Object Detection(객체 탐지)
객체 탐지는 컴퓨터 비전과 이미지 처리와 관련된 기술로서, 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스를 감지하는 일을 다룬다.
Finding Tiny Faces(CVPR 2017)
아주 작은 얼굴들을 탐지하기 위해서 어떤 기술적 테크닉들이 필요한지 살펴보자.

객체 탐지를 위해 5가지의 approaches를 이야기 한다.
먼저 고정된 사이즈의 얼굴을 디텍션할 수 있는 템플릿을 정해놓고 이미지 피라미드를 만들어서 해당 얼굴 영역을 찾는다. 원본 상태에서 영상 크기를 줄여가며 여러 템플릿에 탐지를 하여 구체적인 얼굴이 매칭되는 것을 찾을 수 있도록 한다.
그리고 기존의 SSD나 YOLO처럼 이미지 안의 여러 스캐일별 얼굴을 탐지할 수 있는 방법으로 찾는다.
나머지 3가지 테크닉을 제시한다.
먼저 이미지 피라미드를 만들고 이미지의 스케일과 템플릿(앵커 박스)의 크기를 복합해서 쓰며, 얼굴만이 아니라 fixed-size의 얼굴을 포함하는 것을 보고 분류를 해야한다고 제시한다. 마지막으로 마지막 레이어의 피쳐만 사용하는 것이 아니라 앞쪽 레이어의 리쳐들도 함께 사용해야 함을 제시한다.


기존의 SSD나 YOLO 및 ResNet 등에서 사용되던 방법들이다. 그래서 무엇이 다른가.
Context information to find small faces
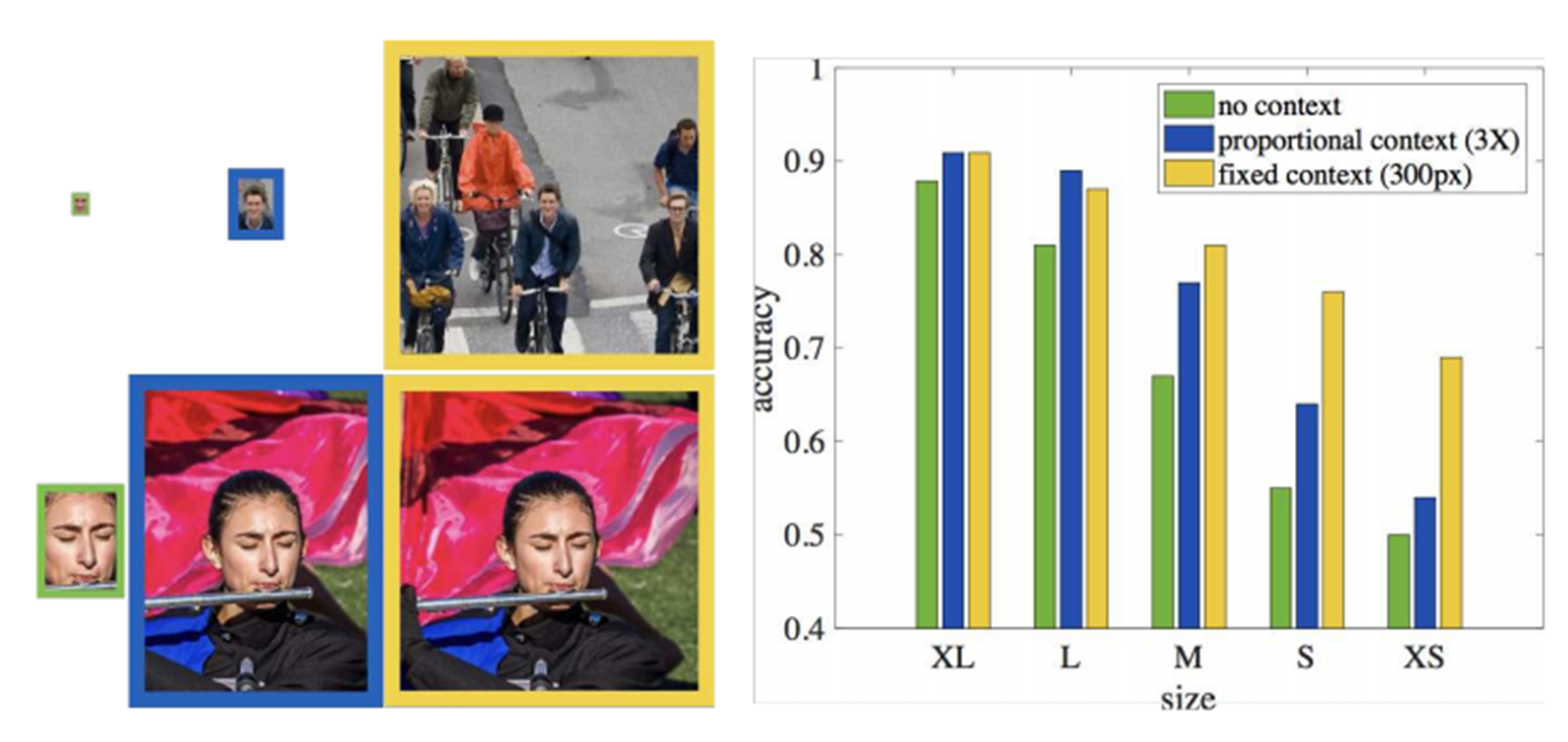
아래의 그림에서 왼쪽 위의 그림은 작은 얼굴을 아래는 큰 얼굴을 갖는 그림이다. 그리고 초록색은 작은 바운딩 박스를 파란색은 얼굴에 맞는 세배 비율의 박스를 노란색은 fixed-size로 얼굴에 상관없이 300필셀로 구분을 한다.
아래 오른쪽 그림은 얼굴 사이즈가 다를 때의 결과인데, context를 반영한 것이 결과가 더 좋다는 것을 반영하고 있는 그림이다. 이 성능의 차이가 사이즈가 작아질수록 fixed-size가 훨씬 좋음을 알 수 있다.
