0. 학습목표
Level 1.
- 학습률(Learning rate)의 개념과 학습률이 너무 크거나 작은 경우 발생하는 문제에 대해 설명할 수 있다.
- 활성화 함수에 맞는 가중치 초기화(Weight Initialization)을 매칭할 수 있다.
- 신경망에 적용할 수 있는 과적합(Overfittion)을 방지할 수 있는 방법(Weight Decay, Dropout, Early stopping)의 개념에 대해 설명할 수 있고 이를 Keras로 적용할 수 있다.
Level 2.
- 지난 강의에서 배운 내용 외에 해당하는 Optimizer의 특징에 대해 개략적으로 설명할 수 있다.
- Dropout의 효과와 Evaluation단계에서 Dropout이 어떻게 적용되는지 설명할 수 있다.
Level 3.
- 배치 정규화(Batch Normalization)를 이해하고 이를 Keras 코드로 신경망에 적용할 수 있다.
1. 학습률 감소 or 계획법(Learing rate Decay or Scheduling)
학습률(Learing rate,lr)이란 매 가중치에 대해 구해진 기울기 값을 얼마나 경사 하강법에 적용할지를 결정하는 하이퍼 파라미터이다.
경사하강법이 산긴을 내려가는 과정을 의미한다면, 학습률은 보폭을 결정하게 된다. 따라서 학습률이 크면 Iteration마다 값이 크게 변하게 되고, 작으면 조금씩 이동하게 된다.
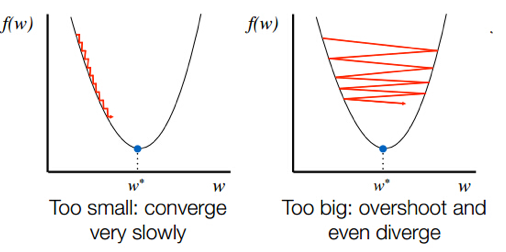
따라서 학습률을 잘못 설정하게 되면 위의 그림과 같이 된다. 위의 그림을 설명하면 다음과 같다.
💡 학습률이 너무 낮을 때
최적점에 이르기까지 너무 오래 걸리거나, 주어진 Iteration 내에서 최적점에 도달하는 데 실패한다.
💡 학습률이 너무 클 때
경사하강 과정에서 발산하면서 모델이 최적값을 찾을 수 없게 된다.
따라서 최적의 학습률을 찾는 것은 학습에서 중요한 요소이다. 따라서 최적의 학습률을 찾기 위하여 사용하는 방법이 학습률 감소/계획법이다.
1. 학습률 감소(Learing rate Decay)
학습률 감소는 Adagrad, RMSprop,Adam과 같은 옵티마이저에 이미 구현되어 있기 때문에 쉽게 적용할 수 있다. 위의 옵티마이저의 하이퍼 파라미터를 조정하면 감소 정도를 변화시킬 수 있다.
- 옵티마이저(Optimizer)의 다양한 하이퍼파리미터를 조정하여 적용
tf.keras.optimizers.Adam(
learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False,
name='Adam'
)위에서 사용된 옵티마이저인 Adam알고리즘은 Momentum과 RMSProp을 조합한 옵티마이저이다.
dadelta와 RMSprop이 직전의 단계인 까지 경사의 제곱의 이동평균 를 지수함적으로 감쇠평균적으로 감쇠평균한 항을 저장해가며 유지하고 매개변수의 변경식에 이 값을 사용했던 것과는 달리 adam에서는 추가로 단순한 경사의 이동평균인 를 지수함수적으로 감쇠시킨 항도 사용한다. 많은 수학적인 공식이 존재하지만 adam알고리즘에서 학습률의 계산은 다음과 같은 식으로 이루어진다.
보통 이 포스트에는 서술하지 않았지만 다른 식에 있는 를 0으로 근사시키기 위해서 보통 로 설정한다. defalut값 역시 이로 설정되어 있다.
epsilon은 아직 무엇인지 정확히 모르겠다. 그리고 amsgrad인자는 AMSGrad변형을 적용할지 여부를 설정하는 인자로, 자세한 설명은 참고자료의 2번을 참고하자.
- 신경망을
compile하는 코드에 하이퍼파라미터를 조정하는 옵티마이저 적용
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001, beta_1 = 0.89),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])2. 학습률 계획법(Learning rate Scheduling)
학습 과정에 학습률을 바꿔가는 메카니즘을 골라서 처리하는 과정을 학습률 계획 또는 학습률 스케쥴이라고 한다.
