
VoteNet(CVPR, 2020)
Indoor Scenes은 기본적으로 데이터 RGBD(RGB + Depth Camera) 스캐닝 방식을 사용한다.
Indoor 3D Scenes Object Detection의 input은 RGBD 이미지로 output은 3D 바운딩 박스로 z축 방향의 rotation이 있는 바운딩 박스를 해당하는 class label과 함께 예측하게 된다.
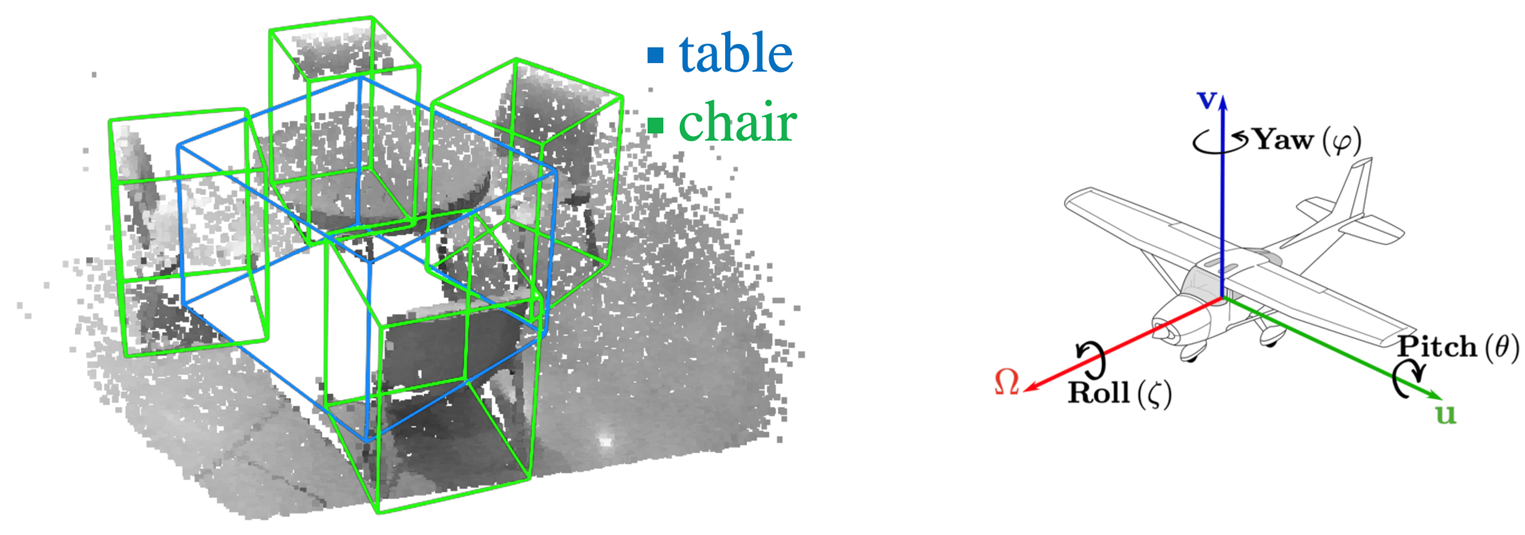
VoteNet(Deep Hough Voting for 3D Object Detection in Point Clouds)은 2D Detector를 사용하지 않는다. 그리고 Point Clouds 자체에서 3D Detection을 수행한다. 그리고 RGBD를 사용하지 않고 Depth Image만을 사용하여도, 기존의 RGBD Image를 사용하는 방법들보다 좋은 성능을 냈다는 특징이 있다.
Hough Voting
먼저 Hough Voting 방식이 무엇인지 잠시 살펴보도록 하자.
Hough Voting은 2D Detection에서 사용되던 방법으로, 아래의 그림과 같이 엣지 부분 등으로 관심가는 포인트들을 찾고 그 포인트의 일정한 크기의 패치를 추출한다. 그리고 패치에서 training에서 존재하는 패치 중 유사한 패치를 찾는다. training에서 각 패치마다 어떤 object center와 연관되어 있는지 알고 있고 training image를 바탕으로 voting을 하게 된다.

모든 voting이 옳바르게 voting이 될 수는 없다. 예로 아래의 그림과 같이 산의 엣지 부분의 패치가 '소'의 엉덩이 부분이랑 잘못 매칭이 되는 경우도 발생한다.

