Multimodal Deep Learning
1.[관련연구]VQA - papers with code
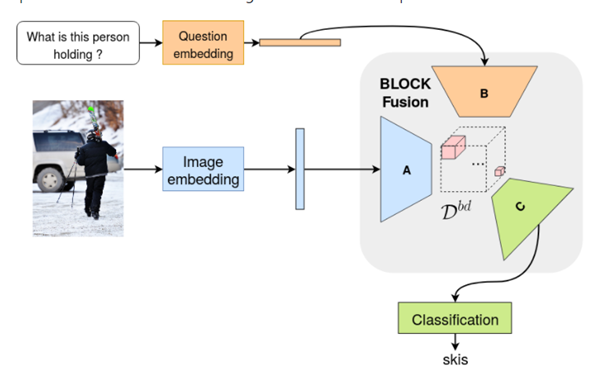
※ 본 글은 Video object segmentation에 선행하는 모델로서 작동하는 VQA 모델을 찾기 위해 사용가능한 github code와 paper를 대략적으로 정리한 글입니다. 작성일 : 2021-05-30
2.[관련연구]Object detection using text
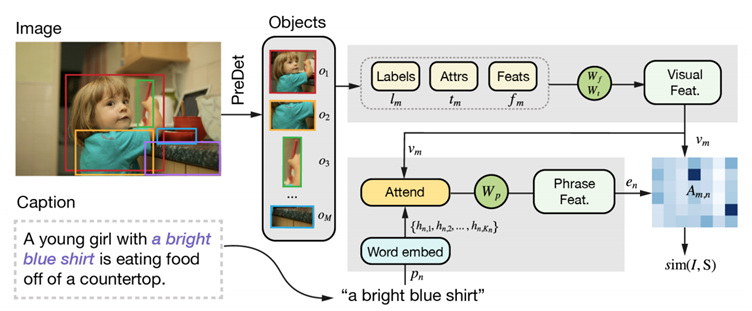
※ Text를 이용해 Image 내의 물체를 탐색하는 연구에 관해 정리한 글이다. 즉, Text(문장, 구, 절, 단어 등)과 Image를 input으로 받아 Output으로 Bounding box를 반환해주는 Text-Object-Detection 연구.
3.[관련연구]State-of-the-Art model in VQA

※ 본 글은 VQA or 'text to bounding box' 관련 모델들의 연구 및 코드를 간단히 정리했으며, 2020~2021년의 일부 연구의 경우 추가로 성능도 비교하였습니다.
