
VoxelNet
Region Proposal Network
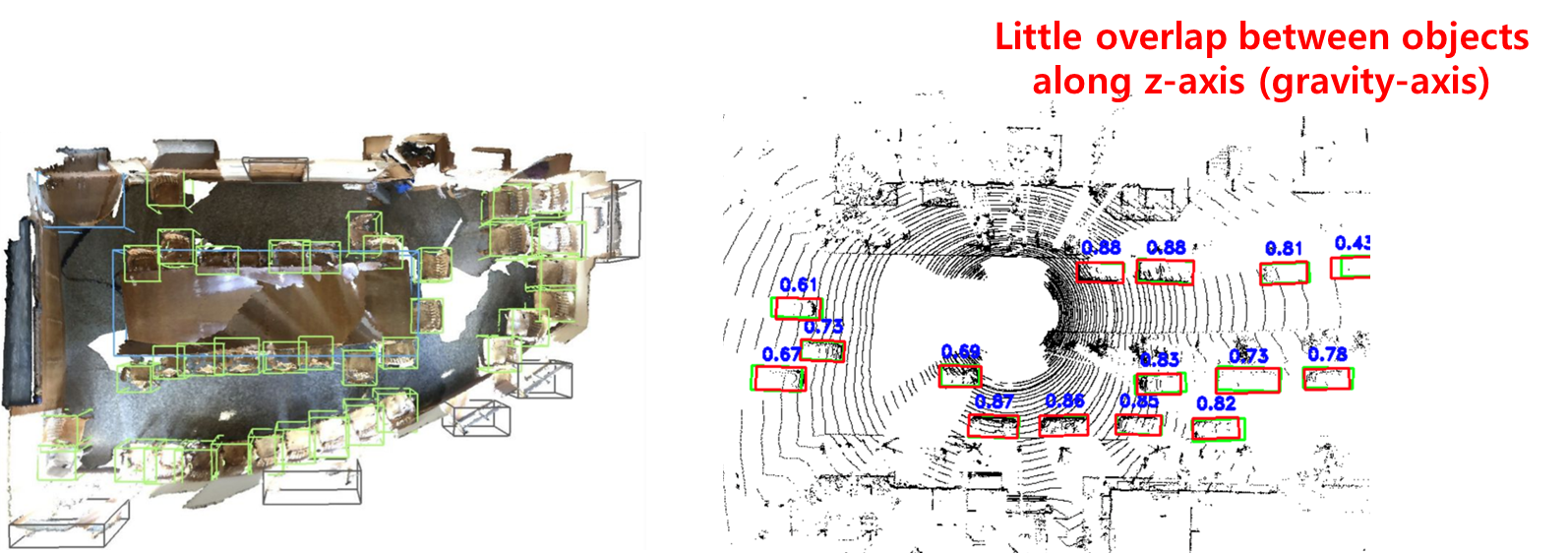
3D Object Detection의 특징은 3D를 BEV(Bird-eye_view), 즉 조감도처럼 2D의 이미지를 먼저 보고, 2D에서 region proposal을 하고 그 region에서 깊이까지 예측을 한다.
