0. 학습목표
Level 1.
- 신경망에 교차 검증(Cross-Validation)을 적용할 수 있다.
- 하이퍼파라미터 탐색범 중 Grid 탐색법과 Random 탐색법에 대해 말하고 둘을 비교하여 설명할 수 있다.
Level 2.
- 신경망 주요 용어에 대해 한 줄 이상으로 설명할 수 있다.
Level 3.
- 실험 계획 라이브러리인 WandB의 사용법을 익히고 Keras를 엮어서 사용해 볼 수 있다.
1. 교차 검증(Cross-Validation)
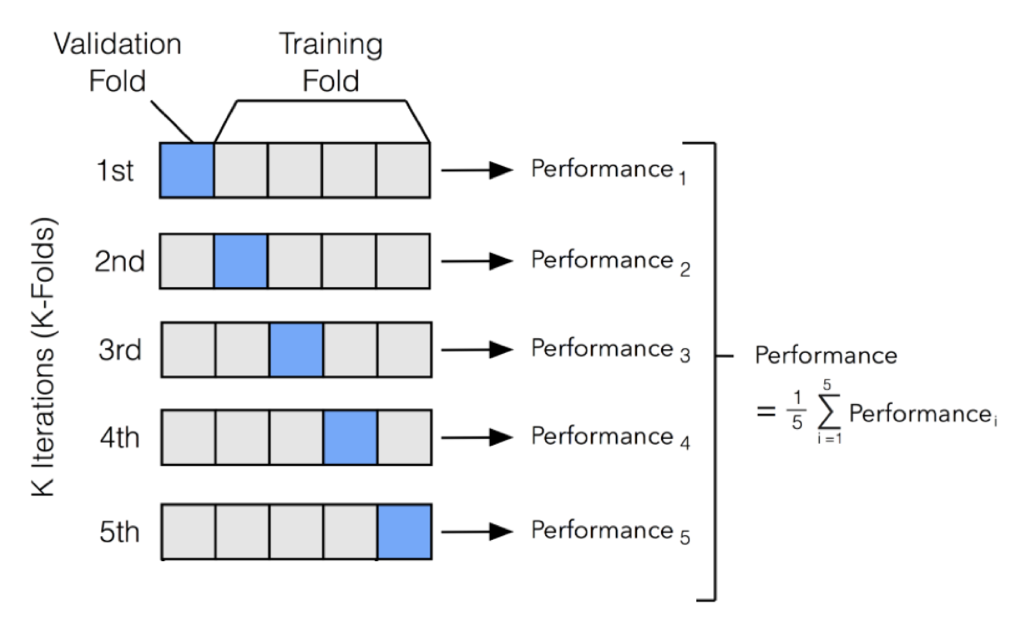
Section2의 N213에서 교차 검증을 다루었다. 교차 검증을 실행할 경우 특정 데이터 세트에 대한 과적합을 방지할 수 있고, 더욱 일반화된 모델을 생성할 수 있다는 장점이 있다. 또한 데이터 세트의 규모가 적을 시 과소적합을 방지할 수도 있다. 하지만 교차 검증을 시행함에 따라서 모델 훈련 및 평가 소요시간이 증가한다는 단점이 있다.
보스턴 집값 실습예제를 통해서 교차 검증이 실제 신경망에서 어떤 식으로 사용되는지 확인하여 보도록 한다.
# 필요한 라이브러리를 import한다.
from tensorflow.keras.datasets import boston_housing
from sklearn.model_selection import KFold, StratifiedKFold
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import tensorflow as tf
import os
# 데이터셋을 불러온다.
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
# 2가지의 Fold 방법
kf = KFold(n_splits = 5)
skf = StratifiedKFold(n_splits = 5, random_state = 42, shuffle = True) 위의 코드에서 2가지 Fold방법이 등장한다. 각각의 차이는 다음과 같다.
