
Swin Transformer
Swin Transformer를 보기에 앞서 Transformer가 무엇인지 간단히 보도록 하자.
Transformer(NIPS 2017)
Transformer는 input과 output 사이의 컴포넌트들의 집합으로 표현이 된다.
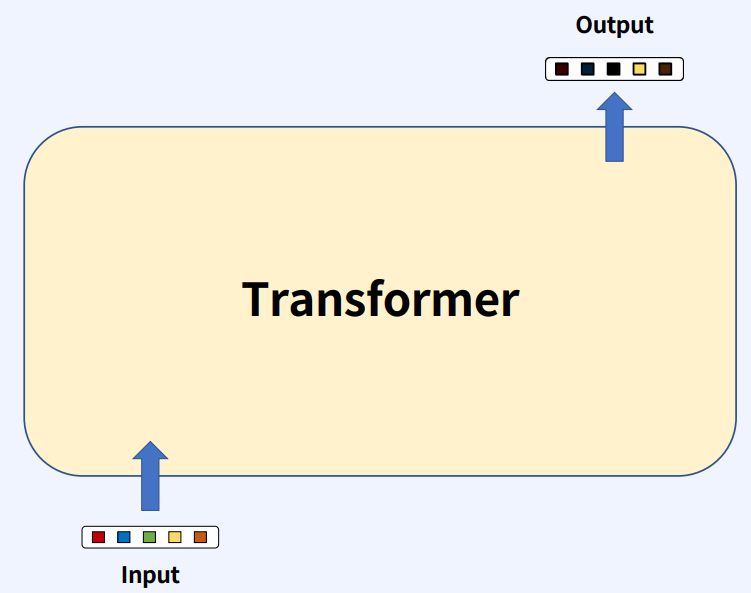
Transformer의 컴포넌트들은 Encoder 혹은 Encoder와 Decoder들로 이루어져 있다. Encoder와 Decoder로 이루어진 Transformer를 주력으로 보자면, Target이 있는 경우는 원하는 출력 형태가 있을 때 유용하게 사용이 된다.(ex. 번역)
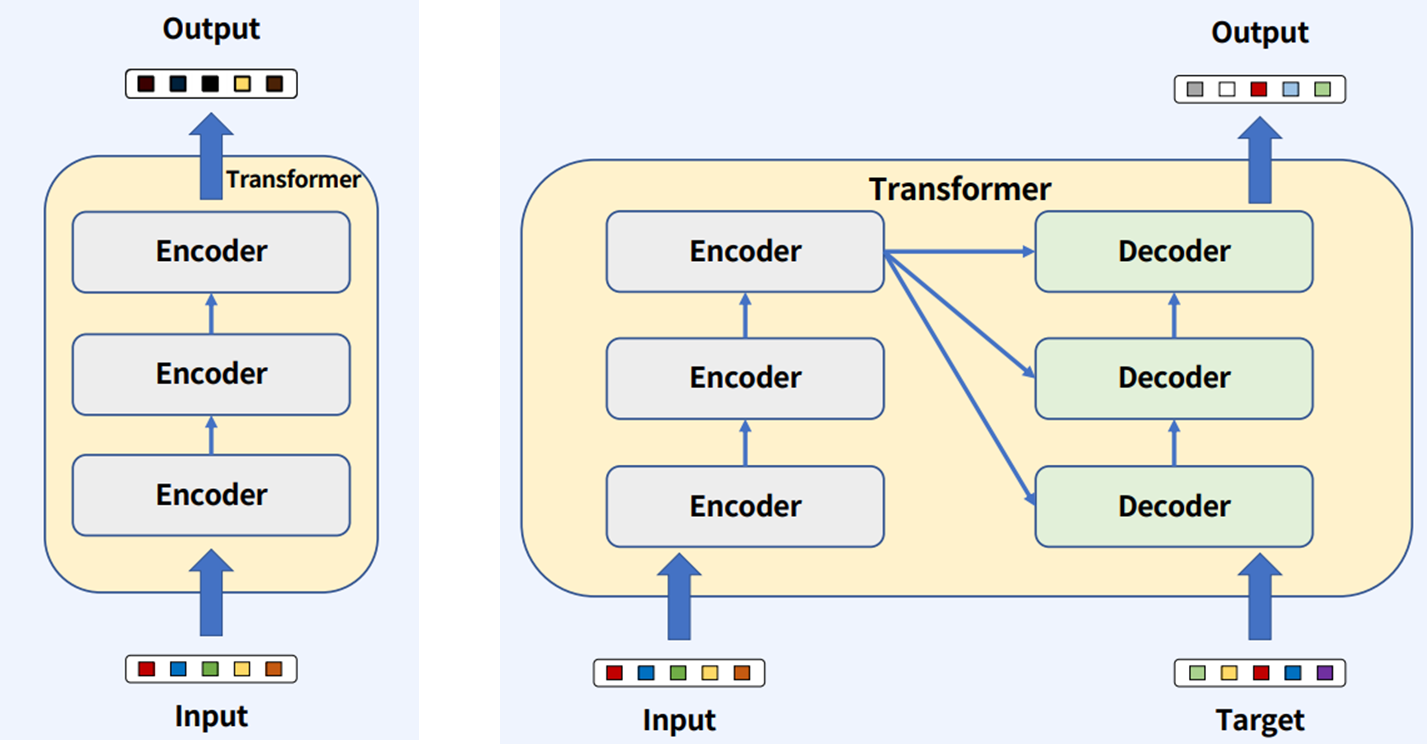