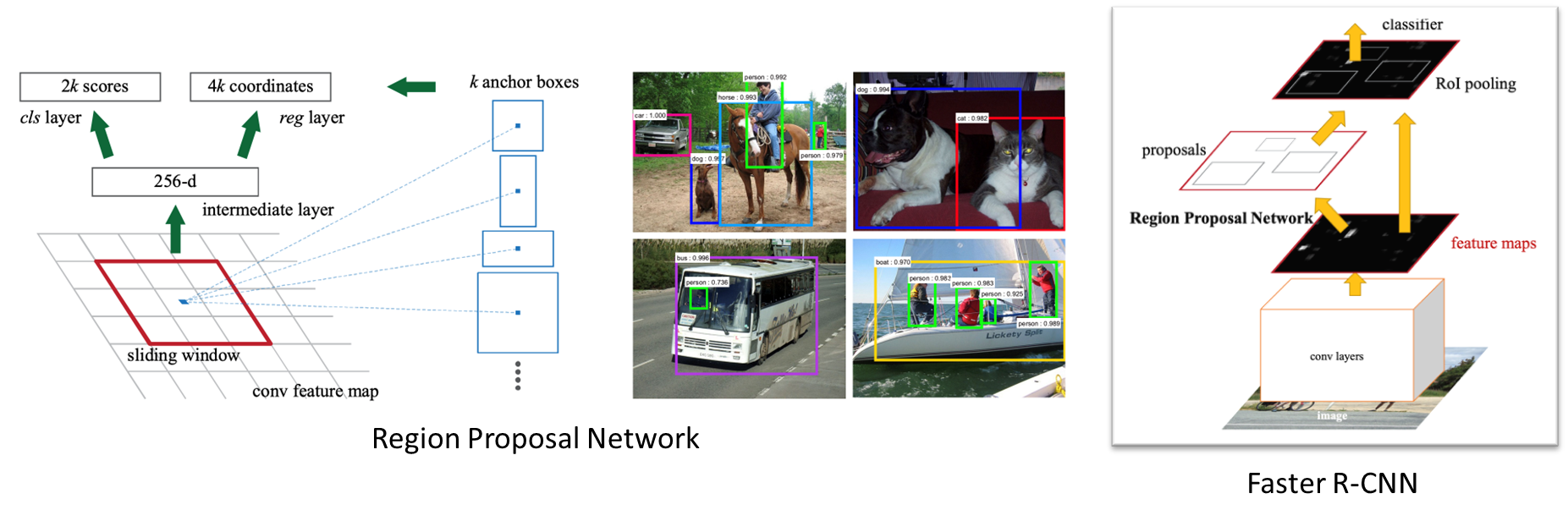
간단히 Region Proposal Network을 다시 말해보자면,
Region Proposal은 Faster R-CNN에서 제안된 것으로, 객체가 있을 만한 곳을 Proposal을 해주는 네트워크다.
필셀별로 미리 정의된 스케일이 다른 앵커 박스를 정의(Faster R-CNN에서는 9개)하고 객체가 있을 법한 바운딩 박스를 찾는다. 그리고 바운딩 박스 안에 있는 features을 RoI Pooling을 통해서 바운딩 박스를 예측한다.
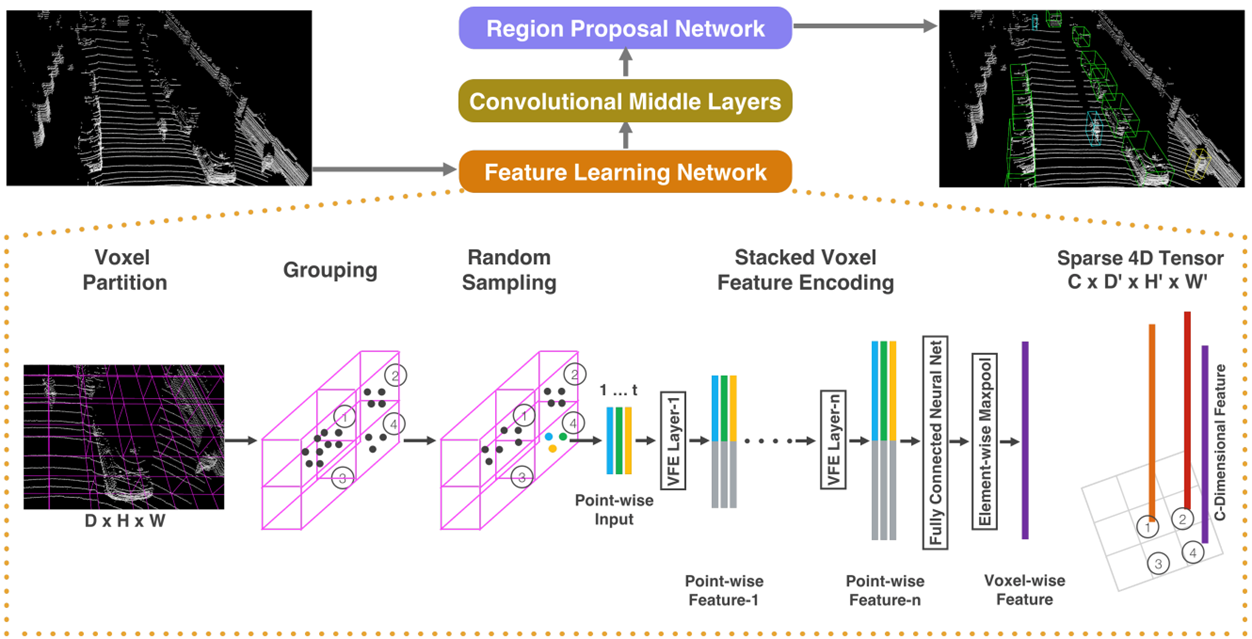
VoxelNet
VoxelNet의 원문은 End-to_End Learning for Point Cloud Based 3D Object Detection으로 3D