그래서 모든 매칭이 이루어진 다음에는 아래와 같이 voting이 밀집되어 있는 곳만 제대로 매칭이 된 voting라고 판단을 하고 Object Detection에 사용하게 된다. 즉 voting space에서 peak 부분만 사용한다고 볼 수 있다.

그리고 peak를 찾고 난 이후에는 voting에 기여한 패치들이 어디 있는지 다시 back projection하여 찾는다. 그리고 패치들을 바탕으로 아래와 같이 바운딩 박스에 대한 정보를 확인할 수 있게 된다.
이것이 2D Hough Voting의 방법을 이용한 Object detector다.

VoteNet 수행 단계
아래의 그림을 참조하여 살펴보자.
Input
VoteNet은 N개의 input을 Point cloud feature를 추출할 수 있는 backbone을 이용하여 Point feature를 추출한다. 논문에서 사용되는 backbone은 PointNet++을 사용한다.
Seeds
추출된 Point feature를 interest points(Seed Point)를 샘플링한다. 샘플링 과정은 Point Transformer에서 사용된 Farthest point sampling(FPS)를 사용한다.
Votes
샘플링을 통해 추출된 M개의 Seed Points에 대하여 Shared MLP를 이용한 voting 과정을 수행한다. voting 과정은 각 seed point에 할당된 object의 center를 에측하는 과정이다.
Vote clusters
Vote 과정에서 빨간점처럼 vote가 있으면 clustering을 통해 voting의 peak 지점을 찾는다. cluster의 개수는 미리 지정하는 k개로 FPS를 이용하여 k개의 cluster center를 먼저 샘플링한다.
Output
그 이후에 radius search를 이용한 grouping을 수행하여 같은 cluster 안에 있는 Point feature를 aggregation하여 마지막 바운딩 박스를 예측하게 된다.
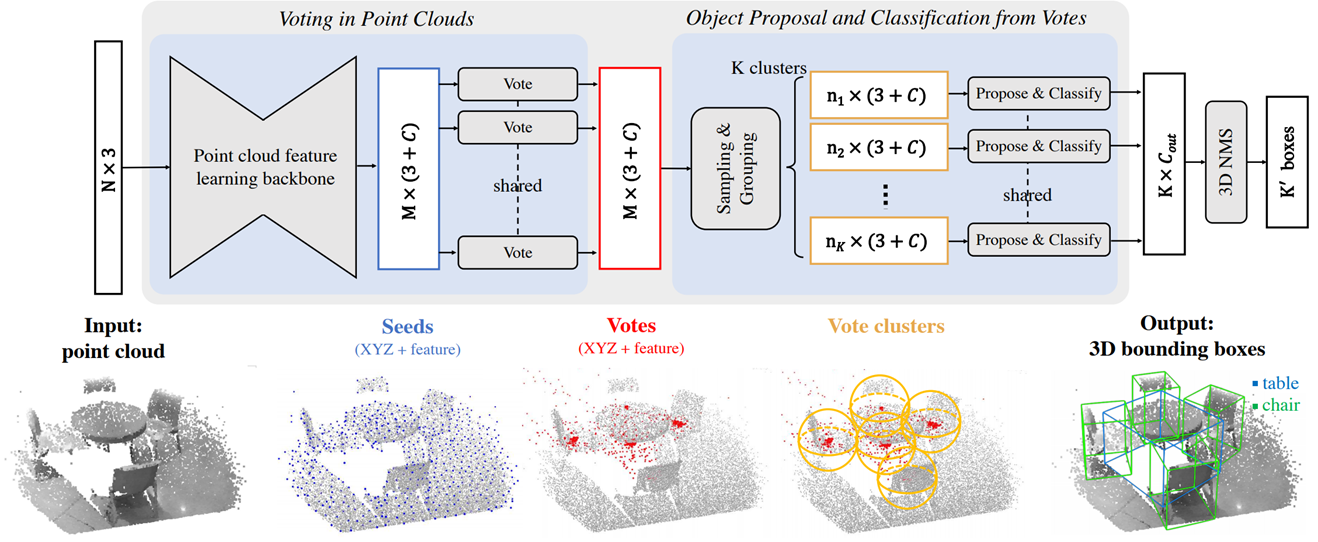
VoteNet은 기본적으로 2 Stage Object Detection 형식을 따르고 있기 때문에 마지막 부분에 3D non-maximum suppression(NMS)과정이 필수적으로 들어가게 된다.
