
지난 시간에 "해당 발언이 어떤 유형인가"보다는 "해당 발언이 혐오 표현인가 아닌가"를 판단하는 것이 더 중요한 문제이기 때문에 방향성을 바꾸기로 했다. 기존 hate, offensive, none 레이블 대신에 binary classification 문제(bad, clean)로 변경하여 데이터셋을 새롭게 구성하고, 새 데이터셋을 사용했을 때 모델의 성능 비교를 진행해보았다.
데이터셋 구성
Korean Hate Speech Dataset을 봤을 때, bias class는 특정 사회적 편견이 포함되어 있는 문장이기는 하지만 사용성을 생각했ㅇ르 때, 혐오 표현으로 분류하기엔 어려운 문장도 존재한다고 생각이 들었다. 이러한 문장까지 혐오 표현으로 분류하여 사용자의 입력을 막았을 때는 유저의 사용성을 해칠 수 있다고(유저의 반발심?) 판단하여 bias class는 제외하고 데이터셋을 구성하였다.
** bias class의 예시 **
그나이에 요감하고 멋지세요~
그래도 남자로서 부럽네...잘생겨서 항상 인기 많은듯
여자 연예인들은 참 힘들겠다 ㅠㅠKorean Hate Speech Dataset + Korean Unsmile Dataset
- Korean hate speech dataset은 테스트셋의 레이블이 공개되어 있지 않고, Unsmile dataset은 별도의 테스트셋이 존재하지 않기 때문에 train + valid(dev) set으로 데이터셋을 구성
- 두 데이터셋의 학습셋을 합친 후에 랜덤으로 9:1로 나누어 새로운 train/dev set으로 사용했으며, 기존 데이터의 valid(dev) 셋을 합쳐서 test set으로 사용

후보 모델
데이터셋을 바꾼 후에도 후보 모델은 이전 실험과 거의 동일하게 사용하였다.
- reference (https://velog.io/@howay96/Korean-Hate-Speech-Detection)
- 저번 실험에서는 직접 구현하지 않았지만, 이번 실험에서는 블로그 글을 참고하여 최대한 같은 셋팅으로 모델을 튜닝하였다.
- LSTM (2 stack BiLSTM + dropout + linear layer)
- CNN ver1(https://aclanthology.org/2020.semeval-1.271.pdf)
- CNN ver2(https://arxiv.org/pdf/1910.12574.pdf)
- https://github.com/JminJ/Bad_text_classifier
- 직접 구현하지 않고, huggingface hub에서 모델을 다운 받아서 성능 측정을 진행했다.
- Korean Hate Speech Dataset(only clean sentence) + Korean Unsmile Dataset
- binary classification
- 일부 clean 문장을 다시 레이블링하여 bad로 변경
- 모델 자체의 구조는 변경하지 않았고 Huggingface의 ElectraForSequenceClassification 구조를 그대로 사용
- focal loss 사용
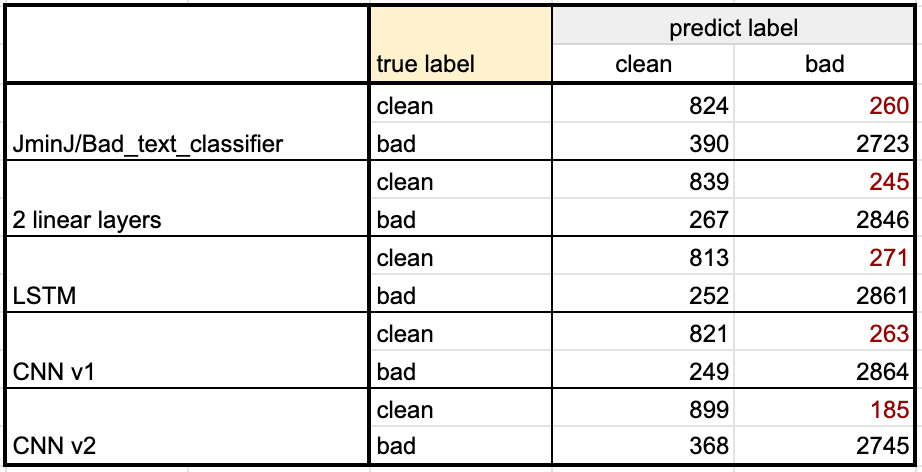
모델 별 성능
- 전체적인 정확률과 f1-score(macro)를 봤을 때는 2 linear layers 모델이 가장 높은 성능을 보였다.
