
Object Detection(객체 탐지)
객체 탐지는 컴퓨터 비전과 이미지 처리와 관련된 기술로서, 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스를 감지하는 일을 다룬다.
Faster R-CNN(NIPS 2015)
Faster R-CNN은 하나의 unified network로 Detection과제를 수행한다.
feature maps는 RPN을 통과해서 바운딩 박스를 출력한다. 그 후에 바운딩 박스에 해당하는 feature maps는 크롭해서 ROI Pooling과 classificaion을 수행한다.
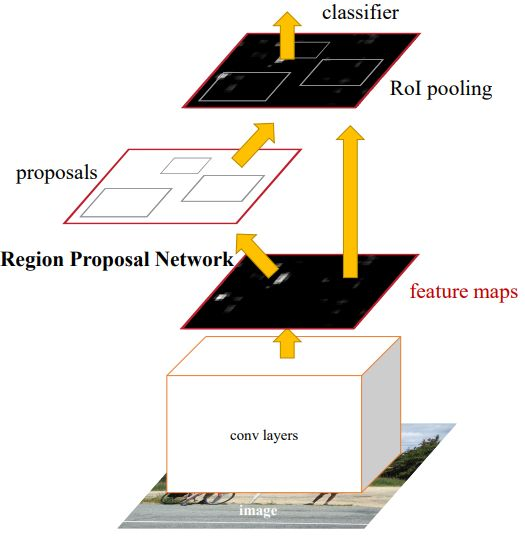
RPN은 이미지를 아래와 같이 빨간색 격자 무늬로 쪼갠 후, 파란색처럼 앵커 박스라는 개념을 도입한다. 빨간색 박스 하나당 미리 정의된 앵커 박스 여러 개가 있고, 앵커 박스 안에 object가 있다고 가정한(가장 알맞다고 예상되는) 박스를 찾는다.
앵커 박스의 크기가 고정되어 있기에 논문에서는 3가지 방법을 제시하는데, 첫번째는 이미지 자체의 크기(scale)를 줄여가며 다음은 필터의 크기를 33이나 77 등 물체의 크기에 맞춰 검출되도록 조절하는 것이고 마지막으로 레퍼런스(앵커 박스처럼 해당 물체에 적합한 박스들을 미리 여러개의 사이즈로 구분)를 여러 개를 사용한다.

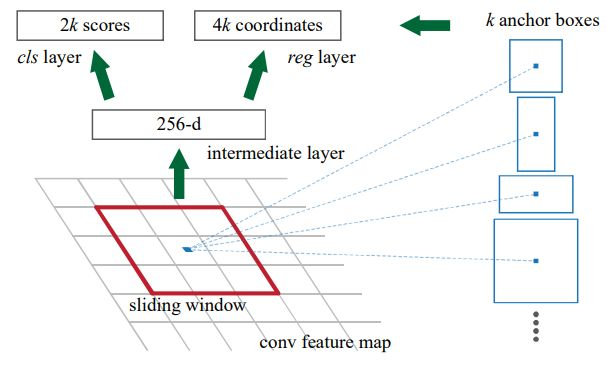
RPN은 sliding window를 정의하고 feature maps을 움직이며 계산을 하고 하나의 sliding window에 2k scores와 4k coordinates를 출력한다.
2k scores는 해당 sliding window에 개체가 있는지 없는지를, 4k coordinates는 미리 정의된 각 앵커 박스들의 중심점 위치와 높이와 넓이를 출력한다.
Faster R-CNN은 최적의 박스를 찾을 때 NMS(Non-Maximum Suppression)이라는 방법을 사용한다. 이 방법은 하나의 물체를 가리키는 여러 개의 박스들 중에서 하나만 남기는 방법으로, Confidence Score와 IOU에 의해 결정된다.