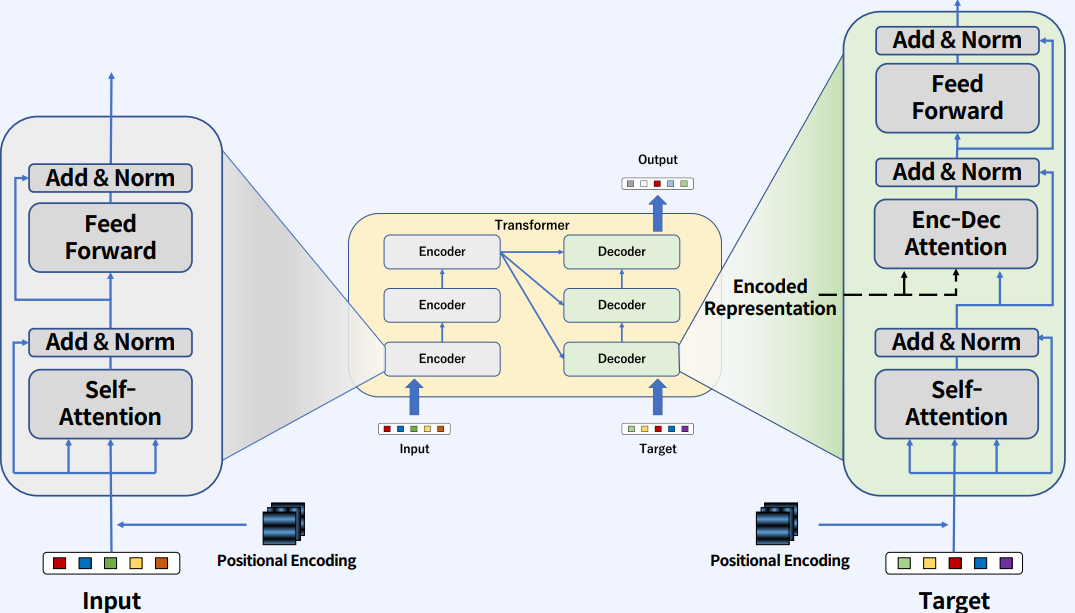
Encoder와 Decoder 블럭의 상세 정보는 다음과 같다.
입력값에 Positional Endocing이 들어가는데, NLP는 시퀀스의 순서 또는 이미지의 경우는 grid상의 위치 정보가 표기되지 않기 때문에 위치 정보를 따로 넣어준다.
input이 들어오게 되면(X) key, query, value 프로젝션 메트릭스를 곱해서 백터로 만든다. Q와 K를 MatMul을 통해서 score를 구한 다음에 스케일링을 하고 Softmax를 통과하고 V와 다시 MatMul을 한다.
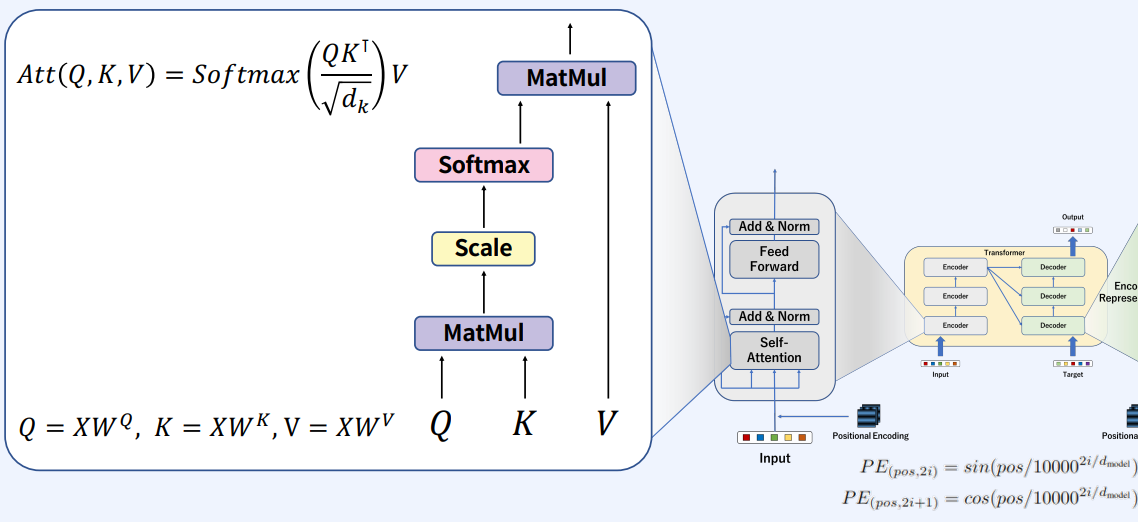
좀 더 자세히 보자면,
입력값(X)에 Q, K, V를 곱해서 Q, K, V 백터를 생성한다.
