
Object Detection(객체 탐지)
객체 탐지는 컴퓨터 비전과 이미지 처리와 관련된 기술로서, 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스를 감지하는 일을 다룬다.
SSD(ECCV 2016)
'SSD'는 'Faster R-CNN'의 개선 버전이라고 볼 수 있다.
Faster R-CNN에서 앵커 박스의 크기가 유연하지 못하다는 단점과 3개의 sub-network들이 유기적으로 작동하는 가에 대한 의문점이 있다.
SSD는 Feature pyramid를 사용하면 앵커 박스의 크기가 달라진다는 점에 초점을 맞춘다. 아래의 a 이미지에서 2개의 객체는 크기가 다른데, 고정된 앵커 박스의 크기가 8×8 feature maps에서는 고양이를 4×4 feature maps에서는 개를 탐지하게 된다. 즉 앵커 박스는 그대로지만 feature maps의 크기가 바뀜으로써 앵커 박스가 상대적으로 커지는 효과를 가지게 된다.
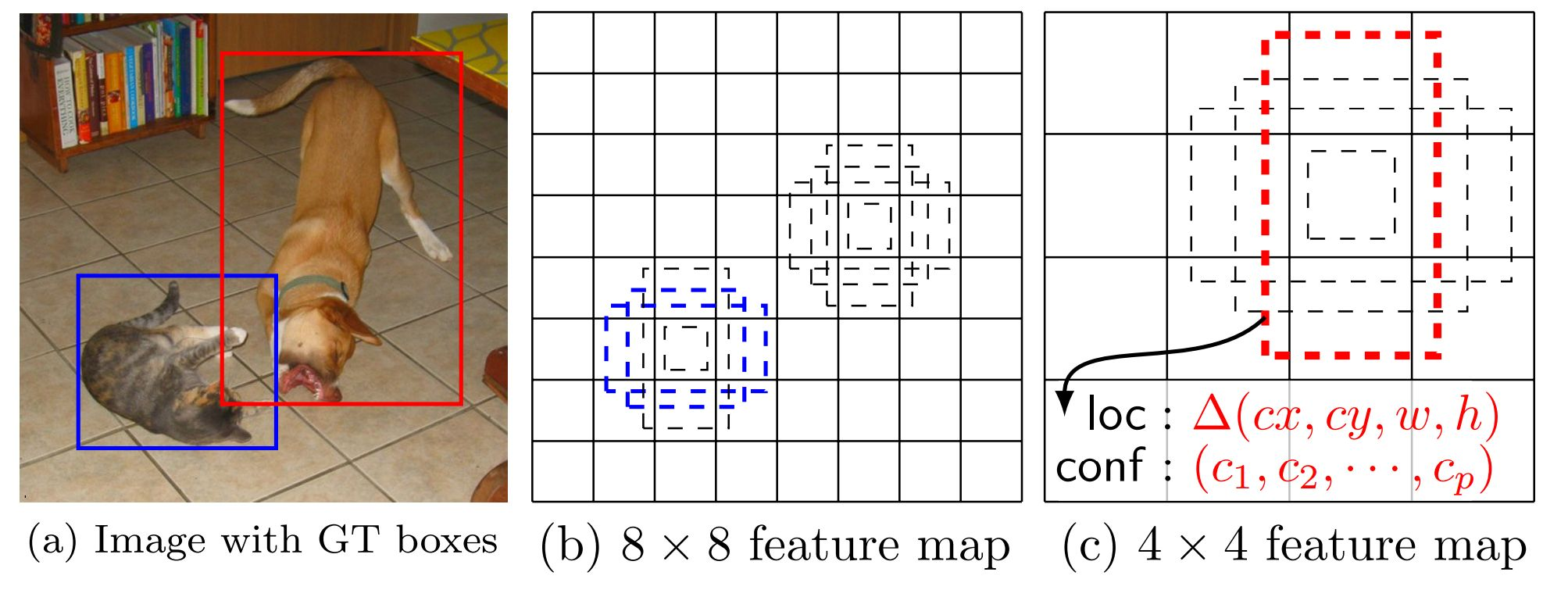
기존부터 CNN 계열은 multi-scale-feature map을 사용해왔다. 아래의 그림과 같이 feature map 사이즈를 줄여가며 학습을 진행한 것에 착안한다.
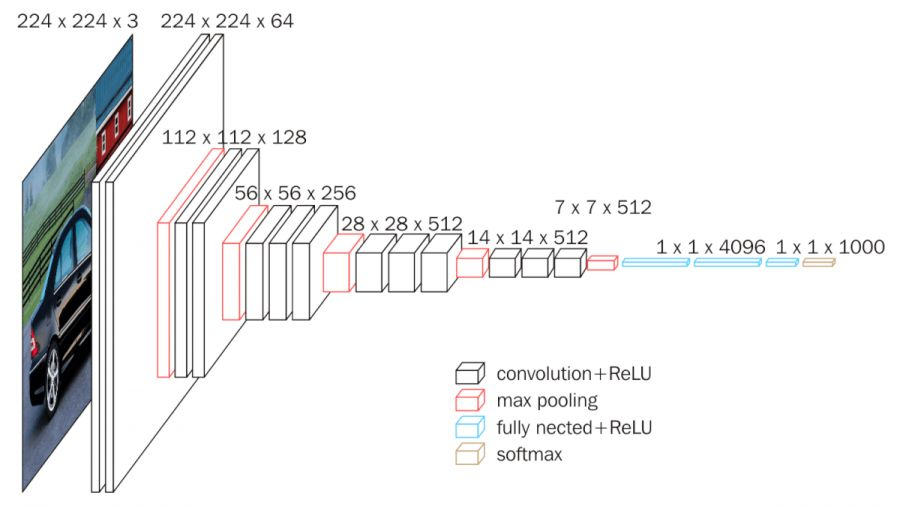
그래서 feature map이 큰 쪽에서는 작은 객체들을, 작은 쪽에서는 큰 객체들을 탐지하게 된다.