Object Detection을 위한 네트워크로 처음으로 End-to_End Learning이 가능한 모델이다.
핵심적으로 제안된 부분은 Voxel feature encoding(VFE) layer다.
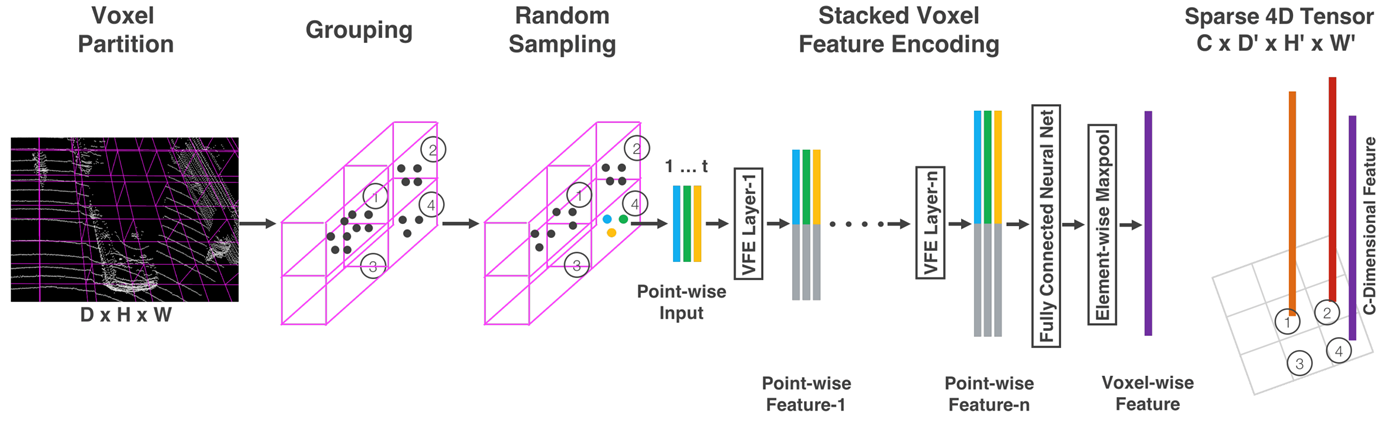
먼저 Feature Learning Network 과정에서 Point Clouds가 들어왔을 때 2D Image다운 Tensor로 Point Clouds를 만드는 과정이 중요하다.
Voxel Partition
LiDAR Point Clouds가 들어오면 resolution DHW 복셀 그리드를 정의한다.
Grouping
그리고 같은 Voxel 아에 들어가는 Point들에 대해서 Grouping을 한다. 일반적으로 MaxPooling 또는 MeanPooling을 한다.