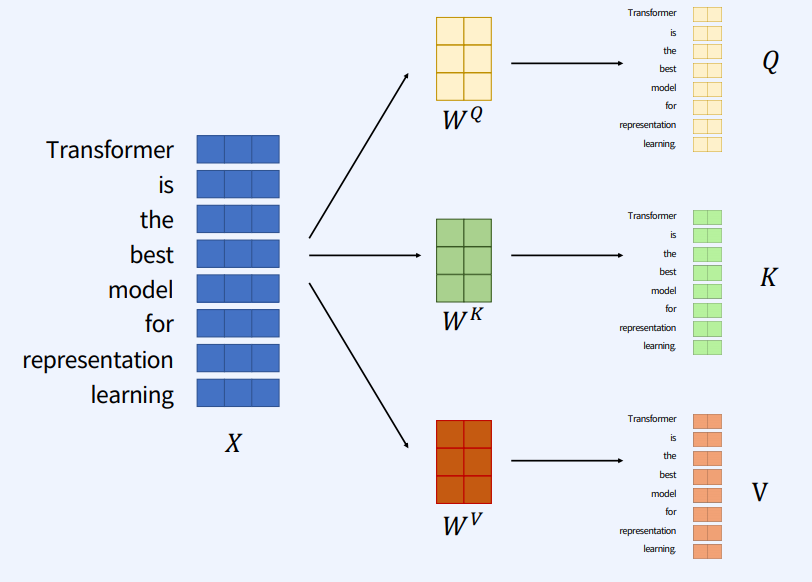
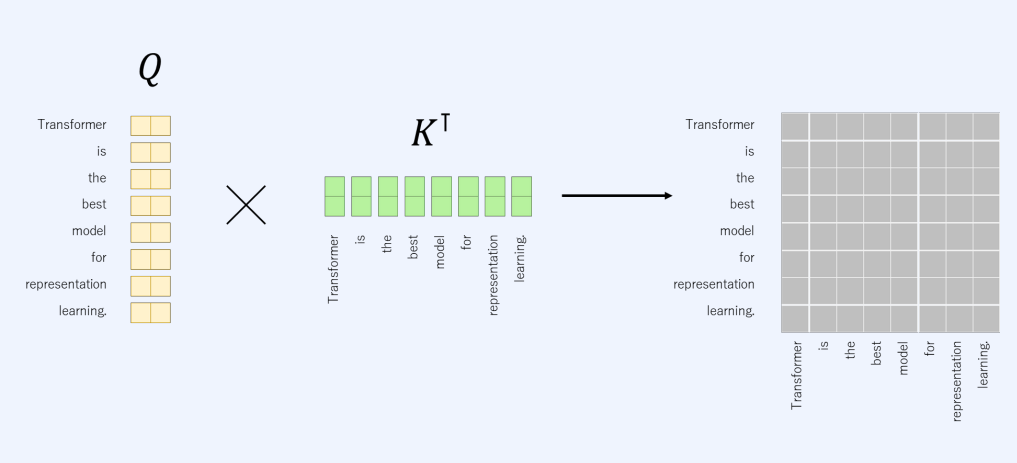
그 다음 Q, K 매칭을 통해 score를 구한다. 지금의 예는 self-attention이기에 같은 문장에서의 백터들을 곱한다. 그리고 그림에서의 행별로 Softmax를 취해 각각 확률값들을 만들어준다.
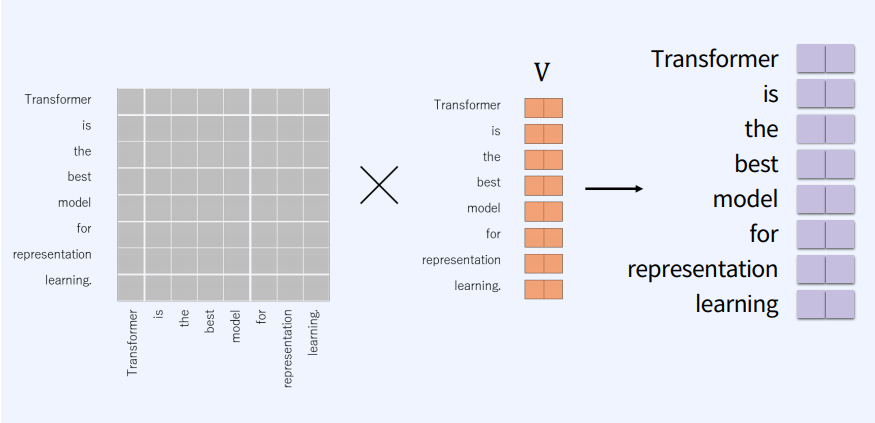
각각 만들어진 attention score들을 V와 MatMul을 통해서 output를 만든다.
이 과정을 attention 블럭을 병렬적으로 사용한다.
self-attention을 거친 백터와 거치지 않은 백터를 더해서 Normalization을 해준 후 FFN로 넘긴다. 보통 FFN에서는 MLP(Multi-Layer Perceptron, 그림에선 2 layers를 거치는)를 사용한다. 그리고 다시 FFN을 거친 것과 거치지 않은 벡터들을 합치고 Normalization을 하여 내보낸다.