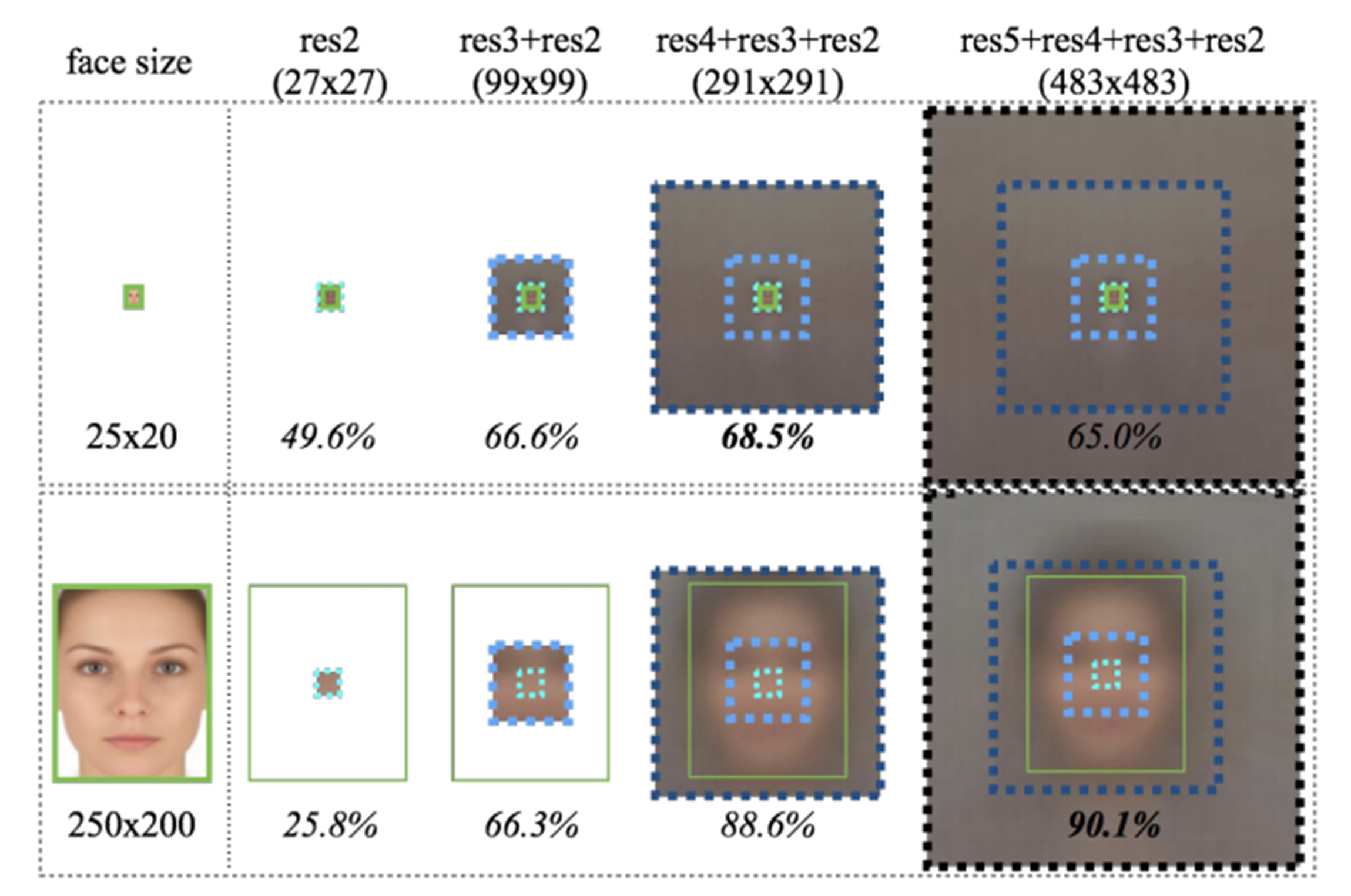
아래 그림에서, face size를 두고 receptive field가 커질수록 정확도가 높아지는 경향이 있음을 알 수 있다.
Foveal descriptor using multiple layers in a deep network
하나의 피쳐만 사용하는 것이 아니라, ResNet skip-connector처럼 앞쪽 레이어의 피쳐를 더했을 때 성능이 더 좋아지는 것을 확인할 수 있다. 특히 res3-4까지는 비슷하나 res5까지 가서 비교를 했을 때 확연한 차이가 있고 작은 얼굴을 탐지할 때 월등한 성능 향상이 있음을 확인할 수 있다. 그래서 논문에서는 Context information을 위해서 무조건 마지막 레이어에서만 결과를 출력하는 것은 반드시 좋은 결과를 나타내지 않는다고 주장한다.
