[2021.10.05] Transformer in Object Detection

💡 Advanced Object Detection 1 Lecture
Further Dev in 2 stage Detectors
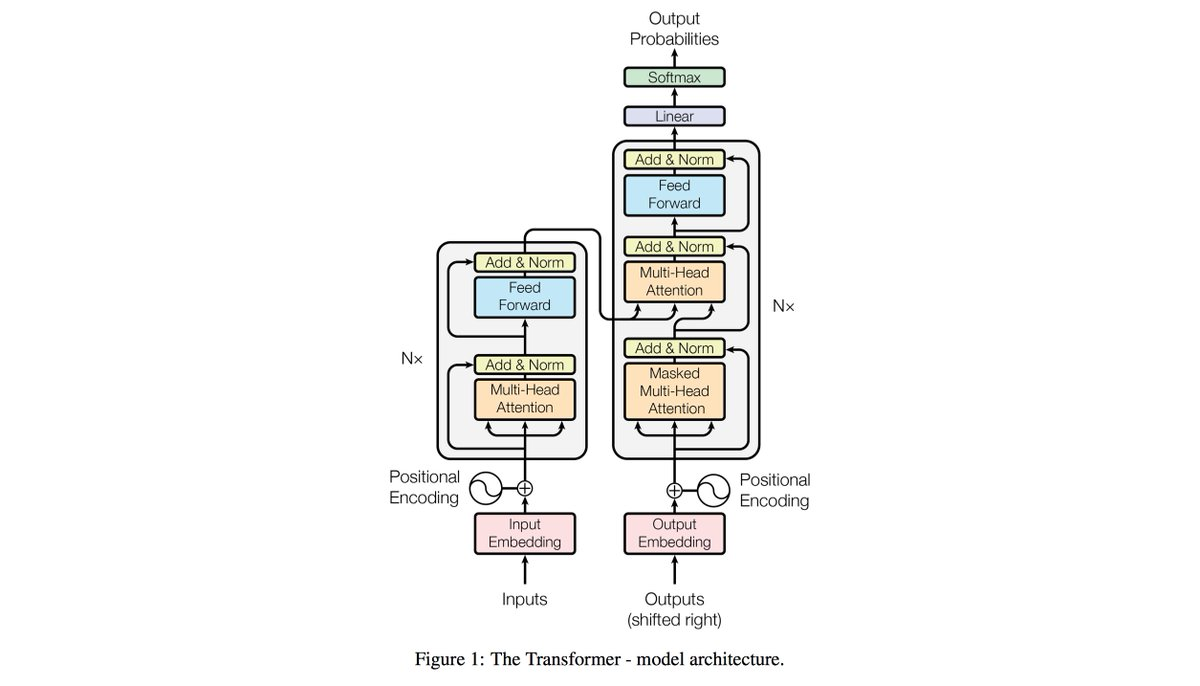
Transformer
- NLP에서 long range dependency 해결 -> vision에도 적용
Self Attention
Vision Transformer (ViT)
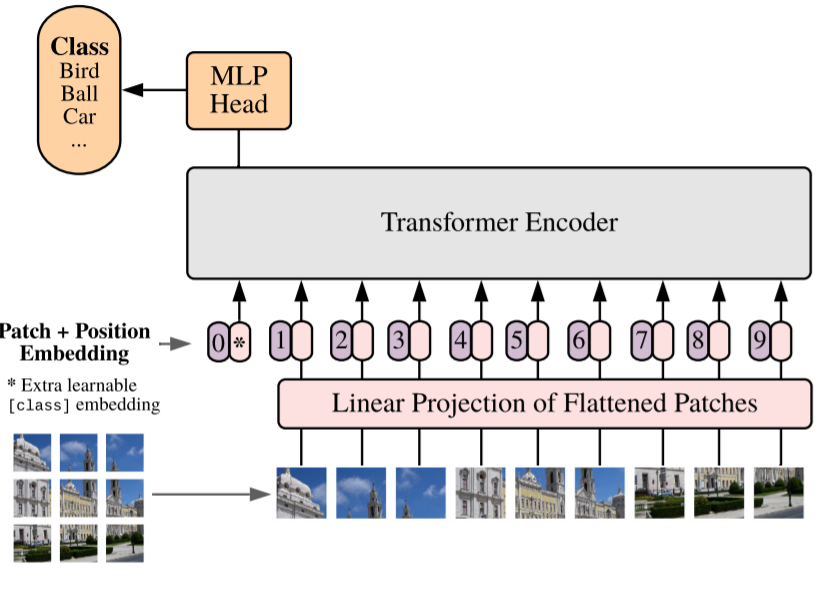
Overview
- Flatten 3D -> 2D (Patch 단위로 나눔)
- Learnable embedding 처리
- class & positional embedding 추가
- Transformer
- Predict
End-to-End Object Detection with Transformer
Contribution
- Transformer를 처음으로 Object Detection에 적용
- 기존의 Object Detection의 hand-crafted post process 단계를 transformer로 없앰