Random Sampling
하지만 단순히 grouping을 해버리면 LiDAR Point Cloud의 특징인 멀어질수록 Sparse해지기에 밀도를 다루는데 있어 어려움이 있다. 이러한 점을 맞춰주기 위해 Random Sampling을 수행한다. 너무 많은 포인트가 있는 복셀들은 포인트를 줄여주는 효과를 가지게 된다.
VStacked Voxel Feature Encoding
이 후에 VFE layer을 통과하여 voxel feature를 최종적으로 얻게 된다.
Sparse 4D Tensor
DHW 위치에서 각각 C dimension의 feature를 가지고 있는 voxel feature grid가 만들어지고 이 4D 텐서를 2D conv으로 적용시킨다.
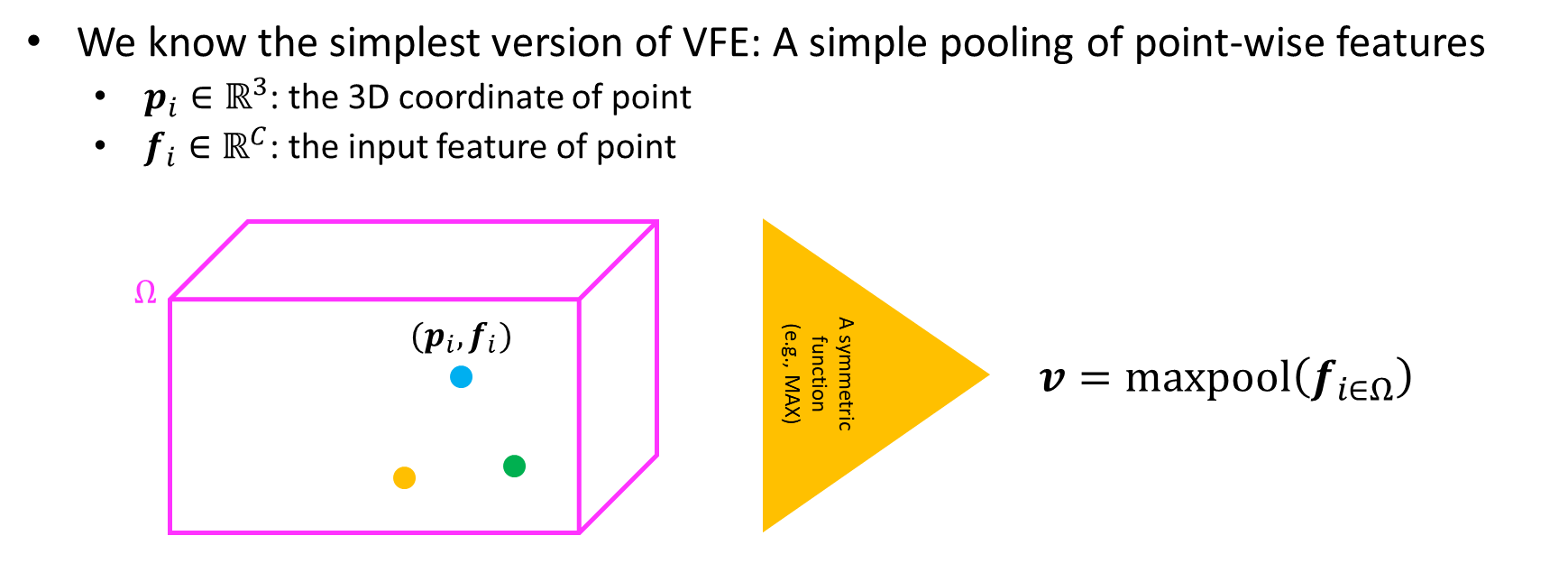
VFE
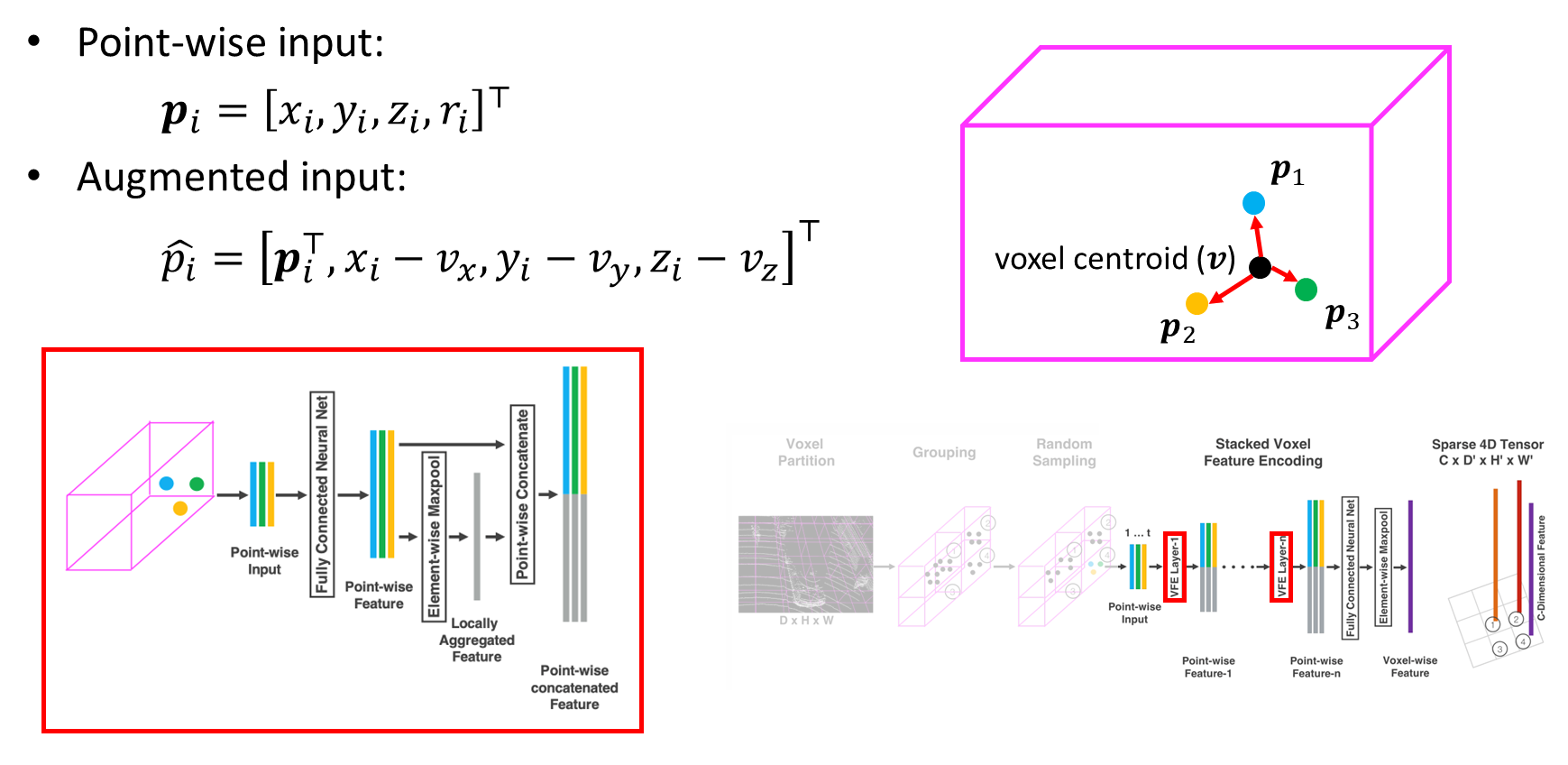
Voxel feature encoding(VFE) layer에 대해서 조금 자세하게 살펴보자.
기존의 복셀은 아래의 그림에서 상자와 같이 생겼다고 했을 때, 각 복셀 안의 point의 위치를 Pi, point의 input feature를 fi라고 한다.
