Self-supervised Learning in Generative Model
SSL(Self-supervised Learning)?
GAN 기반 생성모델들은 최근 많은 발전을 이루었지만, 기존에는(그리고 현재도) 학습의 불안정성을 많이 겪어왔습니다.
애초에 판별자와 생성자가 적대적으로 경쟁해가며 학습하기 때문에 high-dimensional space에서 내쉬 균형을 찾기란 쉽지 않습니다.
데이터 관련 문제(memory, cost, lack of data, e.t.c)도 존재하구요.
반면, NLP분야에서는 BERT, GPT 등을 필두로 한 Self-supervised Learning이 큰 잠재력을 보였고, 2021년 최근에는 사실상 Computer Vision 분야에서도 Transformer를 필두로 하는 모델들이 Sota를 차지하고 있습니다.
SSL in GM
이에 따라 GM(Generative Model) 분야에서도 NLP, CV분야처럼 large-scale dataset을 이용한 pre-trained model을 활용하려는 움직임이 활발해졌습니다.
여기서 말하는 Pre-trained model은 Label이 주어진 데이터에 사전학습시킨 것이 아닌, Label이 필요 없는 Self-supervised learning 방식으로 학습한 모델을 뜻합니다.
사실 Label이 필요 없다기 보다는 대용량 데이터에 대한 Label을 얻는 비용이 만만치 않기 때문이지만요.
Self-supervised learning은 기본적으로 엄청나게 많은 parameter를 갖는 모델을 이용해 초대형 데이터셋을 학습하게 되고, 이 과정에서 스스로 라벨을 부여해 주어진 데이터 셋으로부터 기본적인 정보들을 학습하게 됩니다.
스스로 라벨을 부여한다는 것은, 연구자가 데이터로부터 바로 라벨을 얻을 수 있는 특정 task를 정해 놓고, 프로그래밍을 통해 데이터 셋에 라벨을 적재한다는 것입니다.
(기계가 이미지를 판단해서 스스로 class를 부여하고 이미지 캡션을 부여하는 등의 개념이 아님)
위에서 라벨을 얻을 수 있는 특정 task를 SSL(Self Supervised Learning) 분야에서는 pretext task라 부릅니다.
대용량 데이터에 pretext task를 활용해 (별도의 라벨링이 필요 없는)Self-supervised방식의 학습을 한 후, 그렇게 학습한 모델을 우리가 적용하고자 하는 down-stream task(specific task)에 지도 학습 방식으로 전이 학습을 시키게 됩니다(**transfer learning).
즉, pretext task에서 충분히 많은 데이터를 학습한 뒤에, 새로운 task에서 소량의 데이터만으로도 의미 있는 representation을 학습할 수 있게 됩니다.
Pipeline
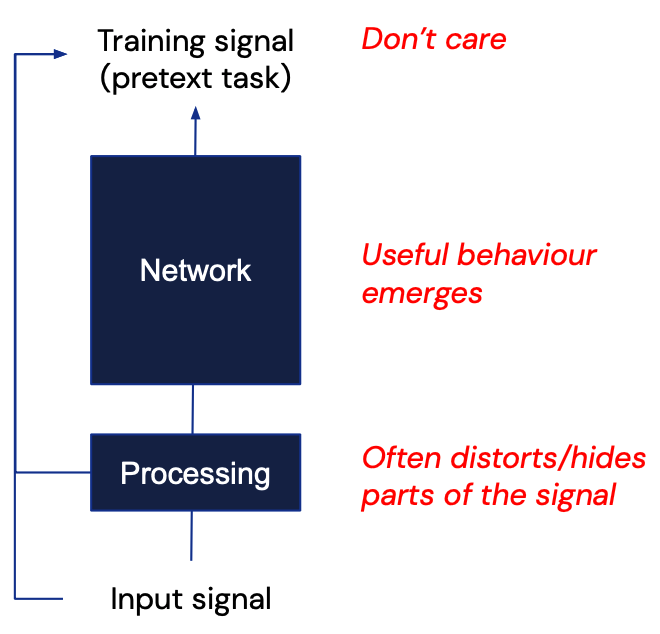
위에서 Network는 일반적인 딥러닝 네트워크를 말하며, Processing은 large-scale dataset으로부터 input data를 적절히 생성하고, 그에 따라 label도 적절히 세팅하는 과정입니다.