아래의 그래프와 같이 Warm-up Step을 포함한 학습률 계획 방법을 적용하기도 한다. 그리고 그래프에 나타난 두가지 계획법에 대해서도 알아보자.
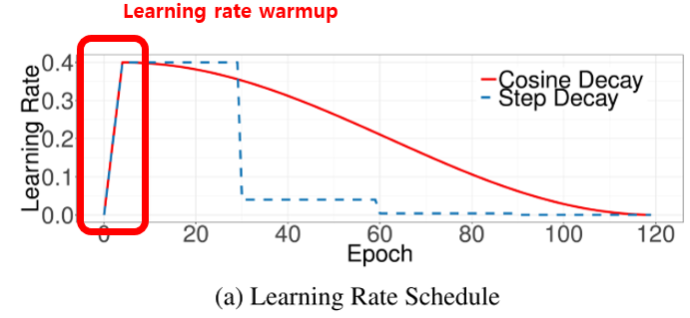
2-1. Step Learning rate Decay Scheduling
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.callbacks import LearningRateScheduler
import tensorflow as tf
import numpy as np
def step_decay(epoch):
start = 0.1
drop = 0.5
epochs_drop = 5.0
lr = start * (drop ** np.floor((epoch)/epochs_drop))
return lr
model = Sequential([Dense(10)])
model.compile(optimizer=SGD(), loss='mse')
lr_scheduler = LearningRateScheduler(step_decay, verbose=1)
history = model.fit(np.arange(10).reshape(10, -1), np.zeros(10),
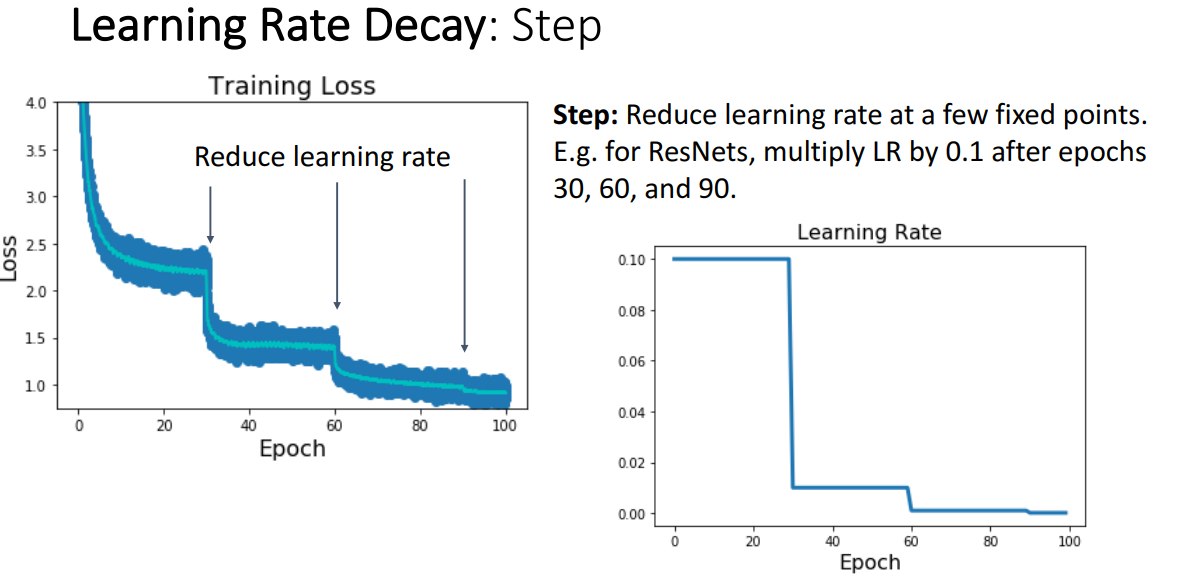
epochs=10, callbacks=[lr_scheduler], verbose=0)가장 많이 사용되는 학습률 스케줄 방법으로는 스텝 스케줄이 있다. ResNet에서 잘 사용하고 있는 계획법이다.
