[2021.09.28] Object Detection Library

💡 MMDetection & Detectron2
| MMDetection | Detectron2 | |
|---|---|---|
| 공통점 | 전체 프레임워크를 모듈 단위 분리 | |
| 특징 | - 많은 프레임워크 지원 - 속도 빠름 | - OD 외에도 Segmentation, Pose prediction 등 알고리즘 지원 |
| 지원 모델 | - Fast R-CNN - SSD - YOLO v3 - DETR - ... | - Faster R-CNN - RetinaNet - Mask R-CNN - DETR - ... |
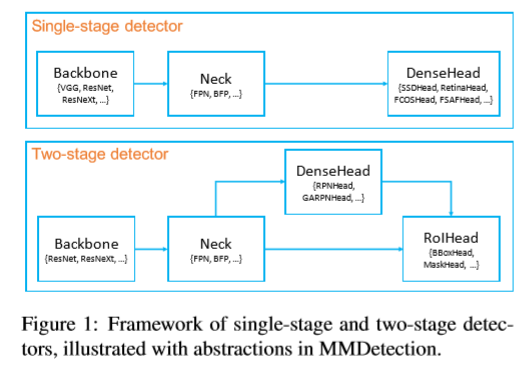
MMDetection
- Pytorch 기반의 obeject detection 오픈소스 라이브러리
- 상당히 많은 모델 지원
- 최근 paper에서 baseline으로 사용
- 단점: library에 대한 완벽한 이해 필요
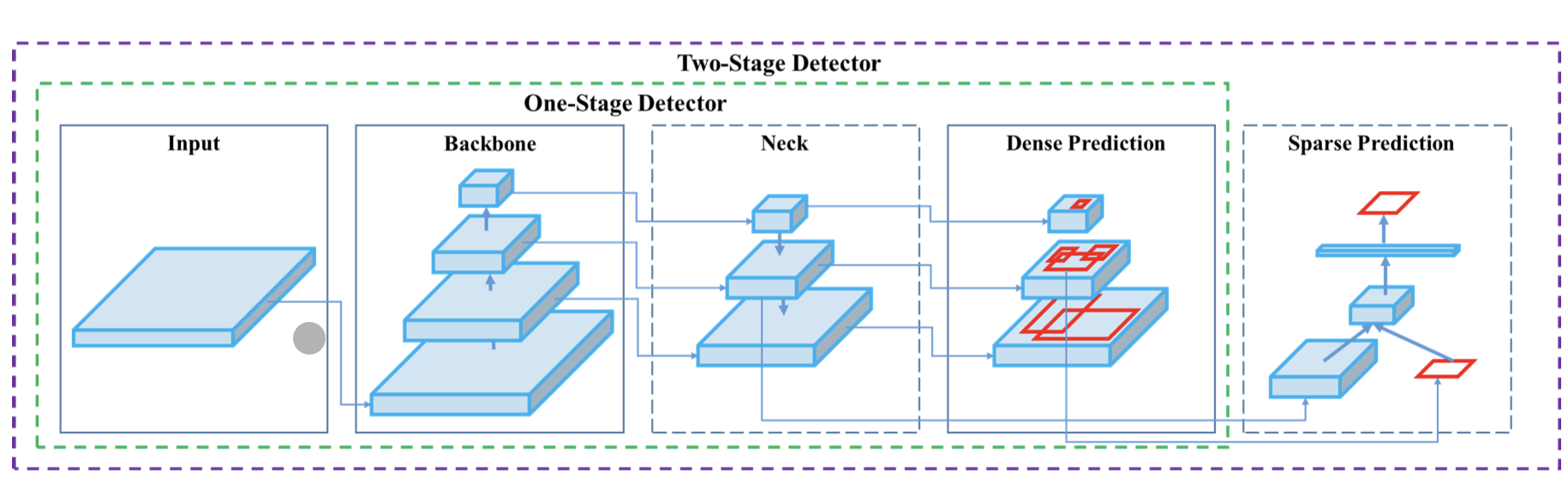
2 stage model
- Backbone / Neck / DenseHead / RoIHead
- 각각의 모듈 단위로 커스터마이징
- Config 파일로 통제
- Backbone: 입력 이미지 -> feature map
- Neck: backbone & head 연결. Feature map 재구성 (ex. FPN)
- DenseHead: Feature map의 dense location (localization)
- RoIHead: RoI --> box 분류 & 좌표 regression 예측
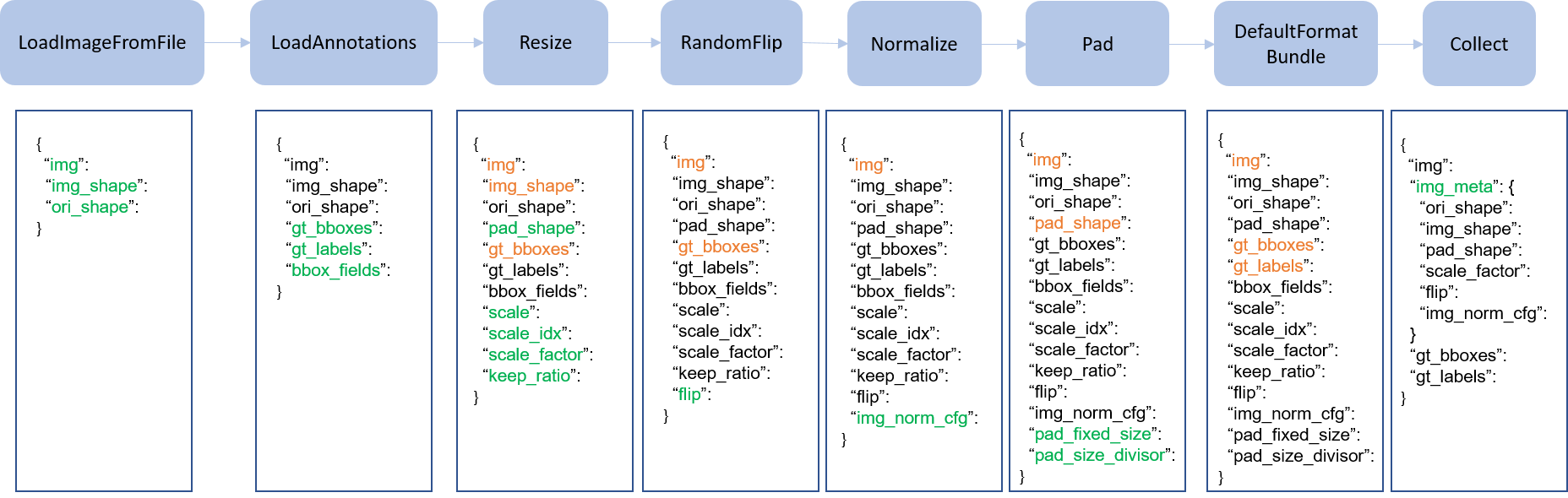
Pipeline 미리보기
- Library & Module import
from mmcv import Config
from mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet.apis import train_detector
from mmdet.datasets import (build_dataloader, build_dataset,
replace_ImageToTensor)- Config file 불러오기
cfg = Config.fromfile('./configs/yolox/yolox_x_8x8_300e_coco.py')- Config file 수정
cfg.data.samples_per_gpu = 4
cfg.model.roi_head.bbox_head.num_classes = 10
cfg.seed = 2021
cfg.gpu_ids = [0]
cfg.work_dir = './work_dirs/faster_rcnn_r50_fpn_1x_trash'
cfg.optimizer_config.grad_clip = dict(max_norm=35, norm_type=2)
cfg.checkpoint_config = dict(max_keep_ckpts=3, interval=1)- 모델, 데이터셋 build
model = build_detector(cfg.model)
datasets = [build_dataset(cfg.data.train)]- 학습
train_detector(model, datasets[0], cfg, distributed=False, validate=False)Config File
