
NeRF(ECCV, 2020)
NeRF는 NeRF:Representing Scenes as Neural Radiance Fields for View Synthesis라는 논문으로 제안된 모델이다.
Novel View Synthesis
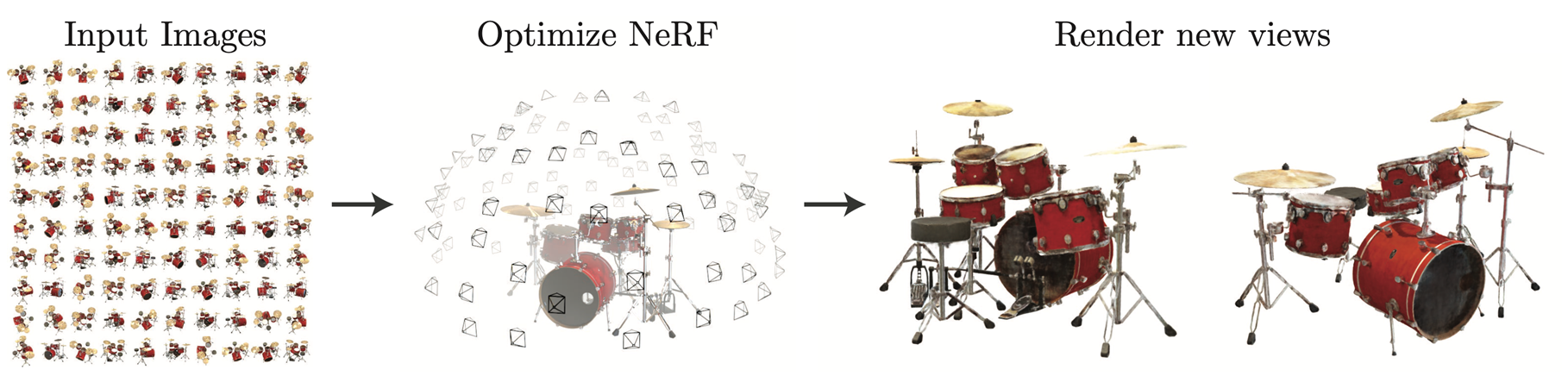
NeRF이 수행하는 task 중에서 Novel View Synthesis를 간단히 보면,
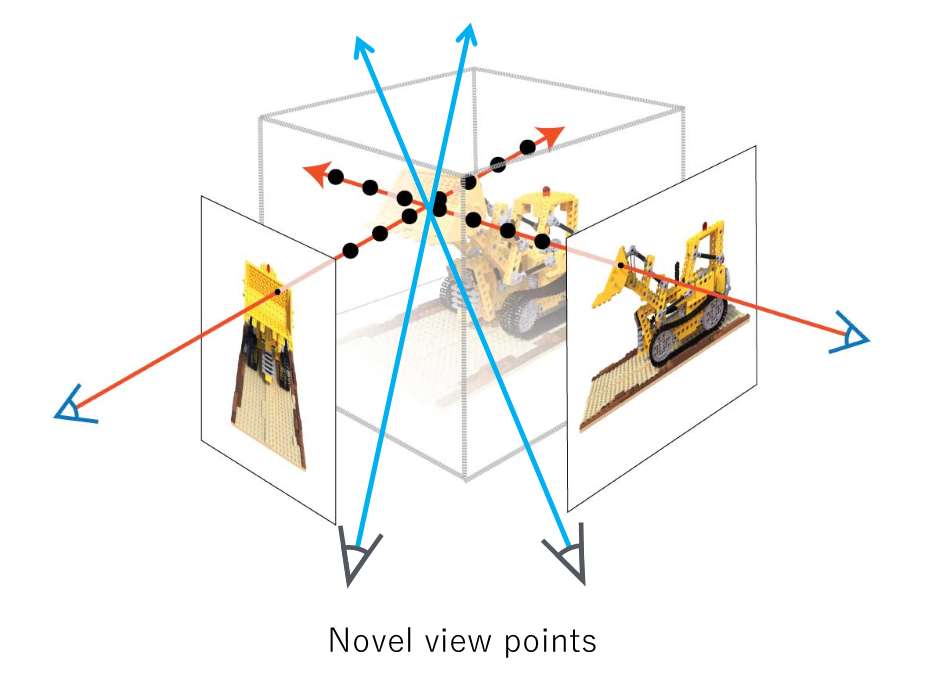
Novel View Synthesis는 아래의 그림과 같이 여러 시점에서 찍은 여러 장의 input image를 받아서, input image에는 존재하지 않던 새로운 시점에서의 이미지를 합성하는 task를 말한다.
