색상의 강도는 각 시점의 주파수 성분의 진폭 또는 파워를 데시벨(dB)로 측정하여 나타낸다.
스펙트로그램은 일반적으로 오디오 신호의 몇 밀리초 정도 되는 짧은 구간에 DFT를 적용하여 주파수 스펙트럼들을 얻어 만들어진다.
이 스펙트럼들을 시간축으로 쌓은것이 스펙트로그램이라고 할 수 있다.
이 이미지에서 각각의 수직 조각들은 아까 위에서 본 주파수 스펙트럼에 해당한다.
기본적으로, librosa.stft()함수는 오디오 신호를 2048개의 샘플로 나누는데 이는 주파수 해상도(frequency resolution)와 시간 해상도(time resolution) 사이의 적절한 절충(trade-off)이기 때문이라고 한다.
멜 스펙트로그램
멜 스펙트로그램은 스펙트로그램의 한 종류로 음성 작업이나 머신러닝 작업에 주로 쓰이는데, 오디오 신호를 시간에 따른 주파수로 보여준다는 점에서 스펙트로그램과 비슷하지만, 다른 주파수 축을 사용한다.
표준적인 스펙트로그램에선 주파수 축이 선형(linear)이며 헤르츠(Hz)단위로 측정된다. 그러나, 사람의 청각 시스템은 고주파보다 저주파에 더 민감하며, 이 민감성은 주파수가 증가함에 따라 로그함수적으로 감소한다. 멜 스케일(mel scale)은 이런 사람의 비선형 주파수 반응을 근사한(approximate) 지각 스케일(perceptual scale)이다.
멜 스펙트로그램을 만드려면 전처럼 STFT를 사용하고 오디오를 여러 짧은 구간으로 나눠 일련의 주파수 스펙트럼들을 얻어야 한다. 그 후 추가적으로, 각 스펙트럼에 mel filterbank라고 불리는 필터들을 적용시켜 주파수를 멜 스케일로 변환한다.
이 모든 단계를 librosa의 melspectrogram() 함수를 통해 대신 하여 멜 스펙트로그램을 그릴 수 있다.
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()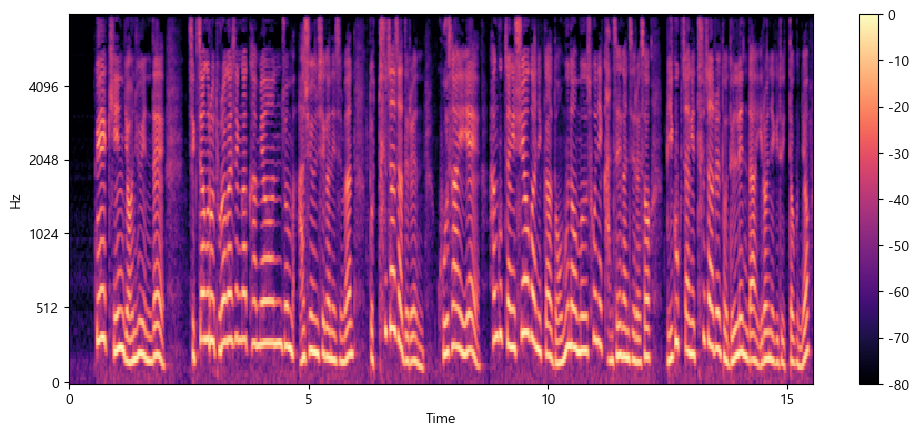
위의 예에서, n_mels는 mel band의 수를 정한다. mel band는 필터를 이용해 스펙트럼을 지각적으로 의미있는 요소로 나누는 주파수 범위의 집합을 정의할 수 있다. 이 필터들의 모양(shape)과 간격(spacing)은 사람의 귀가 다양한 주파수에 반응하는 방식을 모방하도록 선택되는데, 흔히 n_mels의 값으로 40 또는 80이 선택된다. fmax는 우리가 관심을 가지는 최고 주파수(Hz 단위)를 나타낸다.
일반적인 스펙트로그램과 마찬가지로 멜 스펙트로그램의 주파수 성분 역시 세기를 데시벨로 표현하는 것이 일반적이다. 데시벨로의 변환이 로그 연산을 포함하기 때문에 이를 흔히 로그-멜 스펙트로그램(log-mel spectrogram)이라 한다.