잠시 self-attention에 의미를 보자.
self-attention는 의미를 찾기 위한 장치다. 의미는 사물 간 관계의 결과이고, self-attention은 관계를 배우는 일반적인 방법, 즉 우리가 어디에 주의를 기울여야 하는지 학습하는 것이다.
ex)
1) 그는 주전자의 물을 컵에 따랐다. 그것이 가득 찰 때까지. -> 그것 : 컵
2) 그는 주전자의 물을 컵에 따랐다. 그것이 텅 빌 때까지. -> 그것 : 주전자
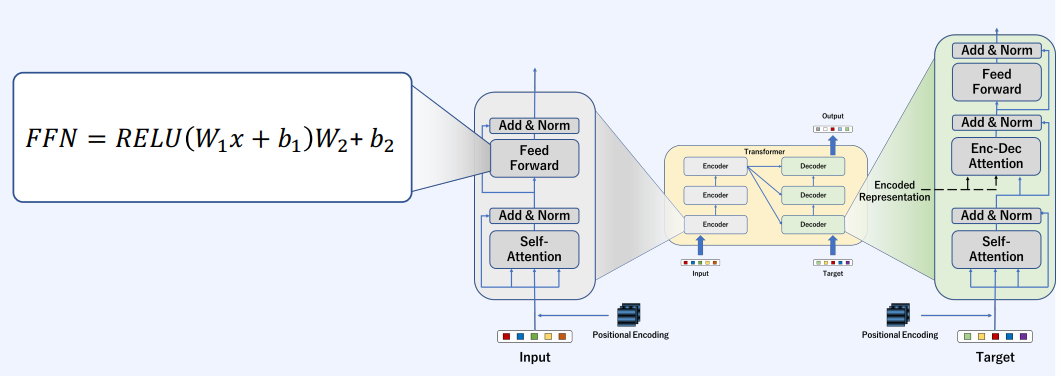
Decoder 부분도 self-attention과 동일한 방법으로 진행한다. 주의점은 Encoder와 Decoder에서 파라미터들은 서로 다른 파라미터들이다.
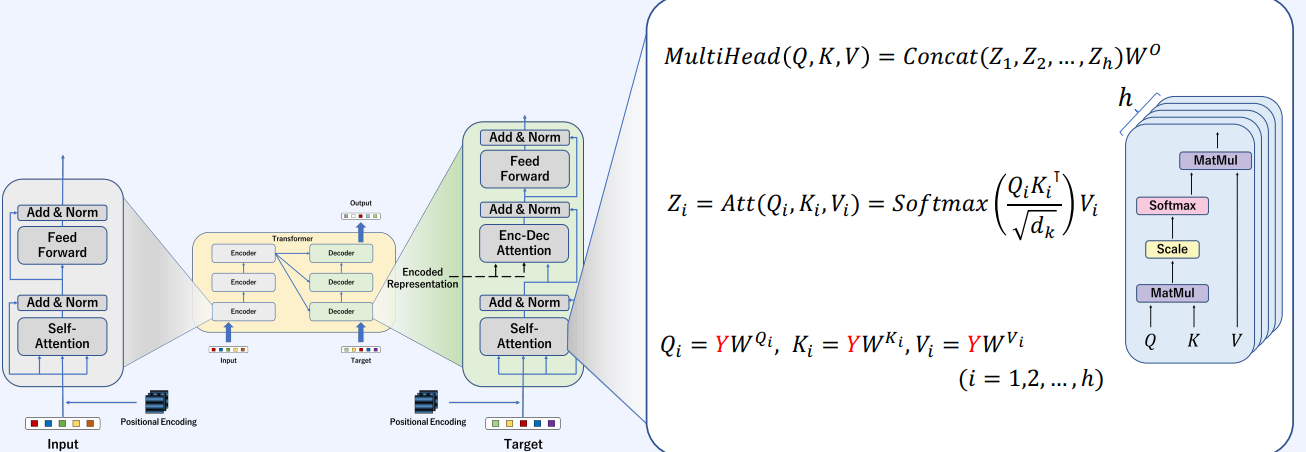
다른 점은 Enc-Dec Attention에서 K, V는 Encoder에서 넘어온 백터를 사용한다는 것이다.
그리고 Encoder에서의 FFN과 같은 방법을 거쳐서, 테스크에 따라서 이미지 객체 탐지라면 바운딩 박스를, 번역이라면 단어들에 대한 확률값 등을 거쳐 최종 output를 내보내게 된다.