- Configs --> Dataset, Model, Scheduler, Optimizer 정의
- Configs에 다양한 object detection 모델들의 config 파일들 정의
- configs/base/ 폴더에 기본 config 파일 존재
- dataset, model, schedule, default_runtime
- 각각의 base/ 폴더에 여러 버전 config 담겨있음
- Dataset - COCO, VOC, Cityscape 등
- Model - faster_rcnn, retinanet, rpn 등
- 틀 갖춰진 config 상속 받고 필요한 부분만 수정
Dataset
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))- Data pipeline
Model
model = dict(
type=...
)- Type: 모델 유형 (ex. FasterRCNN, RetinaNet, ...)
type='FasterRCNN',- Backbone: Input -> feature map (ex. ResNet, ResNext, HRNet, ...)
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),- Neck
- Backbone & head 연결
- Feature map 재구성
- ex. FPN, NAS_FPN, PAFPN, ...
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),- RPN_head
- Region Proposal Network
- RPNHead, Anchor_Free_Head, ...
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),- RoI head
- Region of Interest
- StandardRoIHead, CascadeRoIHead, ...
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),사용 가능한 model
__all__ = [
'RegNet', 'ResNet', 'ResNetV1d', 'ResNeXt', 'SSDVGG', 'HRNet',
'MobileNetV2', 'Res2Net', 'HourglassNet', 'DetectoRS_ResNet',
'DetectoRS_ResNeXt', 'Darknet', 'ResNeSt', 'TridentResNet', 'CSPDarknet',
'SwinTransformer', 'PyramidVisionTransformer', 'PyramidVisionTransformerV2'
]Custom backbone 모델 등록
- 새로운 backbone 등록
import torch.nn as nn
from ..builder import BACKBONES
@BACKBONES.register_module()
class MobileNet(nn.Module):
def __init__(self, arg1, arg2):
pass
def forward(self, x):
pass- Module import
from .mobilenet import MobileNet- 등록한 backbone 사용
backbone = dict(
type='MobileNet',
arg1=...
