Paper : arxiv.org
Code: github.com

0. Abstract
Video inpaint는 video에서 시-공간적인 hole을 그럴 듯 한 내용으로 채우는 것을 목표로 한다. Image inpainting을 위한 딥러닝 네트워크가 엄청나게 발전했음에도 불구하고, 이 방법을 video domain에까지 확장하는 것은 매우 어렵다. 왜냐하면 추가적으로 time dimension을 고려해야 하기 때문이다. 본 연구에서는, fast video inpainting을 위한 신선한 deep netowork architecture를 제안한다.
Image-based encdoer-decoder 모델을 기반으로, 우리가 제안한 framework는 이웃 frame에서 정보를 얻고 정제해 아직 안 알려진 region을 합성하게끔 설계된다. 동시에, recurrent feedback과 temporal memory module을 이용해 output은 시간적으로 consistent하게끔 강화된다. Sota image inpainting 알고리즘과 비교해도 우리 방법은 매우 semantically correct하고 temporally smooth한 비디오를 생성했다. Time-consuming optimization에 의존하는 이전의 video completion method 방법과 대조적으로 우리 방법은 거의 real-time으로 경쟁력 있는 video result를 생성한다. 마지막으로, 우리는 우리의 frame work를 video retargeting task에 적용하였고, 시각적으로 만족할 만한 결과를 얻었다.
1. Introduction
Video inpainting은 다양한 비디오 편집과 undesired object removal, scratch, damage resotration 등과 같은 복구 태스크와 retargeting 등에 도움이 된다. 더 중요한 것은, 전통적인 요구를 배제하고, video inpainting은 더 좋은 시각적 경험을 위해 Augmented Reality (AR)과의 결합에도 쓰일 수 있다는 것이다.
즉, overlaying new elments를 하기 이전에 existing item을 지우는 데 초점을 두는 것이다.
따라서, Diminished Reality (DR, 증강현실의 반대격) 기술로서, 최신의 real-time/deep learning-based AR 기술과 연결할 기회를 준다.
또한, automatic content filtering 또는 visual privacy filtering과 같은 semi-online streaming scenario 또한 있다. 이러한 요소들로 인해 speed(혹은 inference time 정도) 그 자체를 굉장히 중요한 이슈로 만든다.
Single image에서 inpainting 기법의 엄청난 진보에도 불구, 여전히 video domain으로 확장하기는 쉽지않다(시간 차원 고려를 위해). Complex motion과 temporal consistency(시각적인 일치; 부드러움)의 고도화 요구에서 오는 어려움은 비디오 인페인팅을 어려운 문제로 만든다. 가장 간단한 비디오 인페이팅 방법은 frame별로 이미지 인페이팅을 적용해, 단순히 연결하는 것이다.
하지만 이 방법은 vidoe dynamic에서 오는 motion regularites를 무시하며, 그로 인해 시간에 따른 image space에서 발생하는, 전혀 사소하지 않은 apperance change를 평가하는 능력을 결여한다. 또한, 이런 현상은 temoporal inconsistency(시각적 불일치)를 불러일으켜 심각한 flickering artifact를 야기한다. 아래 그림의 2번째 행이 state-of-the-art feed-forward image inapinting 방법을 video 내 frame마다 적용한 결과물이다.

위 그림의 input 특성 상 본 연구의 모델이 훨씬 유리하다는 것은 감안하도록 하자. 카메라가 stable 할 뿐만 아니라, shadow를 잡지 못했다는 점 등도 주목할 만 하다.)
Temoporal consistency를 다루기 위해, 여러 방법들이 이미 개발되어 왔다. Local spatio-temporal pathces에서 greedy selection을 이용하거나, per-frame diffusion-based 기법이나, iterative optimization 등이 그 예시이다. 하지만, 처음 두 방법은 flow estimation이 color estimation과 독립적이라 여기며, 마지막 기법은 시간을 잡아먹는 optimization 방법에 의존한다(위 그림의 3번째 row가 그에 해당; 또한 효과적이긴 하나 실용성과 general scenario에서의 유연성에서 한계가 존재).
또 다른 사람은 post-processing method를 적용함으로써 temporal consistency를 유지하는 것을 시도하기도 했다. 최근에는 input으로 original video와 per-frame processed video를 받고, temporally consistent video를 생성하는 deep CNN model이 제안되었다. 하지만, 이 방법은 단지 two input video가 pixel-wise correspondence(예를 들어, colorization)을 가질 때에만 적용 가능하며, 이는 video inpainting에 알 맞는 상황은 아니다.
video colorization

