지난 포스팅에서는 Odds 에 대해 알아보았습니다.
https://velog.io/@shh0422/Logistic-%ED%9A%8C%EA%B7%80-Odds
이번 포스팅에서는 본격적으로 Logistic 회귀에 대해 알아보려고 합니다.
Logistic 회귀?
아래와 같은 데이터를 살펴보겠습니다.
x축은 설명변수, y축은 0과 1만을 가질 수 있는 이진형 종속변수입니다.
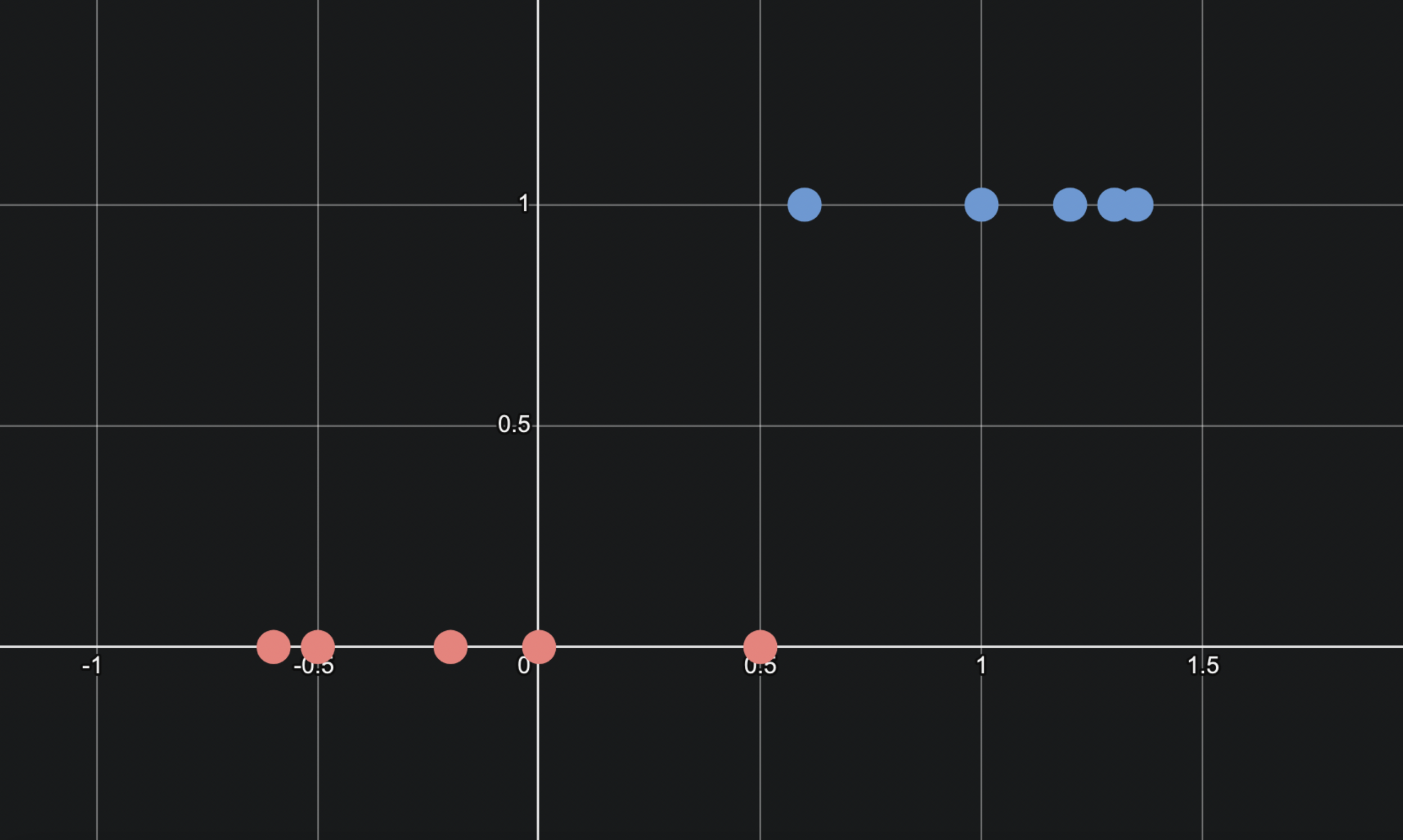
우리는 이 데이터를 나타낼 수 있는 최적의 선을 찾으려고 합니다.