4.[논문리뷰]EXplainable AI (XAI) approach to image captioning
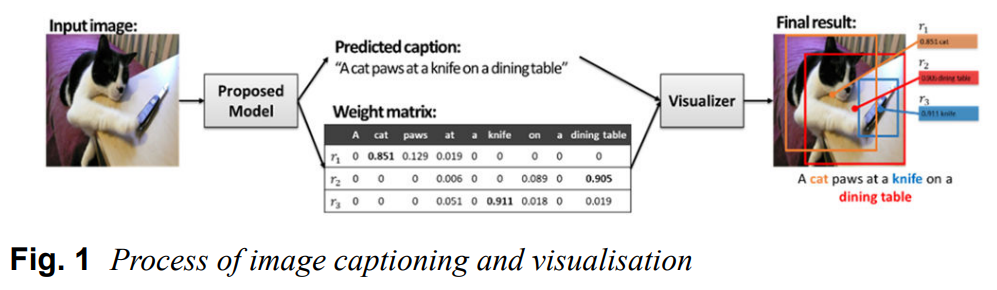
※ 본 글은 Image Captioning task 내에서 XAI적 접근법을 적용한 한 논문을 다룹니다. Paper: EXplainable AI (XAI) approach to image captioning]
5.[논문리뷰] MDETR - Modulated Detection for End-to-End Multi-Modal Understanding
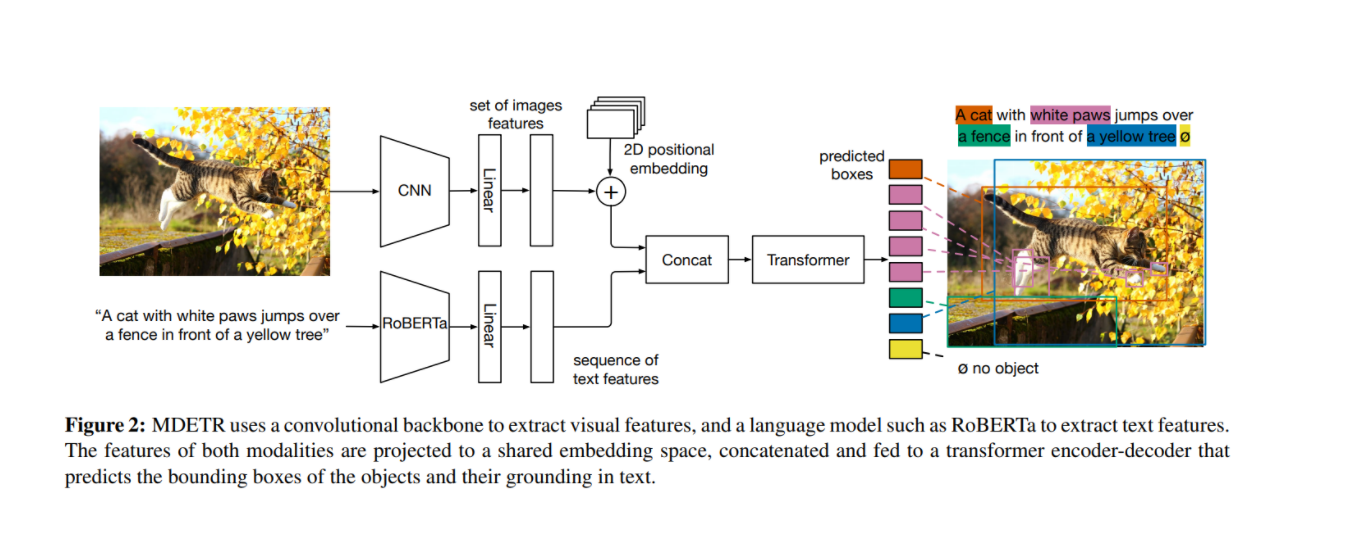
"MDETR - Modulated Detection for End-to-End Multi-Modal Understanding(2021)"에 관한 리뷰입니다.
6.Visual Question Answering using Deep Learning: A Survey and Performance Analysis

Survey paper for VQA(2020)