Transformer 간단 Code
def multi_head_attention(Q, K, V):
num_batch, num_head, num_token_length, att_dim = K.shape
Q = Q / (att_dim**0.5)
attention_score = Q @ K.permute(0,1,3,2) # num_batch, num_head, num_token_length, num_token_length
attention_score = torch.softmax(attention_score, dim=3)
Z = attention_score @ V # num_batch, num_head, num_token_length, att_dim
return Z, attention_score
class MultiHeadAttention(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, Q, K, V):
num_batch, num_head, num_token_length, att_dim = K.shape
Q = Q / (att_dim**0.5)
attention_score = Q @ K.permute(0,1,3,2) # num_batch, num_head, num_token_length, num_token_length
attention_score = torch.softmax(attention_score, dim=3)
Z = attention_score @ V # num_batch, num_head, num_token_length, att_dim
return Z, attention_score
class EncoderLayer(torch.nn.Module):
def __init__(self, hidden_dim, num_head, dropout_p=0.5):
super().__init__()
self.num_head = num_head
self.hidden_dim = hidden_dim
self.MHA = MultiHeadAttention()
self.W_Q = torch.nn.Linear(hidden_dim, hidden_dim, bias=False)
self.W_K = torch.nn.Linear(hidden_dim, hidden_dim, bias=False)
self.W_V = torch.nn.Linear(hidden_dim, hidden_dim, bias=False)
self.W_O = torch.nn.Linear(hidden_dim, hidden_dim, bias=False)
self.LayerNorm1 = torch.nn.LayerNorm(hidden_dim)
self.LayerNorm2 = torch.nn.LayerNorm(hidden_dim)
self.Dropout = torch.nn.Dropout(p=dropout_p)
self.Linear1 = torch.nn.Linear(hidden_dim, hidden_dim)
self.Linear2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.Activation = torch.nn.ReLU()
def to_multihead(self, vector):
num_batch, num_token_length, hidden_dim = vector.shape
att_dim = hidden_dim // self.num_head
vector = vector.view(num_batch, num_token_length, self.num_head, att_dim) # [num_batch, num_token_length, num_head, att_dim]
vector = vector.permute(0,2,1,3) # [num_batch, num_head, num_token_length, att_dim]
return vector
def forward(self, input_Q, input_K, input_V):
# input_Q : [num_batch, num_token_length, hidden_dim]
Q = self.W_Q(input_Q) # [num_batch, num_token_length, hidden_dim]
K = self.W_K(input_K)
V = self.W_V(input_V)
num_batch, num_token_length, hidden_dim = Q.shape
Q = self.to_multihead(Q) # [num_batch, num_head, num_token_length, att_dim]
K = self.to_multihead(K)
V = self.to_multihead(V)
Z , _ = self.MHA(Q,K,V) # [num_batch, num_head, num_token_length, att_dim]
Z = Z.permute(0,2,1,3) # [num_batch, num_token_length, num_head, att_dim]
Z = Z.reshape(num_batch, num_token_length, self.hidden_dim) # [num_batch, num_token_length, hidden_dim]
Z = self.W_O(Z)
Z = self.LayerNorm1( self.Activation(Z) + input_Q)
Z1 = self.Dropout(Z)
Z = self.Activation(self.Linear1(Z1))
Z = self.Dropout(Z)
Z = self.Activation(self.Linear2(Z))
Z = self.Dropout(Z)
Z = Z + Z1
Z = self.LayerNorm2(Z)
return ZSwin Transformer
Transformer를 기반으로 비젼 문제를 푸는 모델이다.
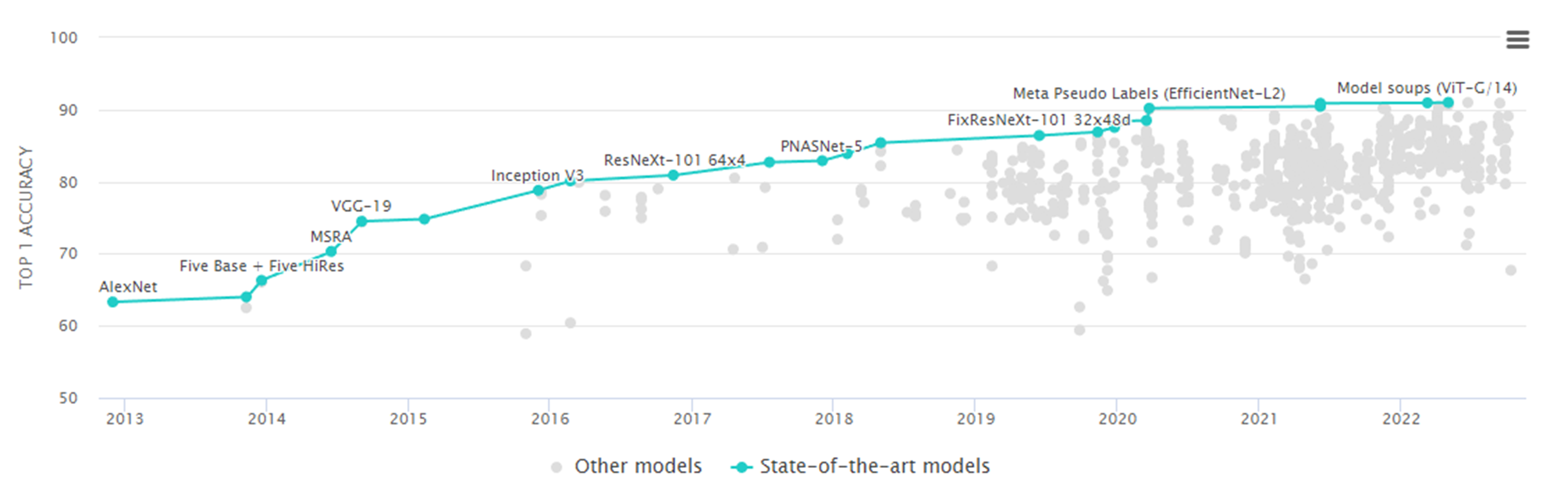
아래는 ImageNet Classification들의 결과인데, ViT(Vision Transformer) 기반의 알고리즘들이 연구되고 발표되면서 비전에서 큰 각광을 받게 된다.
단점은 Transformer는 엄청난 양의 데이터와 계산을 필요로하며 시간도 오래 걸리는 테스크들이 많다. 그래서 큰 데이터와 자본을 가지고 있는 메이져 기업이 아니면 진행하기 힘든 연구라는 것이다.
그래서 메이저 기업들에서 사전 학습된 모델의 backbone을 올려주고, 이것을 파인 튜닝해서 연구를 진행하는 형식으로 진행이 되고 있다.
