1. Introduction
- MAML, one of the most popular optimization based meta-learning algorithm.
- Preconditioned MAML
- Imporved by Preconditioned Gradient Descent(PGD) for inner loop optimization
- Meta learns not only initialization parameters of models but also meta-parameters of preconditioner .
- was adapted with innder-step k or with individual task separately, thus Riemman metric condition cannot be satisfied.- Riemman metric : A condition that the steepest gradient descent can be achieved on a given parameter space.
- Proposing Geometry Adaptive Preconditioned gradient descent (GAP), which includes two unconsidered properties.
- is adapted with individual task and optimization path(path dependent i,e, innder-step dependent).
- is a Riemman metric.
2. Background
2.1. MAML
Inner loop

Outer loop
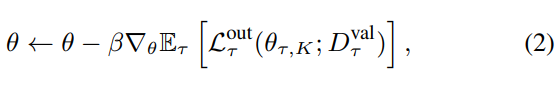 Note that, has used instead of , on the MAML paper.
Note that, has used instead of , on the MAML paper.
2.2. PGD
Preconditioned gradient update
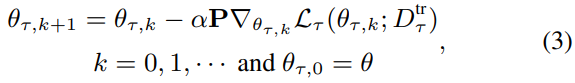
PGD often reduces the effect of pathological curvature and speed up the optimization.
2.3. Unfolding: reshaping a tensor into a matrix
Tensor and Tensor decompositions link
2.4. Riemmannian manifold
Riemannian manifold and metric
3. Methodology
Setting
- : number of layers of NN
- : CNN parameters
- : preconditioner parameters
- , : batch of tasks
- , : a task
- : number of samples
3.1. GAP: Geometry-Adaptive Preconditioner
3.1.1 Inner-Loop Optimization
-
L-layer neural network with parameters WWW
-
Let gradient GW
-
Reshape G witn unfolding mode-1 into . (mode-1 performs the best)

-
Define additional parameters
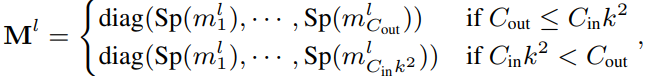 where
where -
SVD into
and -
Reshape back to it's original tensor form
-
Preconditioned gradient descent of GAP becomes:

3.1.2 Outer-loop Optimization
- GAP learns two parameter sets
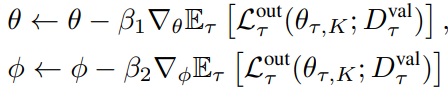
3.1.3 Training precedure
3.1.4 Desirable properties of GAP
- Fully adaptive in both task-specific() and path-depend() way
- Riemannian metric
- Steepest descent learning

HAPPY the cat