3. 비지도 학습과 데이터 전처리
비지도 학습(unsupervised learning): 출력값이나 정보 없이 학습 알고리즘을 가르쳐야 하는 모든 종류의 머신러닝
3.1 비지도 학습의 종류
-
비지도 변환(unsupervised transformation): 데이터를 새롭게 표현하여 사람이나 다른 머신러닝 알고리즘이 원래 데이터보다 쉽게 해석할 수 있도록 만드는 알고리즘
-
차원 축소(dimensionality reduction): 고차원 데이터를 특성의 수를 줄이면서 꼭 필요한 특징을 포함한 데이터로 표현하는 방법
- ex. 텍스트 문서에서 주제 추출
-
군집 알고리즘: 데이터를 비슷한 것끼리 묶는 것
3.2 비지도 학습의 도전 과제
비지도 학습의 결과를 평가? 직접 확인하는 방법뿐
비지도 학습 알고리즘: EDA단계에서 많이 사용, 지도 학습의 전처리에도 사용
3.3 데이터 전처리와 스케일 조정
-
[스케일 조정법]
train set 와 test set에 같은 변환을 적용해야함- StandardScaler: 각 특성의 평균을 0, 분산을 1로 변경하여 모든 특성이 같은 크기를 갖게 함.
- RobustScaler: 특성들이 같은 스케일을 갖게됨. 평균과 분산 대신 중간값, 사분위값 사용. 이상치에 영향 받지 않음
- MinMaxScaler: 모든 특성이 정확하게 0과 1 사이에 위치하도록 데이터 변경
- Normalzier: 특성 벡터의 유클리디안 길이가 1이 되도록 데이터 포인트를 조정(지름이 1인 원or구에 데이터 포인트를 투영). 각 데이터 포인트가 다른 비율로 스케일 조정. 특성 벡터의 길이는 상관 없고 데이터의 방향만이 중요할 때 많이 사용
-
[데이터 변환 적용]
- 훈련 세트와 테스트 세트로 나눈다
- 훈련 세트와 테스트 세트의 산점도 그리기
-
스케일 조정
- 스케일이 조정된 데이터의 산점도 그리기
- 테스트 세트의 스케일 조정
3.4 차원축소, 특성 추출, 매니폴드 학습
3.4.1 주성분 분석(PCA)
-
데이터를 회전시키고 분산이 작은 주성분으로 덜어내는 것
-
특성들이 통계적으로 상관관계가 없도록 데이터셋을 회전 시키는 기술
-
어떤 성분의 가중치 합으로 각 데이터 포인트를 나타냄
3.4.2 비음수 행렬 분해(NMF)
-
NMF(non-negative matrix factorization)는 유용한 특성을 뽑아내기 위한 특성추출에 사용하는 비지도 학습 알고리즘
-
PCA와 비슷하고 차원 축소에 사용가능
-
음수가 아닌 성분과 계수 값을 찾음
3.4.3.t-SNE를 이용한 매니폴드 학습
-
고차원 데이터가 있을 때 고차원 데이터를 공간에 뿌리면 샘플들을 잘 아우르는 subspace가 있을 것이라는 가정에서 학습을 진행하는 방법
-
고차원 데이터를 저차원으로 옮길 때 데이터를 잘 설명하는 집합의 모형
-
2차원 산점도를 이용해 시각화 용도로 많이 사용
-
클래스 레이블 정보를 사용하지 않음
3.5 군집
군집(clustering): 데이터셋을 클러스터라는 그룹으로 나누는 작업
3.5.1 k-평균 군집
-
데이터 포인트를 가장 가까운 클러스터 중심에 할당하고, 클러스터에 할당된 데이터 포인트의 평균으로 클러스터 중심을 다시 지정
-
클러스터에 할당되는 데이터 포인트에 변화가 없을 때 알고리즘이 종료
-
입력 데이터와 k-평균 군집 알고리즘이 3번 진행되기까지 과정
-
원형이 아닌 클러스터를 잘 구분하지 못한다는 단점이 있음

