1. Overflow
Overflow 처리 : 더하기는 +1bit / 곱하기는 input bit수를 다 더해서 사용하면 어느정도 오류를 막을 수 있다(but 절대적이진 않음) 이렇게 추가 bit 사용 또는 Saturation같은 추가 Logic을 사용할 수 있다.
ex)
8bit + 8bit = 255 + 255 = 510으로 8bit + 1bit = 9bit 사용
8bit * 8bit = 255 * 255 = 65025으로 8bit + 8bit = 16bit 사용
상황에 맞게 MIN/MAX로 계산 할 것 Signed / Unsigned
MSB(Most Significant Bit) : 최상위 bit
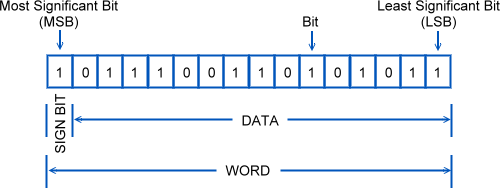
2's Complement : 2의 보수

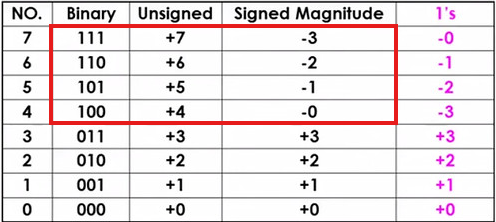
Unsigned Case
- n bit로 표현가능한 값의 범위 : 0 ~ (2^n - 1) ex) 8bit ( 0~255 )
- 부호 X(-사용 X)
Signed Case
- n bit로 표현가능한 값의 범위 : -(2^(n-1))
~ (2^(n-1))-1 - 부호 O , 0포함해서 +/-를 구분한다.
Vivado를 활용한 Unsigned-Signed (잘못된 계산) / Signed-Signed 확인

결론 : 부호를 꼭 짝이 맞게 사용할 것 (Signed-Signed /Unsigned-Unsigned)
2. Counter
Counter를 활용한 Module 설계 예시
- Memory의 원하는 address에 data를 read/write하는 메모리 컨트롤러 desgin(설계)
- Clock 속도를 변화시킬 수 있는 분 주기 Modeling
<Design과 Modeling>
Design은 하드웨어의 구체적인 구현을 목표로 하고, Modeling은 설계가 올바르게 동작하는지 검증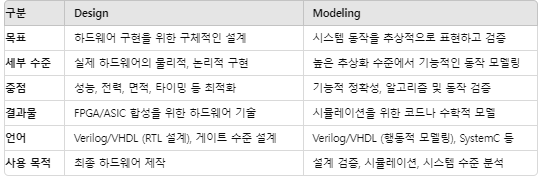
3. Pipeline : 복잡한 연산을 여러 단계로 나누어, 각 단계가 동시에 처리될 수 있도록 하는 설계 기법이다. FPGA나 ASIC 등에서 파이프라인 구조를 적용하면 복잡한 연산을 더 빠르고 효율적으로 처리할 수 있습니다.
Parallel Processing
하드웨어에서는 순차적으로 진행되는 SW와 달리 모든 논리 블록이 동시에 실행되기에 병렬 처리(Parallel Processing)에 적합하다.
Verilog에서의 병렬 처리, 여러 always 블록과 assign 문이 동시에 실행되는 동시적 특성을 가지고 있다.
<always> <assign>
always @(예시1 or 예시2) begin assign o_cnt = cnt;
assign o_cnt_always = cnt_always;
if(조건1) begin
cnt <= 0;
end else if (조건2) begin
cnt <= cnt + 1;
end
end
always @(예시1' or 예시2') begin
if(조건1') begin
cnt' <= 0;
end else if (조건2') begin
cnt' <= cnt' + 1;
end
end //이런식으로 여러가지의 always, assign문을 병렬로 처리 가능3. Pipeline
Latency (L, 시간)
하나의 입력이 처리되어 출력으로 나오는 데 걸리는 시간
4단계 파이프라인이 있다고 가정, 각 단계가 2ns씩 걸린다면, 하나의 입력이 파이프라인을 거쳐 최종 출력으로 나오는 데 걸리는 시간, 즉 latency는 총 8ns가 된다.
Stage 1: 2ns
Stage 2: 2ns
Stage 3: 2ns
Stage 4: 2ns
총 Latency = 2 + 2 + 2 + 2 = 8ns
Throughput (T, 작업량)
주어진 시간 동안 얼마나 많은 데이터를 처리할 수 있는 작업량
위의 4단계 파이프라인이 있고, 각 스테이지가 2ns, 첫 번째 데이터가 출력되기까지는 8ns가 걸리지만, 그 이후에는 매 2ns마다 새로운 결과가 나온다. 따라서, 처리량(Throughput) 은 매 2ns마다 한 번씩 결과를 출력할 수 있게 되어, 시간당 더 많은 데이터가 처리
ex) 20ns 동안 5개의 데이터를 처리할 수 있다면, 처리량은 5 데이터/20ns
Troughput과 Latency 개념 및 Pipeline 설계 방법에 대한 이해
Pipeline에대한 이해 돕기 자료, 시간없으면 중간 부분부터
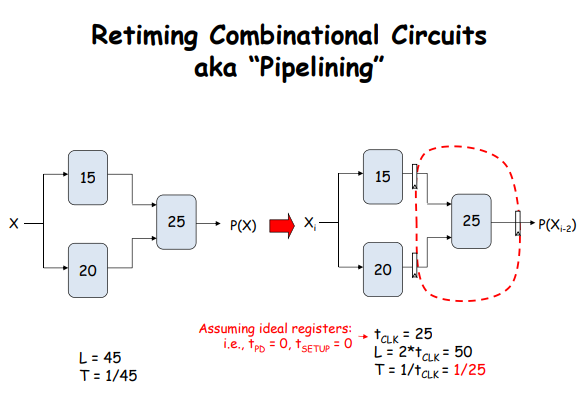
작업량(Throughput)은 Clock 주기(최대 지연 시간)에 반비례 한다!