2D Hough Voting에서는 바운딩 박스를 찾기 위해 voting을 하는데 기여한 패치들을 back projection하는 과정이 필요했던 반면, 3D VoteNet에서는 clustering하여 찾아낸 cluster features를 aggregation하여 Pooling할 것인지 MLP를 통해서 학습을 하게 된다.
Loss
Vote Regression Loss
Seed point들이 object 중심을 잘 예측할 수 있도록 Regression Loss가 있다.
그 다음은 2 Stage Object Detection 형식을 따르고 있다.
Classification Loss
Proposal된 바운딩 박스가 object인지 아닌지 분류하는 Classification Loss가 있다.
Bounding Box Regression Loss
예측된 Bounding Box의 크기를 예측하는 Regression Loss가 있다.
semantic Classification
예측된 Bounding Box에서 각 semantic class가 무엇인지 분류하는 Classification Loss가 있다.
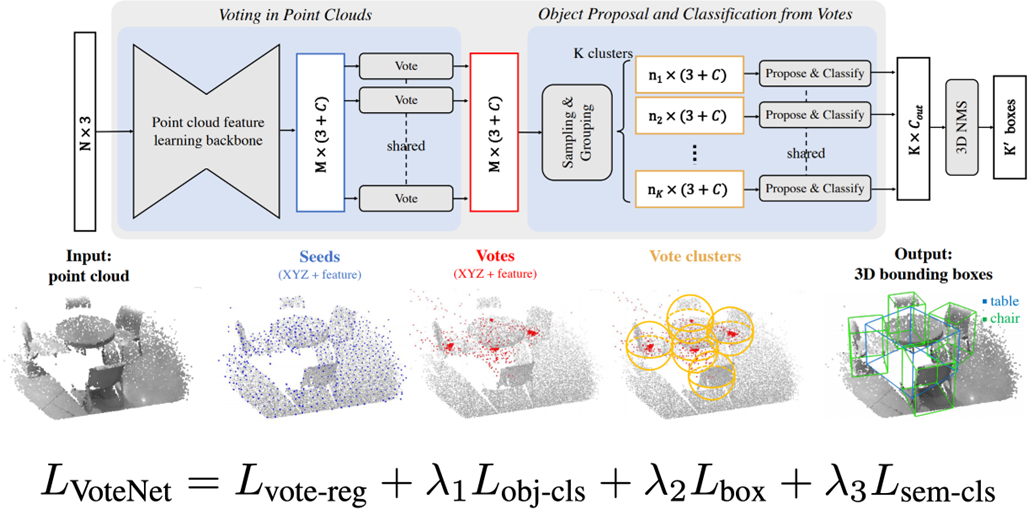
Vote Regression Loss 다음의 3가지 Loss는 기존의 2 Stage Object Detection에서 사용한 Loss와 같다.
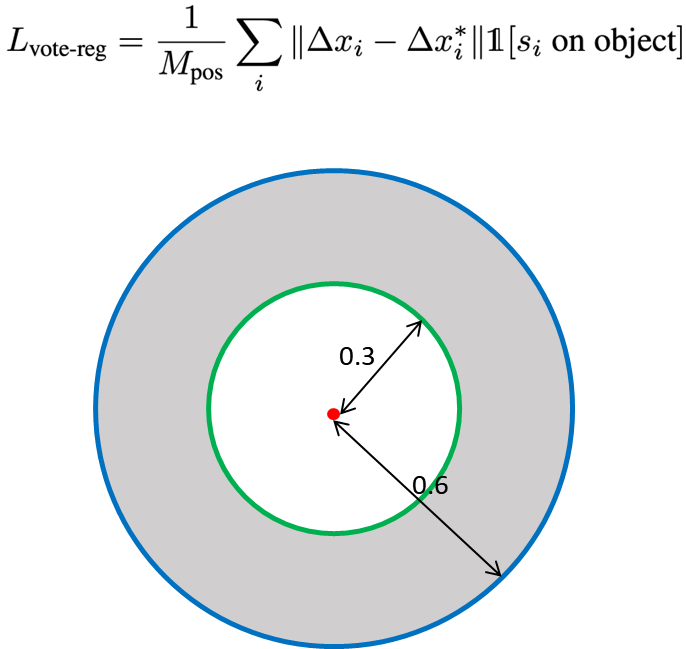
Vote Regression Loss 좀 더 살펴보자면, Seed point가 object일 때 Loss를 계산한다.