그리고 복셀 안의 fi를 symmetric function, 예로 maxpooling, sumpooling, meanpooling 등을 이용해서 voxel feature v를 만든다. 이런 방법은 복셀 내부 포인트의 distribution을 인코딩할 수가 없게 된다. 왜냐하면 포인트들이 어떤 식으로 위치해 있든 fi를 pooling을 하게 되면 v라는 백터는 동일하기 때문이다.
LiDAR point cloud가 들어오면 복셀마다 density를 맞춰주는 Random Sampling 과정이 있다.
Random Sampling 다음, 아래의 그림과 같이 한 복셀 안에 Pi들, P1, P2, P3이 있고 복셀의 centroid v를 정의한다. 센트로이드에서 각 포인트까지의 이어진 위치를 계산해서 Augmented 한다. 이렇게 되면 Augmented input은 복셀 내부의 distribution을 인코딩할 수 있게 된다.
그래서 point-wise feature에 voxel feature를 붙여서 point-wise concatenated feature를 얻게 된다. 최종적으로 이 과정을 반복하여 Maxpooling을 하여 voxel-wise feature를 얻게 된다.
이렇게 만들어진 4D 텐서가 만들어지면 2D Conv을 이용하여 처리하게 된다.
아래의 그림은 RPN으로 feature map이 들어왔을 때 2D Conv를 이용하여 U-Net같은 형태로 수행을 한다. 그리고 최종적인 score map과 regression map을 예측한다.
2D RPN과 같이 2가지의 앵커를 미리 정의하는데, 앵커의 shape은 마지막의 전체 픽셀을 의미하고 각도만 기존의 90도 로테이션하여 정의한다.
그 다음 probability score map은 하나의 스칼라 값으로 각 앵커가 pos or neg한지 에측한다. 전체 앵커가 location마다 2개이기에 최종적으로 2개를 에측하게 되어 있다.
그 다음 3D 바운딩 박스이기 때문에 7개의 스칼라 값으로 표현할 수 있고 각 앵커마다 7개의 스칼라 값을 regression한다. 앵커마다 7개의 스칼라 값이기 때문에 2개의 앵커에 14개의 스칼라 값을 예측하게 된다.
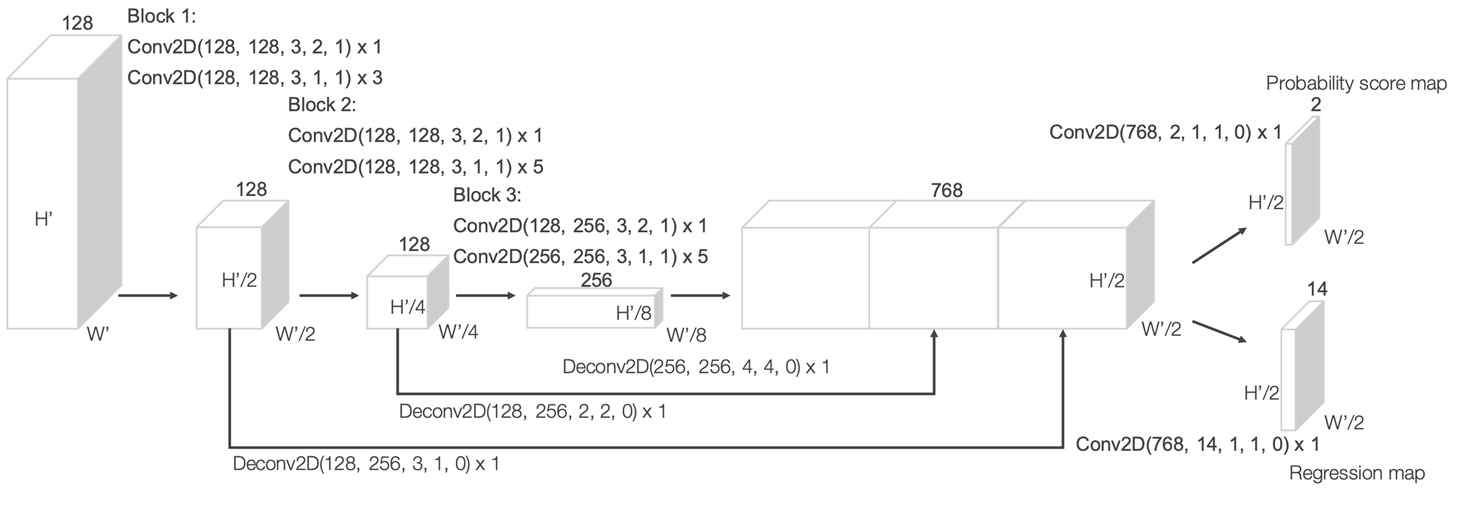
regression map 안의 2개의 앵커에 7개의 스칼라 값은 x, y, z 센터의 위치와 l, w, h라는 바운딩 박스의 크기와 세타(theta)로 이루어져 있다. theta는 z축(중력이 작동하는 축) 기준으로 theta만큼 회전시킨 것을 의미한다.