- 전체 precision과 recall은 각각 CNN v1 모델, CNN v2 모델이 가장 높은 성능을 보임


🤔 결과에 대한 생각
현재 튜닝한 모델들의 테스트 데이터에 대한 성능 자체는 높을 수 있지만, 실제 상황에서의 활용도는 떨어질 수 있을 것이라는 생각이 들었다. 아래와 같은 실제 상황에 대한 가정을 고려하여 해소해야할 문제를 생각해봤다.
- 문제가 없는 유저의 입력을 막을 경우에 나쁜 경험을 부여할 것
- 실제 상황에서는 bad보다 일반적인 문장(clean)이 입력될 경우가 더 많을 것
위와 같은 상황에 따라서 두 가지를 고려해야 할 것.
1️⃣ 레이블 불균형 문제 해소
- 현재 데이터셋은 레이블 불균형 문제가 존재.(clean : bad = 3 : 7) 이러한 데이터로 학습을 한 모델은 새로운 입력이 들어왔을 때, 비율이 더 높은 bad sentence로 분류할 확률이 높을 수 있다.
- 불균형 해소를 위해서 아래와 같은 방법을 적용 해볼 수 있을 것.
-
clean 문장 추가
추가하는 문장의 경우에 일관성을 위해서 랜덤한 문장이 아닌, 기존 데이터셋과 비슷하게 유저가 직접 작성한 문장이 할 것 → NSMC(Naver Sentiment Movie Corpus)의 긍정 평가 문장을 활용?
-
전체 레이블을 모두 이용하여 트레이닝 후 레이블 치환
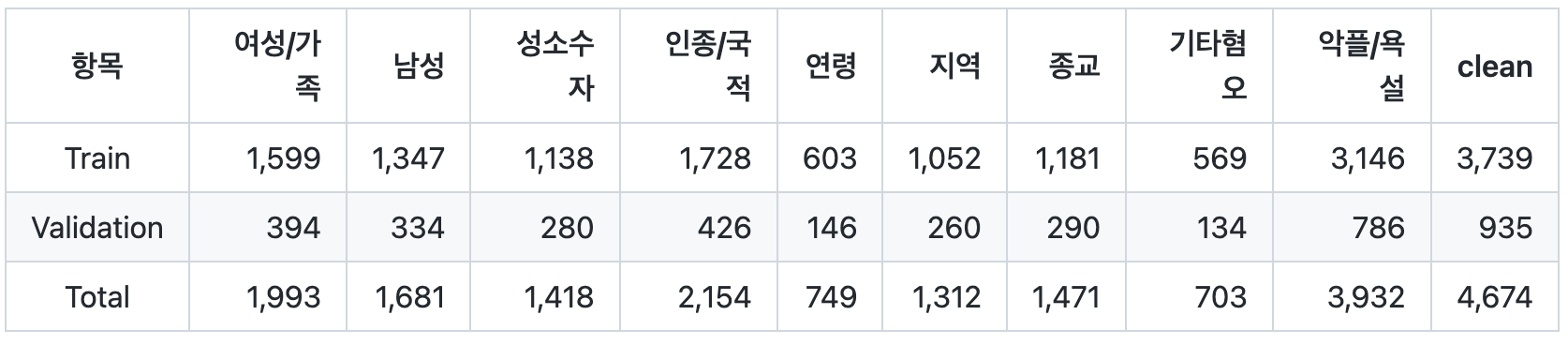
데이터셋을 봤을 때, bad와 clean 레이블은 매우 불균형하지만, 모든 레이블에 대한 비율을 봤을 때는 비교적 균형적인 비율로 구성되어 있음. 이를 활용하여 전체 레이블에 대해서 모델을 학습한 후에 인퍼런스 단계에서 binary label로 치환하여 사용할 수 있을 것. (NER 모델을 개발할 당시에 BIT label을 활용했던 것을 바탕으로 한 아이디어)
-
불균형 데이터를 위한 알고리즘 적용
- 샘플링 방식 적용 - SMOTE(over sampling)
- loss function - weighted cross entropy, focal loss
-
2️⃣ 모델 선택 방식
- 실제 상황에 대한 가정에 따라서 모델을 선택할 때, 전체 데이터에 대한 성능보다는 다른 기준을 잡아서 best model을 선택하는 것이 좋을 것.
- 전체적인 f1이나 recall을 조금 희생하더라도 1(bad sentence)에 대한 precision이 가장 중요하게 봐야 하는 요인이라고 생각됨. (성능 평가 결과의 빨간 글씨 부분)
- 이 기준을 이용하여 모델을 선택한다면 CNN v2가 가장 적합
다음 시간에는 위에서 세웠던 기준과 보완 방법을 바탕으로 현재 트레이닝한 모델이 목적에 부합하는지 평가하고, 부족한 면을 보완할 수 있는 아이디어들을 추가하여 성능 향상을 위한 실험을 진행할 예정!