기존에 찍었던 사진들을 바탕으로 시점을 자유롭게 움직일 수 있는 3D-aware selfie를 만든다거나, 촬영된 영상을 시점과 타이밍을 조절하며 다른 각도와 시점에서 볼 수 있도록 해준다.
이런 task는 여러 산업 분야, 게임이나 영화 또는 VR/AR 산업 등에 사용이 된다. 그래서 전문적이지 않아도 View Synthesis를 수행할 수 있다는 점이 장점이다.
Implicit representation
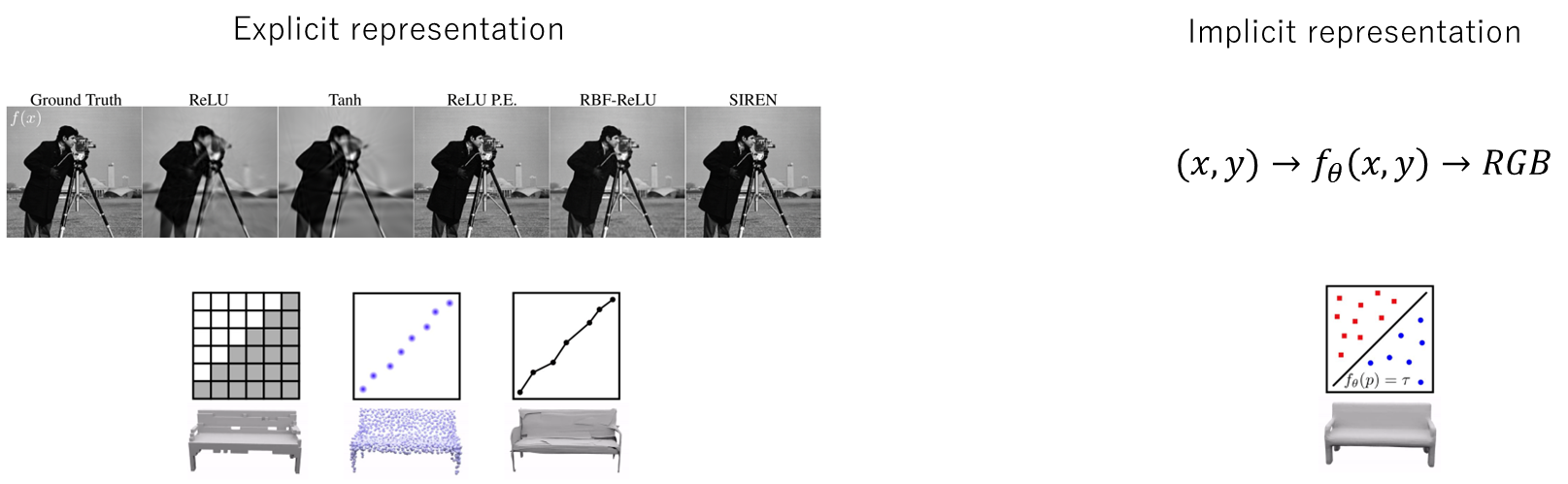
데이터를 2가지로 나눈다면 Explicit representation과 Implicit representation으로 나눌 수 있는데, Explicit representation의 경우에는 명시적인 데이터 구조를 사용해서 표현하는 방식으로 2차원 이미지나 3차원 매쉬, Point Cloud 등이 있다.
그리고 Implicit representation는 좌표에 대한 하나의 함수로 데이터들을 간접적으로 표현하는 방식으로, 픽셀 좌표를 input으로 넣어주면 해당 좌표에 대한 RGB값을 출력하는 식으로 간접적으로 이미지를 표현하는 방식이다. 이런 방식의 장점은, Explicit representation의 이미지와 같이 각 필셀들이 2차원 배열에 한 칸씩 차지하는 형식이기에 불연속적인 정수 좌표에서만 표현이 되는 반면, Implicit representation는 함수를 통해서 연속적인 필셀 좌표에서의 RGB값을 개선할 수 있고 시그널이 연속적이고 부드럽게 작동한다는 것이다. 또한 Neural Network 통해 뛰어난 표현력을 이용할 수 있다는 장점도 있다. 하나의 네트워크를 사용하여 데이터를 저장하는데 비용 절감 효과까지 가지고 있다.