본 논문에서는 feed-forward deep network가 video inpainting task에 채택될 만 한지를 탐구한다. 구체적으로, 우리는 두 가지의 핵심 기능을 하는 모델을 학습할 것이다.
1. Temporal feature aggregation
2. Temporal consistency preseving
Temporal feature aggregation을 위해서는, video inpainting task를 sequential한 mutl-to-single frame inpainting problem으로 여길 것이다. 특히, 우리는 2D-based(즉, image based) encoder-decoder model을 기반으로하는 3D-2D feed-forward network를 도입한다. 이 네트워크는 neighbor frame으로부터 potential hint를 얻고, 정제해 semantically-coherent video content를 시공간적으로 합성하게끔 구현된다.
Temporal consistency를 위해서는, reccurent feedback과 memory layer(convolutional LSTM)를 사용하는 방법을 제안한다. 추가로, 우리는 이전의 합성된 frame의 warping을 학습하는 flow loss와 short-term, 그리고 long-term consistency를 강화하는 warping loss를 사용한다.
마지막으로, 우리는 single, unified deep CNN model인 VINET을 개발했다.
우리는 우리 모델의 기여를 검증하기 위해 광범위한 실험을 수행했다. 우리는 우리의 multi-to-single frame formulation이 (이전 방법에 비해) 매우 정확하고 시각적으로 만족스러운 video를 생성했음을 보여준다. 우리 모델은 sequentially하게 임의의 길이를 가진 video frame를 처리하고, test time에넌 어떠한 optical flow computation을 필요로 하지 않으며, 그렇기에 거의 real-time에 달하는 속도로 수행할 수 있다.
Contribution
3. Method
3.1. Problem Formulation
Pass
3.2. Network Design
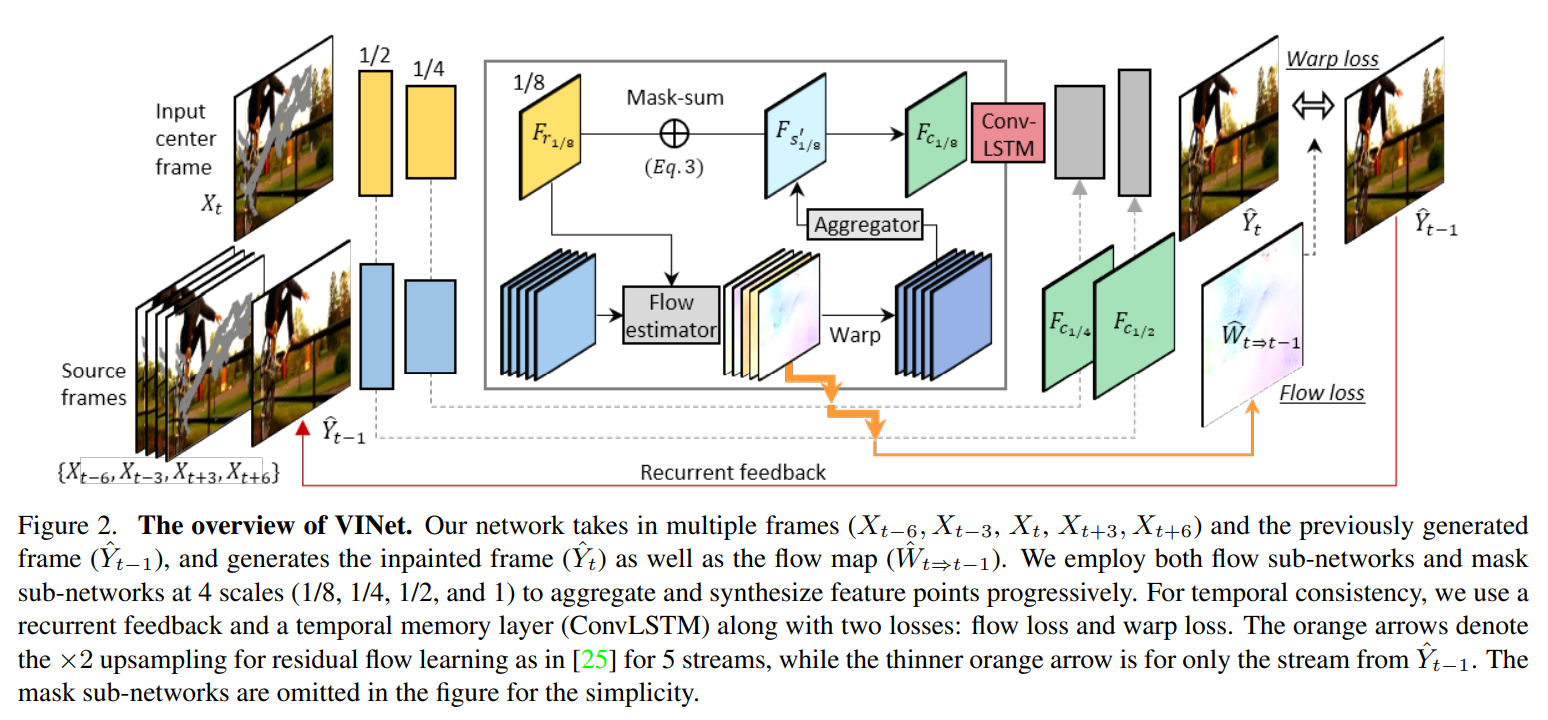
우리의 모델은 이전의 여러 프레임들과 바로 직전의 inpainted frame을 이용한다. 또한 Flow map도 생성한다. Flow sub-networks와 mask sub-networks를 1/8, 1/4, 1/2, 1 scale에서 각각 시행하는데, 이는 feature points를 점진적으로 aggregate하고 synthesize 하기 위함이다.
Temporal consistency를 위해 recurrent feedback과 temporal memory layer(ConvLSTM)을 사용한다. 이 때 loss는 flow loss, warp loss 2가지를 사용한다. 오렌지 색 화살표는 연구 PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume"에서 쓰인 것처럼 residual flow는 2배 업샘플링 해준다(5 stream). 반면에, 오렌지 색 얇은 화살표는 오직 (에서 나온 stream을 이용한다. Mask sub-networks는 그림에서 생략됐다.
