Paper : Motion Representations for Articulated Animation(2021.04)
Code: github.com

0. Abstract
Distinct part로 구성된 object의 animating을 위한 방법을 제공한다. 완전히 비 지도 방법으로, principal axes를 고려해 motion을 추론한다. 이전의 keypoint-based 방법들과는 대조적으로, 우리의 방법은 의미 있고 consistent한 region을 생성하고, location, 모양, pose까지 묘사한다. Regions은 semantically하게 관련있으며 distinct한 object part와 대응되는데, 이는 driving video의 frame들에서 더욱 찾기 쉽다. Foreground와 background를 구분하기 위해서( 후에 background hyperparameter에서 조절할 필요 있음), additional affine transformation을 통한 non-object related global motion을 모델링 한다. Driving object의 shape가 새는 것을 막고 애니메이션을 용이하게 하기 위해서 region space의 shape와 pose를 disentangle 한다. 우리 모델은 다양한 object를 애니메이션 할 수 있으며, 매우 좋은 성능을 보인다.
1. Introduction
Static한 object에 animationㅇ을 부여하는 것은, 교육이든 엔터테이먼트든 굉장히 널리 적용될 수 있다. 특히, 유저의 경험에 있어서 창의성, 생생한 콘텐츠, 스토리텔링 등을 제고할 수 있다. 이러한 태스크에 대한 기존의 접근은 아무래도 object shape, pose 등을 배우는 데 pose와 shape에 대한 ground truth를 필요로 했다. Segmentation mask를 만드는 데는 상당히 큰 노력을 필요로 하기 때문에, 비지도 학습이 필요할 수도 있었던 것.
비지도 학습에 있어서 해결해야 할 문제는 아래와 같다.
- Object의 shape와 pose를 포함해 비정형 object의 part에 대해 표현할 방법
- Object part가 주어졌을 때, 어떻게 driving video의 motion을 통해 animate를 해낼 방법
본 논문에서 초기 여러 모델들은 여러 문제들이 있었고, 이를 해결한 비지도 모델을 소개하려 한다. 모델이 기여한 것부터 알아보자면 아래와 같다.
- Regression 대신 regions이라는 개념을 사용해, motion representation의 기반을 재정의했다.
- 이는 수렴, 안전성, robust object, motion representation 등을 증가시키며, 경험적으로는 object의 part 또한 잘 포착했다.(Fig.3)
- Non-object와 관련된 motion을 설명하는 global, affine transformation의 모수를 예측함으로써, frame 간에 존재하는 background or camera motion을 모델링했다.
- 이는 메인 모델이 object의 point를 잘 포착하게 만들어 준다.
- Shape가 변형되는 걸 막고, animation 성능을 높이기 위해 비지도 영역 차원에서 object의 shape와 pose를 disentangle했다. 즉, 높은 신뢰를 보이는 animation을 만들었다.
2. Method
우리는 FOMM(저자의 이전 모델)을 넘어서는 3가지 기여를 보였는데, 아래와 같다.
- PCA-based motion estimation(3.2)
- Background motion representation(3.3)
- Animation via disentanglement(3.6)
전반적인 모델의 과정은 아래와 같다.