1. pretext task 학습(with large-scale Unlabeled data)
라벨이 없는 대규모 데이터에 학습을 진행하게 됩니다.

위의 그림에서는 pretext task로 rotation classification을 설정해, 각도라는 Label을 부여해 학습하게 됩니다(데이터로부터 곧바로 얻을 수 있음).
2. Downstream task 1차 학습(with small-scale labeled data)
라벨이 있는 소규모 데이터에 우리가 원하는 task에 대한 학습을 진행하게 됩니다(새롭게 추가한 layer만).
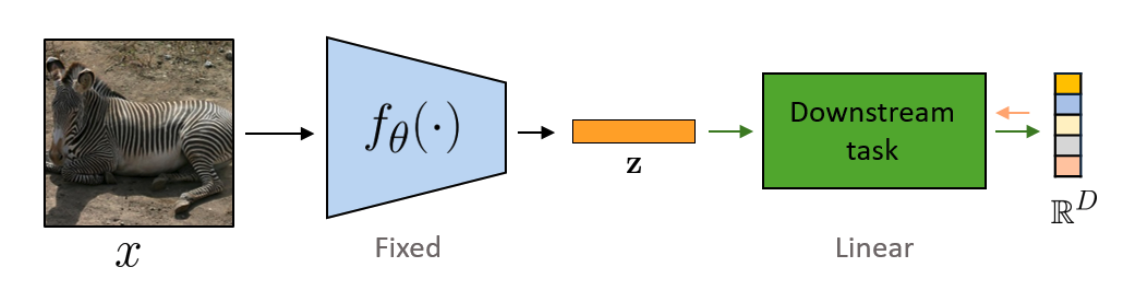
이 때, pretext task에서 학습한 모델의 parameter는 우선 fixed한 다음, 새롭게 원하는 downstream task에 맞게 추가된 layer만 학습하게 됩니다.
Transfer Learning의 첫 번째 단계로 볼 수도 있습니다(Task Generalization).
3. Downstream task 2차 학습(with small-scale labeled data)
라벨이 있는 소규모 데이터에 우리가 원하는 task에 대한 추가 학습을 진행하게 됩니다(pre-trained model의 layer도 학습)
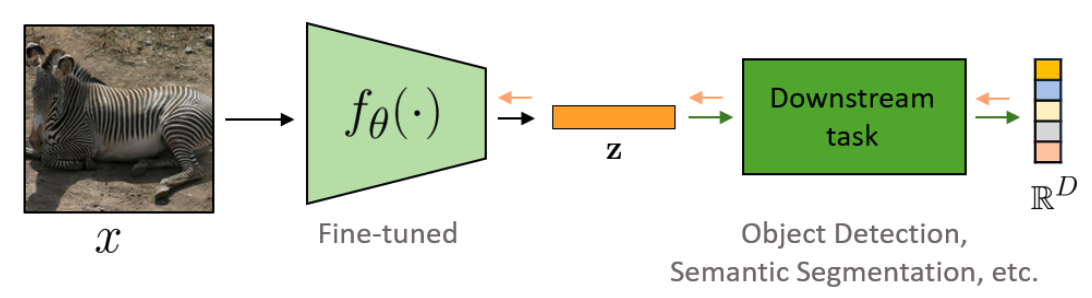
사전학습한 parameter가 제 기능을 할 수 있도록 '학습률을 낮춰' 진행해야 하기 때문에 이를 Fine-tuning이라 부르기도 합니다(Transfer Learning의 두 번째 단계 : Dataset Generalization).
SSL방법의 장점과 pretext task의 일부 예시
장점
- pretext task를 학습할 때에는 데이터 셋을 구축하는 데 비용과 시간이 크게 들지 않는다(라벨링할 필요가 없으므로).
- 사실 이거 자체가 뭐 장점은 아닌데, pretext task 학습으로 downstream task의 성능을 크게 올릴 수 있다면 장점이 될 수 있을 것.