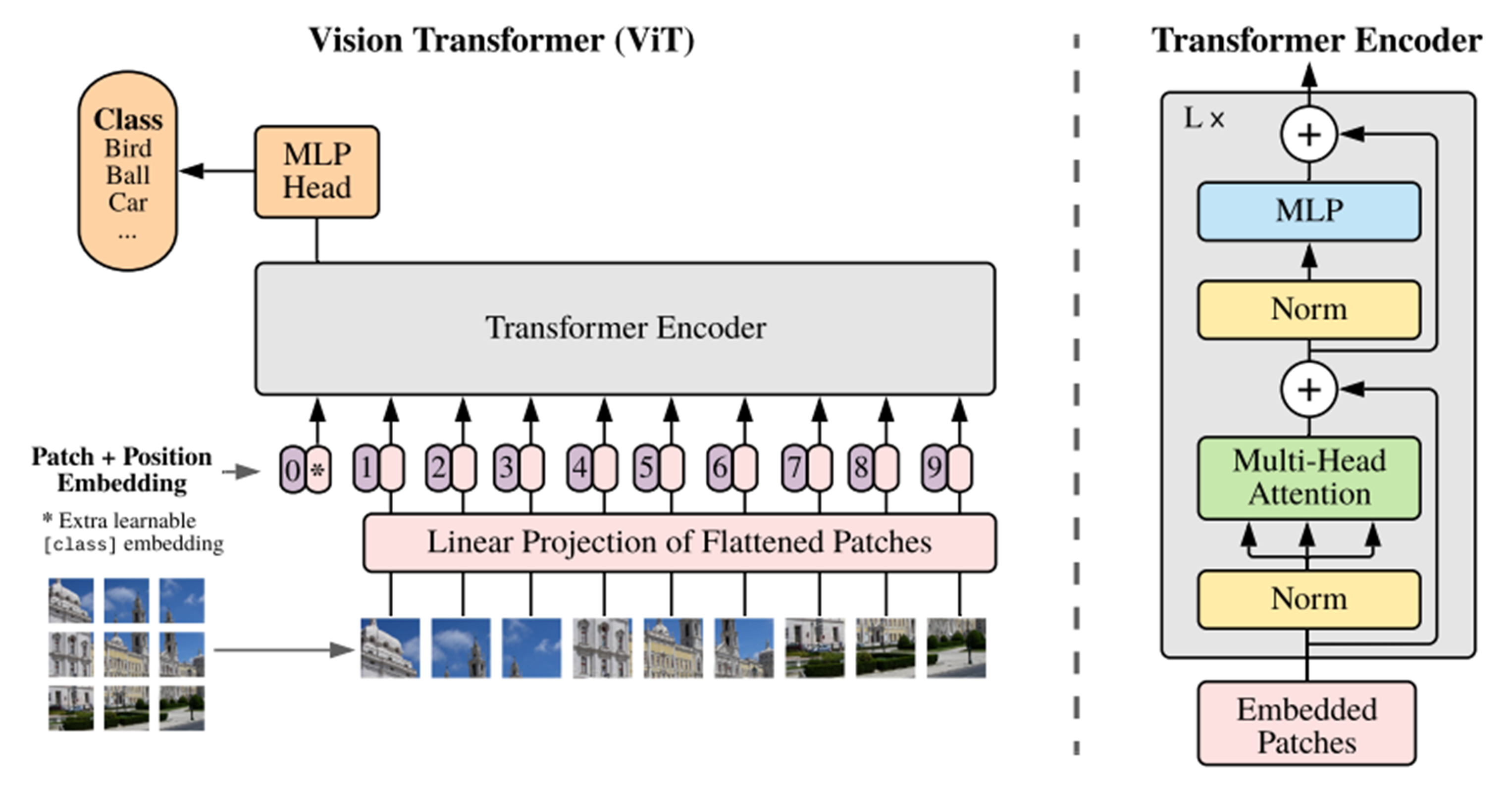
ViT
ViT를 간단히 말해보자면, 기존 NLP에서 글자로 되어 있던 부분을 이미지 패치로 바꾸어 적용시켰다고 볼 수 있다. 아래의 그림과 같이 영상이 주어져 있으면, 영상을 패치 단위로 쪼개고 Linear Projection을 통해서 백터화 시킨다. 그리고 이미지 패치에 따라서 백터가 주어지고 그것을 Encoder에 넣는 방식이다.
미리 정해진 방법대로 영상의 패치를 쪼개서 각 패치들끼리의 관계를 attention을 통해 찾는 것이 ViT였다.
반면 Swin Transformer는 패치를 매우 작게 쪼갠 것과 더 크게 키운 패치들을 한 번에 볼 수 있는 Hierarchical feature map을 만든다. 그래서 객체가 작고 큰 경우, 영상 전체 maps를 보고 분류를 할 것인지 작은 부분을 보고 분류를 할 것인지 판단하게 된다. 다양한 패치들의 크기를 가지고 다양하게 비전 테스크를 수행한다.