그런데 만약 선형회귀 방식을 사용한다면 다음과 같은 선을 얻을 것입니다.
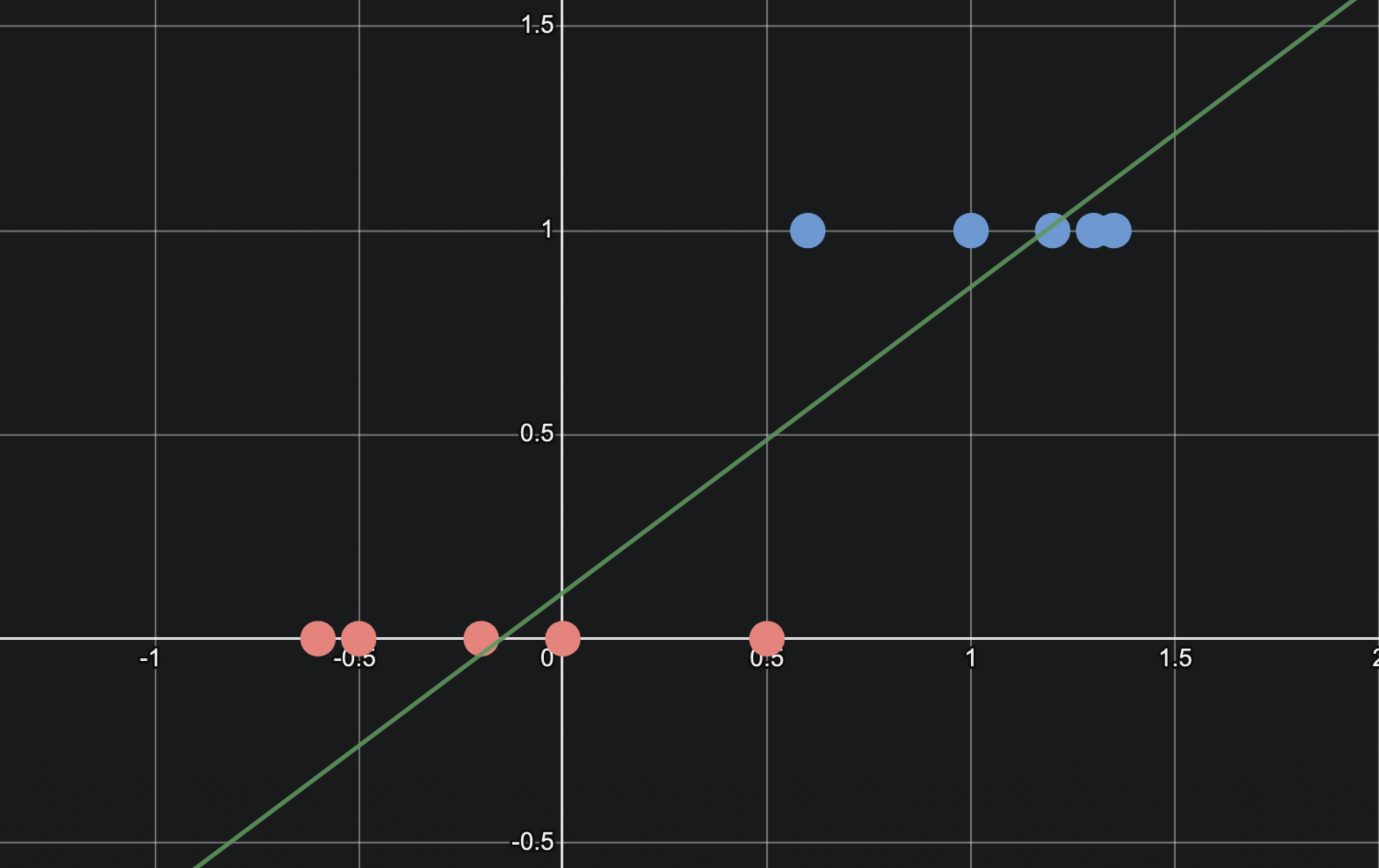
하지만 이것은 그리 만족스럽지 않은 결과입니다.
왜냐하면 지금은 y축이 연속형 변수가 아닌 0과 1 만을 가질 수 있는 이진형 변수이기 때문입니다.