- 데이터 셋 편향 최소화(대규모 모델).
- 범용성을 가지는 모델을 학습할 수 있음.
- Few-shot Learning과 유사한 기능
pretext task
- 얻은 데이터의 일부분을 손상시킨 뒤, 그를 채우는 방향으로 학습
- 시각적인 상식이나 문맥을 이용(Label이 필요 없는)
- 대조적으로 학습.
더욱 구체적으로는 아래에서 살펴보겠습니다.
Example of SSL in GM
굳이 경계를 나눌 필요는 없지만, 본 글에서는 Generative Model(Auto Encoder, Variational AutoEncoder, GAN) 기반의 SSL만을 다룹니다.
일반적인 이미지 관련 SSL 기법들은 Self-supervised learning in Computer Vision(본 블로그)을 참고하세요.
1. AutoEncoder-Based Approaches
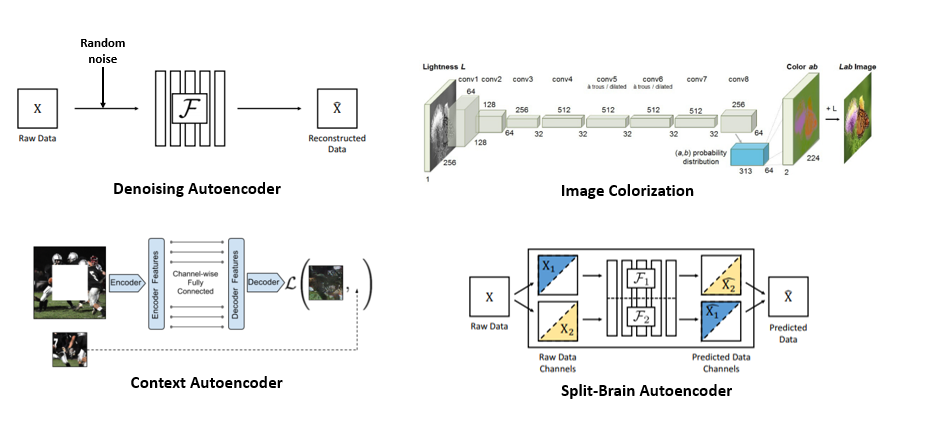
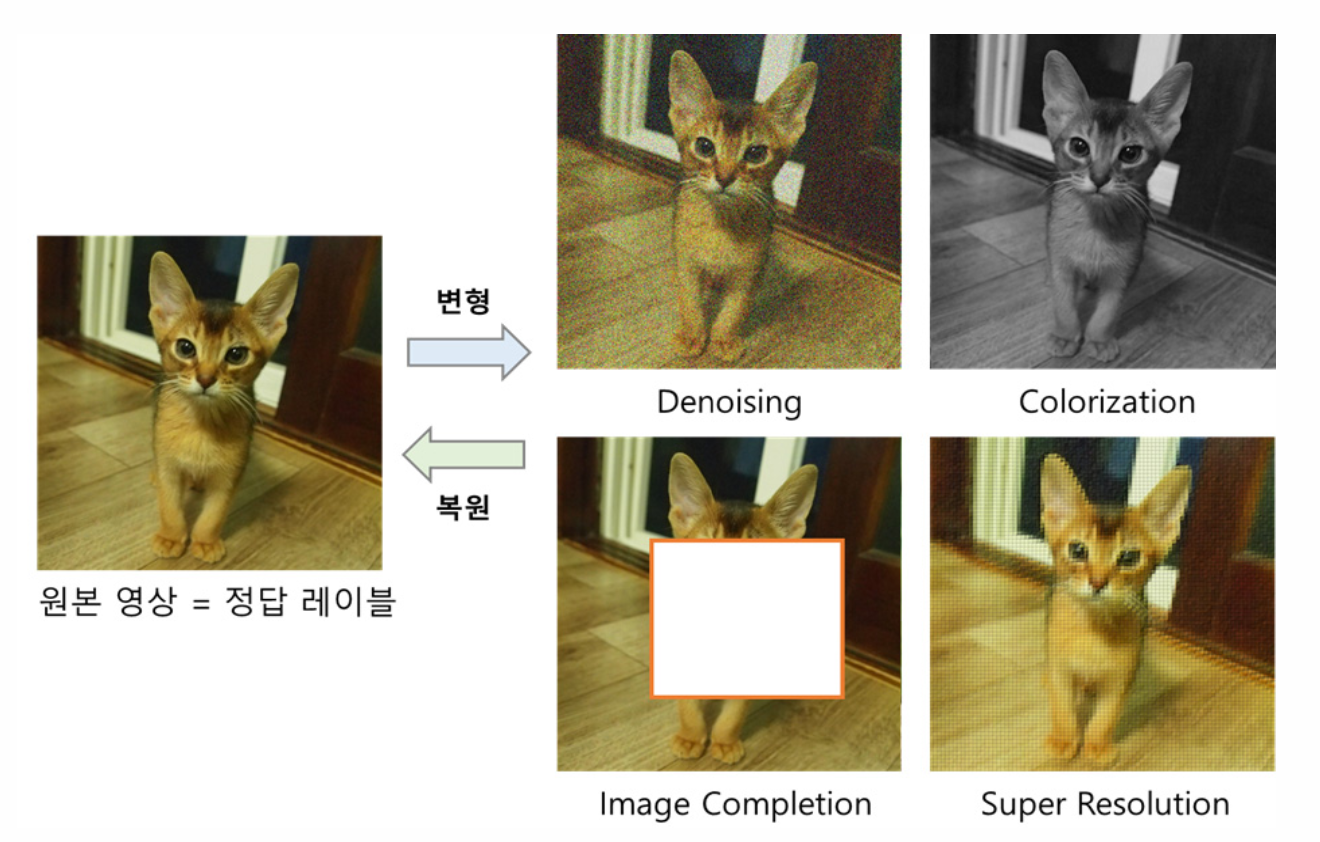
- Denosing AutoEncoder : input image를 최대한 똑같이 복원하되, input image에 random noise를 추가해 네트워크를 통과시키는 방식.