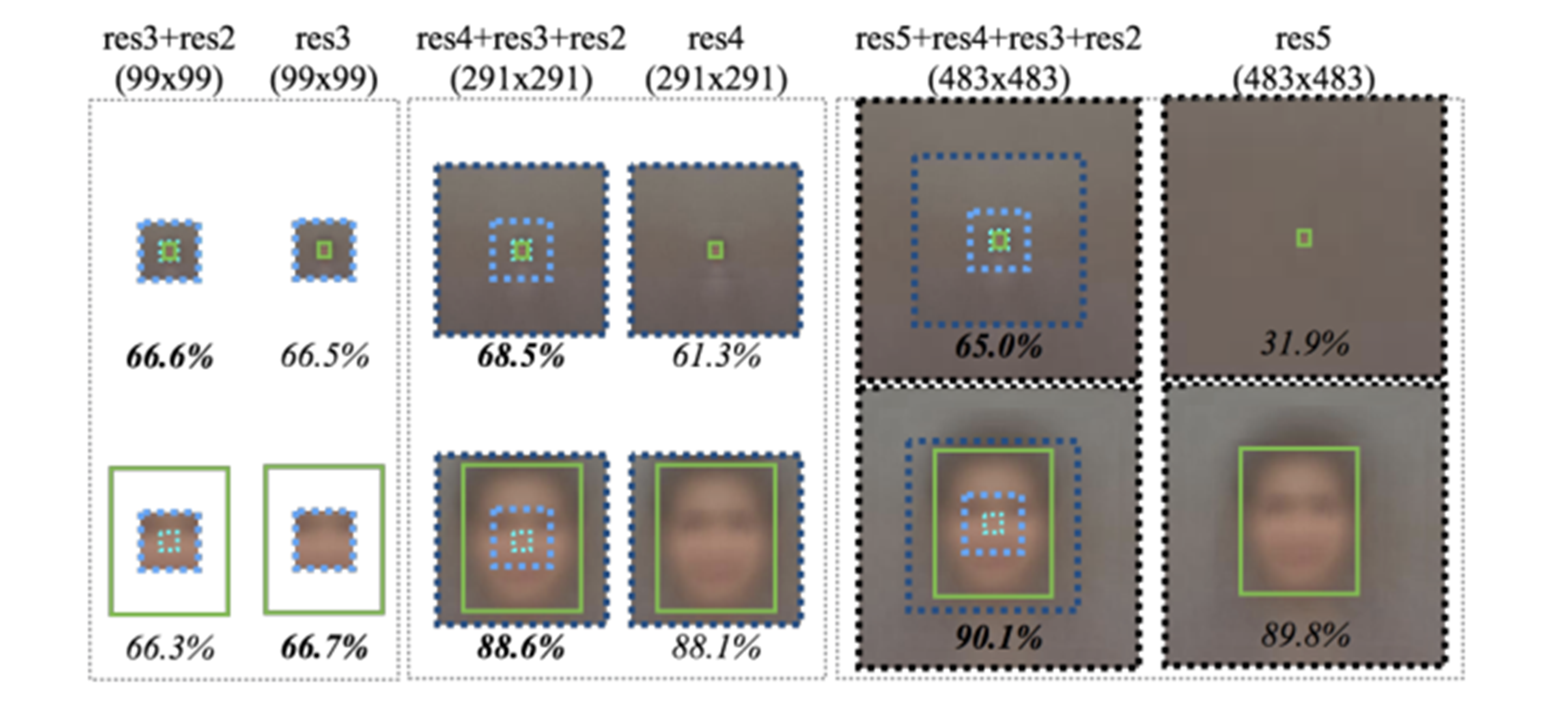
Image scale
얼굴의 크기에 따라서 객체 탐지의 성능이 달라지는데, 그렇다면 얼굴을 탐지하기 위해서 가장 좋은 패치 사이즈는 얼마인지를 고민하게 된다.
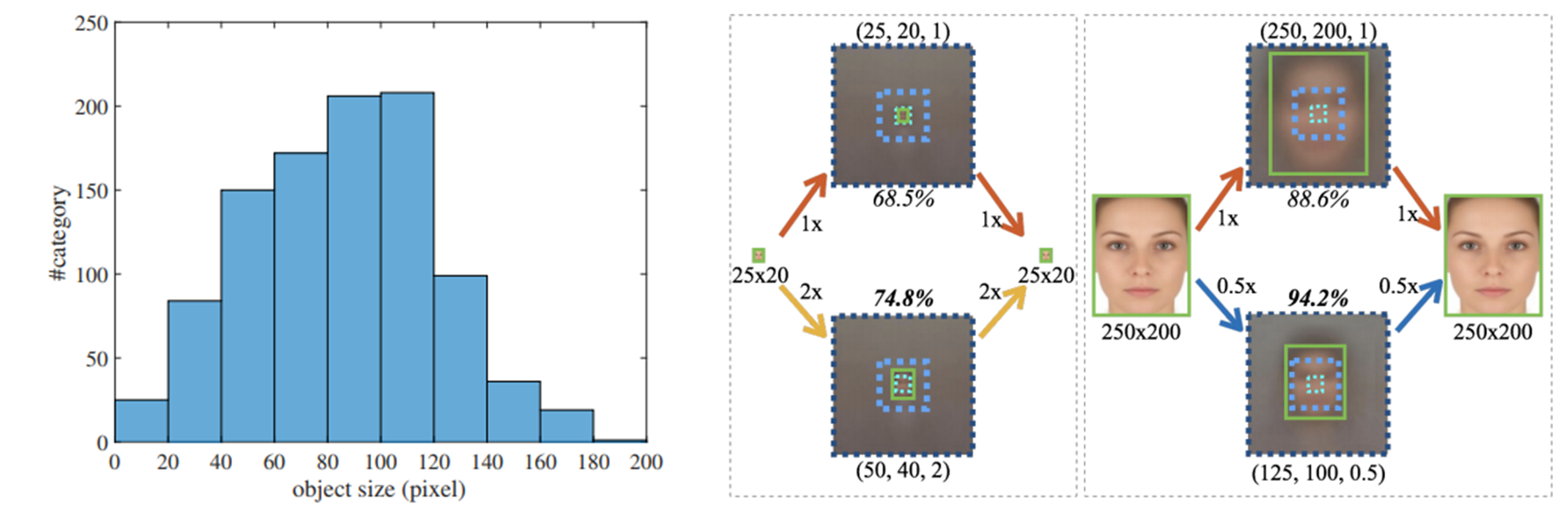
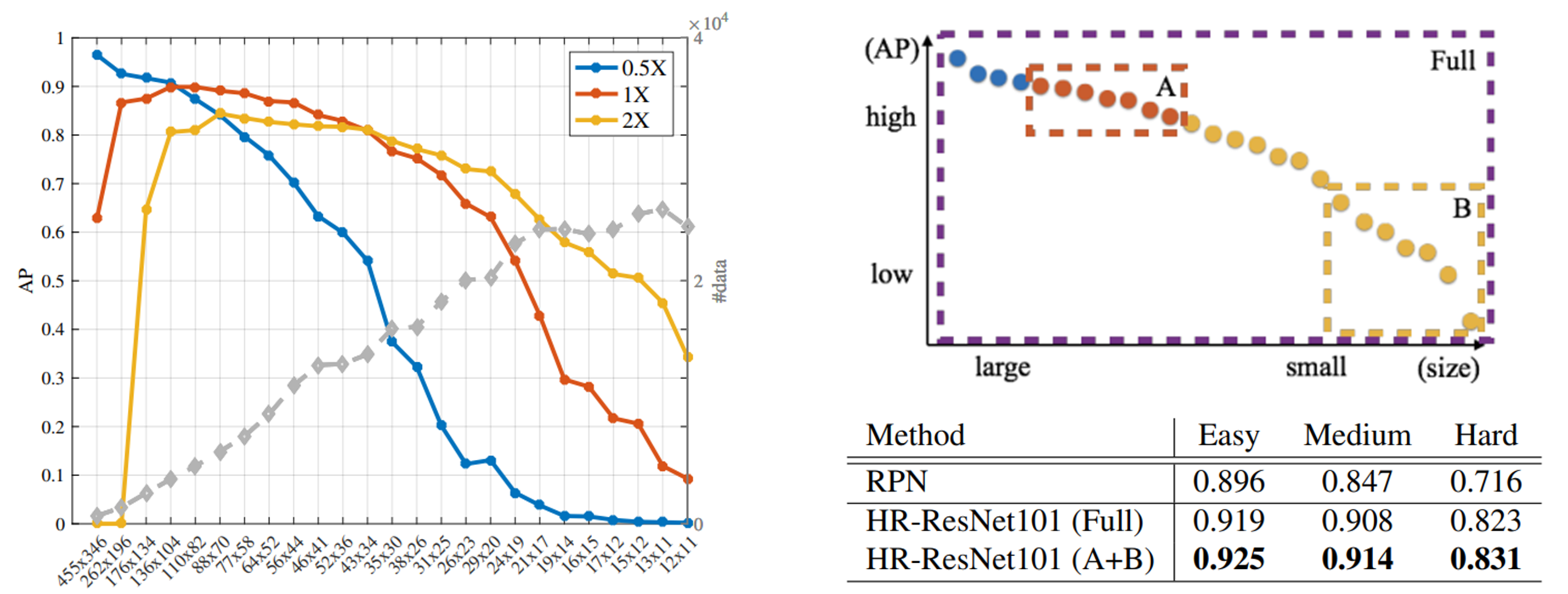
아래 오른쪽 그림에서 작은 얼굴은 사이즈를 2배 키웠을 때 약 10% 정도의 성능 향상을 가지고, 큰 얼굴은 사이즈를 2배 줄였을 때 약 5% 정도의 성능 향상을 가지고 있다. 즉 무조건 얼굴 사이즈가 크다고 성능 향상과 직결되지는 않는다고 주장한다. 그래서 논문 저자들은 객체의 크기보다 크기들의 분포에 이슈가 있다고 말한다.