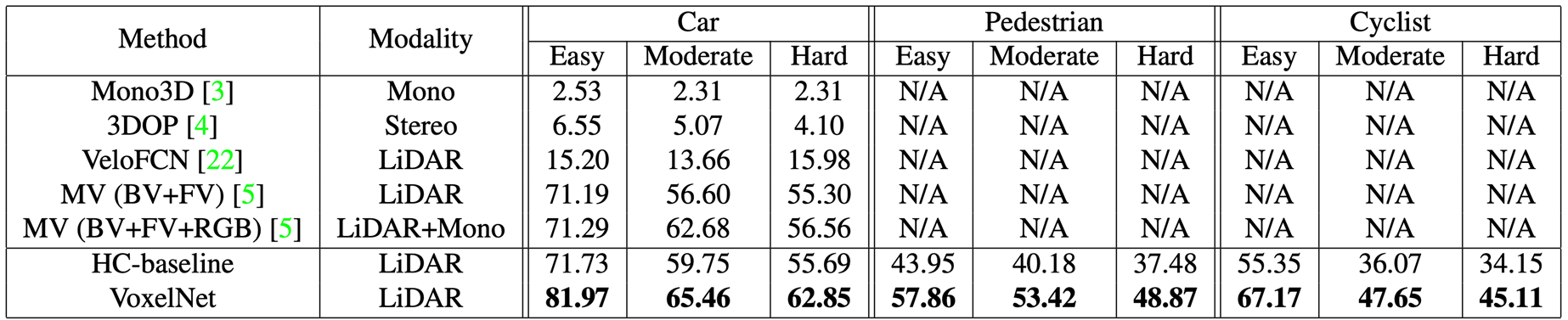
Results
KITTI Dataset에서 실험을 한 결과이다.
VoxelNet 아키텍처
참조 코드 : GitHub
VoxelNet Architecture는 torch_scatter와 MinkowskiEngine이라는 모듈을 사용하여 구현을 한다. 그래서 새로운 environment를 생성하여 진행하는 것을 추천한다.
torch_scatter는 Voxelization된 feature를 구하는데 유용하게 사용된다. 버전을 잘 맞춰 모듈을 사용할 수 있도록 한다.
그리고 Sparse Convolution을 제공하는 라이브러리들이 있다. 그 중에서 MinkowskiEngine을 사용하기로 한다.
3D IoU with oriented boxes (x, y, z, l, w, h, yaw)
def box_iou_3d(boxes1, boxes2):
N = len(boxes1)
M = len(boxes2)
# 1. Calculate 2D IoU.
def convert_3d_to_2d(boxes):
return torch.cat([
boxes[:, :2], boxes[:, 3:5], torch.cos(boxes[:, -1])[..., None], torch.sin(boxes[:, -1])[..., None]
], dim=1)
boxes1_2d = convert_3d_to_2d(boxes1)
boxes2_2d = convert_3d_to_2d(boxes2)
# boxes center, l, w -> 4ea boxes corners
iou, union, area1, area2 = box_iou(
box_center_to_corners(boxes1_2d),
box_center_to_corners(boxes2_2d),
return_areas=True
)