- Image Colorization : 1 color -> 3 colors 복원 task
- Context AutoEncoder : Input image에 missing patch를 부여해 이를 채우는 방식
- Split-Brain AutoEncoder : 이미지의 RGB channel을 쪼개서, 각각 다른 channle을 예측하도록 학습
다른 예시 사진은 아래와 같습니다(Context AutoEncoder Image Completion).
2. SSGAN(Self-supervised GAN)
Rotation-based 자기지도 학습
Rotated image를 원본 이미지로 만들 수 있게끔 각도를 예측하는 Classification Pretext Task 외에 GAN을 활용한 pretext task 방법도 존재하는데, 이것이 SSGAN입니다.
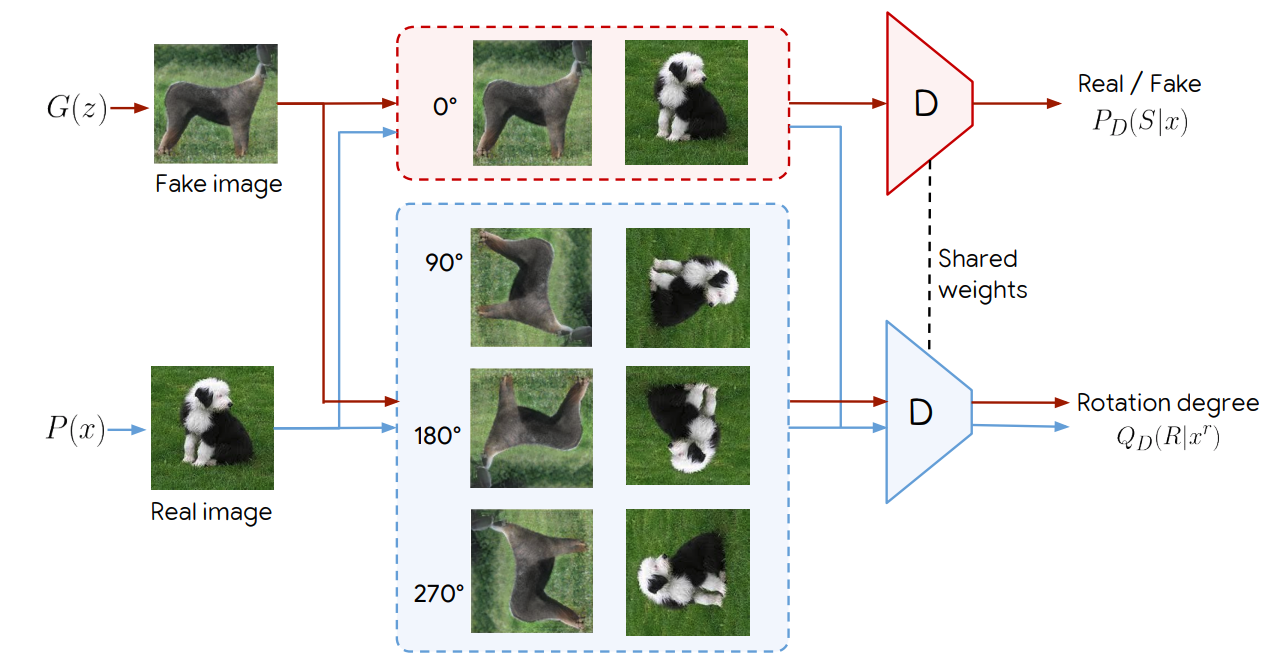
rotation-based SSGAN은 기본적으로 (1) 이미지의 진위 여부 판별와 (2) rotation degree 예측 task로 이루어져 있습니다.