아래 왼쪽 그림에서처럼, 너무 작은 사이즈나 큰 사이즈는 샘플 수가 부족해서 탐지가 안되는 것이라 주장을 한다.
그렇다면 어떻게 사이즈가 다른 객체들을 크기에 상관없이 잘 탐지할 수 있을까.
논문에서는, CNN 모델을 특정한 객체 사이즈에 맞춰 학습하는 방법을 제시하게 된다.
입력 영상이 주어졌을 때, 기존 영상과 2배 키운 영상과 2배 줄인 영상인 3가지의 피라미드를 만들고 end-to-end로 학습을 진행한다. 그리고 기존의 영상에서는 중간 정도의 객체를 2배 키운 영상에서는 작은 객체를 반으로 줄인 영상에서는 큰 객체를 추출을 한다. 즉 바운딩 박스의 필셀 크기로 로스를 정의하고 탐지를 한다. 그리고 추출된 객체들을 합치고 NMS를 통해 최종 출력을 하게 된다.
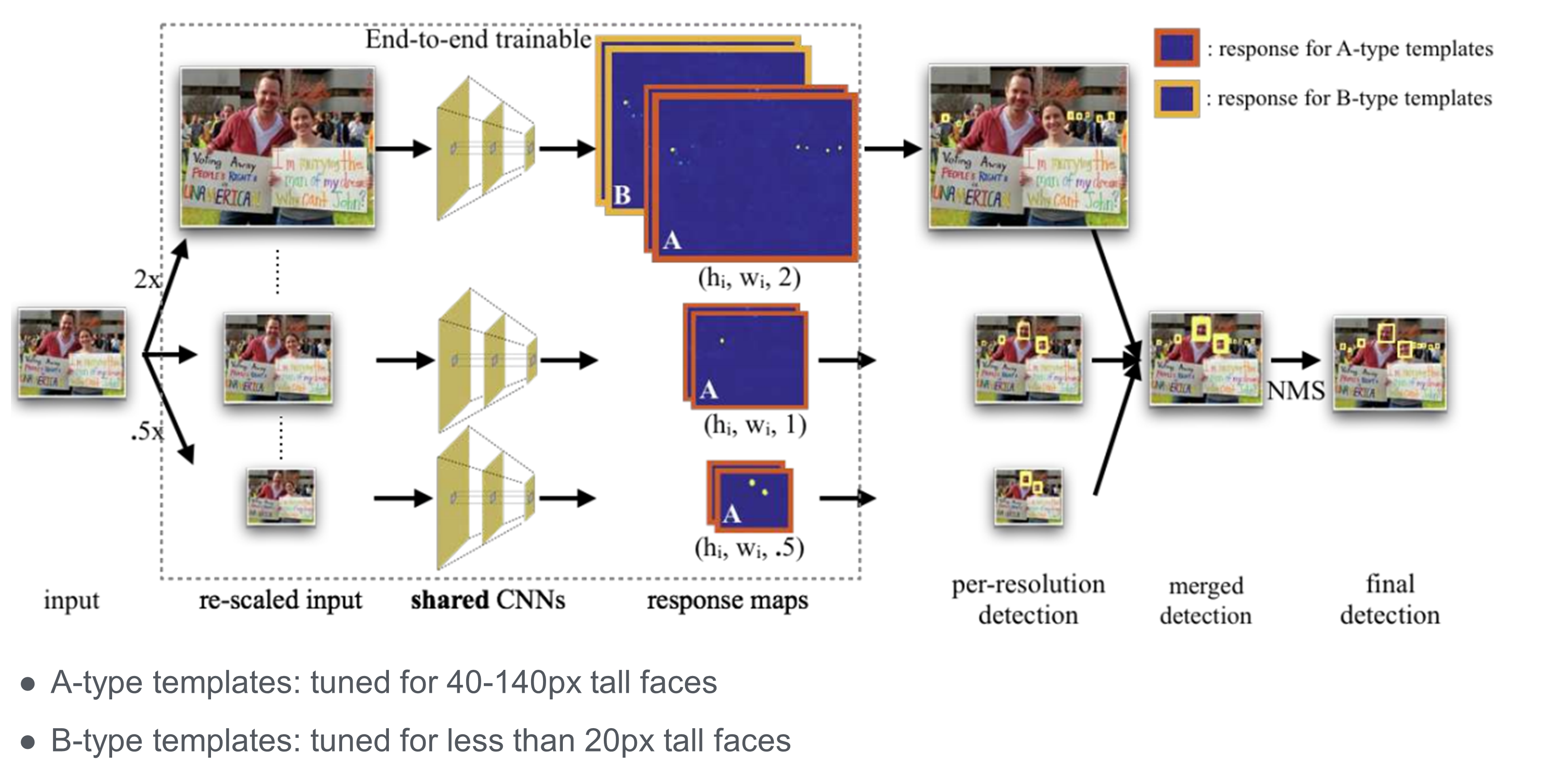
결과를 보면 반으로 줄인 사이즈에서는 큰 얼굴의 탐지가 잘 되고, 2배로 키운 사이즈는 큰 얼굴은 탐지가 잘 되지 않고 작은 얼굴일수록 탐지가 잘 되는 것을 볼 수 있다.
영상의 사이즈별로 탐지를 잘하는 영역이 다르기에, 잘 하는 영역에 맞게 최종 출력물의 모델을 다르게 써서 문제를 해결한다. 그래서 모든 사이즈들을 모두 합쳐서 출력을 내면 Full Model이고, 2가지를 합친 Model이나 하나의 Model도 사용할 수 있다. 아래의 오른쪽 그림은 그것에 대한 결과물이다. 데이터셋과 그 결과물을 보면서 해당 데이터셋에 맞는 모델을 선정하면 될 것이다.
Finding Tiny Faces 아키텍쳐
Model
class DetectionModel(nn.Module):
def __init__(self, base_model=resnet101, num_templates=1, num_objects=1):
super().__init__()
# 4 is for the bounding box offsets
output = (num_objects + 4)*num_templates # num_objects = face만 탐색하기에 1
self.model = base_model(pretrained=True) # backbone = ResNet101
# delete unneeded layer
del self.model.layer4
self.score_res3 = nn.Conv2d(in_channels=512, out_channels=output,
kernel_size=1, padding=0)
self.score_res4 = nn.Conv2d(in_channels=1024, out_channels=output,
kernel_size=1, padding=0)
self.score4_upsample = nn.ConvTranspose2d(in_channels=output, out_channels=output,
kernel_size=4, stride=2, padding=1, bias=False)
self._init_bilinear()
def _init_weights(self):
pass
def _init_bilinear(self):
"""
Initialize the ConvTranspose2d layer with a bilinear interpolation mapping
:return:
"""
k = self.score4_upsample.kernel_size[0]
factor = np.floor((k+1)/2)
if k % 2 == 1:
center = factor
else:
center = factor + 0.5
C = np.arange(1, 5)
f = np.zeros((self.score4_upsample.in_channels,
self.score4_upsample.out_channels, k, k))
for i in range(self.score4_upsample.out_channels):
f[i, i, :, :] = (np.ones((1, k)) - (np.abs(C-center)/factor)).T @ \
(np.ones((1, k)) - (np.abs(C-center)/factor))
self.score4_upsample.weight = torch.nn.Parameter(data=torch.Tensor(f))
def learnable_parameters(self, lr):