아래의 계산식에서 보면, s1(seed point) on object는 Seed point가 object 위에 있을 때를 의미하는 것으로 Seed point에만 Loss를 주고 아닐 때에는 Loss를 주지 않는다.
그러면 object인지 아닌지 판단하는 것은 아래의 그림과 같이, object 중심으로부터 0.3 이내에 있으면 objcet 안에 있다고 보고 0.6보다 밖에 있으면 아니라고 본다.
실험 결과를 살펴보면. VoteNet의 Input은 Geo metric(Depth)만을 사용하여도 기존의 방법들보다 좋은 성능을 보이고 있다.

VoteNet 아키텍처
참고
Point feature를 추출하는 부분과 Farthest point sampling은 PointNet++ 또는 Point Transformer 아키텍처를 참고한다.
-
참고 : Point Transformer
-
소스 코드 : GitHub
Radius Search
N개의 dataset points에서 M개의 query points 중에서 Radius 안에 들어가는 points를 찾는 것이기에 매번 output이 달라질 수 있다. 그래서 indices를 list 형태로 반환한다.
def find_radius_general(query_points, dataset_points, r):
M = len(query_points)
N = len(dataset_points)
# 1. Compute pairwise distance
delta = query_points.view(M, 1, 3) - dataset_points.view(1, N, 3) # (M, N, 3)
dist = torch.sum(delta ** 2, dim=-1) # (M, N)
# 2. Find indices
mask = dist < r
indices = []
for mask_ in mask:
indices.append(torch.nonzero(mask_, as_tuple=True)[0]) # index 부분 저장
return indicesIoU for Axis-aligned 3D Bounding Boxes
2개의 bounding box의 IoU
def cal_iou3d(bb1, bb2):
# bounding box: (x1, y1, z1, x2, y2, z2), z1 < z2
# Use the same coordinate system
# 1. Find coordinates of the intersection cuboid.
x_small = max(bb1[0], bb2[0])
y_small = max(bb1[1], bb2[1])
z_small = max(bb1[2], bb2[2])
x_large = min(bb1[3], bb2[3])
y_large = min(bb1[4], bb2[4])
z_large = min(bb1[5], bb2[5])
# 2. If there is no overlap, return 0. Otherwise, find the overlapped volume.
if x_large < x_small or y_large < y_small or z_large < z_small:
iou = 0.
else:
intersection_volume = (x_large - x_small) * (y_large - y_small) * (z_large - z_small)
bb1_volume = (bb1[3] - bb1[0]) * (bb1[4] - bb1[1]) * (bb1[5] - bb1[2])
bb2_volume = (bb2[3] - bb2[0]) * (bb2[4] - bb2[1]) * (bb2[5] - bb2[2])
iou = intersection_volume / (bb1_volume + bb2_volume - intersection_volume)
return iouNMS를 구현할 때에는 보통 중심이 되는 바운딩 박스와 다른 바운딩 박스들(박스 셋)간의 IoU를 구하는 경우를 구현해야 한다.
def cal_iou3d_multi(box, boxes):
# box: (x1, y1, z1, x2, y2, z2), z1 < z2
# boxes: (N, 6)
# Use the same coordinate system
# 1. Find coordinates of the intersection cuboid.
x_small = boxes[:, 0].clamp(min=box[0])
y_small = boxes[:, 1].clamp(min=box[1])
z_small = boxes[:, 2].clamp(min=box[2])
x_large = boxes[:, 3].clamp(max=box[3])
y_large = boxes[:, 4].clamp(max=box[4])
z_large = boxes[:, 5].clamp(max=box[5])
# 2. Define the delta tensor.
x_delta = x_large - x_small
y_delta = y_large - y_small
z_delta = z_large - z_small
# 3. Calculate IoUs.
iou = torch.zeros((len(boxes),), dtype=box.dtype)
has_overlap = (x_delta > 0) * (y_delta > 0) * (z_delta > 0)
# 4. Find the overlapped volume if there is overlap.
if len(has_overlap.nonzero()) == 0:
return iou
else:
boxes_valid = boxes[has_overlap]
x_delta_valid = x_delta[has_overlap]
y_delta_valid = y_delta[has_overlap]
z_delta_valid = z_delta[has_overlap]
intersection_volume = x_delta_valid * y_delta_valid * z_delta_valid
box_volume = (box[3] - box[0]) * (box[4] - box[1]) * (box[5] - box[2])
boxes_volume = (boxes_valid[:, 3] - boxes_valid[:, 0]) \
* (boxes_valid[:, 4] - boxes_valid[:, 1]) \
* (boxes_valid[:, 5] - boxes_valid[:, 2])
iou_valid = intersection_volume / (box_volume + boxes_volume - intersection_volume)
iou[has_overlap] = iou_valid
return iou3D Non-Maximum Suppression
IoU를 구하는 함수를 가지고 3D NMS를 구현한다.
