Self-supervised learning in Computer Vision
딥러닝 분야에서 data와 label은 빼놓을 수 없는 요소입니다.
라벨링 된 대용량 데이터를 기반으로한 딥러닝 모델들은 수 년간 엄청난 성능을 보이며 수 많은 성과를 보였습니다.
다만, 라벨링 된 데이터는 구하기 쉽지 않기 때문에, 수 년간 Unsupervised Learning, Few-Shot Learning, Reinforcement Learning 등 라벨이 필요 없거나 데이터가 적더라도 잘 작동할 수 있는 기법들이 많이 연구되어 왔습니다.
또한 기계가 인간의 인지능력을 따라 잡기 위해서는 '라벨링된 데이터로 학습된 고도의 통계 기계'라는 한계를 넘어 '스스로 판단할 수 있는 능력'을 갖춘 기계가 될 필요가 있습니다.
본 글에서는 이러한 딥러닝 모델의 한계를 보완하기 위해 라벨링 데이터를 필요로 하지 않는 Self-supervised learning에 대해 다루어보도록 하겠습니다.
Self-supervised learning?
인간의 아기는 세상을 관측하고, 행동하고, 피드백을 받아가며 세상의 상식을 학습하게 됩니다.
가령, 1~2장의 사슴 이미지를 보여준다면, 앉아 있는 사슴, 달리는 사슴, 해변가에 누워 있는 사슴 등 다양한 사슴 이미지를 판별할 수 있습니다.
기존의 Supervised-learning-based model들에게는 쉽지 않죠.
그냥 많은 데이터를 넣어 주어야 합니다.
In NLP
사실 SSL(Self Supervised Learning)은 보다 새로운 개념은 아니고, NLP분야에서는 널리 쓰이고 있는 개념입니다.
가령, BERT, GPT 등 large-scale dataset을 학습하는 모델들은 (라벨링이 필요 없는)수 많은 corpus를 학습하게 됩니다.
이를 통해 일반적으로 문장을 이해하는 기본 능력을 학습한 다음에는, 우리가 원하는 down stream task에 비교적 적은 양의 라벨링 데이터를 사용해 fine-tuning 해 좋은 성능을 뽑아낼 수 있습니다.
약간 구체적으로 말하면, NLP분야에서 위와 같은 SSL 모델은
'( )가 초원에서 풀을 먹고 있다'
라는 문장을 받아 ( )에 초식동물에 해당하는 동물이 들어오게끔 예측해가며 학습할 수 있습니다.
In CV
하지만, Computer Vision 분야에서는 이와 같은 태스크를 하기가 쉽지 않습니다.
이미지는 애초에 한 칸만 채우면 되는 문장과 다르게 많은 픽셀을 갖는 patch단위, 혹은 missing frame을 채우는 방식을 택했을 경우에 경우의 수가 너무 많기 때문이죠.
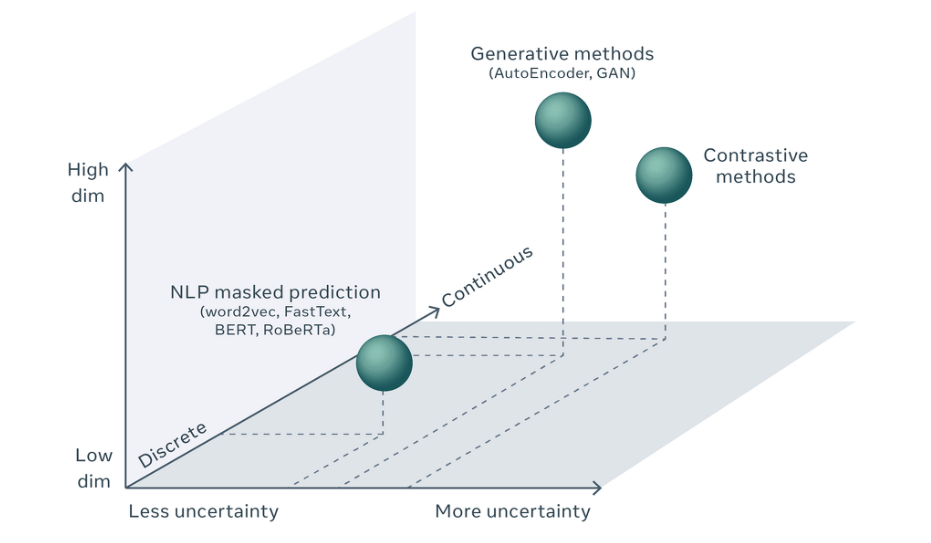
이렇듯 NLP분야와 CV분야의 차이는 Uncertainty, 그리고 Dimension으로 기술할 수 있습니다.
NLP분야에서 단어들의 집합은 discrete하기 때문에 빈 칸을 채우기 위해 단순히 Softmax를 통한 prediction이라는 간단한 classification task를 수행하면 됩니다.
하지만, CV분야에서는 픽셀 값들도 사실상 continuous일 뿐만 아니라, 그 픽셀 조차 상당히 많기 때문에 high dimensional continuous object라 할 수 있고, 경우의 수는 사실상 무한에 가깝습니다.
NLP가 probability distribution을 통해 단어를 고르는 방식으로는 missing part를 채울 수가 없겠죠.
아무튼 단순히 NLP 분야의 방법론을 CV에 적용할 수는 없었기에 Energy based model(EBM)을 사용해 SSL 방법론을 활용했다고 합니다.
(2017)Conditional iterative generation of images in latent space
Pretext Taks for SSL in CV(Pretrained on large-scale dataset)
그러면, Computer Vision 분야에서는 어떤 방식으로 SSL를 시도해왔는지 예시들을 살펴보도록 하겠습니다.
SSL 분야에서는 위에서 계속해서 다루었던 missing part task를 pretext Tasks라고 합니다. 즉, 구체적인 task에 적용하기 이전에 Unlabeled data를 활용해 모델의 능력을 향상
아래의 예시들은 블로그 https://hoya012.github.io/blog/Self-Supervised-Learning-Overview/ 의 예시들을 참고로 작성했습니다 !!
Context Prediction, 2015 ICCV
"Unsupervised Visual Representation Learning by Context Prediction"
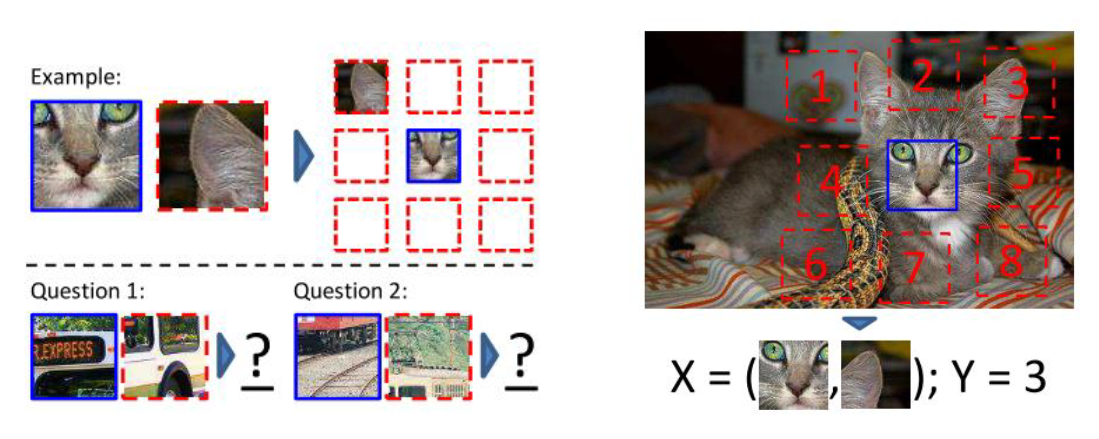
위의 그림에서 볼수있다시피 마치 퍼즐처럼 이미지 패치 간 상대적인 위치를 예측하는 태스크입니다.
즉, 하나의 패치를 가운데 패치라 가정하고, 나머지 패치의 위치를 Classify하는 태스크입니다(8-class classification).
저건 저도 못 풀겠습니다.
네트워크 구조는 아래와 같습니다(AlexNet 기반).