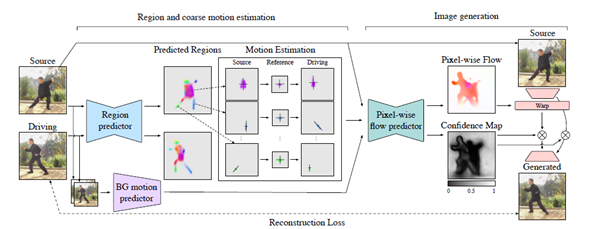
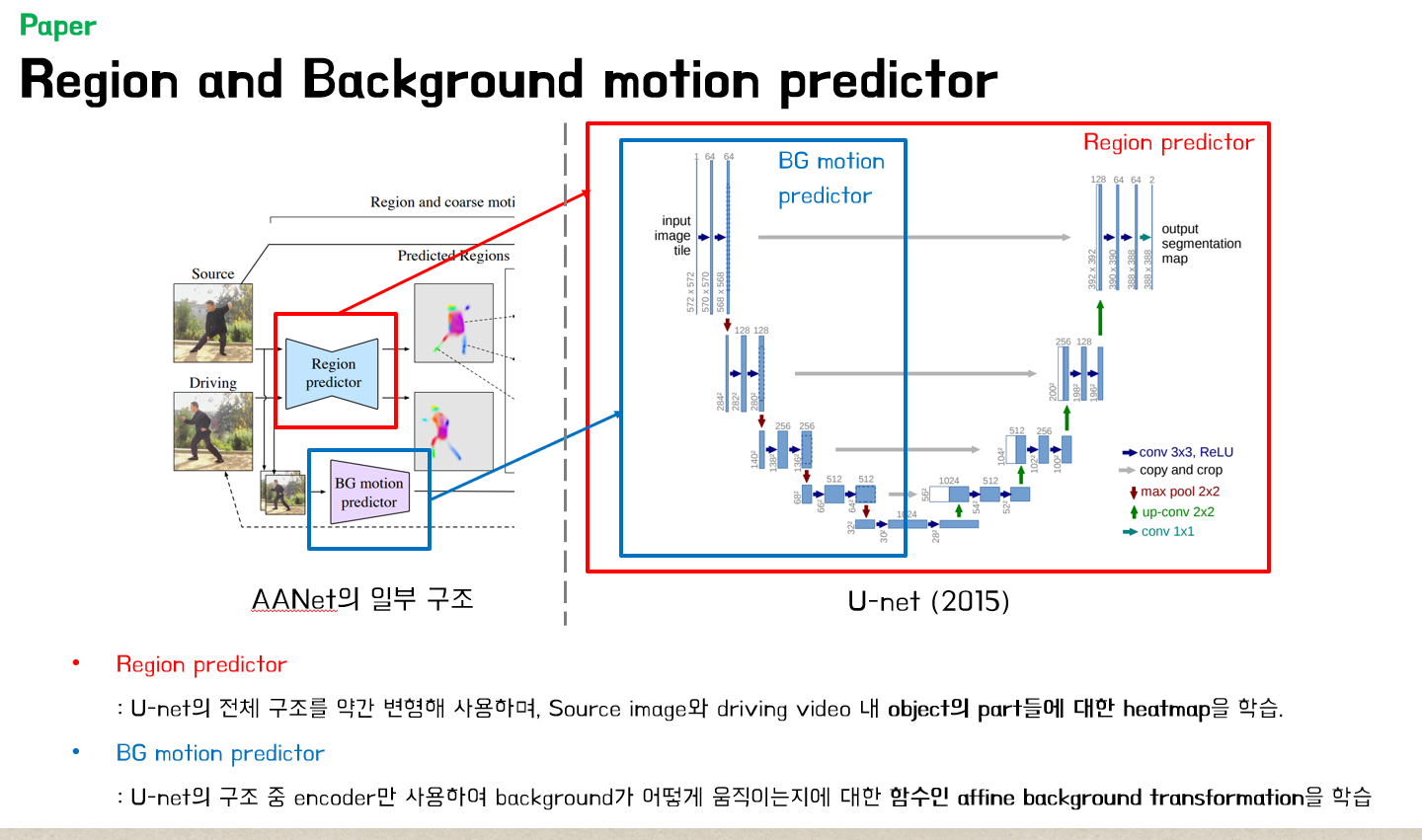
우선, Region predictor가 source image와 driving video에 존재하는 각 part에 대한 heatmap을 반환한다. 그 후, 각 heatmap의 principal axes을 계산해(PCA), source image의 각 region을 whitened reference frame을 통해 driving frame으로 맞춰준다. Region과 background transformation은 pixel-wise flow prediction network에 의해 통합된다. 타겟 이미지는 pixel-wise flow를 사용해 feature space에 있는 source image를 와핑함으로써 생성되고, 새롭게 도입된 region을 채운다(confidence map에 있다).
일단, 이전 모델에서 쓴 기법 또한 베이스가 되기 때문에 그에 대해서 먼저 소개하겠다(본 글에서는 우선 패스).
2.1. First Order Motion Model(FOMM)
2.2. PCA-based motion estimation
2.3. Background motion estimation
2.4. Image generation
FOMM과 유사하게, target image를 2단계로 렌더링한다.
- pixel-wise flow generator가 조악한 motion을 dense optical flow로 변환
- source image의 encoded feature가 flow를 따라서 와핑되며, missing region을 inpainting한다.
Dense flow predictor는 H x W x ( ) 차원의 인풋을 가진다. 이 때 region당 4개의 채널을 가지는데, 3개는 region의 affine transformation을 통해 와핑되는 source image를 위함이고, 1개는 region의 heatmap을 위함인데, 통틀어 의 gaussian approximation이다(). 또한, source image를 위한 3개의 채널은 background’s affine transformation에 따라 와핑된다.