Confidence Score는 박스 안에 객체가 있을 Score의 값이다. Confidence Score를 정의하고 낮은 점수를 가진 박스들을 다 제거한다. 그리고 가장 높은 값을 가지는 박스에 대해서 주변 박스들의 IOU를 계산한다. IOU는 두 박스가 얼마나 겹쳐있는지 나타내는 값이다.(교집합/합집합)
그리고 너무 많이 겹치는 박스들을 제거하고 한 객체에 대해서 Confidence Score가 가장 높은 하나의 박스만 남게 된다. IOU Score가 일정 수준 이하로 낮다면 그것은 다른 객체로 구분하게 되어 인스턴스별 detection이 가능해진다.
Loss functions은 classification loss와 바운딩 박스 regression loss를 함계 사용한다.
그리고 평가 지표로는 mAP(mean Average Precision)을 사용한다. AP는 Precision-recall 그래프를 단조 감소 함수로 변경한 후 계산한 면적이며, 복수의 class에 대한 AP 값의 평균을 mAP라고 한다.
데이터
kaggle의 Open-Images-Bus-Trucks를 사용한다.
데이터셋
- 이미지 : kaggle
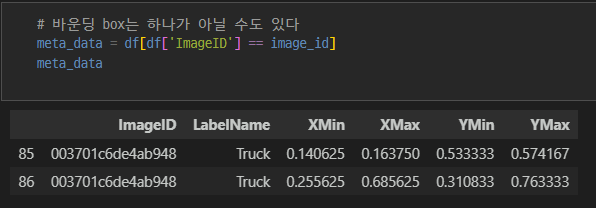
- csv : 이미지 파일 이름, label(class) name, Confidence Score, 바운딩 박스 좌표
소스코드 : GitHub
GPU 사용을 위해 구글 코랩 환경에서 진행한다.
Object Detection - Bus/Truck
데이터 나누기
전체 데이터를 train/val/test를 8:1:1 비율로 나눈다.
# 데이터 전체 수
data_len = os.listdir(data_dir + '/images')
len(data_len)
>
15225
# 데이터셋 비율 - 8:1:1
split_ratio = [0.8, 0.1, 0.1]
train_len = int(len(data_len) * split_ratio[0])
val_len = int(len(data_len) * split_ratio[1])
test_len = len(data_len) - train_len - val_len
print('{}, {}, {}'.format(train_len, val_len, test_len))
>
12180, 1522, 1523하나의 이미지에 여러 class가 있다.
데이터셋 구축
dataset 정의
class MyDataset():
def __init__(self, data_dir, phase, transform=None):
super().__init__()
self.data_dir = data_dir
self.phase = phase
self.df = pd.read_csv(os.path.join(self.data_dir, 'df.csv'))
self.image_files = [file_name for file_name in os.listdir(os.path.join(self.data_dir, phase)) if file_name.endswith('jpg')]
self.transform = transform
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
file_name, image = self.get_image(index)
boxes, class_ids = self.get_label(file_name)
img_h, img_w, _ = image.shape
if self.transform:
image = self.transform(image)
_, img_h, img_w = image.shape
boxes[:, [0, 2]] *= img_w
boxes[:, [1, 3]] *= img_h
target = {}
target['boxes'] = torch.Tensor(boxes).float()
target['labels'] = torch.Tensor(class_ids).long()
return image, target, file_name
def get_image(self, index):
file_name = self.image_files[index]
image_path = os.path.join(self.data_dir, self.phase, file_name)
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return file_name, image
def get_label(self, file_name):
image_id = file_name.split('.')[0]
meta_data = self.df[self.df['ImageID'] == image_id]
label_names = meta_data['LabelName'].values
class_ids = np.array([CLASS_NAME_TO_ID[label_name] for label_name in label_names])
boxes = meta_data[['XMin', 'XMax', 'YMin', 'YMax']].values
boxes[:, [1, 2]] = boxes[:, [2, 1]] # -> xmin, ymin, xmax, ymax
return boxes, class_idsdataloader 정의
IMAGE_SIZE = 448
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(size=(IMAGE_SIZE, IMAGE_SIZE)),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
# 바운딩 박스 색
def collate_fn(batch):
image_list = []
filename_list = []
target_list = []
for a, b, c in batch: # image, target, file name
image_list.append(a)
target_list.append(b)
filename_list.append(c)
return image_list, target_list, filename_list
# 정의
def build_dataloader(data_dir, batch_size=BATCH_SIZE, image_size=IMAGE_SIZE):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(size=(IMAGE_SIZE, IMAGE_SIZE)),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
dataloaders = {}
train_dataset = MyDataset(data_dir=data_dir, phase='train', transform=transform)
val_dataset = MyDataset(data_dir=data_dir, phase='val', transform=transform)
test_dataset = MyDataset(data_dir=data_dir, phase='test', transform=transform)
dataloaders['train'] = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn)
dataloaders['val'] = DataLoader(val_dataset, batch_size=1, shuffle=False, collate_fn=collate_fn)
dataloaders['test'] = DataLoader(test_dataset, batch_size=1, shuffle=False, collate_fn=collate_fn)
return dataloadersFaster R-CNN detection 아키텍쳐
사전 학습된 모델을 fasterrcnn_resnet50_fpn 불러와서 사용한다. fasterrcnn_resnet50_fpn은 자동으로 loss를 계산한다.