처음에는 상대적으로 큰 학습률로 시작하여 최적화 과정에서 특정 지점에서 학습률을 감쇄시키고자 더 낮은 학습률을 사용한다. 위의 왼쪽 그림은 학습률 감쇄 스케쥴이라고 부르는 건데, 여기서 비용 함수의 특성이 나타나는 곡선을 볼수 있다. 여기서 스텝 학습률 감쇠로 첫 30 에폭 페이스에선 상대적으로 큰 학습률을 사용해서 빠르게 진행을 하여, 큰 값으로 시작했던 초기 비용을 지수적으로 줄일수가 있었다.
하지만 30 에폭쯤에서 처음 처럼 빠르게 진행할 수가 없어, 이 30에폭 시점에서 학습률을 감쇄시켜 10으로 나눈뒤 학습을하면 다시 비용이 급격히 떨어져 지수적인 패턴이 나오기 시작한다. 또 다시 평탄한 부분이 나오면 60 에폭 쯤에서 학습률을 다시 감쇄하여 빠르게 떨어트리고 다시 평탄해지는 스케줄을 사용하였을때 이런 특성이 나타나게 된다. 이게 스탭 학습률 스캐쥴이란 방법으로 모델을 학습시킬때 볼수 있는 학습률 곡선의 특성 형태이다.
이 계획법의 경우 모델을 학습하는데 여러개의 하이퍼파라미터가 필요하고, 따라서 튜닝하는데 워낙 많은 경우의 수가 생겨 상당히 많은 시간이 소요된다. 그래서 최근에너는 이런 단점을 극복한 다양한 계획법이 나왔다.
2-2. Cosine Learning rate decay Scheduling
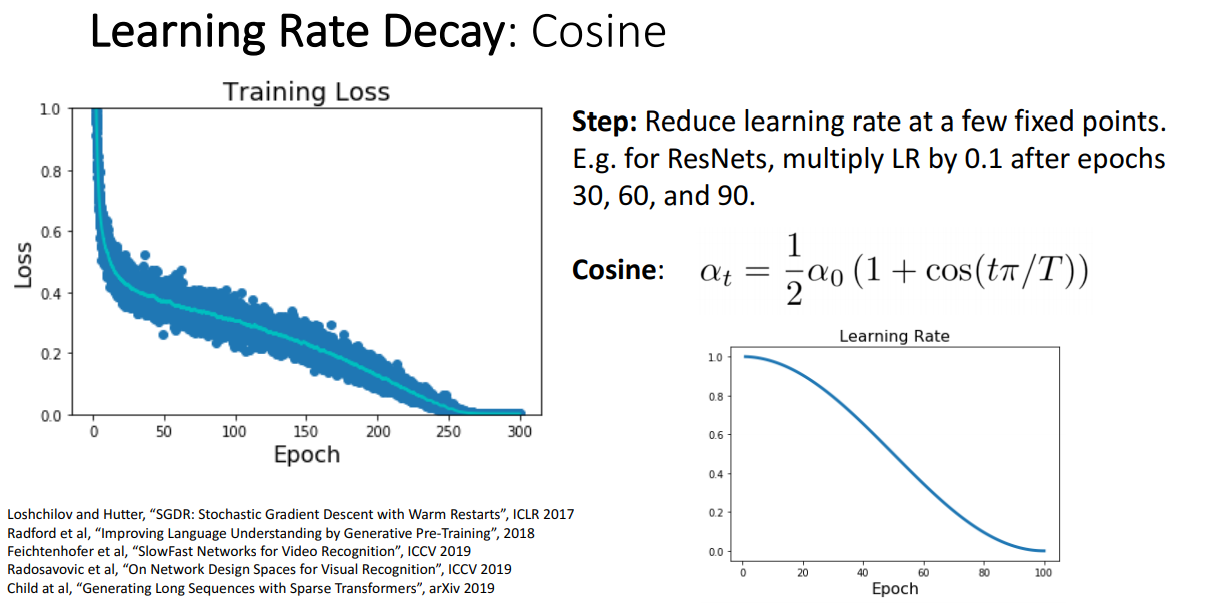
스텝 학습률 감소 계획법의 단점을 극본한 방법 중 하나이다. 특정 반복 회차, Epoch에서 감쇄하는 것이 아니라 사간에 대한 함수를 사용한다. 학습률은 모든 Epoch 회차에 대한 함수로 정해진다.