-
KFold: K개의 학습데이터 세트를 일정한 간격으로 나누어 평가 진행, 학습/검증 데이터 셋 나누어 진행 -
StratifiedKFold: 불균형한 label비율을 가진 데이터 세트에 적용하는 Fold방법으로 label의 분포 비율을 그대로 유지하여 학습/검증 데이터를 나눈다. 따라서split()메서드에 피처뿐만 아니라 label데이터 세트도 넣어주어야 한다.
계속해서 예제를 진행한다.
x_train = pd.DataFrame(x_train)
y_train = pd.DataFrame(y_train)
# 모델 생성
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(64, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
# 교차검증을 이용한 평과결과 출력
for train_index, val_index in kf.split(np.zeros(x_train.shape[0]),y_train):
training_data = x_train.iloc[train_index, :]
training_data_label = y_train.iloc[train_index]
validation_data = x_train.iloc[val_index, :]
validation_data_label = y_train.iloc[val_index]
# compile
model.compile(loss='mean_squared_error', optimizer='adam')
# 모델 훈련
model.fit(training_data, training_data_label,
epochs=10,
batch_size=32,
validation_data = (validation_data, validation_data_label),
)
# 모델 평가
results = model.evaluate(x_test, y_test, batch_size=32)
print("test loss, test mse:", results)2. 하이퍼 파라미터 튜닝
하이퍼 파라미터란 모델링 시 사용자가 직접세팅하는 값을 뜻한다. 학습률, epoch, batch size, 각 층의 node 수, 은닉 층의 수 등을 하이퍼 파라미터라고 할 수 있다.
그리고 이런 하이퍼 파라미터 튜닝에는 다양한 것이 존재한다.
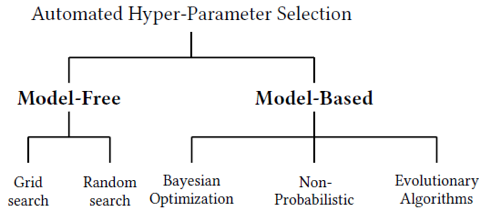
위 사진 외에도 정말 다양한 하이퍼 파리미터 튜닝 방식이 존재하며 manual Search방법을 제외한 나머지 방법을 Automated hyperparameter selection이라고 한다.
1. Babysitting or Grad Student Descent
프로젝트나 스프린트에서 모델의 성능을 높이기 위해 여러 숫자를 직접 넣어보며 하이퍼 파라미터를 조정하였다. 이 방식을 육아(Babysitting) 혹은 대학원생 갈아넣기(Grad student descent)라고 한다.
100% 수작업(manual)으로 파라미터를 수정하는 방법으로 학계에서 논문을 출간할 수 있을 정도로 놀라운 정확도를 보여주는 하이퍼파라미터 수치를 찾아내기 위해 쓰는 방법이다.
2. Grid Search
위의 방식을 자동화한 방법이 바로 Grid Search이다. 이 방법에서는 하이퍼파라미터마다 탐색할 지점을 정해주면 모든 지점에 해당하는 조합을 알아서 수행한다.
자동으로 수행되는만큼 프로그램을 돌려놓기만 하면 끝이다. 하지만 범위를 너무 많이 설정하게 되면 프로그램이 끝날 줄 모르고 계속해서 연산을 수행할 수 있다.
그렇기 때문에 이 방법으로 많은 하이퍼 파라미터를 찾으려고 하는 것 보다는 1개, 혹은 최대 2개 정도의 파라미터 최적값을 찾는 용도로 적합하다. 모델 성능에 보다 직접적인 영향을 주는 하이퍼파라미터가 따로 있기 때문에 굳이 많은 하이퍼 파리미터 조합을 시도할 필요는 없다.
높은 영향을 주는 하이퍼 파라미터만 제대로 튜닝해서 최적값을 찾은 후 나머지 하이퍼 파라미터도 조정해 나가면 못해도 90% 이상의 성능을 확보할 수 있다.
당뇨병 데이터셋을 신경망에 적용해보고 배치 사이즈를 여러 개로 조정하면서 최적의 배치 사이즈와 은닉층의 노드 개수를 찾아보겠다.
인공 신경망 모델을 Scikit-learn에서 사용하기 위해 Wrapping을 해주어야 한다.