아래 그림에서 알 수 있듯이 무조건 Register를 많이 나눠서 설계하는게 좋은것은 아니다.
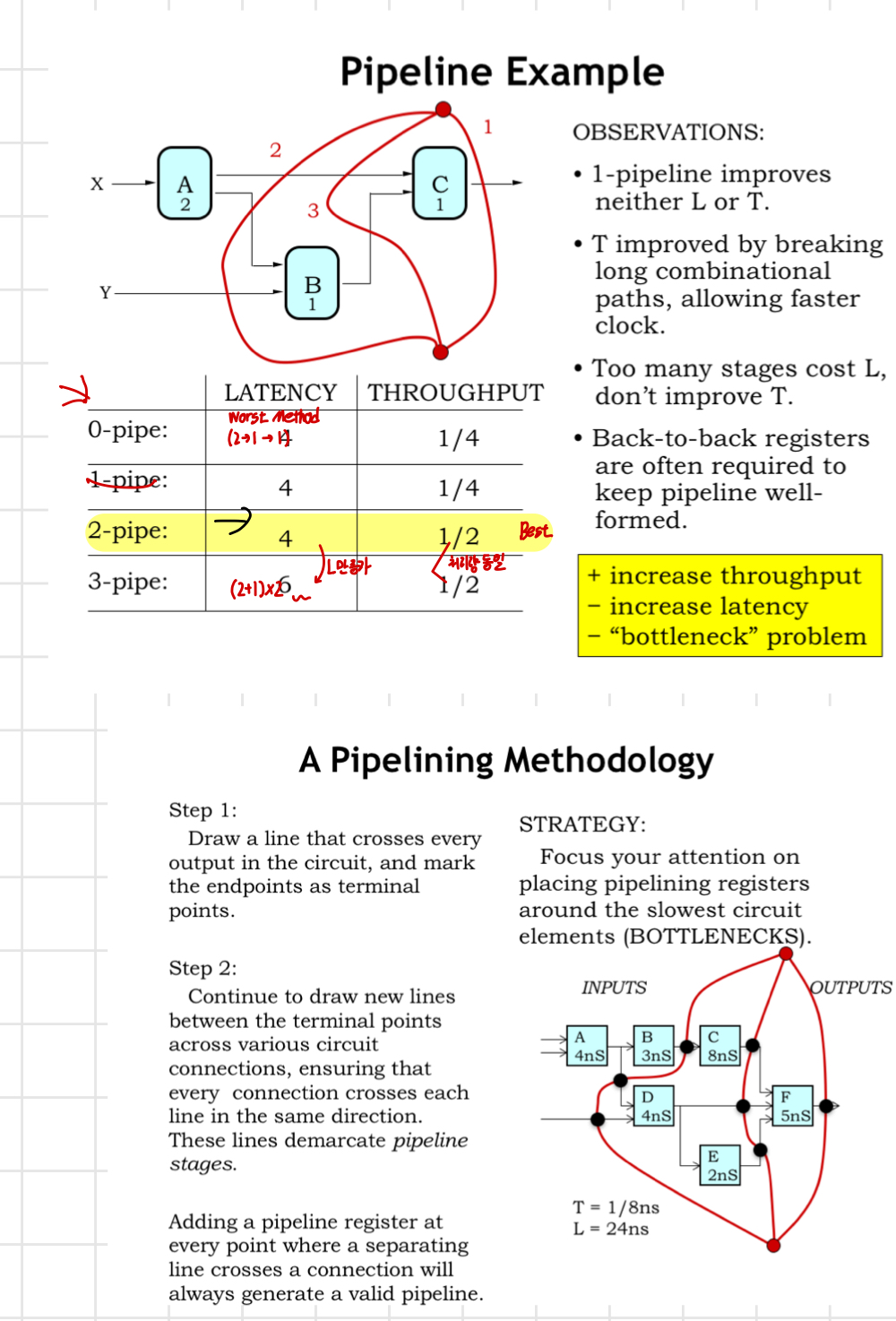
Latency와 Throughput의 단위는 'cycle'이라는 단위를 사용한다. Buffer
각 단계의 입-출력을 중계, 데이터는 저장하지 않음(플립플롭은 데이터를 저장) 일반적으로 신호 지연 줄이기, 안정화, 증폭에 사용된다.
플립플롭(Flip-Flop)은 1비트의 데이터를 저장 할 수 있고 레지스터(Register)는 여러 비트의 데이터를
'동시에' 저장 할 수 있다. 즉, 플립플롭은 레지스터를 구성하는 요소라고 할 수 있다.