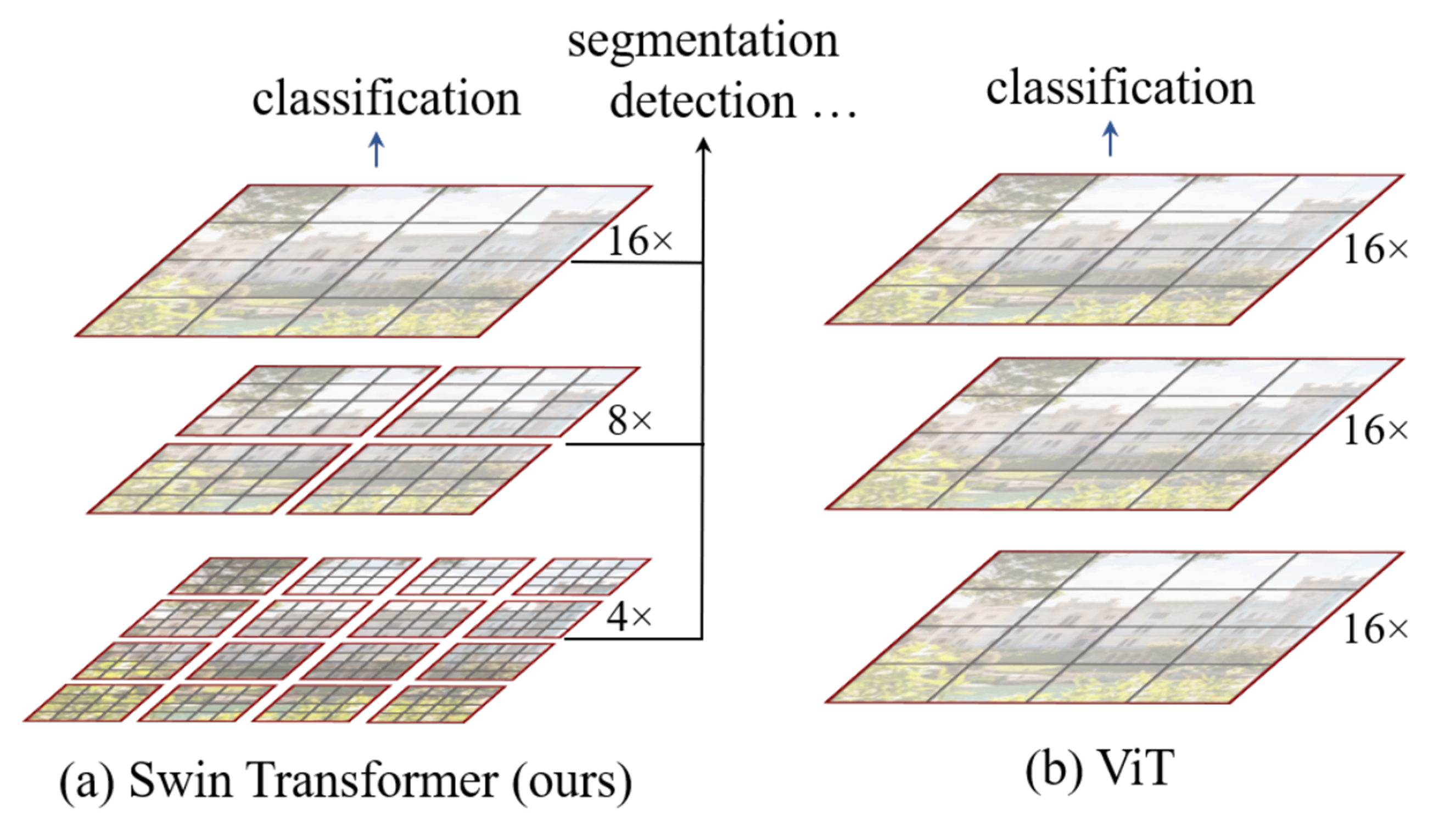
Swin Transformer Shifted window 방법을 사용한다.
아래 빨간색의 테두리가 하나의 패치인데, 이 패치를 다시 쪼개서 패치 안에서 더 작게 쪼갠 패치들의 attention score를 계산한다. 그리고 빨간색 패치의 위치를 바꾸어서 다시 진행하게 된다. 레이어별로 이동하면서 attention을 계산할 window를 이동시키는 것이다.
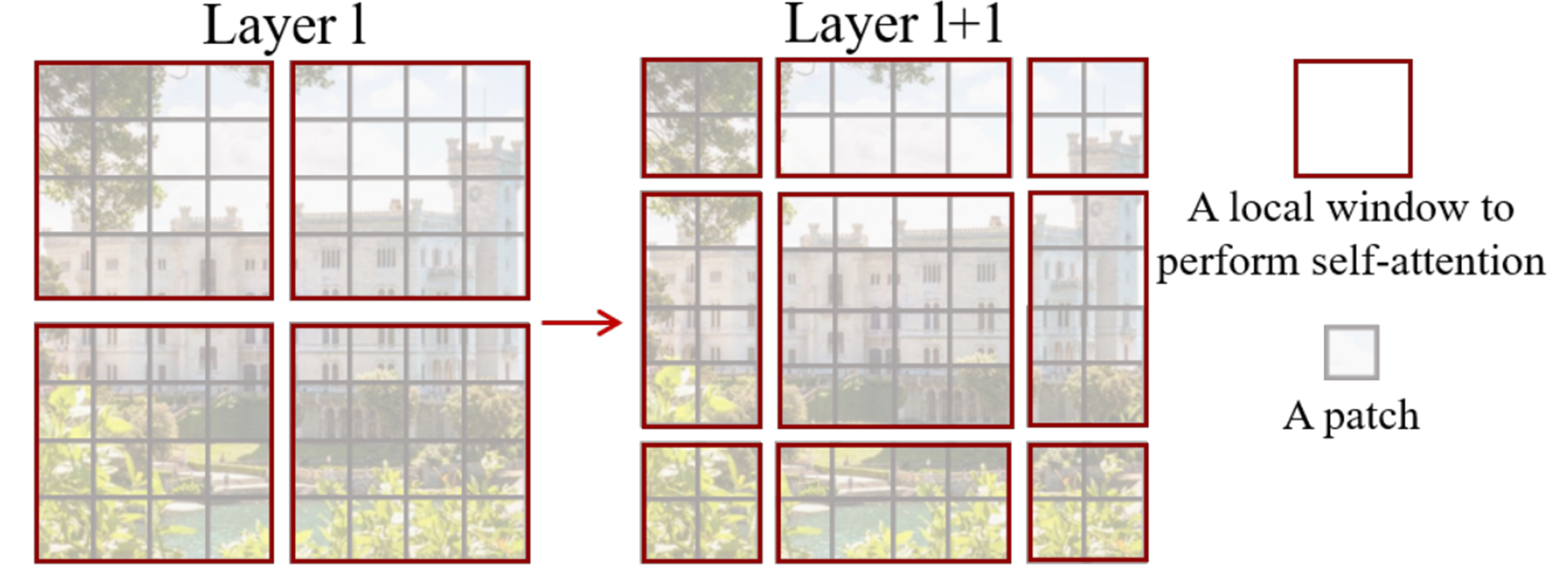
Swin Transformer의 아키텍쳐를 보면, 가장 작은 패치 단위를 1/4×1/4로 큰 패치를 1/32×1/32로 잡았다.