def build_model(num_classes):
model = models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return modeltrain
# train 정의
def train_one_epoch(dataloaders, model, optimizer, device):
train_loss = defaultdict(float)
val_loss = defaultdict(float)
# fasterrcnn_resnet50_fpn은 loss를 자동으로 계산한다.
model.train()
for phase in ['train', 'val']:
for index, batch in enumerate(dataloaders[phase]):
images = batch[0]
targets = batch[1]
filename = batch[2]
images = list(image.to(device) for image in images)
targets = list({k: v.to(device) for k, v in target.items()} for target in targets)
with torch.set_grad_enabled(phase=='train'):
loss = model(images, targets)
total_loss = sum(each_loss for each_loss in loss.values())
if phase == 'train':
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
if (index > 0) and (index % VERBOSE_FREQ) == 0:
text = f"{index}/{len(dataloaders[phase])} - "
for k, v in loss.items():
text += f"{k}: {v.item():.4f} "
print(text)
for k, v in loss.items():
train_loss[k] += v.item()
train_loss['total_loss'] += total_loss.item()
else:
for k, v in loss.items():
val_loss[k] += v.item()
val_loss['total_loss'] += total_loss.item()
for k in train_loss.keys():
train_loss[k] /= len(dataloaders['train'])
val_loss[k] /= len(dataloaders['val'])
return train_loss, val_loss
# 파라미터 조정
data_dir = '/content/data/'
is_cuda = True
NUM_CLASSES = 2
IMAGE_SIZE = 448
BATCH_SIZE = 6
VERBOSE_FREQ = 10
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 모델 정의
dataloader = build_dataloader(data_dir=data_dir, batch_size=BATCH_SIZE, image_size=IMAGE_SIZE)
model = build_model(num_classes=NUM_CLASSES)
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
num_epochs = 1
train_losses = []
val_losses = []
# 학습 진행
for epoch in range(num_epochs):
train_loss, val_loss = train_one_epoch(dataloaders, model, optimizer, DEVICE)
train_losses.append(train_loss)
val_losses.append(val_loss)
print(f'EPOCH : {epoch+1}/{num_epochs} - Train Loss : {train_loss["total_loss"]:.4f}, Val Loss : {val_loss["total_loss"]:.4f}')
# if epoch+1 % 10 == 0:
# utils.save_model(model.state_dict(), f'model_{epoch+1}.pth')
utils.save_model(model.state_dict(), f'model_{epoch+1}.pth')NMS 적용
torchvision에서 지원하는 nms를 사용한다.