NeRF(Neural Radiance Fields)
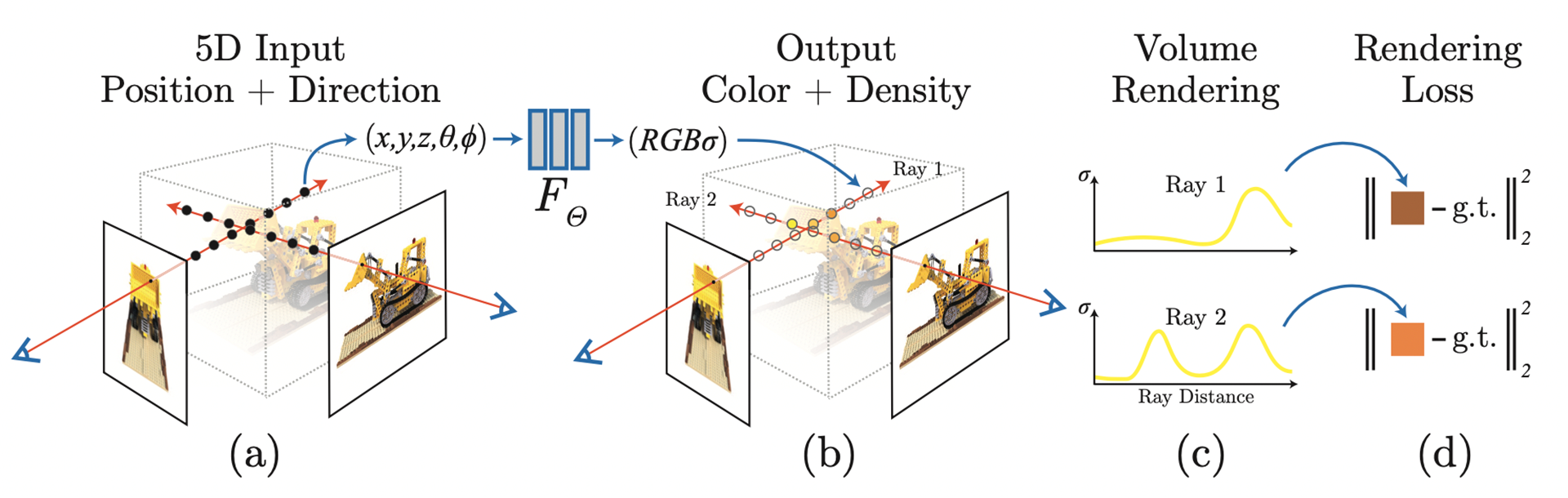
아래의 그림은 NeRF의 작동 방식을 보여준다.
NeRF의는 5차원의 함수로 Scene을 표현한다. input으로 입력되는 5차원의 좌표는 3차원 공간 좌표 x, y, z와 2차원 시점 백터 세타와 파이로 구성된다.
시점 백터가 사용되는 이유는 Novel View Synthesis를 위해서는 시점에 따라 달라지는 RGB값을 잘 표현해야 되기 때문으로, 같은 물체라도 실제 상황에서의 조명이나 물체 표면 성질에 따라 보는 시점이 달라지면 색이 달라질 수 있기 때문이다. 이를 모델링하기 위한 표현 방법이 Radiance Field다.
NeRF는 하나의 픽셀을 렌더링 하기 위해 카메라 중심으로부터 해당 필셀을 뚫고 지나가는 가상의 레이를 쏜다고 가정한다. 그리고 이 레이 위에 여러 개의 샘플 포인트들을 골라낸 후 샘플 포인트들의 좌표와 시점 벡터를 Neural Network에 입력으러 넣고 Neural Network 가 각 샘플 포인트들의 Color와 Density 값들을 예측한다. Density는 해당 공간에 물체가 있는지 없는지를 나타내기 위한 값으로써, 0에 가까울수록 해당 공간은 빈 공간임을 의미하고 값이 커질수록 해당 공간에 물체가 존재한다는 것을 의미한다.
이미지를 랜더링하기 위해서 NeRF는 Volume Rendering 방법을 사용한다.
쏘아진 레이 위에 여러 포인트들을 샘플링한 뒤 Neural Network를 통해 각 샘플 포인트들의 컬러와 밀도 값을 예측을 하는데, 예측된 각 샘플 포인트들의 컬러와 밀도 값을 조합하여 최종적인 픽셀의 컬러 값을 계산한다. 이때 샘플 포인트들의 밀도 값은 가중치로 사용을 하는데, 물체 표면과 가까운 샘플 포인트의 컬러 값에는 높은 가중치를 주고 빈 공간에 있는 점들에는 낮은 가중치를 주어서 해당 이미지 픽셀에 물체 표면의 색이 더 많이 반영될 수 있도록 하여, 최종적으로 물체 표면의 색이 랜더링될 수 있도록 한다.