우리의 데이터를 잘 나타낼 수 있는 선은 아마도 다음과 같은 모양이겠죠.

우리는 위 그림과 같은 초록 선의 방정식을 찾고 이것을 마치 확률처럼 생각할 것입니다.
초록선의 방정식이
라면 를 에 대한 종속변수의 예측값이 1일 확률로 생각하는 것이죠.
초록선의 방정식 찾기
사실 위 그림의 초록선과 같은 형태의 함수는 한 가지가 아닙니다.
따라서 우리는 초록선을 나타낼 수 있는 여러 함수 중 하나를 골라야 합니다.
여기서는 전 포스팅에서 다루었던 Odds 에 관련된 함수를 사용하려고 합니다.
다만 Logistic 회귀에서 왜 Odds 의 개념을 사용했는지는 아직 이해하지 못했습니다.
(아시는 분 있으면 댓글로 알려주세요)
이제 구체적으로 초록선의 방정식을 찾아보겠습니다.
초록선의 방정식을 찾는다는 말은 가 어떻게 확률 에 대응되는지 그 규칙을 찾는다는 말과 같습니다.
를 어떻게 확률 에 대응시키는 과정은 크게 두 단계로 쪼개볼 수 있는데요, 각 과정은 다음과 같습니다.
- 를 로 대응
- 를 로 대응
먼저 1번 과정은 를 간단하게 선형변환하는 과정입니다.
여기서 등장하는 을 구하는 것이 이번 포스팅의 최종 목적입니다.
여기서 중요한 것은 대응 전과 대응 후에 가질 수 있는 값의 범위가 어떻게 변화했는지입니다.
가 가질 수 있는 값의 범위는 입니다. (일반적인 상황을 가정하였습니다)
그리고 이 0이 아닌 이상 가 가질 수 있는 값의 범위 또한 입니다.
즉, 1번 대응에 의해서는 값이 가질 수 있는 범위가 변하지 않았습니다.
다음으로 2번 과정을 살펴보겠습니다.
우리는 범위의 값을 가지는 를 범위의 값을 가지는 확률로 대응시켜야 합니다.
그런데 서로 대응되어야 하는 구간이 무언가 익숙하지 않나요?
이전 포스팅에서 다루었던
)
함수가 을 로 대응시켰었죠.
지금 하고 싶은 것은 방향이 거꾸로 된 대응이므로 의 역함수를 사용해주면 됩니다.
즉, 다음 함수의 역함수를 구하면 됩니다.
역함수를 구하기 위해 를 서로 바꾸면
분자, 분모를 로 나눠주면
이 됩니다.
따라서 범위의 값을 가지는 를 범위의 값을 가지는 확률 로 대응시키려면
를 의 자리에 집어넣으면 됩니다.