Architecture

- CNN backbone -> Transformer(Encoder-Decoder) -> Prediction Heads
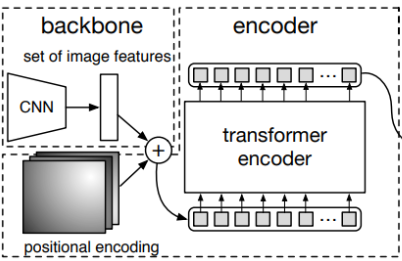
- Highest level feature map만 사용 (많은 연산량)
- Flatten 2D
- Positional embedding
- Encoder
- 224 x 224 input
- 7x7 feature map size
- 49개의 feature vector -> encoder input (7x7 flatten해서 사용)
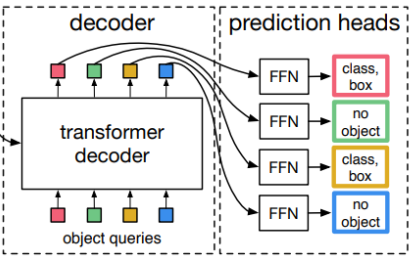
- Decoder
- Feed Forward Network (FFN)
- N개(>한 이미지에 존재하는 object 개수)의 output
Train
- Ground-truth에서 부족한 object 개수만큼 no object로 padding 처리
- Ground-truth, prediction N:N mapping
- 각 예측 값이 N개 unique - post-process 필요X