)Runtime settings
- Optimizer: ex. SGD, Adam, ...
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)- Training schedules: learning rate, runner
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)Detectron2
- Facebook AI Research의 Pytorch 기반 라이브러리
- Object detection 외 Segmentation, Pose prediction 등 제공
Pipeline

- Library & module import
import os
import copy
import torch
import detectron2
from detectron2.data import detection_utils as utils
from detectron2.utils.logger import setup_logger
setup_logger()
from detectron2 import model_zoo
from detectron2.config import get_cfg
from detectron2.engine import DefaultTrainer
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data.datasets import register_coco_instances
from detectron2.evaluation import COCOEvaluator
from detectron2.data import build_detection_test_loader, build_detection_train_loader- Dataset
register_coco_instances('coco_trash_train', {}, '../dataset/train.json', '../dataset/')
register_coco_instances('coco_trash_test', {}, '../dataset/test.json', '../dataset/')- Config 파일 불러오기
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file('COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml'))- Config 수정
cfg.DATASETS.TRAIN = ('coco_trash_train',)
cfg.DATASETS.TEST = ('coco_trash_test',)
cfg.DATALOADER.NUM_WOREKRS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url('COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml')
cfg.SOLVER.IMS_PER_BATCH = 4
cfg.SOLVER.BASE_LR = 0.001
cfg.SOLVER.MAX_ITER = 15000
cfg.SOLVER.STEPS = (8000,12000)
cfg.SOLVER.GAMMA = 0.005
cfg.SOLVER.CHECKPOINT_PERIOD = 3000
cfg.OUTPUT_DIR = './output'
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 10
cfg.TEST.EVAL_PERIOD = 3000- Augmentation mapper 정의
def MyMapper(dataset_dict):
dataset_dict = copy.deepcopy(dataset_dict)
image = utils.read_image(dataset_dict['file_name'], format='BGR')
transform_list = [
T.RandomFlip(prob=0.5, horizontal=False, vertical=True),
T.RandomBrightness(0.8, 1.8),
T.RandomContrast(0.6, 1.3)
]
image, transforms = T.apply_transform_gens(transform_list, image)
dataset_dict['image'] = torch.as_tensor(image.transpose(2,0,1).astype('float32'))
annos = [
utils.transform_instance_annotations(obj, transforms, image.shape[:2])
for obj in dataset_dict.pop('annotations')
if obj.get('iscrowd', 0) == 0
]
instances = utils.annotations_to_instances(annos, image.shape[:2])
dataset_dict['instances'] = utils.filter_empty_instances(instances)
return dataset_dict- Trainer 정의
class MyTrainer(DefaultTrainer):
@classmethod
def build_train_loader(cls, cfg, sampler=None):
return build_detection_train_loader(
cfg, mapper = MyMapper, sampler = sampler
)
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
if output_folder is None:
os.makedirs('./output_eval', exist_ok = True)
output_folder = './output_eval'
return COCOEvaluator(dataset_name, cfg, False, output_folder)- 학습
os.makedirs(cfg.OUTPUT_DIR, exist_ok = True)
trainer = MyTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()Config File
구조
- Config 파일 수정
_BASE_: "../Base-RCNN-FPN.yaml"
MODEL:
WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl"
MASK_ON: False
RESNETS:
DEPTH: 101
SOLVER:
STEPS: (210000, 250000)
MAX_ITER: 270000불러오기
- Default config 불러온 후, yaml 형식의 config 파일 채움
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file('COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml'))Dataset
Config
- Dataset, dataloader
- TRAIN, TEST에 각각 등록한 train/test 데이터셋의 이름 입력
# -----------------------------------------------------------------------------
# Dataset
# -----------------------------------------------------------------------------
_C.DATASETS = CN()
# List of the dataset names for training. Must be registered in DatasetCatalog
# Samples from these datasets will be merged and used as one dataset.
_C.DATASETS.TRAIN = ()
# List of the pre-computed proposal files for training, which must be consistent
# with datasets listed in DATASETS.TRAIN.
_C.DATASETS.PROPOSAL_FILES_TRAIN = ()
# Number of top scoring precomputed proposals to keep for training
_C.DATASETS.PRECOMPUTED_PROPOSAL_TOPK_TRAIN = 2000
# List of the dataset names for testing. Must be registered in DatasetCatalog
_C.DATASETS.TEST = ()