이것이 바로 우리가 찾고 싶었던 초록선의 방정식입니다.
정리하면 의 관계는 다음과 같습니다.
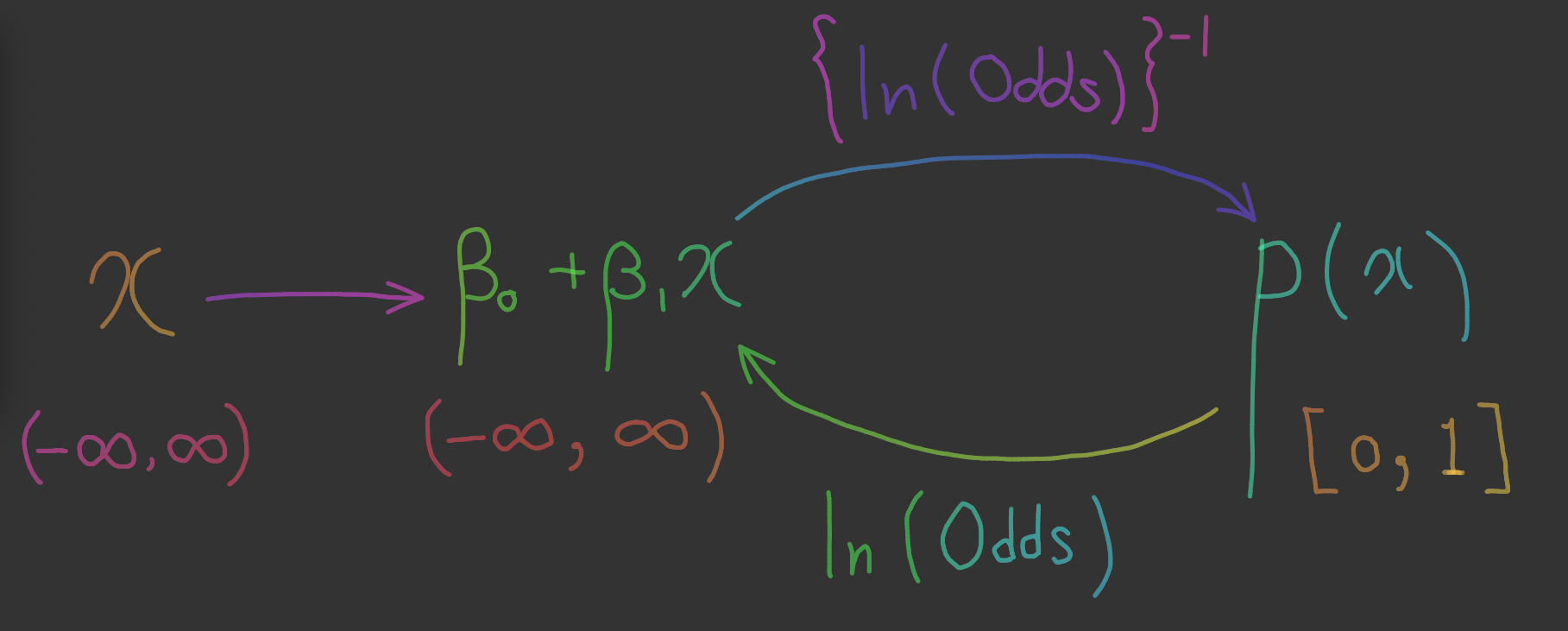
회귀 계수 구하기
각종 회귀모델에서 회귀계수를 구하는 방식은 근본적으로 모두 동일합니다.
먼저 Error 함수를 정의한 후 해당 Error 를 최소화시키는 계수를 찾는 방식이지요.
그러면 Logistic 회귀 모델에서는 Error 함수를 어떻게 정의하면 좋을지 생각해보겠습니다.
원본 데이터가 다음과 같다고 가정해보겠습니다.
그리고 우리의 확률 예측 함수 는 다음과 같은 예측을 했다고 생각해봅시다.
이 경우 모델의 Error 를 어떻게 수치화할 수 있을까요?
먼저 을 해석해보면 다음과 같습니다.
에 대한 값이 일 확률이 이다.
바꾸어 말하면, 에 대한 값이 일 확률이 이다
그런데 에 대한 실제 값은 0이므로 의 주장에 따라 값을 예측했을 때 답을 맞출 확률은 로 생각할 수 있습니다.
마찬가지로 의 주장에 따라 값을 예측했을 때 답을 맞출 확률은 입니다.
같은 논리로 생각해보면 의 주장에 따라 값을 예측했을 때 답을 맞출 확률은 입니다.
이를 종합해보면 의 주장에 따라 값을 예측했을 때 모두 맞출 확률은
가 됩니다. 확률이니까 서로 곱하는 것이 자연스럽죠.
이 값이 1에 가까울수록 를 신뢰할 수 있습니다. 즉, Error 가 0에 가까운 것이죠.
반대로 이 값이 0에 가까울수록 를 신뢰할 수 없습니다. 즉, Error 가 높은 것이죠.
따라서 이 값을 일 때는 으로, 일 때는 엄청 큰 값으로 한 번 더 대응시켜주면 훌륭한 Error 함수가 됩니다.
한 번 더 대응에 사용될 함수는 가 적당하겠네요.
따라서 우리는 Error를 다음과 같이 표현할 수 있습니다.
이제 Error 함수를 에 대한 식으로 표현하고 이것을 최소화하는 계수를 찾는 과정을 거치면 을 구할 수 있습니다.
해당 과정은 훌륭한 설명이 있는 링크로 대체하겠습니다.
https://angeloyeo.github.io/2020/09/23/logistic_regression.html
이번 포스팅에서는 Logistic 회귀를 전반적으로 알아보았습니다.
감사합니다.
