
※ 본 글에서는 VQA or 'text to bounding box' 관련 모델들의 연구 및 코드를 간단히 정리했으며, 2020~2021년의 일부 연구의 경우 추가로 성능도 비교하였습니다.
Papers with code
1. MAttNet: Modular Attention Network for Referring Expression Comprehension(2018)
Paper : MAttNet: Modular Attention Network for Referring Expression Comprehension(2018, Cited by 265)
Code : github.com
Demo : Demo
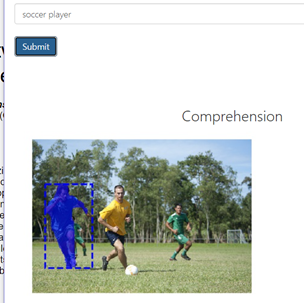
2. Referring Expression Object Segmentation with Caption-Aware ConsistencY(2019)
Paper : Referring Expression Object Segmentation
with Caption-Aware Consistency(10 Oct 2019, Cited by 15)
Code : github

3. MAF: Multimodal Alignment Framework for Weakly-Supervised Phrase Grounding(2020)
※ velog 내 시리즈 "Getting XAI Ideas for Object Detection..." 의 글에서도 한 번 다루었던 논문입니다.
Paper: MAF: Multimodal Alignment Framework for Weakly-Supervised Phrase Grounding(12 Oct 2020, Cited by 3)
Code: github
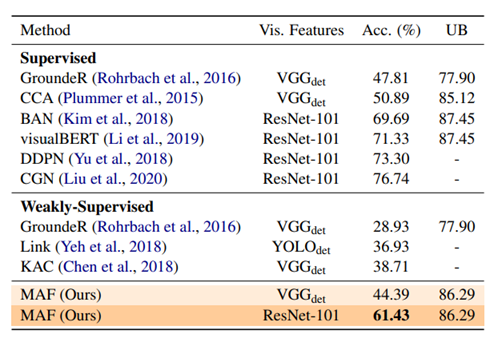
4. Referring Expression Comprehension: A Survey of Methods and Datasets(2020)
- survey paper
Paper: Referring Expression Comprehension: A Survey of Methods and Datasets
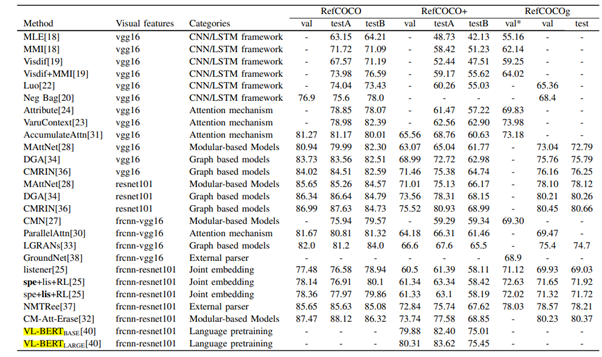

- 2020년 기준 성능이 가장 좋았던 것은 VL-BERT였다.
5.VL-BERT: PRE-TRAINING OF GENERIC VISUAL LINGUISTIC REPRESENTATIONS(2020)
Paper: VL-BERT: Pre-training of Generic Visual-Linguistic Representations
Code : github.com
- 2020년 기준 SOTA
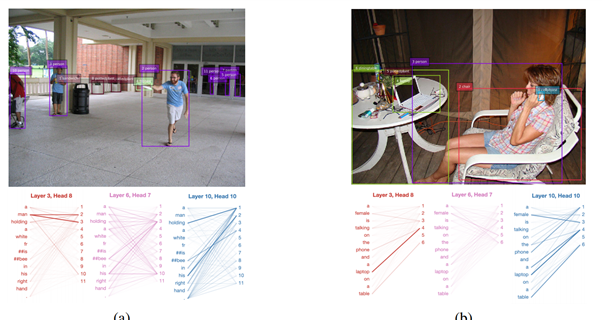
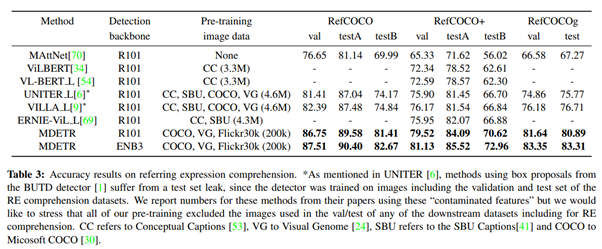
6. MDETR - Modulated Detection for End-to-End Multi-Modal Understanding(2021)
- 2021년 기준 SOTA
Paper : MDETR - Modulated Detection for End-to-End Multi-Modal Understanding



Code: github.com
Others
Benchmark site
Cite: Referring Expression Comprehension | Papers with code
Conclusion
- 이전 시리즈의 글과 마찬가지로, 모델 내 Object detection 근처 구조에서 고도의 추론을 어떤 식으로 처리했는 지 정리할 만 하다.
- 추가로, SOTA 논문인 MDETR은 논문 리딩도 해봄직 함.