Swin Transformer
ViT의 문제점
- 많은 양의 데이터 필요
- Computational cost 큼
- Backbone으로 사용하기 어려움
해결법
- CNN과 유사한 구조로 설계
- Window -> cost 감소
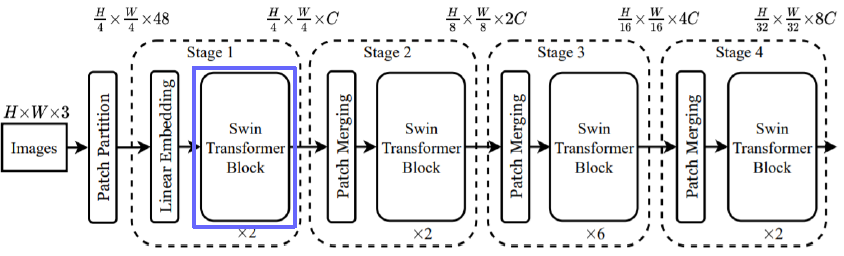
Architecture
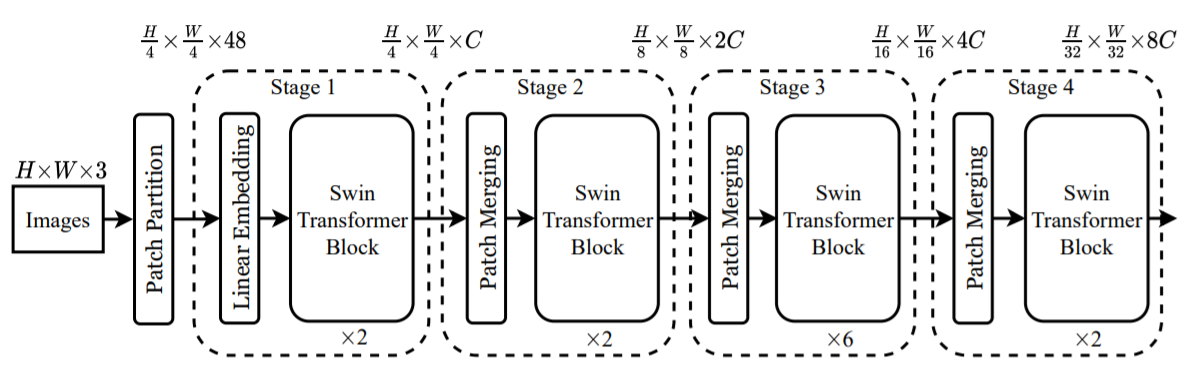
- Patch Partitioning
- Linear Embedding
- Swin Transformer Block
- Window Multi-head Attention
- Patch Merging
Patch Partition
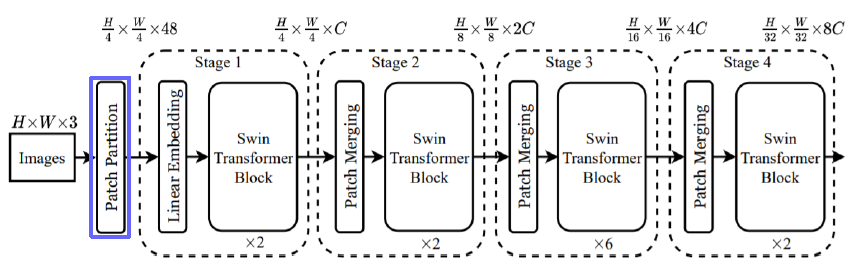
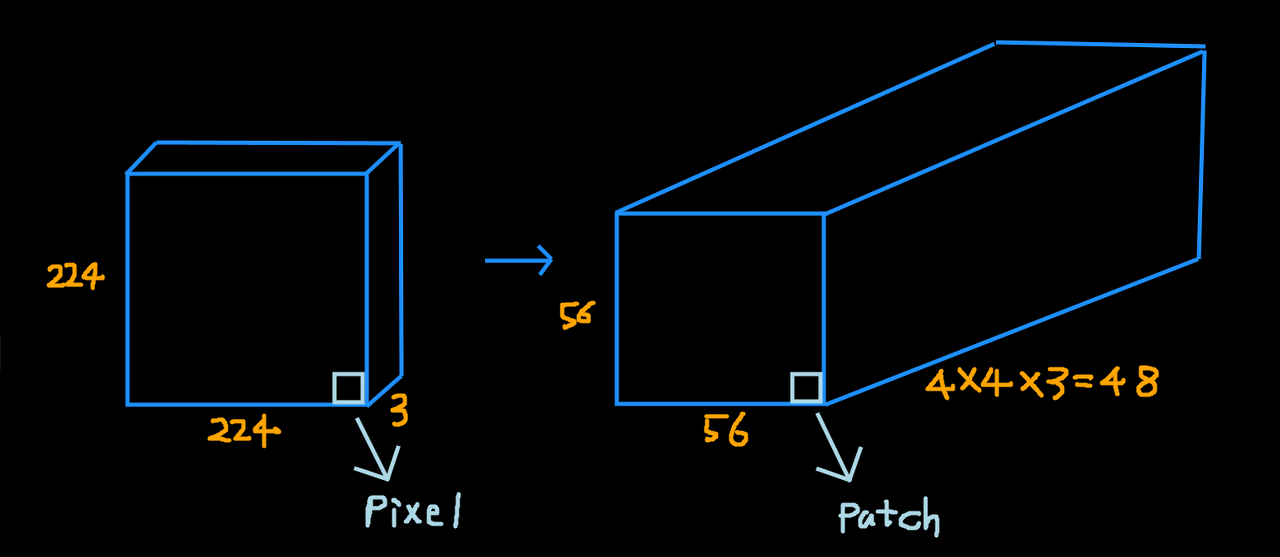
Linear Embedding
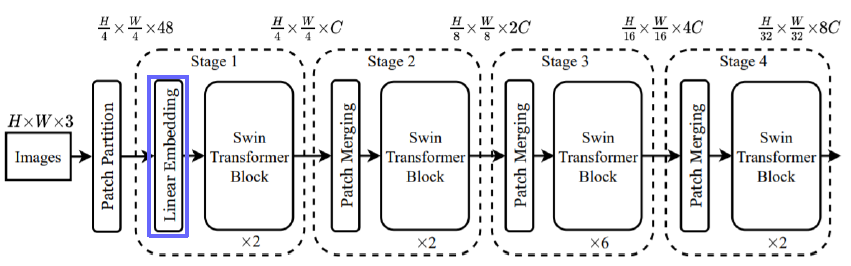
- ViT와 Embedding 방식 동일
- ViT에서 class embedding 제거
Swin Transformer Block
- Attention 2번 통과
