※ 본 글은 Image Captioning task 내에서 XAI적 접근법을 적용한 한 논문을 다룹니다.
Paper: EXplainable AI (XAI) approach to image
captioning(27 July 2020)
Paper
0. Abstract
해당 연구는 image captioning으로의 XAI apporach를 다룹니다. Image captioning task를 예로 들면, 딥러닝의 'black-box' 성질 때문에 특정 이미지에 대한 캡션을 생성할 때 '왜 이 단어를 썼는지' 이해할 수 없으며, 그렇기에 때로 어이없는 결과를 내놓곤 한다.
이런 문제를 해결하기 위해 본 연구는 explainable image captioning model을 제안하며, 이를 통해 주어진 이미지 내 object(or a concept)의 region과 특정 word(or phrase) 간의 시각적 연결을 제공할 수 있게 된다.
1. Introduction
이미지 캡셔닝은 컴퓨터 비전(CV)와 자연어 처리(NLP) 분야의 하위 분야라고 할 수 있으며, 주어진 이미지에 대한 묘사를 생성하는 태스크이다. 딥러닝 기반의 이미지 캡셔닝 모델은 주로 CNN과 RNN을 사용한 encoder-decoder framework를 사용한다.
- encoder: CNN 기반의 인코더는 input image로부터 feature vector를 추출한다.
- decoder: RNN 기반의 디코더는 매 time step마다 단어를 생성하며, word들의 시퀀스(예를 들어 문장)가 caption으로 쓰인다.
하지만, 딥러닝의 'black-box' 성질때문에 이미지에 대한 캡션을 생성할 때 왜 특정 단어가 쓰이는 지에 대한 이해는 부족한 실정이다. 이런 문제를 해결하기 위해 연구 "Explainable Image Caption Generator Using Attention and Bayesian Inference"(동일저자)에서는 image 내 object와 특정 word(or phrase)의 link를 제공하는 explainable image captioning model을 제안했다.
해당 모델은 아래 그림과 같은 구조로 이루어져있다.
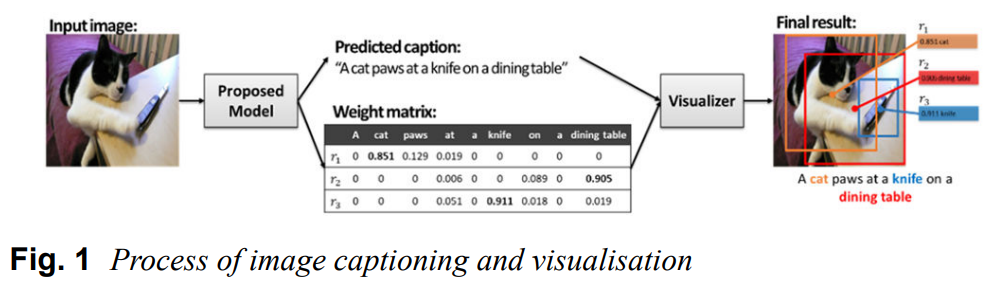
이 모델의 학습이 완료됐다고 가정하면(방법은 Section 3에 기술), caption 생성 과정은 아래와 같이 이루어진다.
- input image가 학습 완료된 model에 투입되어 caption과 weight matrix를 생성한다.
- caption은 object와 word로 학습된 언어 모델을 이용해 생성한다.
- weight matrix는 생성된 caption의 words와 이미지에서 detected된 object를 이용한 attention model을 통해 생성된다.
- 이 캡션과 가중치 행렬은 캡션 내 단어와 그에 대응하는 이미지 내 영역을 하이라이팅하는 visualizer에 전달된다.
- 그 결과, 위의 그림과 같이 가중치 값, 단어, 바운딩 박스 등이 같은 색으로 연결된다.
위에서 가중치 값은 word-region pair에서 word와 object가 얼마나 'matching'되는 지 연관성 정도를 나타낸다. 이 matched pair는 왜 캡션이 선택된 words를 이용해 생성됐는지 합리성을 제공한다.
본 논문에서는 위에서 소개한 연구의 확장 버전을 소개하며, 이는 image captioning에 대한 XAI apporach를 다룬다. 연구를 간단히 요약하면 아래와 같다.
- 우리는 region information을 고려함으로써 더욱 정교한 caption을 생성할 수 있고, visual explanation(어떤 유형인지 파악할 필요 o)을 제공할 수 있는 새로운 image caption generator를 제안한다.
- Bayesian inference를 기반으로 하는, 'explanation part'라 불리는 시각적 설명을 위한 새로운 모듈을 제안한다.
- 제안한 모델의 효율성에 대해 입증하는 정성적, 정량적 평가도 진행하였다.
Section 2에서는 관련 연구를, Section 3에서는 제안한 모델의 세부사항을, Section 4에서는 실험 결과를, 마지막으로 Section 5에서는 결론을 다룬다.
