
1. 서론
모델 성능 개선을 위한 다음 단계로는 이전에 2. 베이스라인 모델 선택하기에서 생각했었던 unlabeled data를 활용하는 방법을 선택하여 실험하기로 결정했다. 이를 적용하기 위해서는 이전에 리서치를 진행했던 Semi-supervised learning for Text classification의 MixText를 활용하고자 한다.
- MixText에서는 데이터 증강을 위해서 back-translation을 활용하는데 이를 그대로 hate speech detection에 적용하기엔 무리가 있다. (아래 그림 참고)
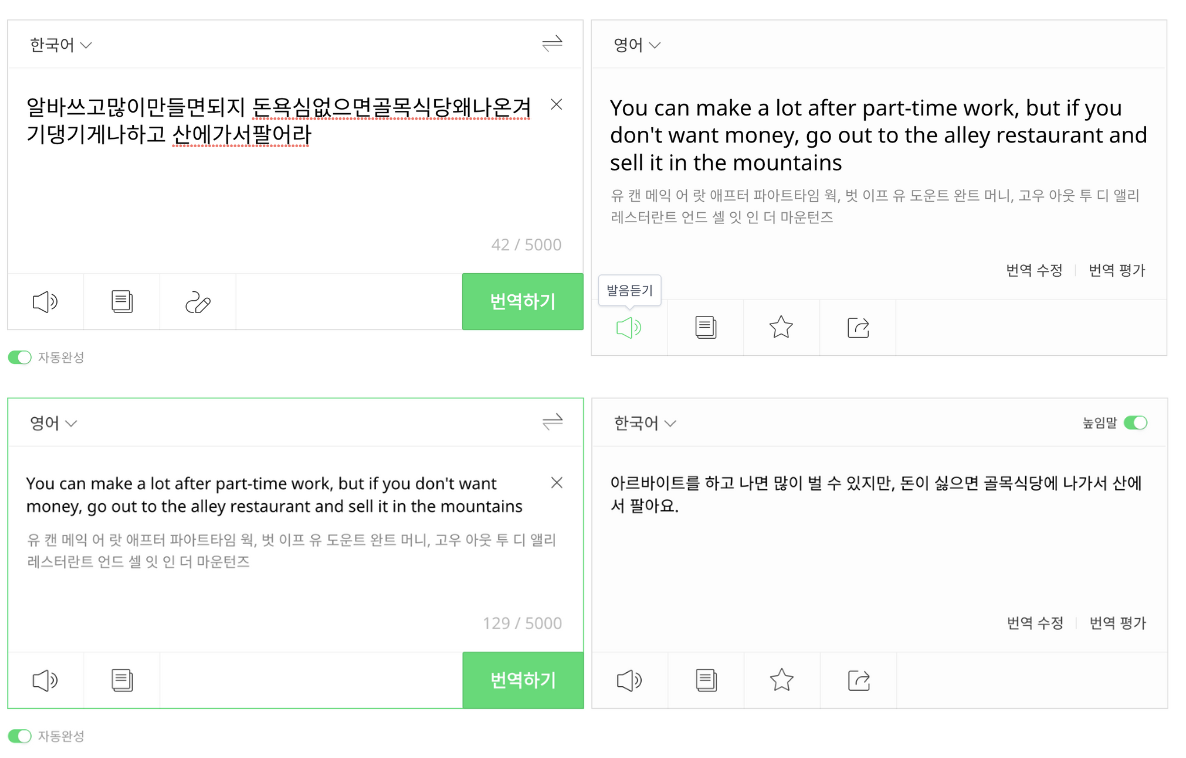
- 원본 문장의 뜻이 달라지고, 기존 입력과 다르게 정제된 형태로 변환되는 문제가 있음.
- 원본 문장의 뜻이 달라지고, 기존 입력과 다르게 정제된 형태로 변환되는 문제가 있음.