Wrapping하는 방법으로 scikeras를 사용해보겠다.
import numpy
import pandas as pd
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# scikeras는 별도 설치 필요하나 설치과정 생략.
from scikeras.wrappers import KerasClassifier
#재현성을 위한 랜덤시드 고정
numpy.random.seed(42)
# 데이터셋 불러오기
url ="https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
dataset = pd.read_csv(url, header=None).values
# Feature와 Label분리
X = dataset[:,0:8]
Y = dataset[:,8]이후 모델을 제작할 때는 KerasClassifier로 Wrapping하기 위하여 신경망 모델을 함수 형태로 정의한다. 그리고 이때 최초 노드의 개수를 정해주어야 정상 작동한다.
# 모델제작
def create_model(nodes=8):
model = Sequential()
model.add(Dense(nodes, input_dim=8, activation='relu'))
model.add(Dense(nodes, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# Wrapping
model = KerasClassifier(model=create_model, batch_size=8, verbose=False)
# 하이퍼파라미터 탐색
nodes = [16, 32, 64]
batch_size = [16, 32, 64]
param_grid = dict(model__nodes=nodes, batch_size=batch_size)
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=1, cv=3)
grid_result = grid.fit(X, Y)
# 최적의 결과를 낸 하이퍼파라미터와 각각의 결과 출력
print(f"Best: {grid_result.best_score_} using {grid_result.best_params_}")
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print(f"Means: {mean}, Stdev: {stdev} with: {param}") 3. Random Search
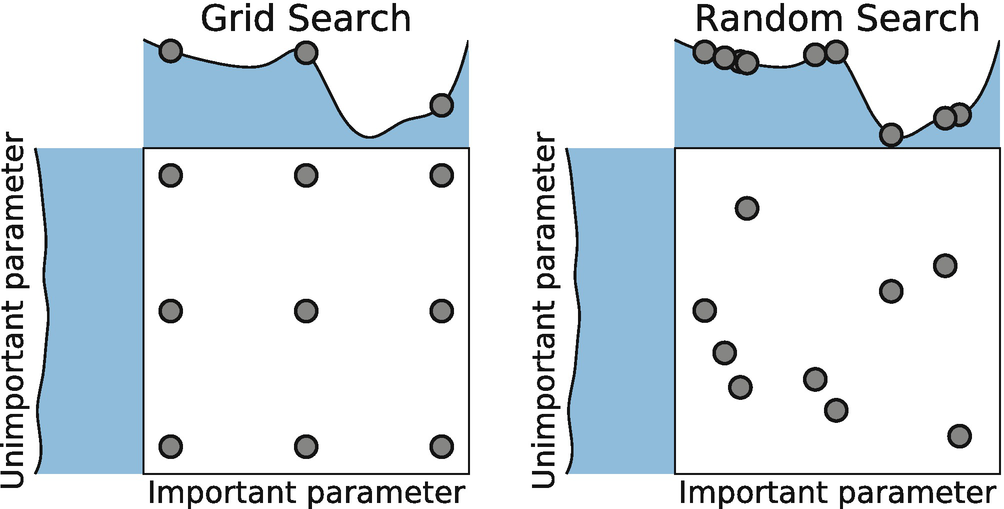
Random Search는 무한 루프는 Grid Search의 단점을 해결하기 위해 나온 방법이다. Random Search는 지정된 범위 내에서 무작위로 모델을 돌려본 후 최고 성능의 모델을 반환한다. 시도 횟수를 정해줄 수 있기 때문에 Grid Search에 비해서 훨씬 적은 횟수로도 끝마칠 수 있다.
Grid Search에서는 하이퍼파라미터의 중요도가 모두 동등하다고 가정한다. 하지만 실제로는 더 중요한 하이퍼파라미터가 있다. Radom Search는 상대적으로 중요한 하이퍼파라미터에 대해서는 탐색을 더 하고, 덜 중요한 하이퍼파라미터에 대해서는 실험을 덜 하도록 한다. 하지만 Random Search는 절대적으로 완벽한 하이퍼파라미터를 찾아주지는 않는다.