이 계획법은 하이퍼파라미터가 초기 학습률로 사용할 와 학습할 에폭의 수 2개이다. 따라서 이전의 스텝 감쇄 계획법보다 다루기가 쉬우며, 일반적으로 학습을 길게 할수록 잘 동작하는 경향을 보인다.
first_decay_steps = 1000
initial_learning_rate = 0.01
lr_decayed_fn = (
tf.keras.experimental.CosineDecayRestarts(
initial_learning_rate,
first_decay_steps))
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=lr_decayed_fn),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])2. 가중치 초기화(Weight Initialization)
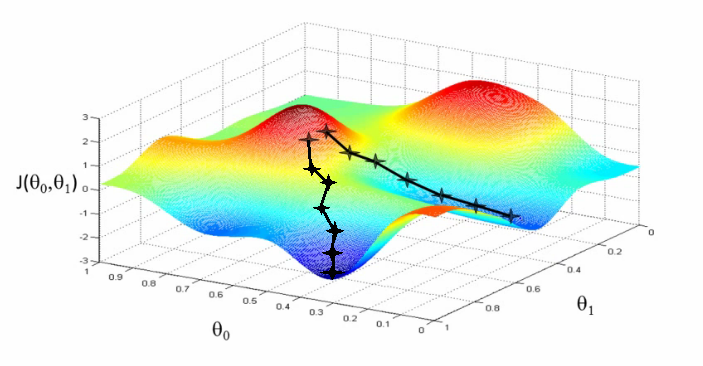
신경망 모델 학습의 목적은 파라미터 최적화이다. 이를 위해서 손실함수에 대해서 경사하강법을 수행한다. 그런데 동일한 경사하강법을 따라서 내려가더라도 위의 그림에서 보듯이 도달하는 최적점이 다른 것을 볼 수 있다. 시작 위치에 따라서 최적점이 달라지게 되는 것이다. 이처럼 첫 위치를 잘 정하는 것도 좋은 학습을 위한 조건 중 하나이다.
따라서 학습 시작 시점의 가중치를 잘 정해주야하고, 이를 위해서 상황에 맞는 적절한 가중치 초기화(Weight initialization) 방법을 사용하게 된다.
1. 가중치 초깃값 = 0
가중치의 초기값을 0으로 default를 주고 시작하면 올바른 학습을 기대하기 어렵다. 오차역전파에서 가중치의 값이 똑같이 갱신되기 때문이다. 가중치가 각각 영향이 있어야 하는데 고르게 되어버리는 상황이 발생하면 각각의 노드를 만든 의미를 잃어버리게 된다
그래서 Keras에서는 Default로 되어 있는 가중치초기화 옵션은 random initialization이다. 하지만 이방식은 역전파 과정에서 미분한 Gradient가 지나치게 커지거나 소실되는 문제에 빠질 위험성이 크다.
2. Sigmoid 함수 가중치 초깃값 설정: Xavier
2-1. 표준편차를 1인 정규분포로 가중치 초기화
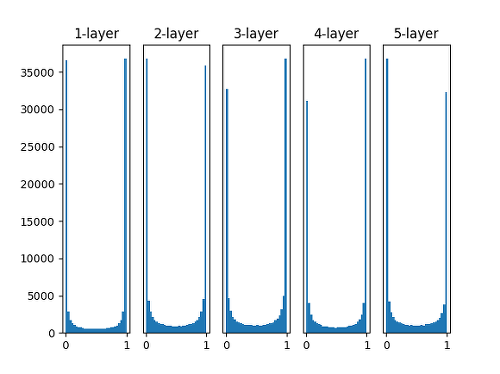
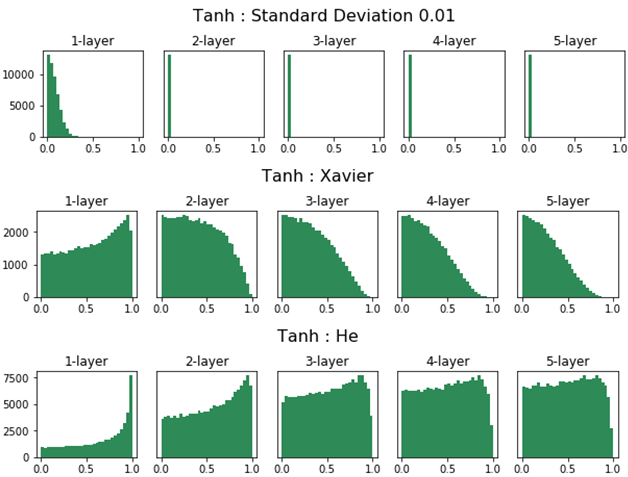
표준편차가 일정한 정규분포로 가중치를 초기화 해 줄 때에는 대부분의 활성화 값이 0과 1에 위치하는 것을 볼 수 있다. 이는 Sigmoid 함수의 특성으로 인한 것이다.