parameters = [
# Be T'Challa. Don't freeze.
{'params': self.model.parameters(), 'lr': lr},
{'params': self.score_res3.parameters(), 'lr': 0.1*lr},
{'params': self.score_res4.parameters(), 'lr': 1*lr},
{'params': self.score4_upsample.parameters(), 'lr': 0} # freeze UpConv layer
]
return parameters
def forward(self, x):
x = self.model.conv1(x)
x = self.model.bn1(x)
x = self.model.relu(x)
x = self.model.maxpool(x)
x = self.model.layer1(x)
# res2 = x
x = self.model.layer2(x)
res3 = x
x = self.model.layer3(x)
res4 = x
score_res3 = self.score_res3(res3)
score_res4 = self.score_res4(res4)
score4 = self.score4_upsample(score_res4)
# We need to do some fancy cropping to accomodate the difference in image sizes in eval
if not self.training:
# from vl_feats DagNN Crop
cropv = score4.size(2) - score_res3.size(2)
cropu = score4.size(3) - score_res3.size(3)
# if the crop is 0 (both the input sizes are the same)
# we do some arithmetic to allow python to index correctly
if cropv == 0:
cropv = -score4.size(2)
if cropu == 0:
cropu = -score4.size(3)
score4 = score4[:, :, 0:-cropv, 0:-cropu]
else:
# match the dimensions arbitrarily
score4 = score4[:, :, 0:score_res3.size(2), 0:score_res3.size(3)]
score = score_res3 + score4
return score
templates
def get_detections(model, img, templates, rf, img_transforms,
prob_thresh=0.65, nms_thresh=0.3, scales=(-2, -1, 0, 1), device=None): # 논문보다 1개 많은 4개의 템플릿을 가진다.(1/4, 1/2, 1, 2의 스케일링)
model = model.to(device)
model.eval()
dets = np.empty((0, 5)) # store bbox (x1, y1, x2, y2), score
num_templates = templates.shape[0]
# Evaluate over multiple scale
scales_list = [2 ** x for x in scales] # 1/4, 1/2, 1, 2
# convert tensor to PIL image so we can perform resizing
image = transforms.functional.to_pil_image(img[0])
min_side = np.min(image.size)
for scale in scales_list:
# scale the images
scaled_image = transforms.functional.resize(image,
np.int(min_side*scale))
# normalize the images
img = img_transforms(scaled_image)
# add batch dimension
img.unsqueeze_(0)
# now run the model
x = img.float().to(device)
output = model(x)
# first `num_templates` channels are class maps
score_cls = output[:, :num_templates, :, :]
prob_cls = torch.sigmoid(score_cls)
score_cls = score_cls.data.cpu().numpy().transpose((0, 2, 3, 1))
prob_cls = prob_cls.data.cpu().numpy().transpose((0, 2, 3, 1))
score_reg = output[:, num_templates:, :, :]
score_reg = score_reg.data.cpu().numpy().transpose((0, 2, 3, 1))
t_bboxes, scores = get_bboxes(score_cls, score_reg, prob_cls,
templates, prob_thresh, rf, scale)
scales = np.ones((t_bboxes.shape[0], 1)) / scale
# append scores at the end for NMS
d = np.hstack((t_bboxes, scores))
dets = np.vstack((dets, d))
# Apply NMS
keep = nms(dets, nms_thresh)
dets = dets[keep]
return dets