# List of the pre-computed proposal files for test, which must be consistent
# with datasets listed in DATASETS.TEST.
_C.DATASETS.PROPOSAL_FILES_TEST = ()
# Number of top scoring precomputed proposals to keep for test
_C.DATASETS.PRECOMPUTED_PROPOSAL_TOPK_TEST = 1000
# -----------------------------------------------------------------------------
# DataLoader
# -----------------------------------------------------------------------------
_C.DATALOADER = CN()
# Number of data loading threads
_C.DATALOADER.NUM_WORKERS = 4
# If True, each batch should contain only images for which the aspect ratio
# is compatible. This groups portrait images together, and landscape images
# are not batched with portrait images.
_C.DATALOADER.ASPECT_RATIO_GROUPING = True
# Options: TrainingSampler, RepeatFactorTrainingSampler
_C.DATALOADER.SAMPLER_TRAIN = "TrainingSampler"
# Repeat threshold for RepeatFactorTrainingSampler
_C.DATALOADER.REPEAT_THRESHOLD = 0.0
# Tf True, when working on datasets that have instance annotations, the
# training dataloader will filter out images without associated annotations
_C.DATALOADER.FILTER_EMPTY_ANNOTATIONS = TrueDataset 등록
- Custom dataset 사용시 dataset 등록
- (Option) 전체 dataset이 공유하는 정보를 메타 데이터로 등록 가능
register_coco_instances('coco_trash_train', {}, '../dataset/train.json', '../dataset/')
register_coco_instances('coco_trash_val', {}, '../dataset/val.json', '../dataset/')
# Set Metadata
classes = ["General trash", "Paper", "Paper pack", "Metal", "Glass", "Plastic", "Styrofoam", "Plastic bag", "Battery", "Clothing"]
MetadataCatalog.get('coco_trash_train').set(thing_classes=classes)
MetadataCatalog.get('coco_trash_val').set(thing_classes=classes)- Config 파일에 train dataset & test(val) dataset을 명시
cfg.DATASETS.TRAIN = ("coco_trash_train", )
cfg.DATASETS.TEST = ("coco_trash_val", )Data augmentation
class MyTrainer(DefaultTrainer):
@classmethod
def build_train_loader(cls, cfg, sampler=None):
return build_detection_train_loader(
cfg, mapper=MyMapper, sampler=sampler
)Model
Config
- BACKBONE: input -> feature map (ex. ResNet, RegNet, ...)
# ---------------------------------------------------------------------------- #
# Backbone options
# ---------------------------------------------------------------------------- #
_C.MODEL.BACKBONE = CN()
_C.MODEL.BACKBONE.NAME = "build_resnet_backbone"
# Freeze the first several stages so they are not trained.
# There are 5 stages in ResNet. The first is a convolution, and the following
# stages are each group of residual blocks.
_C.MODEL.BACKBONE.FREEZE_AT = 2- FPN: backbone과 head 연결, Feature map 재구성
# ---------------------------------------------------------------------------- #
# FPN options
# ---------------------------------------------------------------------------- #
_C.MODEL.FPN = CN()
# Names of the input feature maps to be used by FPN
# They must have contiguous power of 2 strides
# e.g., ["res2", "res3", "res4", "res5"]
_C.MODEL.FPN.IN_FEATURES = []
_C.MODEL.FPN.OUT_CHANNELS = 256
# Options: "" (no norm), "GN"
_C.MODEL.FPN.NORM = ""
# Types for fusing the FPN top-down and lateral features. Can be either "sum" or "avg"
_C.MODEL.FPN.FUSE_TYPE = "sum"- Anchor Generator
- RPN
- ROI_HEADS
_C.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.05
# Overlap threshold used for non-maximum suppression (suppress boxes with
# IoU >= this threshold)
_C.MODEL.ROI_HEADS.NMS_THRESH_TEST = 0.5
# If True, augment proposals with ground-truth boxes before sampling proposals to
# train ROI heads.
_C.MODEL.ROI_HEADS.PROPOSAL_APPEND_GT = True- ROI_BOX_HEAD
Custom backbone 모델 등록
- 새로운 backbone 등록
from detectron2.modeling import BACKBONE_REGISTRY, Backbone, ShapeSpec
@BACKBONE_REGISTRY.register()
class ToyBackbone(Backbone):
def __init__(self, cfg, input_shape):
super().__init__()
# create backbone
self.conv1 = nn.Conv2d(3, 64, kernel_size=2, stride=16, padding=3)
def forward(self, image):
return {"conv1": self.conv1(image)}
def output_shape(self):
return {"conv1": ShapeSpec(channels=64, stride=16)}- 등록한 backbone 사용
cfg = ... # read a config
cfg.MODEL.BACKBONE.NAME = 'ToyBackbone' # OR set it in config
model = build_model(cfg) Solver
- LR_SCHEDULER
- WEIGHT_DECAY
- CLIP_GRADIENTS