이렇게 활성값이 양 끝 단에 집중적으로 분포되어 고르지 못할 경우에는 학습이 제대로 이루어지지 않는다. 그렇기 때문에 가장 간단한 방법임에도 잘 사용하지 않는다.
2-2. Xavier Initialization
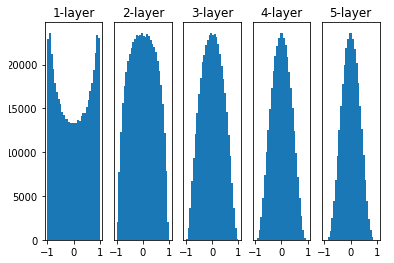
Xavier 초기화(Xavier initialization)는 가중치를 표준편차가 고정값인 정규분포로 초기화 했을 때의 문제점을 해결하기 위하여 등장한 방법이다.
Xavier초기화는 이전 층의 노드가 개 일 때, 현재 층의 가중치를 표준편차가 인 정규분포로 초기화한다.
Keras에서는 이전 층의 노드가 개이고 현재 층의 노드가 개일 때, 현재 층의 가중치를 표준편차가 인 정규분포로 초기화 한다. 또한 glorot라는 이름으로 사용한다.
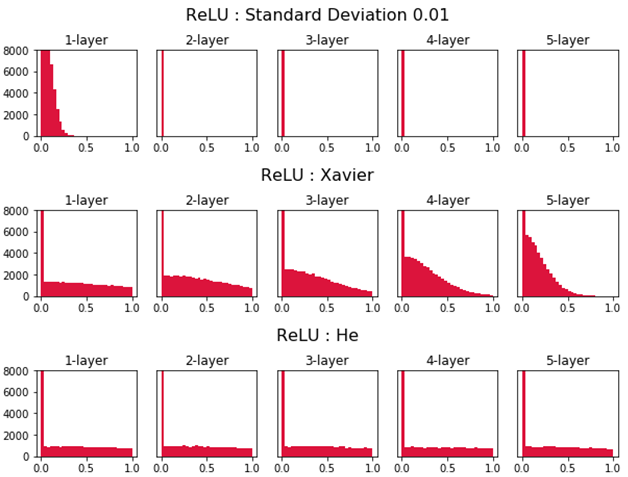
3. ReLU 함수 가중치 초깃값 설정: He
Xavier초기화는 활성화 함수가 시그모이드인 신경망에서는 잘 작동한다. 하지만 활성화 함수가 ReLU인 신경망에서는 층이 지날수록 활성값이 고르지 못하게 되는 문제를 보이게 된다.
이런 문제를 해결하기 위해 등장한 것이 바로 He 초기화(He initialization이다. He초기화는 이전 층의 노드가 개일 때, 현재 층의 가중치를 표준편차가 인 정규분포로 초기화한다. He초기화를 적용하면 아래 그림처럼 층이 지나도 활성값이 고르게 유지되는 것을 확인할 수 있다.
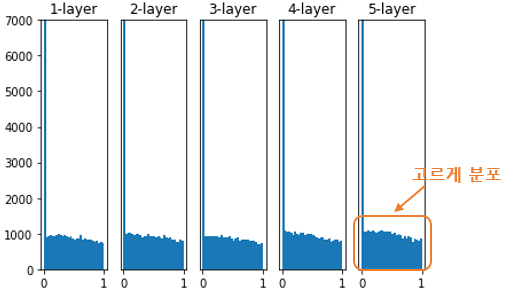
위의 방법 외에도 여러 가지가 있다. 케라스에서는 아래와 같은 가중치 초기화 방법을 제공하고 있다.
['uniform', 'lecun_uniform', 'normal', 'zero', 'glorot_normal', 'glorot_uniform', 'he_normal', 'he_uniform']케라스의 Dense layer에서는 default로 glorot_uniform이 설정되어 있다. 적용하는 방법은 다음과 같다.
