
지난 시간에 리서치한 것을 바탕으로 혐오 표현 탐지에 사용할 수 있을만한 PLM을 몇 가지 뽑아서 각 모델 별 특징을 정리해보았다. 이후, 간단하게 각 모델 별 성능을 측정하여 베이스라인 모델을 선택해봤다.
🇰🇷 Korean Pretrained Language Models 🇰🇷
선택한 모델들은 공통적으로 정제되지 않은 구어체, 신조어 등 공식적인 글쓰기에 나타나지 않은 표현들을 학습한 모델들이다(KoELECTRA는 제외). 현재 태스크는 유저들이 직접 작성한 댓글에 욕설 및 혐오 표현이 있는지 없는지를 판단하기 때문에 비정제 데이터를 학습한 모델이 적합할 것이라고 예상되어서 아래와 같은 모델을 후보로 선택해봤다.
1. KcBERT
Reference : https://github.com/Beomi/KcBERT
Data
- 2019.01.01 ~ 2020.06.15 사이에 작성된 댓글 많은 뉴스들의 댓글과 대댓글을 모두 수집한 데이터를 사용하여 학습 [KcBERT 댓글 데이터]
- 아래와 같은 전처리 과정을 거친 데이터를 사용하여 약 8.9천만 문장 학습(12.5GB)
- 한글, 영어, 특수문자, 이모지를 모두 포함하고 한자는 제외
- 댓글 내의 중복 문자열은 축약하여 사용(ㅋㅋㅋㅋㅋ ➡️ ㅋㅋ)
- 영문에 대한 대소문자를 유지하는 cased model
- 10글자 미만의 텍스트 제외
- 중복 문장 제외
- Huggingface의 Tokenizers 라이브러리를 통해 토크나이저 학습
BertWordPieceTokenizer이용
2. TUNiB-ELECTRA
Reference
https://github.com/tunib-ai/tunib-electra
https://tunib.tistory.com/entry/20211119-김수환-연구원-SOSCON-2021-발표-영상
Data
- 약 100GB의 한국어 텍스트(
Ray를 이용하여 크롤링 진행)- 모두의 말뭉치 데이터
- AI Hub 텍스트 데이터
- 블로그 데이터
- 뉴스 기사
- 댓글(블로그, 뉴스, 커뮤니티, 학교 커뮤니티)
- 질문/답변 데이터
- 대화 데이터
- 웹소설
- 나무위키, 한국어 위키피디아
- 청와대 국민 청원 데이터
- 공개된 음성 인식 데이터 전사 데이터
- 전체 데이터에 대해 아래와 같은 전처리 수행
- HTML 태그 삭제
- 한자, 일본어 비율이 높은 데이터 삭제
- 전체 문장 길이 대비 띄어쓰기의 비율이 너무 낮거나 높은 문장 제거
- 전체 문장 길이 대비 특수문자 비율이 높은 문장 제거
- 길이가 너무 짧은 문장 제거
- 특수문자 관련 처리
- Huggingface의 Tokenizer 라이브러리를 통해 토크나이저 학습
- 모든 데이터 소스로부터 같은 양을 샘플링한 2GB 데이터 사용
- WordPiece 방식 사용
3. KoELECTRA
Reference
https://github.com/monologg/KoELECTRA
https://monologg.kr/2020/05/02/koelectra-part1/
Data
- 약 34GB의 한국어 텍스트 데이터
- 뉴스, 위키피디아, 나무위키, 모두의 말뭉치 등
- 아래와 같은 전처리 적용
- 한자, 일부 특수문자 제거
- 한국어 문장 분리기 (kss) 사용
- 뉴스 관련 문장은 제거 (
무단전재,(서울=뉴스1)등 포함되면 무조건 제외)
- Huggingface의 Tokenizers 라이브러리를 통해 학습
BertWordPieceTokenizer이용- v1, v2에서는
wordpiece만을 사용 - v3에서는
mecab과wordpiece를 이용
4. KcELECTRA
Reference
https://github.com/Beomi/KcELECTRA
data
- 2019.01.01 ~ 2021.03.09 사이에 작성된 댓글 많은 뉴스/전체 뉴스 기사들의 댓글과 대댓글을 모두 수집한 데이터
- KcBERT의 학습 데이터 + 2020.07~2021.03 초반의 뉴스
- KcBERT와 동일한 전처리 과정을 거친 데이터를 사용하여 약 1억 8천만 문장 학습(17.3GB)
- Huggingface의 Tokenizers 라이브러리를 통해 토크나이저 학습
BertWordPieceTokenizer이용
🤔 실험_PLM에 따른 성능 비교
별도의 데이터 전처리, 모델 구조 변경 없이 학습을 진행하여 각 PLM에 따른 Hate speech detection 성능 비교를 진행.
실험 환경
data
- Korean HateSpeech Dataset
- multi-class, multi-label 데이터이지만 kaggle의 리더보드와의 비교를 위하여 우선적으로
hate speech class만을 대상으로 테스트를 진행. hate,offensive,none
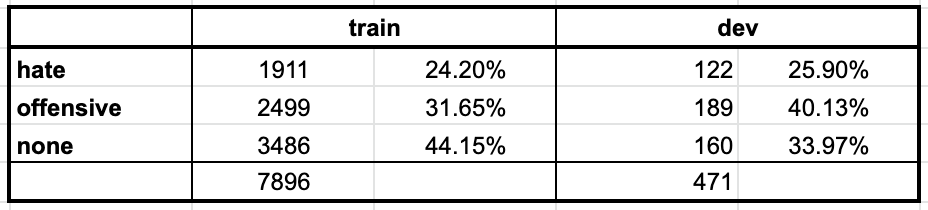
- multi-class, multi-label 데이터이지만 kaggle의 리더보드와의 비교를 위하여 우선적으로
model
- KcBERT-large
- KoELECTRA-base-v3
- KcELECTRA-base
- TUNiB-ELECTRA-ko-base
코드(reference)
- https://github.com/monologg/korean-hate-speech-koelectra
- 해당 코드는
bias class,hate class모두에 대해 학습하도록 구현이 되어 있어서 참고하여 몇 가지 수정하요 실험에 사용.