Volume Rendering 방법을 수식화하면 아래와 같다.
(C)에서 2번째 레이를 보면 물체를 2번 뚫고 지나가는 형식을 그린 것으로, 레이가 첫 번째로 교차하는 물체 표현의 색에 더 많은 가중치를 두고 두 번째 교차하는 표면에는 가중치값을 줄여서 표면의 컬러 값이 해당 레이 픽셀 값에는 적게 반영되도록 한다.
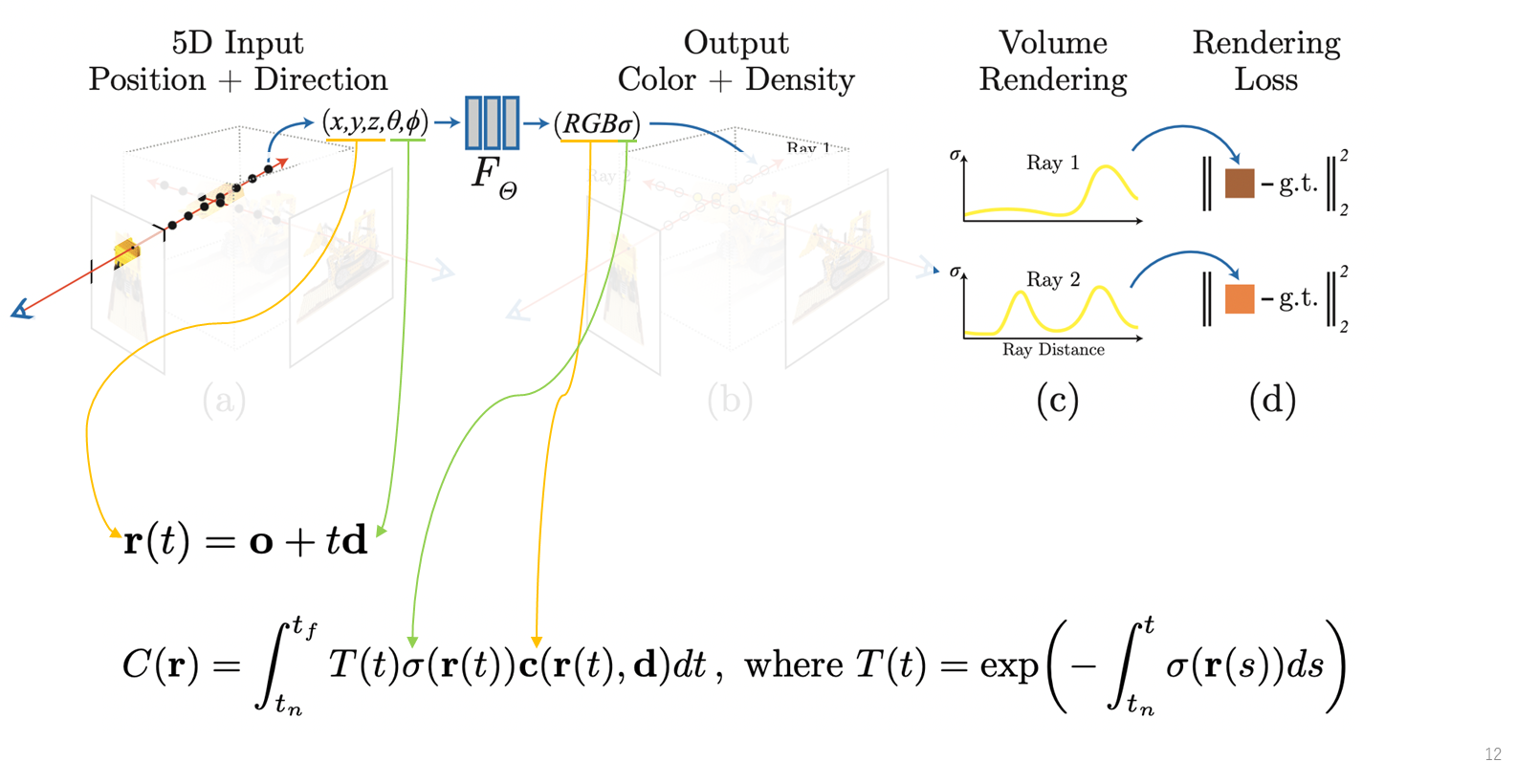
NeRF를 학습을 할 때에는, 각 ray마다 rendering한 픽셀값을 정답 픽셀값과 같아지도록 하는 reconstruction loss, rendering loss를 계산하여 이 값이 줄어들도록 network optimization을 한다. 그리고 멀티뷰 이미지에 대해서 학습을 하기 때문에, multi-view training 이미지에 대해서 학습을 하면서 네트워크는 여러 시점에서 일관되는 multi view consistent 한 scene representation을 학습하게 됩다.