3.2.1. Multi-to-Single Frame Video Inpainting
만약 이전, 또는 미래 frame에서 현재 frame의 가려진 부분 등을 얻어올 수 있다면 좋겠다고 생각한다. 이를 위해서 temporal feature aggregation과 single-frame inpainting을 동시에 학습하는 encoder-decoder network(vinet)을 구성했다. 다양한 input을 다룰 수 있게끔 fully convolutional 하게 구현했다.
Source and reference encoders
Encoder는 source stream(5개, 참고 할 시점)와 reference streams(1개; 아마 현재 시점)를 가지는 multiple-tower network이다.
Source stream은 input으로 inpainting mask() + past frames(with mask, 2개)+ future frames(2개)를 받는다.
Reference stream에서는 current frame과 그것의 inpainting mask를 제공받는다.
이미지의 channel(rgb, black..)을 따라 image frame과 mask를 concat하고, 이를 encoder로 투입한다.
우리는 이 때 6-tower encoder를 사용하는데 5 source stream(, 그리고 마지막으로 을 Input으로 취하며 가중치는 공유)와 1 reference stream으로 이루어진다. Reference feature와 겹치지 않는 source features의 경우 feature flow learning과 learnable feature composition을 따름으로써 missing regions을 채우는 데 쓰일 수 있다.
Feature Flow Learning
우리는 source frame과 reference feature를 바로 합치기 보다는 feature point를 explicitly align하는 방법을 제안한다. 이는 neighbor frame으로부터 추적 가능한 특징을를 쉽게 빌리게 해준다.
이를 위해서 4개의 scale에서 source와 reference 간의 flow를 측정하는 flow-sub-networks를 도입, 여기서 flownet을 사용한다. (이전 프레임과 현재 프레임의 pseudo-ground-truth flow를 추출)
Learnable Feature Composition
5 source streame으로부터 aligned feature map이 주어진다면, time-dimensions을 따라 concat되고, 5x3x3 형태()의 convolution layer로 투입된다. 이 conv-layer는, 1 time dimension의 spatio-temporally(시공간적) aggregated feature map 를 생성한다.
이는 time axis 동안 source feature point를 역동적으로 고르는데, reference feature와 일치(complimantary)하는 feature를 하이라이팅하고, 아니라면 무시한다.
단순히 이전, 미래 frame이 현재와 일치하는 부분들을 배운다고 보면 될 듯합니다.
For each 4 scales, mask-sub-network를 수행하는데 이 network는 위의 aggregated feature map 를 reference feature map 과 통합한다. 식은 아래와 같다(예시는 in 1/8 scale).