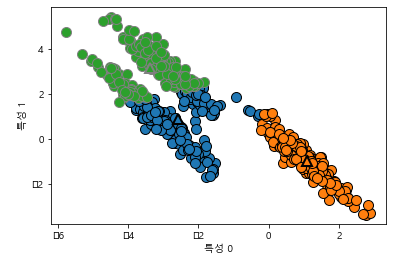
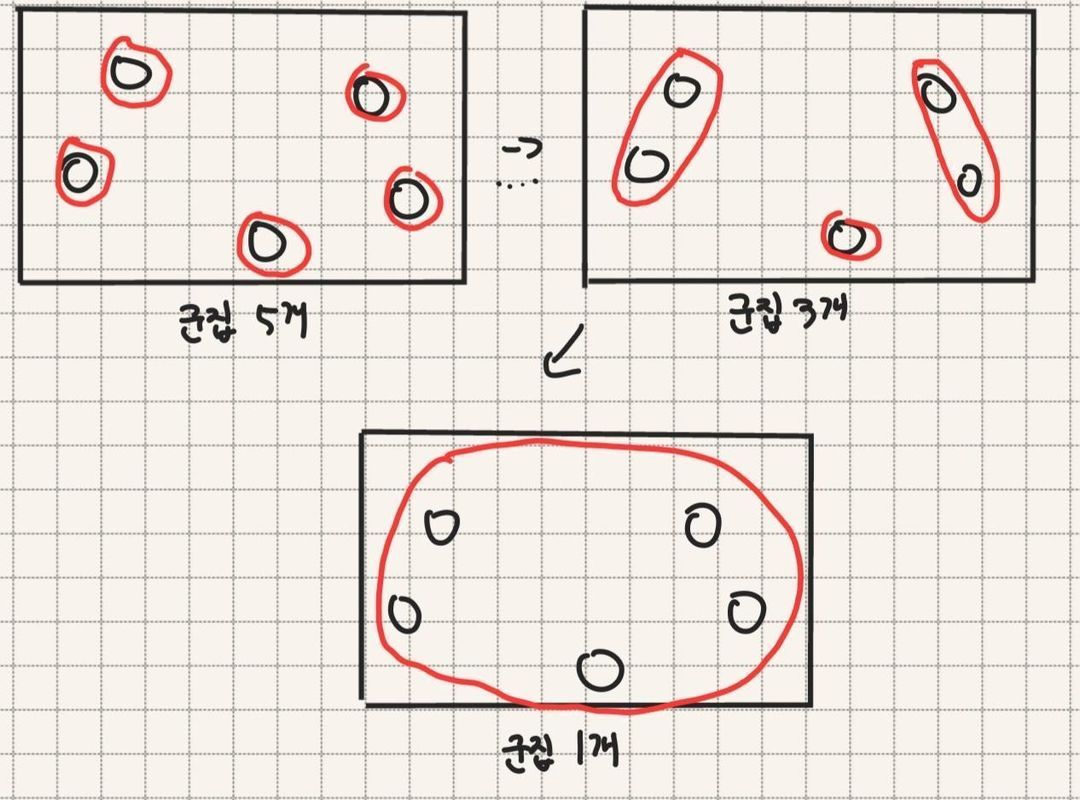
3.5.2 병합 군집(agglomerative clustering)
-
시작할 때 각 포인트를 하나의 클러스터로 지정하고, 종료 조건을 만족할 때까지 가장 비슷한 두 클러스터를 합쳐나감
-
두 인접 클러스터를 반복적으로 합쳐나가는 병합 군집
-
병합 군집은 계층적 군집(Hierarchical clustering)을 만듬

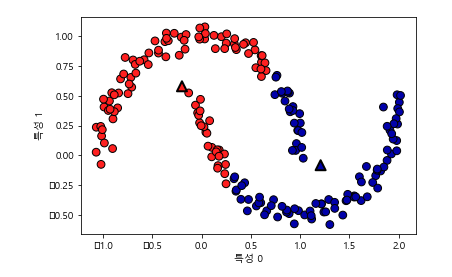
3.5.3 DBSCN(density-based spatial clustering of applications with noise)
-
밀집지역: 데이터가 많이 붐지는 지역
-
핵심 샘플(포인트): 밀집 지역에 있는 포인트
-
매개변수: min_samples, eps// 한 데이터 포인트에서 eps 거리 안에 데이터가 min_samples 개수만큼 들어 있으면 이 데이터 포인트를 핵심 샘플로 분류
-
포인트 종류: 핵심 포인트, 경계 포인트, 잡음 포인트
3.5.4 군집 알고리즘의 비교와 평가
- ARI(adjusted rand index) & NMI(noramlized mutual information)

-
클러스터를 무작위로 할당했을 때의 ARI 점수는 0이고, DBSCAN은 (완벽하게 군집을 만들어냈기 때문에) 점수가 1
-
실루엣 계수(sillhouette coefficient): 클러스터의 밀집 정도 계산