그래서 NeRF를 통해서 가상의 카메라를 원하는 위치 및 시점에 놓고 해당 카메라로부터 ray들을 발사하여 픽셀을 렌더링하고 새로운 시점에서의 이미지를 합성해낼 수 있게 된다.
Volume Rendering
Volume Rendering을 구현할 때는 연속적인 곡선이 주어졌을 경우 아래의 면적을 적분을 사용하여 계산한다. 계산은 근사치로 곡선 아래의 직사각형들을 놓고 그 면적을 합치는 방식으로 곡선 아래의 면적을 근사한다. 대신 적분식이 아닌 가중치합의 형태로 변환을 해서 픽셀 값을 계산하게 된다.
Positional Encoding
5차원의 좌표를 네트워크에 넣고 학습을 했을 때 디테일들을 잡아내지 못해서 흐릿한 결과물을 내놓게 된다. 이 문제를 해결하기 위해 Positional Encoding 방법을 사용한다.
Positional Encoding이 적용되는 것은 5차원의 좌표로, 5차원 좌표 값에 Positional Encoding이 적용되면 5차원의 공간보다 더 높은 차원의 공간으로 맵핑이 되고 이 맵핑된 feature가 input으로 들어가게 된다. 그래서 5차원의 좌표가 바로 input으로 들어가는 것이 아닌 고차원의 공가으로 맵핑이 된 후 네트워크의 input으로 들어가게 된다.
Positional Encoding의 형태는 아래의 그림과 같다.