Dense(32, activation='relu', kernel_initializer='he_uniform')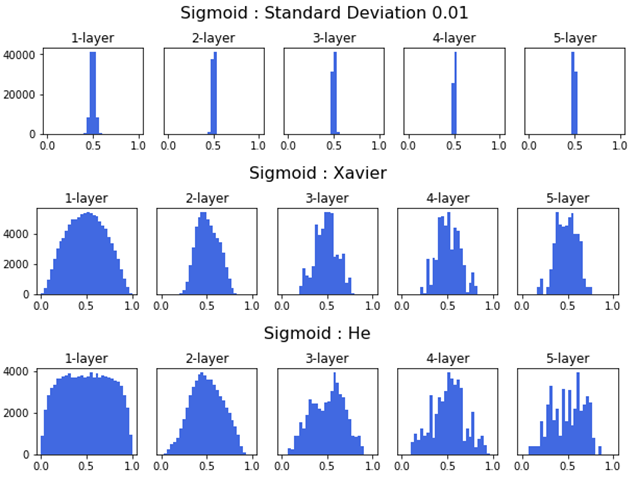
3. 과적합 방지를 위한 방법들
인공 신경망의 노드 수와 층을 늘리다 보면 매개 변수가 상당히 많아진다. Fashion MNIST예제를 풀기 위해서 구축한 신경망에서는 은닉층 없이 출력층만 설계했음에도 7,850개의 파라미터가 있었다. 딥러닝, 즉 은닉층이 3개 이상인 신경망에는 훨씬 더 많은 수의 파라미터가 있다.
머신러닝에서는 모델이 복잡해지면 과적합(Overfitting)문제가 발생하는 경향이 있다. 이러한 과적합 방지를 위해서 사용되는 방법들에 대해 알아보자.
1. Weight Decay(가중치 감소)
과적합은 가중치의 값이 클 때 주로 발생한다. 가중치 감소에서는 가중치가 너무 커지지 않도록 가중치 값이 너무 커지지 않도록 조건을 추가한다. 이 과정에서 손실 함수(Cost function)에 가중치와 관련된 항을 추가하게 된다.
조건을 어떻게 적용할지에 따라 L1 Regularization(LASSO), L2 Regularization(Ridge) 으로 나뉜다. 그 식은 위에 나타내었다.
Keras에서는 아래와 같이 가중치 감소를 적용하고 싶은 층에 regularizer파라미터를 추가하면 된다.
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01))2. Dropout(드롭아웃)
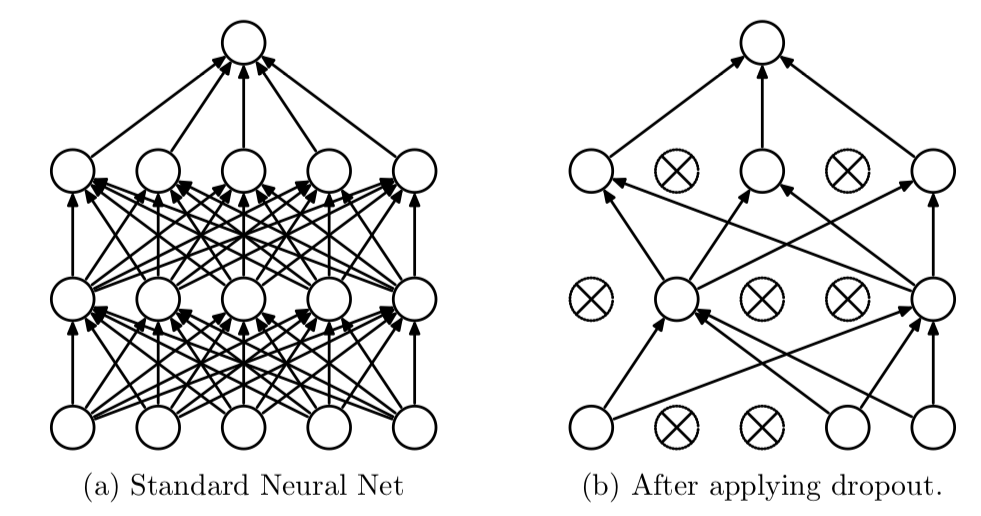
Dropout(드롭아웃)은 Iteration마다 레이어 노드 중 일부를 사용하지 않으면서 학습을 진행하는 방법이다. 매 Iteration마다 랜덤하게 노드를 차단하여 다른 가중치를 학습하도록 조정하기 때문에 과적합을 방지할 수 있게 된다.
Dropout을 적용할 때에는 0 ~ 1 사이의 실수를 입력할 수 있지만, 보통 0.3 ~ 0.5 사이의 값을 사용한다.