# 2. Find z-axis intersection.
boxes1_dz = 0.5 * boxes1[:, 5]
boxes1_z_max = boxes1[:, 2] + boxes1_dz
boxes1_z_min = boxes1[:, 2] - boxes1_dz
boxes2_dz = 0.5 * boxes2[:, 5]
boxes2_z_max = boxes2[:, 2] + boxes2_dz
boxes2_z_min = boxes2[:, 2] - boxes2_dz
inter_z_max = torch.min(torch.cat([
boxes1_z_max[..., None].repeat(1, M).unsqueeze(-1),
boxes2_z_max[None, ...].repeat(N, 1).unsqueeze(-1)
], dim=-1), dim=-1)[0]
inter_z_min = torch.max(torch.cat([
boxes1_z_min[..., None].repeat(1, M).unsqueeze(-1),
boxes2_z_min[None, ...].repeat(N, 1).unsqueeze(-1)
], dim=-1), dim=-1)[0]
inter_dz = inter_z_max - inter_z_min # (N, M)
inter_dz = inter_dz.clamp(min=0)
# 2. Cacluate 3D IoU.
iou_3d = torch.zeros(N, M) # init
inter = iou * union
inter_vol = inter * inter_dz # (N, M)
vol1 = area1 * boxes1[:, 5]
vol2 = area2 * boxes2[:, 5]
iou_3d = inter_vol / (vol1.unsqueeze(-1) + vol2.unsqueeze(-2) - inter_vol)
return iou_3dVoxel Feature Extraction(VFE) Layer
# voxelization
def ravel_hash(voxel_indices):
# 1. Find the maximum value of each axis.
max_index = np.max(voxel_indices, axis=0).astype(np.uint64) + 1
# 2. Hashing
keys = np.zeros(len(voxel_indices), dtype=np.uint64)
for d in range(voxel_indices.shape[1] - 1): # dimension
keys += voxel_indices[:, d]
keys *= max_index[d + 1]
keys += voxel_indices[:, -1]
return keys
def voxelize(points, voxel_size):
# 1. Make all the coordinates positive
origin = np.min(points, axis=0)
points = points - origin
# 2. Make the voxel indices and hash keys
voxel_indices = np.floor(points / voxel_size).astype(np.uint64)
keys = ravel_hash(voxel_indices)
# 3. Find the unique voxel indices and the mappings.
_, unique_mapping, inverse_mapping = np.unique(keys, return_index=True, return_inverse=True)
unique_voxel_indices = voxel_indices[unique_mapping]
return origin, unique_voxel_indices, unique_mapping, inverse_mapping
# Voxel Feature Extraction(VFE) Layer
class VFELayer(nn.Module):
def __init__(self, in_channels, out_channels, voxel_length):
super(VFELayer, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.l = voxel_length
# Feed-forward network : in_channels + x,y,z(3) + voxel centroid relitive position(x, y, z)(3)
self.ffn = nn.Sequential(
nn.Linear(3 + in_channels + 3, out_channels, bias=False),
nn.BatchNorm1d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, points, point_features):
# 1. Voxelization
_, _, unique_map, inverse_map = voxelize(points.numpy(), self.l)
M = len(unique_map)
inverse_map = torch.from_numpy(inverse_map)
# 2. Calculate the centroid of each voxel.
centroids = torch_scatter.scatter_mean(points, inverse_map, dim=0, dim_size=M)
rel_pos = points - centroids[inverse_map]
aug_point_features = torch.cat([points, point_features, rel_pos], dim=-1)
# 3. Feed-forward the augmented point features.
aug_point_features = self.ffn(aug_point_features)
# 4. Locally max-pool the features to calculate voxel features.
voxel_features, _ = torch_scatter.scatter_max(aug_point_features, inverse_map, dim=0, dim_size=M)
# 5. Point-wise concatenation.
out_point_features = torch.cat([aug_point_features, voxel_features[inverse_map]], dim=-1)
return out_point_features