- 아래는 MixText의 과정을 나타낸 그림이고, 아래 그림에서 back-translation(남색 박스)를 대신할 데이터 증강 방식을 찾기
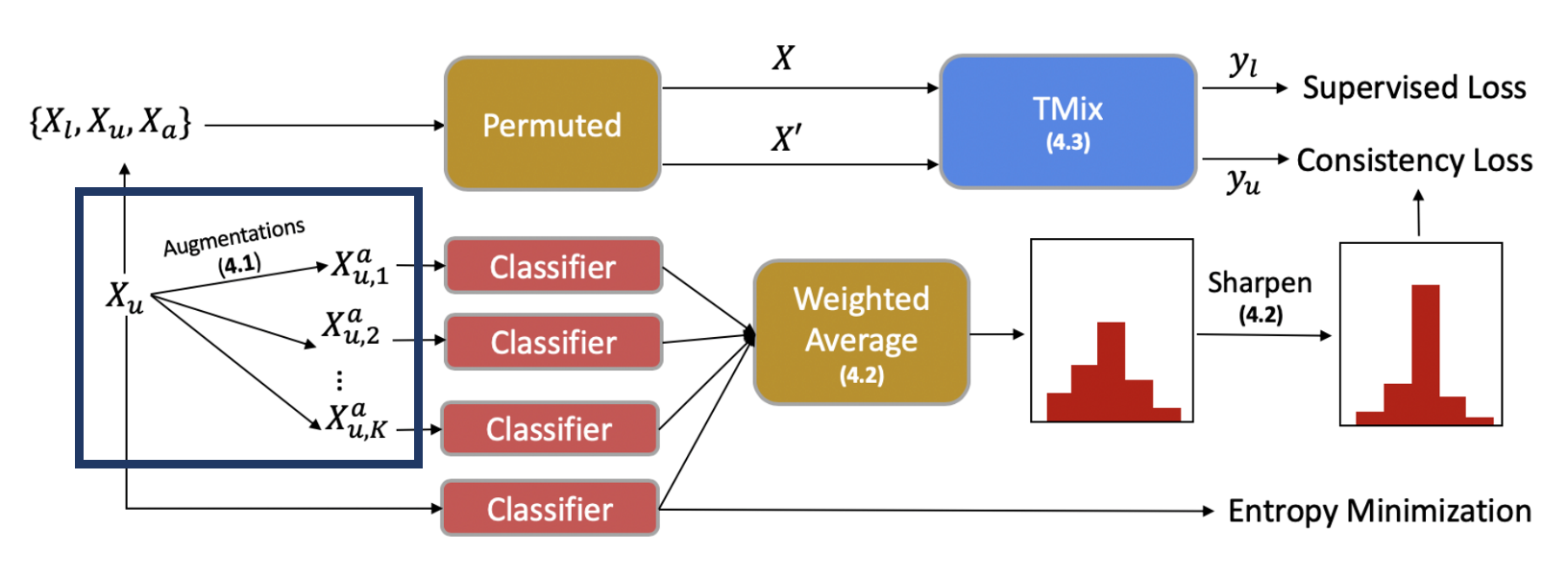
2. Masked Language Modeling 활용
원문장의 임의의 토큰을 마스킹하고, MLM 방식으로 학습한 모델을 이용하여 해당 마스크에 새로운 토큰을 생성해내는 방식으로 데이터를 증강하는 방식
reference
한국어 상호참조해결을 위한 BERT 기반 데이터 증강 기법
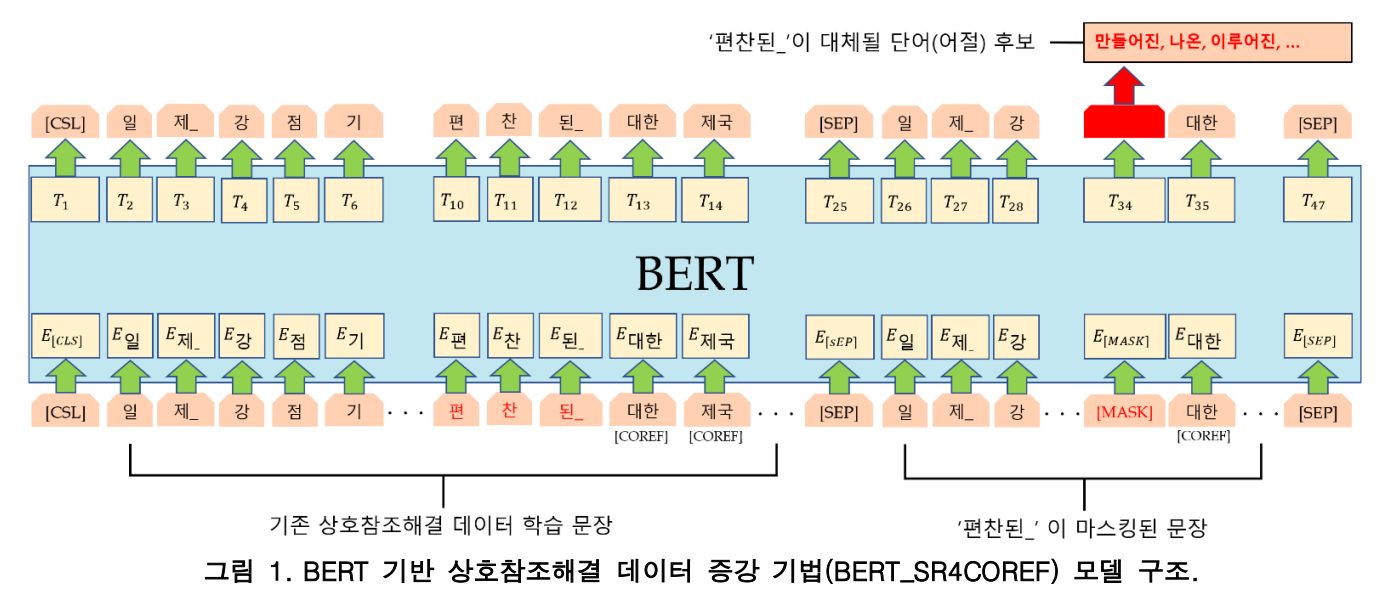
-
논문에서는 어절 단위로 마스킹을 한 후에 새로운 어절을 생성해냈다고 한다.
-
하지만, Hate Speech Detection은 비정제 데이터를 대상으로 할 때는 맞춤법 및 띄어쓰기가 제대로 되어 있지 않아서 어절 단위가 불명확하기 때문에 PLMTokenizer 토큰 단위로 마스킹 및 생성을 진행했다.