Fourier feature은 아래의 그림과 같이 증가하는 값을 가지는 sin, cos 함수로 구성이 되어 있는데, 저차원의 좌표 값이 입력되면 고차원의 feature vector로 맵핑이 되는 형태다. 그리고 L이라는 값으로 몇 차원의 공간으로 맵핑할 것인지가 결정이 된다. NeRF에서는, 3차원 공간 좌표 xyz일 때 L은 10, 2차원 시점 백터에 대해서는 L은 4라는 값을 사용한다.
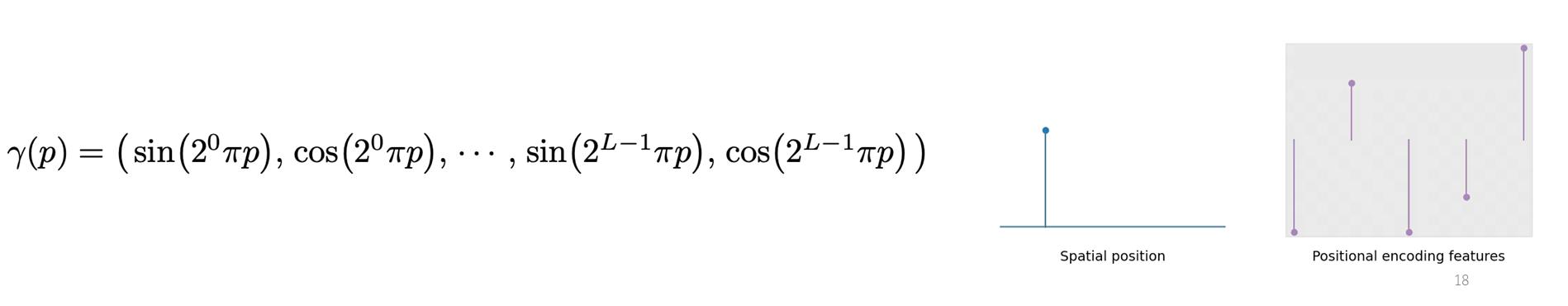
Architecture
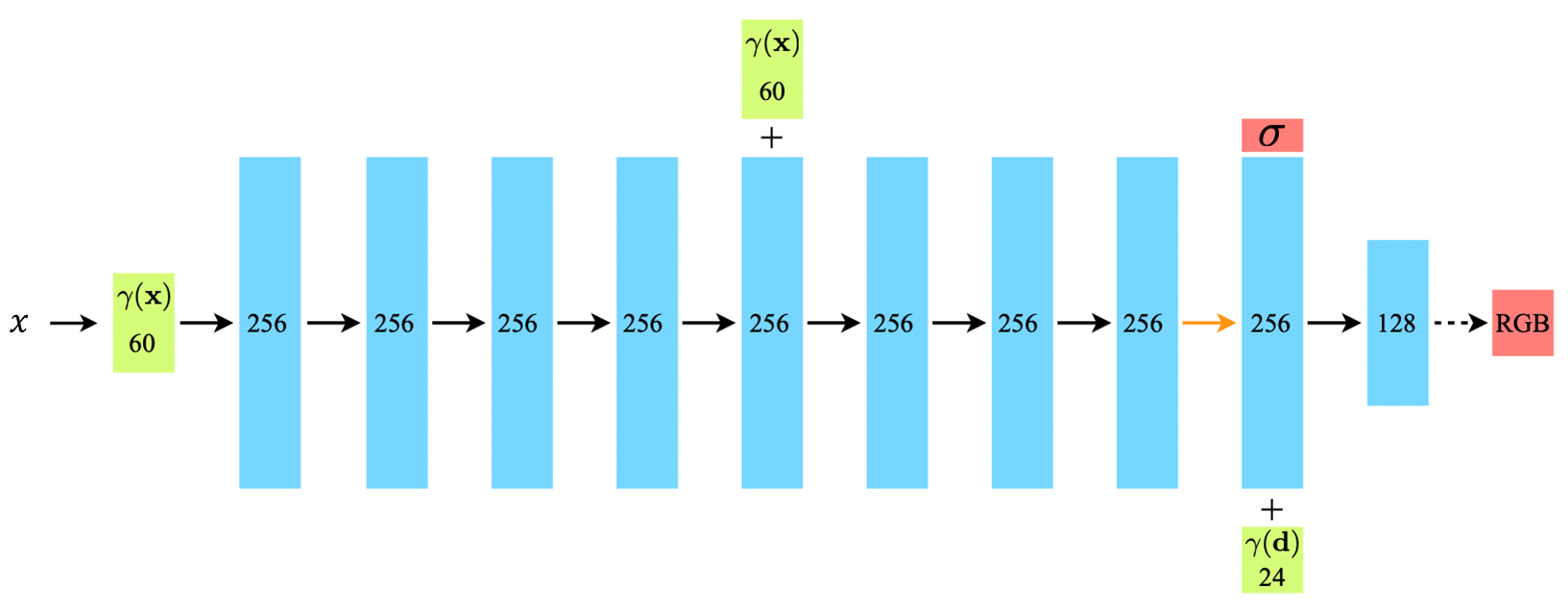
NeRF의 아키텍처는 아래와 같다.
총 8개의 FC Layer로 구성되어 있고, skip connetion을 통해 첫 번째와 네 번째 레이어에 60차원으로 맵핑된 3차원 공간 좌표가 입력으로 들어온다. 그리고 마지막 레이어에 Positional Encoding 된 시점 백터가 입력이 된다.
Density 값은 물체가 있는지 없는지에 대한 것으로 3차원 공간 좌표에 의해서 결정이 되고, RGB값은 시점에 따라 달라지기 때문에 마지막 레이어에 시점 백터가 추가되어 RGB 값을 예측하는 형태로 되어 있다.
Stratified Sampling
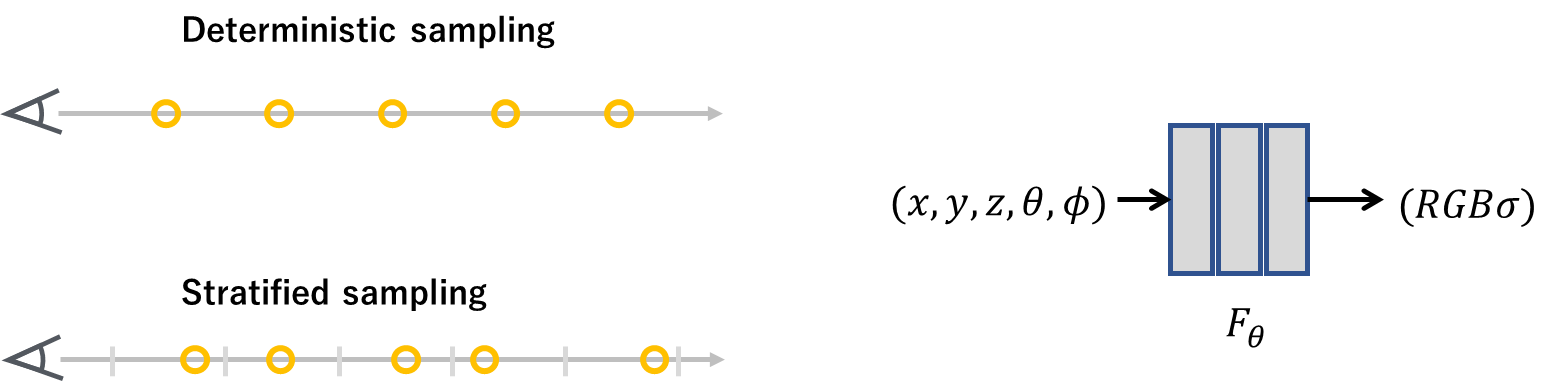
레이 위의 포인트들을 샘플링하는 방법은 아래의 그림과 같은 형태로 되어 있다.