def nms(boxes, scores, threshold):
# 1. Sort boxes in the ascending order of scores.
order = scores.argsort()
# 2. Iteratively perform NMS.
keep = []
while len(order) > 0:
# 2-1. Pick the box with the highest score among the remaining boxes.
idx = order[-1]
box = boxes[idx]
keep.append(box)
order = order[:-1]
if len(order) == 0:
break
# 2-2. Calculate IoU between the selected box and the others.
remaining_boxes = boxes[order]
iou = cal_iou3d_multi(box, remaining_boxes)
# 2-3. Find the non-maximum boxes.
mask = iou < threshold
order = order[mask]
return torch.stack(keep)Voting Module (including feature extraction)
class VotingModule(nn.Module):
def __init__(self, in_channels, out_channels, num_votes, ratio, k):
super(VotingModule, self).__init__()
self.num_votes = num_votes
self.pfe = SimplePointTransformer(in_channels, out_channels, ratio, k) # Point Feature Extractor
self.voter = nn.Sequential(
nn.Linear(out_channels, out_channels, bias=False),
nn.BatchNorm1d(out_channels),
nn.ReLU(inplace=True),
nn.Linear(out_channels, 3 + out_channels) # delta_x (3) and delta_f (C_out)
)
def forward(self, points, features):
# 1. Point Feature Extraction (In our case, Point Transformer)
out_features = self.pfe(points, features)
# 2. Sample seed points
indices = farthest_point_sampling(points, self.num_votes)
seed_points = points[indices]
seed_features = out_features[indices]
# 3. Voting
residuals = self.voter(seed_features)
vote_points = seed_points + residuals[:, :3]
vote_features = seed_features + residuals[:, 3:]
return vote_points, vote_featuresDetection Head
class DetectionHead(nn.Module):
def __init__(self, in_channels, num_clusters, radius, nms_iou_threshold):
super(DetectionHead, self).__init__()
self.num_clusters = num_clusters
self.radius = radius
self.nms_iou_threshold = nms_iou_threshold
self.mlp1 = nn.Sequential(
nn.Linear(3 + in_channels, in_channels),
nn.ReLU(inplace=True),
nn.Linear(in_channels, in_channels),
nn.ReLU(inplace=True)
)
self.mlp2 = nn.Sequential(
nn.Linear(in_channels, in_channels),
nn.ReLU(inplace=True),
nn.Linear(in_channels, in_channels),
nn.ReLU(inplace=True)
)
self.final = nn.Linear(in_channels, 7)
def forward(self, vote_points, vote_features):
# 1. Sample cluster centroids.
sampled_indices = farthest_point_sampling(vote_points, self.num_clusters)
cluster_points = vote_points[sampled_indices]
# 2. Find cluster neighbors.
indices = find_radius_general(cluster_points, vote_points, self.radius) # List[torch.LongTensor]
# 3. Grouping (MLP1 and MLP2)
grouped_features = []
for group_center, group_indices in zip(cluster_points, indices):
# 3-1. Calculate the relative position.
features_in_group = vote_features[group_indices]
relative_pos = (group_center.unsqueeze(0) - vote_points[group_indices]) / self.radius
features_with_pos = torch.cat([relative_pos, features_in_group], dim=1)
# 3-2. MLP1 -> MaxPool -> MLP2
group_feature = self.mlp1(features_with_pos).max(dim=0)[0]
group_feature = self.mlp2(group_feature)
grouped_features.append(group_feature)
grouped_features = torch.stack(grouped_features)
# 4. Predict bounding boxes
boxes = self.final(grouped_features)
box_scores = boxes[:, 0].sigmoid()
box_coordinates = boxes[:, 1:]
# 5. Non-maximum suppression
final_boxes = nms(box_coordinates, box_scores, self.nms_iou_threshold)
return final_boxes