Constant variance를 사용하는 FOMM과 다르게 우리는heatmap으로부터 covariance를 추정한다. Dense optical flow는 아래와 같은 식으로 주어진다.
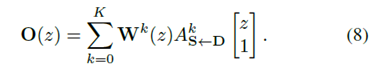
추정된 optical flow와 confidence map은 FOMM처럼 쓰인다. 하지만 deformable skip connection이 인코더와 디코더 사이에 쓰이는 점이 약간 다르다.
3. Method
3.1. FOMM
3.5. Training
우리가 제안한 모델은 end-to-end로 학습되는데, pretrained VGG-19의 feature sapce에 있는 reconstruction loss를 사용한다. 이전 연구에서 사용했던 multi-resolution reconstruction loss를 사용한다.
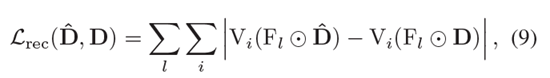
∶ driving frame(label)
: generated image(predict)
: VGG-19의 i번째 layer
: down sampling operator.
이에 추가로, equivariance loss를 사용한다.
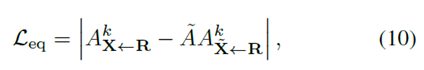
: 특정 random geometric transformation.
: 에 의해 transform된 이미지.
위의 (9)+(10)의 식을 최종 Loss로 사용한다.
3.6. Animation via disentanglement
4. Evaluation
4.2. Benchmarks
VoxCeleb : 연예인들의 인터뷰 비디오 중 정사각형 ‘얼굴’ 영역을 추출하여 256 x 256으로 다운스케일링하였음. Frame은 64에서 1024에 달한다.
TaiChiHD : 태극권 액션을 취하는 전신 비디오를 생성함. 256 size와 512 size video를 취했으며, 그를 감당할 수 없는 비디오는 삭제함.
MGif : 구글서치를 통해 2D 캐릭터 동물 dataset을 얻음.
Ted-talks : 일반화 성능을 얻기 위해 새로 모았음. 인간의 상반신을 crop하고, 384 x 384로 d다운스케일링하였다. Frame은 역시 64에서 1024에 달한다.
Evaluation method?
Video animation은 비교적 새로운 문제기 때문에 적절한 방법은 없다. 정량적인 측정을 위해 video reconstruction accuracy를 사용하였다고 한다.
error∶ ground-truth video의 pixel 값과 reconstrued video의 pixel값의 mean absolute difference
Average key-point distance and Missing Key-point Rate : AKD와 MKR이라 부른다. Ground truth video와 reconstructed video의 pose 차이를 평가한다. Body와 face에 대한 공개 비디오를 사용해 Landmark를 추출하였다. AKD는 이 랜드마크와 대응하는 평균 거리이고, MKR는 reconstrued video에는 없는, ground truth video의 randmark 비율이다.
Average Euclidean distance (AED): reconstructed video에 얼마나 identity가 보존됐는지를 말한다. Reconstructed video와 ground truth frame 으로부터 identity를 추출해 L2 norm을 계산한다.
Reconstruction quality
VoxCeleb을 제외한 모든 dataset(전신)에 대해 더욱 좋은 성능을 보였다. FOMM을 위해 Standard를, ours를 위해 avd를 사용하였다. 분명히 개선이 많이 된 모습을 프로젝트 페이지에서 볼 수 있다.
Animation Quality
성능은 그냥 우리 것이 굉장히 좋았다. Reconstruction method를 통해서는 우리의 avd 성능을 평가할 방법이 없기 때문에, 추가적으로 additional user study를 수행하였다.

Avd가 source image의 체형을 더욱 잘 보존한다.

(K=10일 때)

Modeling background motion
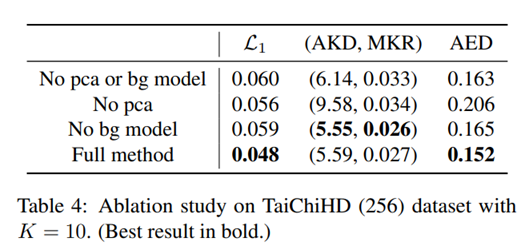
백그라운드는 이미지에서 굉장히 많은 부분을 차지하기 때문에 L_1 부분에서 굉장히 낮을 수 있다. AED 또한 눈여겨볼만 한데, Identity representation이 약간의 background를 모사한다고 볼 수 있다. 실제로, 어떠한 백그라운드 모델도 같지 않는 것은 region segmentation quality에서 약간 떨어지는 것을 볼 수 있다. (바로 위 그림의 2번째 열) 하지만, AKD와 MKR은 background modelling을 해도 크게 차이가 안 나는 것을 볼 수 있다.