Mask sub-network는 3개의 convolution layer로 구성되며, 두 feature map의 차이()를 input으로 받아, single channel composition mask 을 생성한다(위 논문의 방법으로). 이 mask 을 사용함으로써 점진적으로 warped feature와 reference feature를 통합할 수 있다.
: 5 source stream’s aggregated feature map
∶ reference feature map
Decoder

Maksed region에서 skip connections이 zero value를 포함하지 않게끔, 우리의 skip-connections은 composite feature similarly를 통과한다((3)과 유사).
Image의 세부사항을 decoder에 전달하기위해 U-net을 사용한다. Zero value가 나오지 않게끔 (3)과 유사하게 설정.
: reference 현재의 frame 관련
: source 과거, 미래의 frames, 그리고 직전의 inpainting frame이 합쳐짐.
: 둘이 합친 것.
위의 1/4, 1/2 scale은 Decoder 이후에 있다는 것.

마지막 스케일(1) 에서 을 를 이용해 current raw output 로 warping 한다. 이를 composition mask 을 갖는 raw output과 합쳐 최종적으로 얻는다.
3.2.2. Recurrence and Memory
비디오 output의 시간적인 일치를 증강하기 위해 과 temporal memory layer 의 recurrent feedback loop를 사용한다. (아래 방정식)


- Current output은 분명 previous output frame의 조건부 분포가 되어야 한다.
- 또한, traceable feature는 변하지 않아야 하며, occlusion 등으로 인해 untraceable한 point는 합성이 필요하다.
- 이는 motion도 잘 따라가고, 이상한 artifact도 안 생기게끔 해준다.
- Recurrent feedback은 연속된 frame을 연결하지만 large hole을 채우는 것은 분명 more long-term(e.g. 5 frames)의 지식을 필요로 한다(ConvLSTM 사용).
- 특히, 1/8 scale(Decoder 이전?)의 (5 source와 reference를 합친 feature map) 를 매 time step에 ConvLSTM에 넣는다.
3.4. Two-Stage Training
- 점진적으로 core functionalities를 학습하는 two-stage training scheme 채택
- Temporal feature aggregation 학습을 위해 recurrent feedback, memory 없이 학습을 시킨다.
- A. 오직 reconstruction loss만을 사용한다.()
- A. 이후, recurrent feedback과 ConvLSTM layer를 이용해 full loss를 사용한다.() for temporal coherent predict
- B. 이를 위해 Youtube-VOS dataset을 사용했다.(256x256 pixels)