300×300 feature map을 받아서 38×38 feature map에서는 38×38×4를 그 다음 레졸루션부터는 feature map × feature map × 6 또는 4의 앵커 박스가 생기게 된다. 그래서 탐지하는 앵커 박스의 수는 8732개가 생기게 된다. 그리고 최종적으로 NMS를 적용하여 바운딩 박스를 정하게 된다.
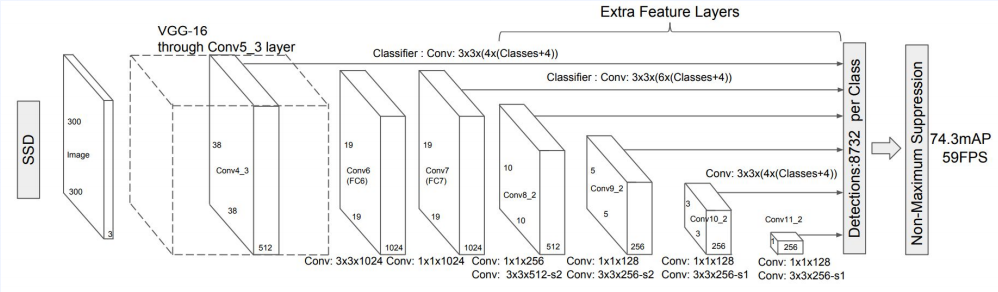
detection model들은 포지티브 샘플(pos sample)에 비해 네거티브 샘플(neg sample)이 많을 수 밖에 없다. 그래서 학습에서 언벨런스가 생기고, 이것을 해결하기 위해 네거티브 샘플들 중에서 confidence score가 굉장히 높은 네거티브 샘플들만 학습에 사용하면서(약 1:3비율) 비율을 맞췄다.
모델링
소스 코드 : GitHub
ResNet을 backbone으로 사용
class ResNet(nn.Module):
def __init__(self):
super().__init__()
backbone = resnet50(pretrained=True)
self.out_channels = [1024, 512, 512, 256, 256, 256]
self.feature_extractor = nn.Sequential(*list(backbone.children())[:7]) # 7개까지만 사용
conv4_block1 = self.feature_extractor[-1][0]
conv4_block1.conv1.stride = (1, 1)
conv4_block1.conv2.stride = (1, 1)
conv4_block1.downsample[0].stride = (1, 1)
def forward(self, x):
x = self.feature_extractor(x)
return xSSD model
class Base(nn.Module):
def __init__(self):
super().__init__()
def init_weights(self):
layers = [*self.additional_blocks, *self.loc, *self.conf]
for layer in layers:
for param in layer.parameters():
if param.dim() > 1:
nn.init.xavier_uniform_(param)
def bbox_view(self, src, loc, conf):
ret = []
for s, l, c in zip(src, loc, conf):
ret.append((l(s).view(s.size(0), 4, -1), c(s).view(s.size(0), self.num_classes, -1)))
locs, confs = list(zip(*ret))
locs, confs = torch.cat(locs, 2).contiguous(), torch.cat(confs, 2).contiguous()
return locs, confs
class SSD(Base):
def __init__(self, backbone=ResNet(), num_classes=81):
super().__init__()
self.feature_extractor = backbone
self.num_classes = num_classes
self._build_additional_features(self.feature_extractor.out_channels) # 추가적인 feature map 계
self.num_defaults = [4, 6, 6, 6, 4, 4] # 앵커 박스 개수
self.loc = []
self.conf = []
for nd, oc in zip(self.num_defaults, self.feature_extractor.out_channels):
self.loc.append(nn.Conv2d(oc, nd * 4, kernel_size=3, padding=1))
self.conf.append(nn.Conv2d(oc, nd * self.num_classes, kernel_size=3, padding=1))
self.loc = nn.ModuleList(self.loc)
self.conf = nn.ModuleList(self.conf)
self.init_weights()
def _build_additional_features(self, input_size):
self.additional_blocks = []
for i, (input_size, output_size, channels) in enumerate(
zip(input_size[:-1], input_size[1:], [256, 256, 128, 128, 128])):
if i < 3:
layer = nn.Sequential(
nn.Conv2d(input_size, channels, kernel_size=1, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU(inplace=True),
nn.Conv2d(channels, output_size, kernel_size=3, padding=1, stride=2, bias=False), # 차이
nn.BatchNorm2d(output_size),
nn.ReLU(inplace=True),
)
else:
layer = nn.Sequential(
nn.Conv2d(input_size, channels, kernel_size=1, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU(inplace=True),
nn.Conv2d(channels, output_size, kernel_size=3, bias=False), # 차이
nn.BatchNorm2d(output_size),
nn.ReLU(inplace=True),
)
self.additional_blocks.append(layer)
self.additional_blocks = nn.ModuleList(self.additional_blocks)
def forward(self, x):
x = self.feature_extractor(x) # ResNet 통과
detection_feed = [x]
for l in self.additional_blocks:
x = l(x)
detection_feed.append(x)
locs, confs = self.bbox_view(detection_feed, self.loc, self.conf)
return locs, confs