5. Conclusion
이전 연구들은 representation 성능 때문에 좋은 결과를 내지는 못하고 있었다. 우리는, PCA-Based의 region motion representation을 제안하며, 이는 네트워크가 region motion을 배우고 semantically 의미 있는 object part를 학습하는 데 도움이 된다. 추가로, background motion estimation module을 제안하는데, 이는 foreground와 background motion을 분리하게 된다. 우리의 모델이 기여한 바는 다음과 같다. Region distribution과 stabilty를 개선했고, reconstruction accuracy와 유저 인식 성능이 좋았으며, 많은 region을 scale하는 능력 또한 특출났다. 우리는 또한, TED-talks라는 굉장히 어려운 dataset을 제안한다. 우리가 domain data에 대해서는 약간의 결과를 냈지만, 여전히 generalization은 어려운 문제로 남아있다. Inanimate object에까지 실용적이기 위해서.
Supplementary
C. Implementation details
공정한 비교에 있어서 우리의 기여를 더욱 강조하기 위해 FOMM과 비교를 하였다. FOMM과 비슷하게 우리의 region predictior(back-ground motion predictor와 pixel-wise flow predictor)가 original resolution의 1/4 부분에서 수행되었는데, 예를 들어 256 size의 비디오에는 64가, 384 video에는 96 등이 쓰였다. 우리는 5개의 ‘convolution – batch norm – ReLU – pooling’으로 이루어진 구조를 인코더에 사용했으며, 5개의 ‘upsample – convolution – batch norm – ReLU’를 디코더에 사용했으며, 이는 region predictor와 pixel-wise flow predictor에 모두 사용되었다.
Background motion predictor를 위해, 우리는 인코더 파트의 5개 블럭만 사용하였다. FOMM과 유사하게, Johnson 구조를 image generation을 위해 사용했는데, 이는 2개의 down-sampling block과 6개의 residual-block, 그리고 2개의 up-sampling block을 사용하였다. 하지만, 여기에 우리는 confidence map에 의해 warped되고 weighted되는 skip connection을 사용하였다. 2e-4 학습률의 Adam을 학습에 사용하였으며, 배치사이즈는 256, 384, 512에 각각 48, 20, 12를 사용하였다. 훈련 과정에서, 300만개의 source-driving pair와 random video chunk에서 random하게 골라진 each pair를 관측하며, 우리는 180만개, 270만개에 각각 학습률을 떨어뜨렸다(즉, 100에폭 중 60, 90). 4개의 Nvidia P100 GPU를 사용하였다.
Shape-pose disentanglement network또한 2개의 동일한 인코더와 하나의 디코더로 이루어진다. 이하 생략.
D. Background movement
Background modelling의 주요 목적은 네트워크가 object를 더욱 잘 다루도록 하는 것인 반면에. Animating articulated object를 위해서 background motion은 사실상 필요하지 않다. 따라서, 우리는 background motion을 estimate하고, animation 동안에 이를 zero로 준다. 하지만, 우리의 framework에서 어떤 것도 camera motion을 컨트롤하는 것으로부터 피하게 도와주는 구조가 없다.
E. TED-talks dataset creation
TED talks 비디오에서, 사람의 상반신이 최소한 64 frame 이상 보이며, person의 bounding box 크기가 적어도 384 pixel보다는 큰 비디오를 골랐다. 그 후, 우리는 손으로 static video와 사람이 presenting 대신에 무언가를 하는 비디오를 골랐다. 결국 411 video쯤 됐고, 그 비디오들을 364의 training과 42의 testing video로 나누었다. 그 후 각 video를 significant camera change가 없는 chunk로 나누었다. 그를 위해 presenter는 starting position에서 크게 움직이지 않았다. 우리는 presenter 주변의 square region을 잘랐으며, 384 x 384 pixel로 다운스케일링 했다. 64 frame보다 길이가 작거나, downscaling 되기에 충분한 해상도가 없는 비디오는 삭제했다. Human에 대한 bounding box estimator를 사용해 distance move와 region cropping을 완료한 다음, 1177개의 training video와 145개의 test video chunk를 얻었다.
발표 때 썼던, PPT