레이 위의 여러 개의 샘플 포인트들을 고르고 샘플 포인트들의 컬러와 Density 값을 예측하고 이들을 다 합쳐서 최종 픽셀 값을 예측을 한다.
이 때 샘플 포인트들이 어떻게 선정되는지가 최종 성능에 영향을 미치기 때문에 NeRF는 Stratified Sampling 방법을 사용한다. Deterministic sampling은 레이의 처음과 끝을 기주으로 균등한 간격으로 나눠진 포인트들을 이용하는데, 이런 방법은 같은 픽셀의 같은 레이에 대해서는 항상 같은 위치의 샘플 포인트들에 대해서만 학습이 이루어지기에 해상도가 떨어지게 된다.
이에 반해 Stratified Sampling 방법은 레이 위의 다양한 포인트들을 샘플링하기 위해 시작점과 끝점을 균등한 간격으로 나누고 나눠진 구간 내에서 학습 때마다 랜덤한 위치에서 포인트들을 샘플링하는 방법이다.
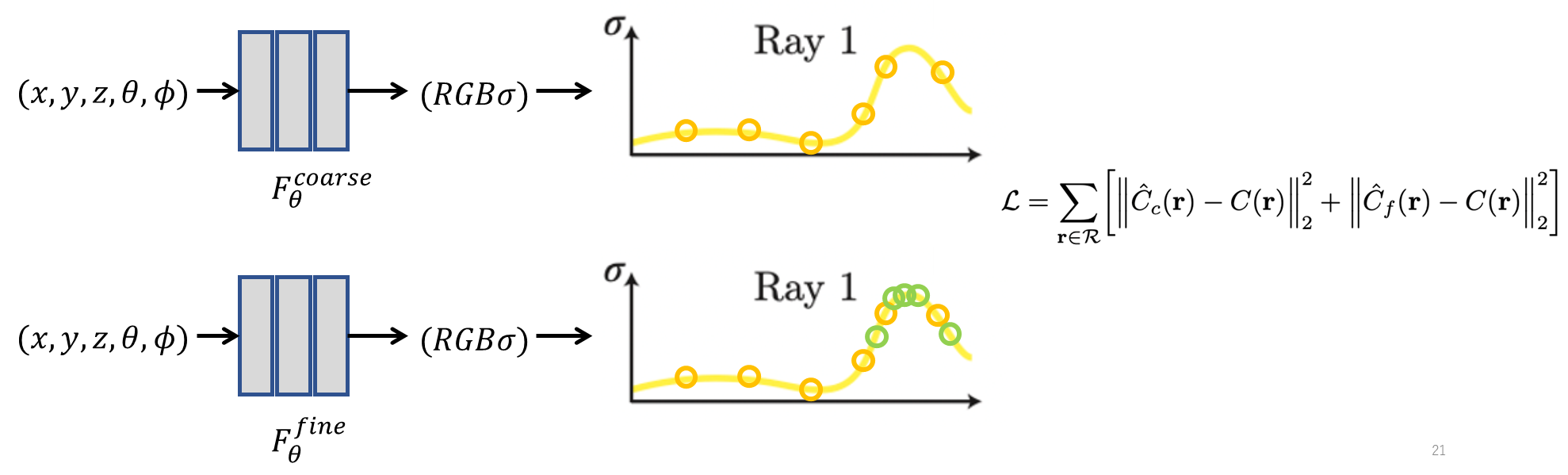
Hierarchical Volume Sampling
NeRF는 좋은 성능을 위해서 Coarse와 Fine 두 가지를 동시에 학습하는 Hierarchical Volume Sampling 방법을 사용한다. 두 가지를 모두 사용하는 이유는 샘플 포인트들을 물체 표면이 위치해야 하는 위치 근처에서 더 많은 샘플 포인트들을 샘플링하기 위해서다.