Keras에서는 아래와 같이 Dropout을 적용하고 싶은 층 다음에 Dropout함수를 추가하면 된다.
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01))
Dropout(0.5)3. Early Stopping
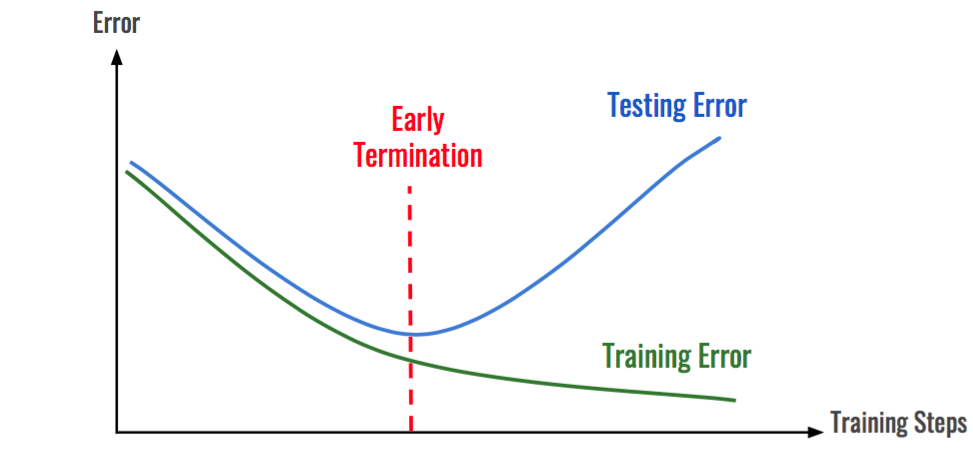
위의 그림에서 볼 수 있는 것처럼 학습(Train)데이터에 대한 손실은 계속 줄어들지만 검증(Validation)데이터셋에 대한 손실은 증가한다면 학습을 종료하도록 설정하는 방법이다.
이제 Fashion MNIST예제에서 구축 신경망에 조기 종료(Early Stopping)를 적용하여 보겠다.
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout
from tensorflow.keras import regularizers
import os
import numpy as np
import tensorflow as tf
import keras
# 시드 고정
np.random.seed(42)
tf.random.set_seed(42)
# 데이터셋 불러오기
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# 데이터 정규화(Normalization)
X_train = X_train / 255.
X_test = X_test / 255.신경망 모델을 구축하고 Compile한다. 이 과정에서 Weight Decay(가중치 감소), Dropout(드롭아웃)을 적용하여 본다.
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64,
kernel_regularizer=regularizers.l2(0.01), # 가중치 감소
activity_regularizer=regularizers.l1(0.01)), # 가중치 감소
Dropout(0.5), # Dropout 적용
Dense(10, activation='softmax')
])compile설정에서 힉습률 감소(Learning rate Decay)를 적용하여 본다.
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001, beta_1 = 0.89)
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])그런 다음 신경망 모델을 학습하고 이 과정에서 Early Stopping을 적용할 수 있도록 파라미터 저장 경로와 조기 종료 옵션을 설정하여 준다.
# 파라미터 저장 경로를 설정하는 코드입니다.
checkpoint_filepath = "FMbest.hdf5"
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
save_best = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath, monitor='val_loss', verbose=1, save_best_only=True,
save_weights_only=True, mode='auto', save_freq='epoch', options=None)위의 코드에서 tf.keras.callbacks.ModelCheckpoint는 어떤 지표로 모니터하고, 어느 경로로 저장하며, 최적의 값만 저장하는지, 또 그중에서 가중치만 저장하는지 등 다양한 설정을 하는 것이다.
model.fit(X_train, y_train, batch_size=32, epochs=30, verbose=1,
validation_data=(X_test,y_test),
callbacks=[early_stop, save_best])콜백(Callback)에 의해 Best 모델의 파라미터가 제대로 저장되었는지 확인하고 해당 모델로 평가를 진행한다.
model.load_weights(checkpoint_filepath)
model.predict(X_test[0:1])
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=1)4. Batch normalization(배치정규화)
배치정규화 참고 사이트
- https://gaussian37.github.io/dl-concept-batchnorm/
- https://buomsoo-kim.github.io/keras/2018/04/24/Easy-deep-learning-with-Keras-5.md/
❗ 참고자료
1. 옵티마이저
2. AMSgrad논문 정리 velog
3. 가중치 초기화