-
논문에서는 전체 입력 문장 어절에 대해서 0.1의 마스킹 비율을 적용했을 때 가장 성능이 좋았다고 한다.
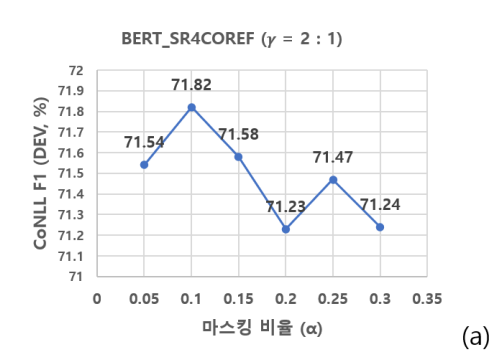
- 논문을 따라서 초기엔 0.1을 적용하고, 추후에 적절한 값을 찾아보도록 한다.
✔️ 실험 세팅
- KcELECTRA-base를 기반으로 하며, Huggingface의 ElectraForMaskedLM 구조를 그대로 사용한다.
- 코드는 깃헙에 올려놨지만, 추후에 Readme와 코멘트를 업데이트 해야할 것 같다😅
(https://github.com/seoyeon9646/MLM-data-augmentation)
- 코드는 깃헙에 올려놨지만, 추후에 Readme와 코멘트를 업데이트 해야할 것 같다😅
- 데이터셋의 구성은 아래와 같다.