위 예제에선 librosa.power_to_db()를 썻는데, 이는 librosa.feature.melspectrogram()는 파워 스펙트로그램(power spectrogram)을 만들기 때문이다.
Gradio
Gradio를 통해서 주피터 노트북 환경에서 파이썬을 통해 wav파일을 실시간으로 디코딩하여 확인해 볼 수 있다.
import gradio as gr
def generate_audio():
audio = {'array':array, 'sampling_rate':sampling_rate}
return (
audio['sampling_rate'],
audio['array'],
), 'Audio'
with gr.Blocks() as demo:
with gr.Column():
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)
Feature Extractor
이렇게 오디오파일 및 라벨링파일에 대해 다양한 전처리와 시각화를 진행해보았다.
그러나 오디오데이터셋을 준비하여 모델 학습을 할 때, Fine Tuning이나 추론을 하고자 한다면, 원본 데이터를 모델의 입력 Feature에 적합하게 맞춰야 할 필요가 있는데, 음성데이터의 경우 샘플링레이트, 음성길이 등 데이터에 요구되는 특징이 모델마다 상이하게 다르다.
그러나 Whisper 모델처럼 입력 데이터를 모델의 feature에 맞게 변환해주는 feature extractor 클래스가 제공된다.
(가령, Whisper 모델의 경우, 모든 데이터가 30초 길이를 갖여야 하고, 오디오 배열들이 로그-멜 스펙토그램으로 변환되어야 한다.)
Whisper의 체크포인트에서 feature extractor를 불러와 내가 원하는 오디오 데이터에 적용해볼 수 있다.
from transformers import WhisperFeatureExtractor
import librosa
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-large-v3")
# 오디오 파일 로드 및 샘플링 레이트 변환
array, _ = librosa.load("data/A220001.1.1.1.wav", sr=16000) # 16000Hz로 변환
# WhisperFeatureExtractor 로드
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-large-v3")
# 오디오 데이터 준비
audio = {'array': array, 'sampling_rate': 16000}
# 특성 추출
features = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"], padding=True)이렇게 추출한 features의 로그-멜 스펙트로그램을 시각화해보았다.
import numpy as np
import matplotlib.pyplot as plt
import librosa.display
# features의 구조 확인
print(features.keys())
# 올바른 키를 사용하여 특성 데이터 할당
input_features = features['input_features'][0] # 가정: 'input_features'가 올바른 키일 경우
# 특성 데이터 시각화
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length
)
plt.colorbar()
plt.show()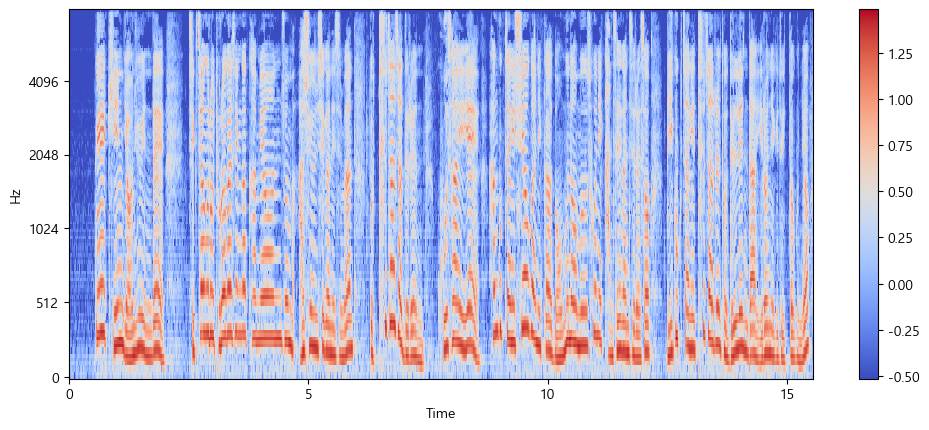
즉, Whisper 모델에 맞게 전처리된 오디오 데이터의 입력은 이러한 형태로 시각화되는 데이터임을 확인할 수 있다.