입력에서 1/4×1/4로 쪼갰기에 디멘전을 맞추기 위해서 3에 16을 곱해서 48로 맞추어 입력을 시킨다. 그리고 C(channel)로 바꾸고 패치를 키우게 되면서 채널도 2배씩 키우면서 디멘전을 맞추어 나간다. 이 방법은 기존 CNN에서 피쳐 레졸루션을 줄여가면서 채널 수를 늘려가는 방식과 같다고 볼 수 있다.
LN은 layers normalization, W-MSA는 Window Multi-Head Self-Attention, SW-MSA는 Shifted-Window Multi-Head Self-Attention방법으로, 전체 구성은 ViT와 비슷하게 되어 있다.
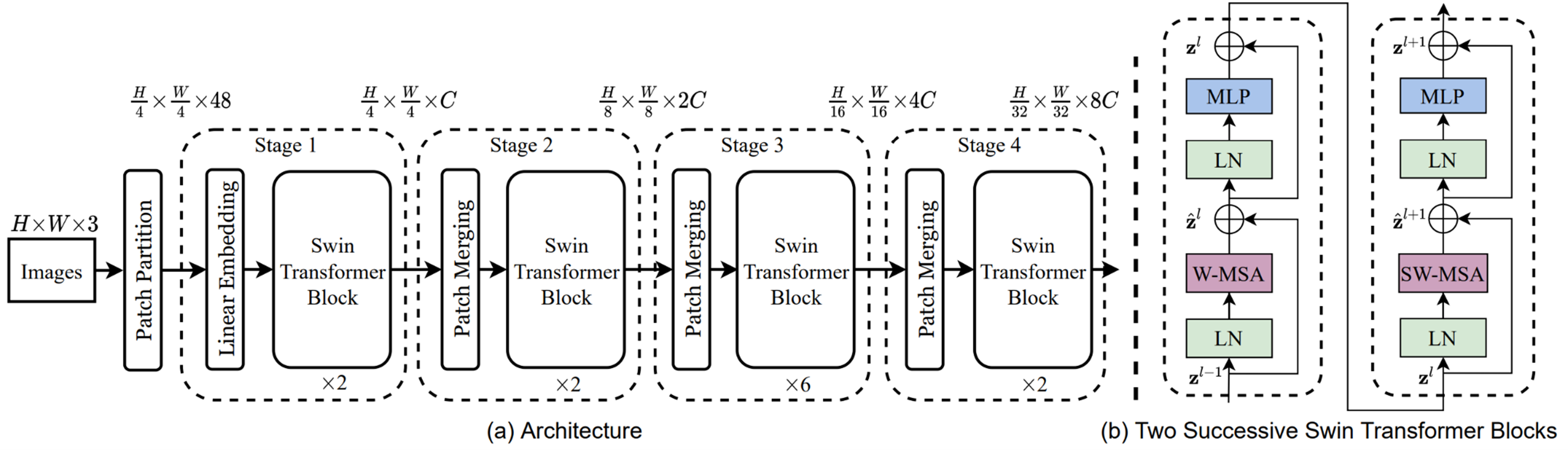
Swin Transformer Model
간단하게 살펴보자.
패치를 합치는 부분.
class PatchMerging(nn.Module):
""" Patch Merging Layer
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
""" Forward function.
Args:
x: Input feature, tensor size (B, H*W, C).
H, W: Spatial resolution of the input feature.
"""
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return xSwin Transformer Block 부분
class SwinTransformerBlock(nn.Module):
""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.H = None
self.W = None
def forward(self, x, mask_matrix):
""" Forward function.
Args:
x: Input feature, tensor size (B, H*W, C).
H, W: Spatial resolution of the input feature.
mask_matrix: Attention mask for cyclic shift.
"""
B, L, C = x.shape
H, W = self.H, self.W
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# pad feature maps to multiples of window size
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
attn_mask = mask_matrix
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return xWindow Attention 부분
class WindowAttention(nn.Module):
""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
""" Forward function.
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x