- 해당 코드는
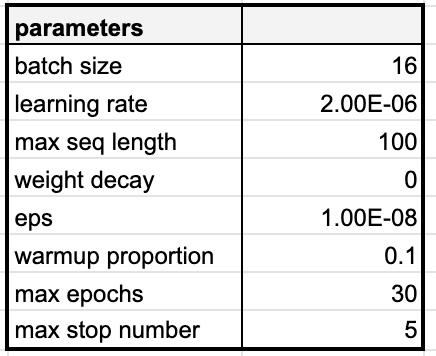
Hyperparameters
- 모든 모델에 대해 고정하여 한 번만 튜닝
✔️ 모델 별 성능
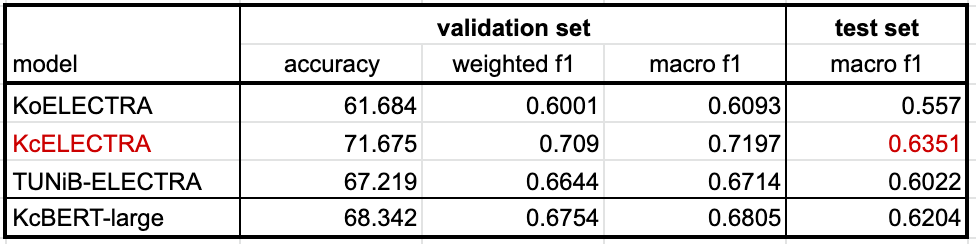
- 예상했던 것처럼 비정제 데이터로 학습한 KcBERT, KcELECTRA가 높은 성능을 보임.
- TUNiB 모델의 경우에는 비정제 데이터와 정제 데이터 모두 트레이닝 했기 때문에 KoELECTRA에 비하면 비교적 높은 성능을 보이긴 하지만, KcBERT/KcELECTRA에 비하면 낮은 성능을 보임.
- KcBERT/KcELECTRA는 유저가 직접 작성한 데이터(인터넷 상에 작성한 댓글 등)를 대상으로 하는 태스크를 목적으로 만들어진 반면에 TUNiB의 모델은 정제 데이터도 학습하여 좀 더 일반적인(general)한 부분에선 더 높은 성능을 보일 것이라고 예상.
✔️ 다음 실험의 방향성
이번 실험에서 모델에 따른 성능 비교를 한 결과, KcELECTRA의 성능이 가장 높았다. 이를 바탕으로 KcELECTRA를 활용한 성능 향상 방향을 정해보았다.
참고
🖇️ KcBERT는 튜닝을 한다면 KcELECTRA와 비슷한 성능이 나올 수도 있지만, 아래와 같은 이유로 배제- KcBERT의 경우에는 Large 모델을 이용했기 때문에 다른 비교 모델에 비해 큰 사이즈를 가지고 있음. → 인퍼런스 시의 속도와 GPU 사용량의 문제로 메리트가 없어보임
- pre-training 단계에서 KcELECTRA가 더 많은 데이터를 학습함(약 2배)
- KcBERT와 KcELECTRA의 저자 이준범님에 따르면, hate speech detection 뿐만 아니라 모든 태스크에서 KcELECTRA가 더 낫다고 함
1️⃣ 모델의 구조 변화
- 현재는 레퍼런스 코드에 따라서 PLM 위에 단순한 classification layer만을 추가한 상태
dropout(rate = 0.1) +linear layer(256, 3)
- KcELECTRA를 이용한 hate speech detection 모델을 만든 다른 글에 따르면 classification layer를 약간만 변경했음에도 f1 score(test_set) = 0.66421으로 리더보드 2위를 달성했다고 함.
- PLM +
Linear(256, 515) +ReLU+dropout(rate=0.5) +Linear(515, 3)
- PLM +
2️⃣ 기사 제목 활용

- Korean HateSpeech Dataset에는 댓글 내용 뿐만 아니라 해당 댓글이 달린 뉴스의 기사 제목 정보도 얻을 수 있음.
- 레퍼런스 코드에서는 이 정보를 활용하고 있고, 기사 제목/내용과 댓글 간에는 유사 관계가 있기 때문에 이를 피쳐로 활용한다면 분류에 유용한 정보가 될 수 있을 것이라고 예상됨.
- 기사 제목의 [종합], (종합) 등 불필요한 정보를 제거하는 전처리 과정 후에
title,comment를 text pair로 인코딩하여 활용.
3️⃣ unlabeled data 활용
데이터셋에 unlabeled 데이터가 2,033,893 문장 포함되어 있음. 이를 활용하기 위하여 semi-supervised learning 방법론을 리서치 중.
➡️ 현 프로젝트와 관련된 다음 포스팅은 NLP에 사용되는 semi-supervised learning과 관련된 내용으로 결정.