7.[논문리뷰] From Show to Tell: A Survey on Deep Learning-based Image Captioning(1)(Visual Encoder Part를 중심으로 )
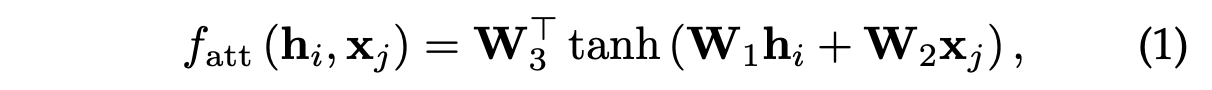
Paper:From Show to Tell: A Survey on Deep Learning-based Image Captioning
8.[논문리뷰] From Show to Tell: A Survey on Deep Learning-based Image Captioning(2)(Language Model을 중심으로)
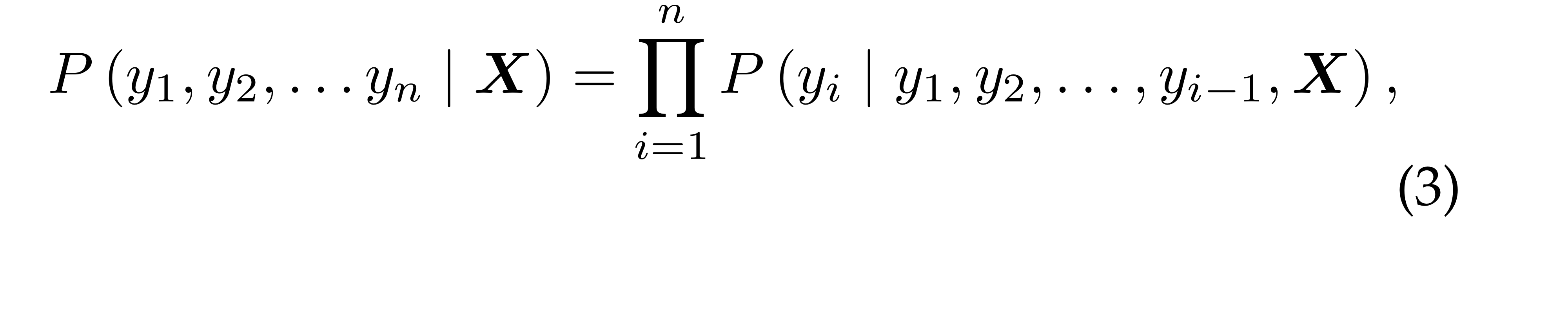
Paper review for "From Show to Tell: A Survey on Deep Learning-based Image Captioning"(Language Model을 중심으로)
9.[논문리뷰]X-Linear Attention Networks for Image Captioning
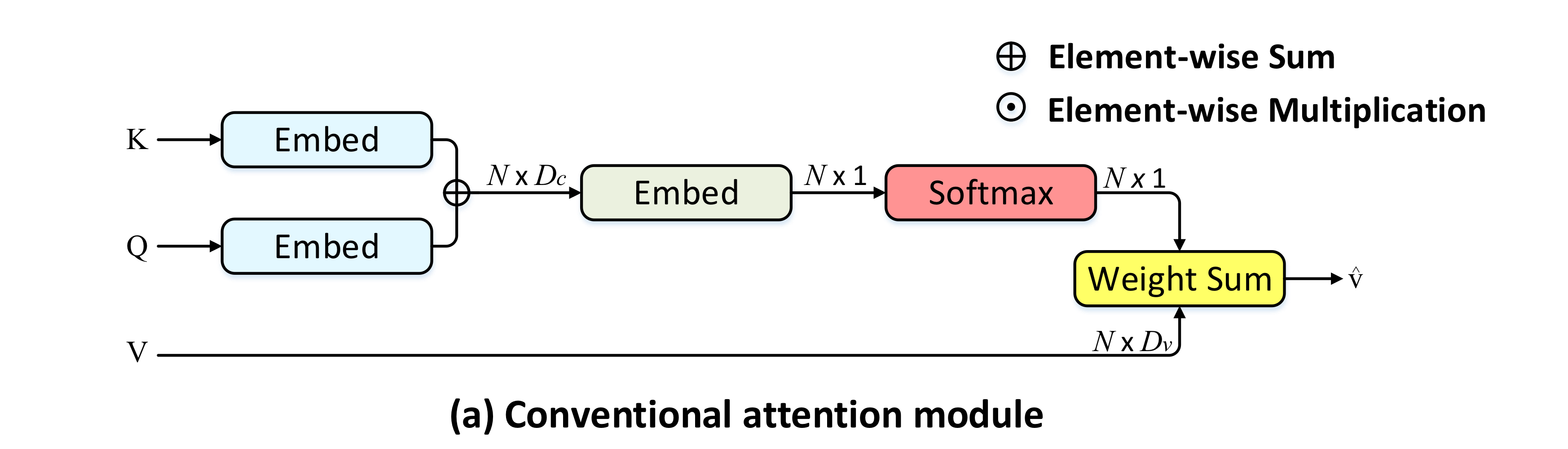
Paper review for X-Linear Attention blocks