- Korean hate speech dataset의 unlabeled 데이터 전체에 대해서 중복 제거 후, 랜덤으로 1,000,000 문장을 선택(나머지는 추후에 MixText에 활용하기 위함 - 841,686 문장)
- Naver Sentiment Movie Corpus 중복 제거 후 전체 사용 - 194,544 문장
- 이전 실험에서 사용했던 hate speech dataset의 train, dev set 전체 사용 - 19,620 문장
→ 랜덤으로 9 : 1로 나누어 train, dev set으로 사용
- 참고했던 논문과는 다르게 text_pair 방식을 사용하지 않았고, 마스킹 및 랜덤으로 다른 토큰으로 교체한 문장을 입력으로 사용하여 원 문장의 토큰을 레이블로 가지도록 학습을 했다. 이를 그림으로 나타내면 아래와 같다.
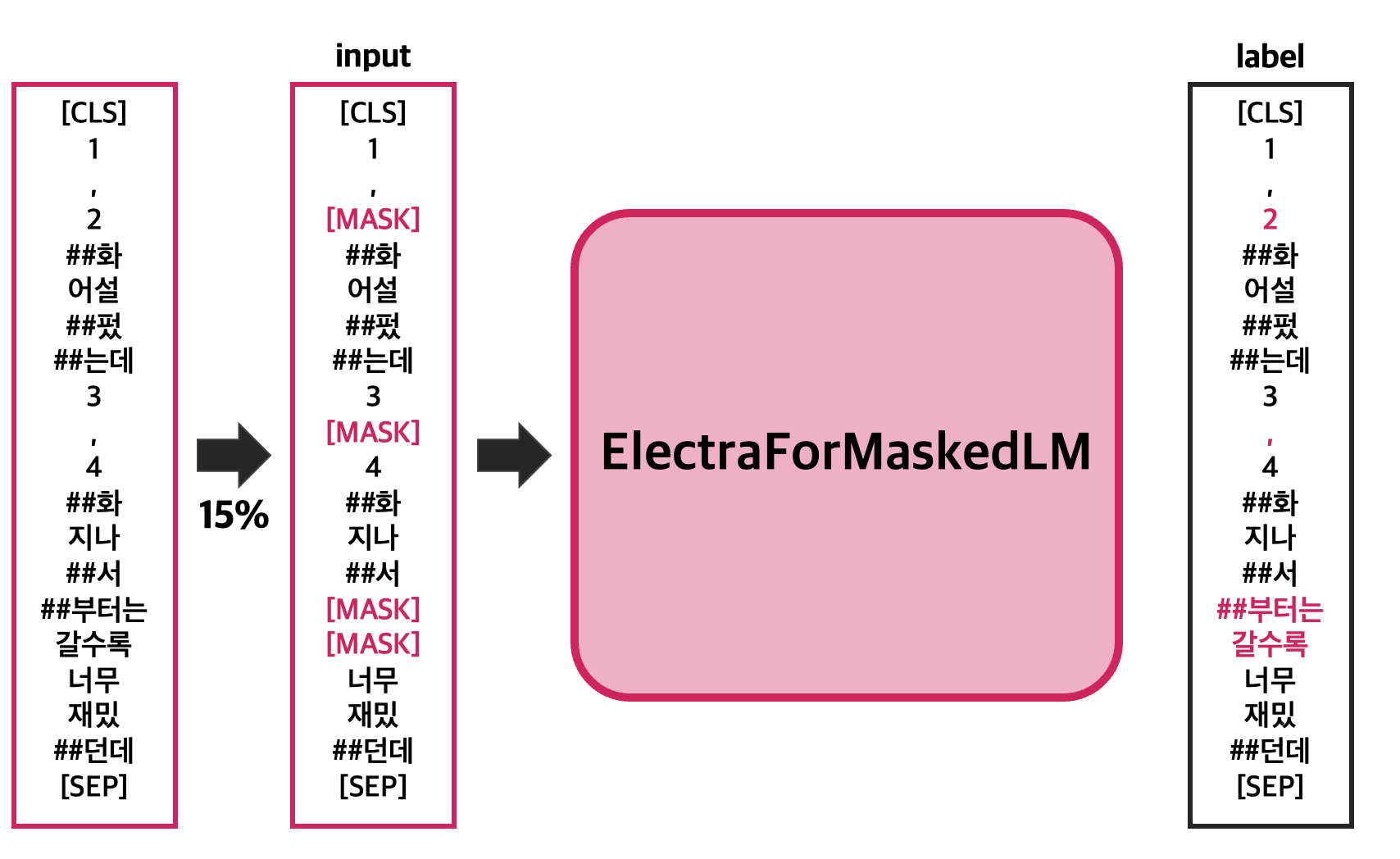
- 기존 Language model의 pre-training 단계와 동일하게 입력 토큰의 15%를 마스킹하여 학습했다.