Classificiation loss에는 회전되지 않은 이미지만 적용되고, Rotation loss에는 real image / fake image 모두 회전시킨 이미지가 적용됩니다.
그러면, 이런 방식으로 SSL을 적용한 Discriminator를 사용한다면 GAN에 비해 어떤 장점이 있을까요?
하나만 꼽자면 Discriminator Forgetting을 해결할 수 있습니다.
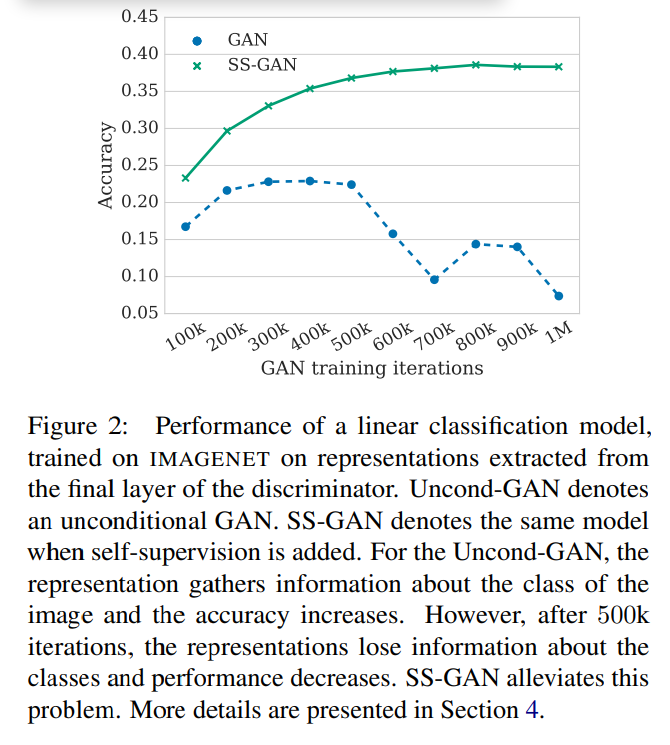
위는 사전학습시킨 Discriminator를 활용해 linear classfier를 추가한 뒤 ImageNet에 학습시킨 결과를 나타냅니다.
Uncontional GAN은 학습함에 따라 class에 대한 정보를 얻고, 정확도가 상승하다가 어느 순간부터는 class에 대한 정보를 잃고 성능이 감소하게 됩니다.
하지만, Self-supervised learning을 추가로 적용해 학습했던 모델을 활용한 SS-GAN의 경우 학습을 계속 하더라도 정보를 잃지 않는 현상을 볼 수 있습니다.
(훨씬 안정적이다).