4. Bayesian Methods
베이지안 방식(Bayesian Method)은 이전 탐색 결과 정보를 새로운 탐색에 활용하는 방법이다. 그렇기 때문에 베이지안 방법을 사용하면 하이퍼파라미터 탐색 효율을 높일 수 있다.
bayes_opt나 hyperopt와 같은 패키지를 사용하면 베이지안 방식을 적용할 수 있다.
더 정확한 베이지안 정리에 대한 설명은 N121을 참고하자.
3. Keras Tuner
Keras Tuner는 케라스 프레임워크에서 하이퍼파라미터를 튜닝하는 데 도움이 되는 라이브러리이다.
Fashion MNIST예제에 Keras Tuner를 적용하여 하이퍼파라미터 튜닝을 수행하여 보겠다.
from tensorflow import keras
from tensorflow.keras.layers import Dense, Flatten
import tensorflow as tf
import IPython
# Keras Tuner Import하기. 설치과정은 생략함.
import keras_tuner as kt
# 데이터 불러오기 및 정규화(Normalizing)
(X_train, y_train), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()
X_train = X_train.astype('float32') / 255.0
X_test = X_test.astype('float32') / 255.0다음으로는 모델을 제작하고 탐색할 하이퍼파라미터 범위와 지점을 정의한다. 이 과정에서 Model builder함수(model_builder)를 지정하는 과정이 필요하다. 먼저 model_builder라는 함수를 정의하고 해당 함수 내부에서 모델 설계와 하이퍼파라미터 튜닝까지 모두 수행해보겠다.
def model_builder(hp):
model = keras.Sequential()
model.add(Flatten(input_shape=(28, 28)))
hp_units = hp.Int('units', min_value = 32, max_value = 512, step = 32)
model.add(Dense(units = hp_units, activation = 'relu'))
model.add(Dense(10, activation='softmax'))
hp_learning_rate = hp.Choice('learning_rate', values = [1e-2, 1e-3, 1e-4])
model.compile(optimizer = keras.optimizers.Adam(learning_rate = hp_learning_rate),
loss = keras.losses.SparseCategoricalCrossentropy(),
metrics = ['accuracy'])
return model다음으로는 하이퍼파라미터 튜닝을 수행할 튜너(Tuner)를 지정한다. Keras Tuner에서는 Random Search, Bayesian Optimization, Hyperband등의 최적화 방법을 수행할 수 있다.
이번에는 Hyperband를 통해서 튜닝을 수행해보도록 하겠다. Hyperband사용 시 Model builder function(model_builder), 훈련할 최대 epochs 수(max_epochs)등을 지정해주어야 한다. Hyperband 는 리소스를 알아서 조절하고 조기 종료(Early-stopping) 기능을 사용하여 높은 성능을 보이는 조합을 신속하게 통합한다는 장점을 가지고 있다.
tuner = kt.Hyperband(model_builder,
objective = 'val_accuracy',
max_epochs = 10,
factor = 3,
directory = 'my_dir',
project_name = 'intro_to_kt') 하이퍼 파라미터 탐색을 실행하기 전에 학습이 끝날 때마다 이전 출력이 지워지도록 콜백 함수를 정의한다.
class ClearTrainingOutput(tf.keras.callbacks.Callback):
def on_train_end(*args, **kwargs):
IPython.display.clear_output(wait = True)이제 하이퍼 파라미터 탐색을 수행한다.
tuner.search(X_train, y_train, epochs = 10, validation_data = (X_test, y_test), callbacks = [ClearTrainingOutput()])
best_hps = tuner.get_best_hyperparameters(num_trials = 1)[0]
print(f"""
하이퍼 파라미터 검색이 완료되었습니다.
최적화된 첫 번째 Dense 노드 수는 {best_hps.get('units')} 입니다.
최적의 학습 속도는 {best_hps.get('learning_rate')} 입니다.
""")최고 성능을 보이는 하이퍼파라미터 조합으로 다시 학습을 진행해보겠다.
model = tuner.hypermodel.build(best_hps)
model.fit(X_train, y_train, epochs = 10, validation_data = (X_test, y_test))