학습된 모델을 불러온다.
def load_model(ckpt_path, num_classes, device):
checkpoint = torch.load(ckpt_path, map_location=device)
model = build_model(num_classes=num_classes)
model.load_state_dict(checkpoint)
model = model.to(device)
model.eval()
return model
model = load_model(ckpt_path='/content/data/trained_model/model_1.pth', num_classes=NUM_CLASSES, device=DEVICE)Confidence Score 기반으로 필러링 후 NMS를 적용한다. nms에는 boxes(x_min, y_min, x_max, y_max 4개 좌표), scores, iou threshold를 인자로 넣는다. torchvision에서 지원하는 f r-cnn은 자동으로 prediction 값을 지원한다.
def postprocess(prediction, conf_threshold=0.2, IoU_threshold=0.5):
pred_box = prediction['boxes'].cpu().detach().numpy()
pred_label = prediction['labels'].cpu().detach().numpy()
pred_conf = prediction['scores'].cpu().detach().numpy()
# confidence filtering
conf_thres = 0.2
test_index = pred_conf > conf_thres
pred_box = pred_box[test_index]
pred_label = pred_label[test_index]
pred_conf = pred_conf[test_index]
# NMS filtering, tensor로 변환해야 한다.
test_index = nms(torch.tensor(pred_box.astype(np.float32)), torch.tensor(pred_conf), IoU_threshold)
pred_box = pred_box[test_index.numpy()]
pred_conf = pred_conf[test_index.numpy()]
pred_label = pred_label[test_index.numpy()]
return np.concatenate((pred_box, pred_conf[:, np.newaxis], pred_label[:, np.newaxis]), axis=1)
# test
pred_images = []
pred_labels = []
for index, (images, _, filename) in enumerate(dataloaders['test']):
images = list(image.to(DEVICE) for image in images)
filename = filename[0]
image = make_grid(images[0].cpu().detach(), normalize=True).permute(1, 2, 0).numpy()
image = (image*255).astype(np.uint8)
with torch.no_grad():
prediction = model(images)
prediction = postprocess(prediction[0])
prediction[:, 2].clip(min=0, max=image.shape[1])
prediction[:, 3].clip(min=0, max=image.shape[0])
xc = (prediction[:, 0] + prediction[:, 2]) / 2
yc = (prediction[:, 1] + prediction[:, 3]) / 2
w = prediction[:, 2] - prediction[:, 0]
h = prediction[:, 3] - prediction[:, 1]
cls_id = prediction[:, 5]
prediction_yolo = np.stack([xc, yc, w, h, cls_id], axis=1)
pred_images.append(image)
pred_labels.append(prediction_yolo)
@interact(index=(0, len(pred_images)-1))
def show_result(index=0):
result = utils.visualize(pred_images[index], pred_labels[index][:, 0:4], pred_labels[index][:, 4])
plt.figure(figsize=(6, 6))
plt.imshow(result)
plt.show()test
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(size=(IMAGE_SIZE, IMAGE_SIZE)),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
from google.colab.patches import cv2_imshow
cap = cv2.VideoCapture(video_path) # video_path : 샘플 비디오 위치
while cap.isOpened():
ret, frame = cap.read()
if ret:
since = time()
ori_h, ori_w = frame.shape[:2]
prediction = model_predict(frame, model, DEVICE)
prediction = postprocess(prediction[0])
prediction[:, [0, 2]] *= (ori_w/IMAGE_SIZE)
prediction[:, [1, 3]] *= (ori_h/IMAGE_SIZE)
prediction[:, 2].clip(max=ori_w)
prediction[:, 3].clip(max_ori_h)
xc = (prediction[:, 0] + prediction[:, 2]) / 2
yc = (prediction[:, 1] + prediction[:, 3]) / 2
w = prediction[:, 2] - prediction[:, 0]
h = prediction[:, 3] - prediction[:, 1]
cls_id = prediction[:, 5]
prediction_yolo = np.stack([xc, yc, w, h, cls_id], axis=1)
canvas = visualize(frame, prediction_yolo[:, 0:4], prediction[:, 4])
text = f'{(time() - since) * 1000:.0f}ms/image'
cv2.putText(canvas, text, (20, 40), cv2.FONT_HERSHEY_PLAIN, 2, (255, 255, 255), 2)
cv2_imshow(frame)
key = cv2.waitKey(1)
if key == 27:
break
if key == ord('s'):
cv2.waiKey()
cap.release()
cv2.destroyAllWindows()