먼저 물체 표면이 어디 있는지를 파악하기 위해 Stratified Sampling을 사용하여 Coarse 모델 학습을 통해서 Density 분포가 어떻게 되는지 파악을 하고, Fine 모델을 학습할 때는 물체 표면 근처에 Density가 높은 점 근처의 샘플 포잍트들을 더 많이 샘플링하게 된다.
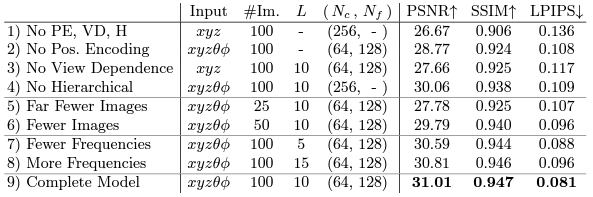
Results
PE는 Positional Encoding, VD는 View Dependence, H는 Hierarchical Volume Sampling을 말한다.
NeRF 아키첵처
tiny nerf 참조 : GiHub
Volume Rendering
def volume_rendering(c, sigma, rays_o, t):
sigma = torch.nn.functional.relu(sigma)[...,0]
c = torch.sigmoid(c)
delta = t[..., 1:] - t[..., :-1]
delta = torch.cat([delta, torch.tensor([1e10], dtype=rays_o.dtype, device=rays_o.device).expand(t[...,:1].shape)], dim=-1)
alpha = 1. - torch.exp(-sigma * delta)
T = torch.cumprod(1. - alpha + 1e-10, -1)
T = torch.roll(T, 1, -1)
T[..., 0] = 1.
w = T * alpha
rgb = (w[..., None] * c).sum(dim=-2)
return rgbPositional Encoding
def positional_encoding(
x, L=6, include_input=True
) -> torch.Tensor:
encoding = [x] if include_input else []
frequency_bands = 2.0 ** torch.linspace(
0.0,
L - 1,
L,
dtype=x.dtype,
device=x.device,
)
for freq in frequency_bands:
encoding.append(torch.sin(x * freq * np.pi))
encoding.append(torch.cos(x * freq * np.pi))
return torch.cat(encoding, dim=-1)Stratified Sampling
def stratified_sampling(
rays_o,
rays_d,
near,
far,
n,
):
# shape: (num_samples)
t = torch.linspace(near, far, n).to(rays_o)
# ray_origins: (width, height, 3)
# noise_shape = (width, height, num_samples)
noise_shape = list(rays_o.shape[:-1]) + [n]
# depth_values: (num_samples)
t = t + torch.rand(noise_shape).to(rays_o) * (far - near) / n
# (width, height, num_samples, 3) = (width, height, 1, 3) + (width, height, 1, 3) * (num_samples, 1)
# query_points: (width, height, num_samples, 3)
x = rays_o[..., None, :] + rays_d[..., None, :] * t[..., :, None]
return x, tArchitecture
class NeRF(torch.nn.Module):
def __init__(self, gamma_x_dim=60, gamma_d_dim=24, num_channels=256, num_layers=8, skip=4):
super(NeRF, self).__init__()
self.layers = []
for i in range(num_layers):
if i == 0:
self.layers.append(torch.nn.Linear(gamma_x_dim, num_channels))
elif not i == skip:
self.layers.append(torch.nn.Linear(num_channels, num_channels))
else:
self.layers.append(torch.nn.Linear(num_channels + gamma_x_dim, num_channels))
self.layers = torch.nn.ModuleList(self.layers)
self.sigma_out = torch.nn.Linear(num_channels, 1)
self.feature = torch.nn.Linear(num_channels, num_channels)
self.branch = torch.nn.Linear(num_channels + gamma_d_dim, num_channels // 2)
self.rgb_out = torch.nn.Linear(num_channels // 2, 3)
self.skip = skip
self.relu = torch.nn.functional.relu
def forward(self, x, d):
out = x
for i, l in enumerate(self.layers):
if not i == self.skip:
out = self.relu(self.layers[i](out))
else:
out = torch.concat([out, x], dim=-1)
out = self.relu(self.layers[i](out))
sigma = self.sigma_out(out)
out = self.feature(out)
out = torch.concat([out, d], dim=-1)
out = self.relu(self.branch(out))
color = self.rgb_out(out)
return color, sigma