
머신러닝 입문중의 입문 캐글 타이타닉 자료로 판다스를 다뤄보고자 한다.
https://www.kaggle.com/c/titanic/data 에서 데이터셋을 다운받을 수 있다.
오늘은 여기서 train.csv만 다루고자 한다.
나머지 데이터들은 이를 이용하여 머신러닝을 할 때 사용하면 된다.
import pandas as pd📁파일 불러오기
titanic_df = pd.read_csv('./titanic_train.csv')read_csv(file_path)를 이용해 csv파일을 읽어올 수 있다.
데이터타입을 찍어보면 다음과 같다.
type(titanic_df)pandas.core.frame.DataFrame
상위 N행 살펴보기
titanic.head()데이터 프레임의 최상단 5개의 데이터를 확인할 수 있다. 비슷하게 tail()은 마지막 데이터 5개를 불러온다.
데이터프레임 칼럼 파악
titanic_df.columnsIndex(['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')
칼럼들의 이름을 파악할 수 있다.
(행, 열) 크기 파악
titanic_df.shape(891, 12)
주어진 데이터는 891행에 12열로 구성된 데이터프레임 인것을 확인할 수 있다.
데이터프레임 정보 파악
titanic_df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB
데이터프레임에 대한 전반적인 정보를 확인할 수 있다.
확인해보면 전체 행의 길이는 891인데 Age, Cabin, Embarked의 개수는 891개가 되지 않는 것을 확인할 수 있다. 결손값이 있다는 것!
결손값 확인
titanic_df.isnull().sum()PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64
isnull()과 sum()을 함께 쓰면 각 칼럼별 결손값의 개수를 알 수 있다.
isnull()을 단독으로 쓰면 각 원소별로 null값인지 아닌지 boolean형태로 출력된다.
요약 통계량 확인
titanic_df.describe()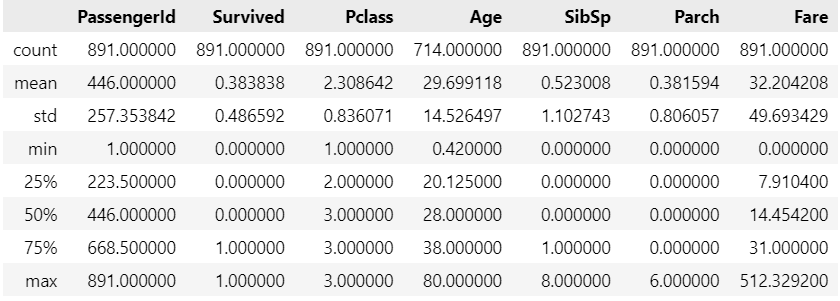
데이터의 컬럼별 요약 통계량을 확인할 수 있다. 또한 mean(), max(), median() 등 개별 함수를 사용하여 통계량을 계산할 수도 있다.
그룹별로 집계하기
titanic_df.groupby('Sex').sum()['Survived']Sex female 233 male 109 Name: Survived, dtype: int64
groupby()를 사용하여 특정 칼럼의 정보만 얻을 수 있다. 해당 코드는 성별 생존자수를 구하기 위해 집계함수 sum()도 같이 사용해줬다.
결손값 채우기
전체 칼럼에 대해서 결손값을 채우고 싶다면 titanic_df.fillna(대체하고싶은 값)을 사용하면 되지만, 타이타닉 자료에서 결손값이 있는 칼럼이 요구하는 값들이 다르기 때문에 특정 칼럼에서 결손값을 채워보고자 한다.
1. Age칼럼 - 평균으로 채우기
특정 칼럼의 결손값을 채우고 싶으면 다음과 같이 코드를 작성하면 된다.
titanic_df['Age'].fillna(titanic_df['Age'].mean(), inplace=True)inplace는 변경 값을 저장할 때 True 값을 준다.
우리는 데이터프레임의 데이터를 바로 변경하고 싶으니, True옵션을 주면 된다.
쉽게 말해서 inplace=True는 바뀐 데이터가 바로 반영이 되는 것이고, inplace=False는 바뀐 데이터가 반영이 안된다는 것으로 이해를 하면 된다.
2. Cabin칼럼 - N으로 채우기
titanic_df['Cabin'].fillna('N', inplace=True)3. Embarked칼럼 - N으로 채우기
titanic_df['Embarked'].fillna('N', inplace=True)데이터프레임 함수 적용
연령대 별로 생존자를 확인하고 싶어서 연령대를 구하는 함수를 데이터프레임에 적용하고자 한다.
def change_age(age):
age = int(age)
if age >= 70:
return '노인'
elif age >= 10:
return str(age//10) + '0대'
else:
return '유아'위와 같은 함수를 데이터프레임에 적용하려면 apply()를 사용해주면 된다.
titanic_df['AgeRange'] = titanic_df['Age'].apply(change_age)함수를 넣어줘도 되고 람다식을 이용해줘도 된다.
위와 같이 코드를 작성하면 새로운 칼럼 AgeRange에 연령대가 저장되게 된다.
연령대별 생존여부를 확인하고 싶으면 아래와 같이 코드를 작성하면 된다.
titanic_df.groupby('AgeRange').sum()['Survived']AgeRange 10대 41 20대 129 30대 73 40대 34 50대 20 60대 6 노인 1 유아 38 Name: Survived, dtype: int64
오늘은 캐글의 타이타닉 train.csv를 이용하여 판다스를 다루는 방법에 대해서 정리해보았다. 판다스의 모든 메서드를 정리한 것은 아니고, 데이터를 확인하기에 용이한 것들만 정리했다.
이후에는 이를 이용하여 머신러닝을 진행한 것을 정리해서 올릴 것이다..~