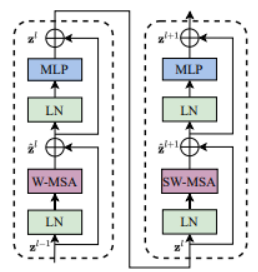
Window Multi-Head Attention (W-MSA)

- Window 단위로 embedding 나눔
- Window 안에서만 transformer 수행
- Window 크기에 따라 computational cost 조절 가능
- Window 내 수행 -> receptive field 제한
Shifted Window Multi-Head Attention (SW-MSA)

- Receptive field 제한하는 단점 해결하기 위해 transformer block 2번째 layer에서 수행
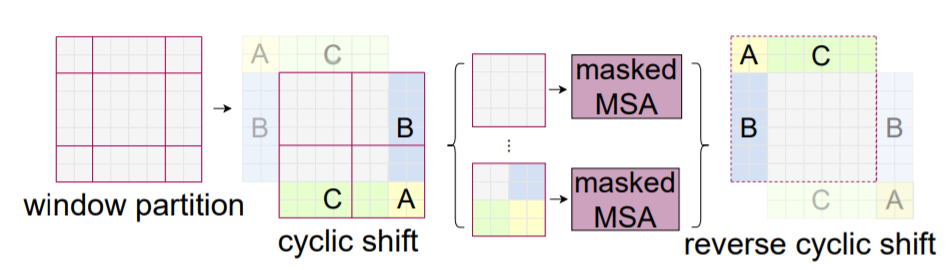
- 남는 부분들 (A, B, C)를 옮김
- 남는 부분들을 masking 처리 -> self-attention 연산 X
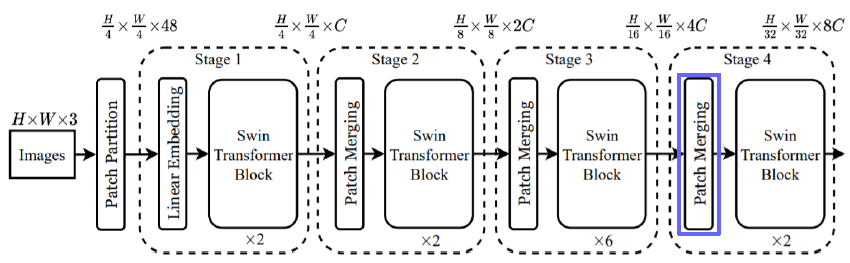
Patch Merging
Summary
- 적은 Data로 학습 가능
- Window 단위 -> computation cost 줄임
- CNN과 비슷한 구조 -> Backbone으로 활용 가능