- 선택된 마스킹 중, 80%는 [MASK]로 치환하고, 10%는 랜덤으로 다른 토큰으로 치환, 10%는 바꾸지 않았다.
- BERT에서의 MLM은 하나의 문장에 대해서 학습 시작부터 끝까지 동일한 위치에 마스킹을 한 상태에서 학습을 진행했지만, 실험에서는 RoBERTa의 MLM 방식처럼 매 이터레이션에서 새로운 위치에 마스킹을 진행했다(dynamic masking 적용).
- 마스킹 방식은
huggingface/transformers/data/data_collator의 코드 활용(https://github.com/huggingface/transformers/blob/v4.21.3/src/transformers/data/data_collator.py#L748)
- 마스킹 방식은
- 기존 Language model의 pre-training 단계와 동일하게 입력 토큰의 15%를 마스킹하여 학습했다.
- 학습 시에 사용한 하이퍼파라미터는 아래와 같다.
{"scheduler_name": "linear", "max_stop_number": 5, "train_batch_size": 128, "eval_batch_size": 128, "max_seq_len": 100, "learning_rate": 0.0002, "num_train_epochs": 30, "weight_decay": 0.01, "eps": 1e-06}
- 많은 데이터를 빠르게 학습하기 위해서 deepspeed ZeRO 적용.
- deepspeed ZeRO에 대해서는 다음 포스팅에서 자세히 기록하도록 한다.
✔️ 증강 테스트
- 현재 max_epoch로 설정했던 30까지 모두 마쳤지만, 아직 수렴을 다 마치지 못 하고 계속해서 loss가 줄고 있는 모습을 보여서 추가적인 학습이 필요한 상황이다.
- 최적의 모델은 아닐 것이지만, 우선적으로 이 방법을 활용할 수 있을 것인지 확인을 위해서 몇 가지 문장(Korean hate speech dataset의 unlabeled data)에 증강을 적용해보았다.
- 인퍼런스 단계에서는 다른 토큰으로 치환하지 않고, [MASK]로 치환만 적용했다.
- 후보 선택 조건
- 마스킹 토큰이 기호가 아니었으면, 생성 토큰도 기호가 아니어야 한다.
- 앞뒤에 중복된 토큰이 있는 후보는 제외한다.(동일한 토큰의 반복)
증강 예시 1

증강 예시 2

증강 예시 3

증강 예시 4

증강 예시 5

결론
- 몇 가지 문장에 대해서 증강을 적용한 결과, 생각보다 꽤 괜찮은 결과가 생성된다!🎉
- 이전 문장에서 크게 벗어나지 않고, 비슷한 의미를 가져가면서 bad/clean의 의도가 달라지지 않았다.
- 증강 예시5를 보면, 띄어쓰기가 없어서 토크나이징이 제대로 되지 않는 문장도 후보 선택 조건을 지켰을 때는 퀄리티가 괜찮다고 생각이 된다.
- 형태소나 어절 단위로 마스킹을 한 것이 아니기 때문에 토큰의 뜻이 이상해지는 경우가 일부 생기지만(반성하고 -> 양성있게), 전체적인 문장의 의도가 달라지는 것은 아니기 때문에 일종의 노이즈라고 생각할 수 있을 것 같다.

ML Engineer @Wrtn Technologies Inc.