단순히 이미지를 patch로 딱 맞게 나눴을 경우에는 그냥 테두리 픽셀의 유사성을 보고 판단하는 문제(trivial solution)가 생길 수 있어서, 패치 간 gap을 추가하거나 각 패치의 위치를 약간씩 흩트려 놓는 trick을 사용했다고 합니다.
Jigsaw Puzzle, 2016 ECCV
”Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles”

이는 위의 Context pretext의 여러 한계(1,2번 픽셀이 비슷하다든지..)를 해결하기 위해 제안된 방법입니다.
즉, 패치들의 순서를 임의로 바꾸어 놓고, 다시 원본 이미지를 만들기 위한 permutation을 찾는 문제 입니다.
경우의 수가 으로 굉장히 많기 때문에 비슷한 순열은 제외한 뒤 100개의 순열만 이용하도록 조정해 100-class classification을 진행했습니다.
저자들이 제안한 아키텍처는 아래와 같습니다(Context-Free-Network).
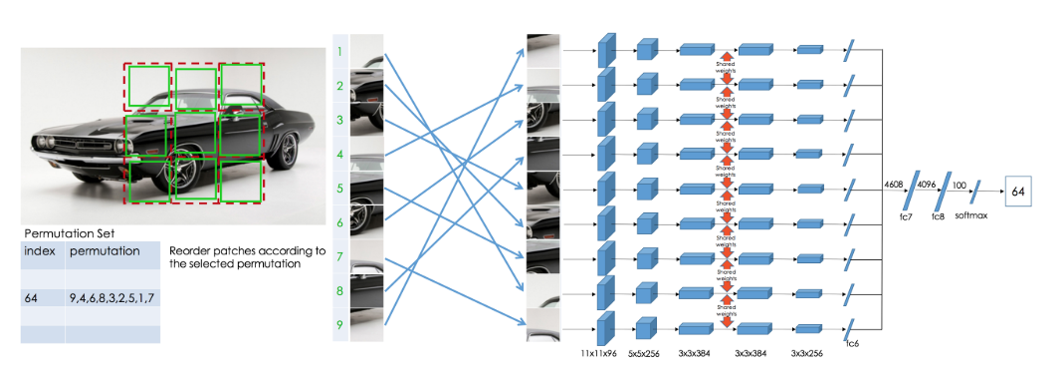
9장의 패치를 Input으로 받아 모든 Weight를 공유하는 Siamese Network 방식을 취합니다.
Count
”Representation Learning by Learning to Count”


Multi-task, 2017 ICCV
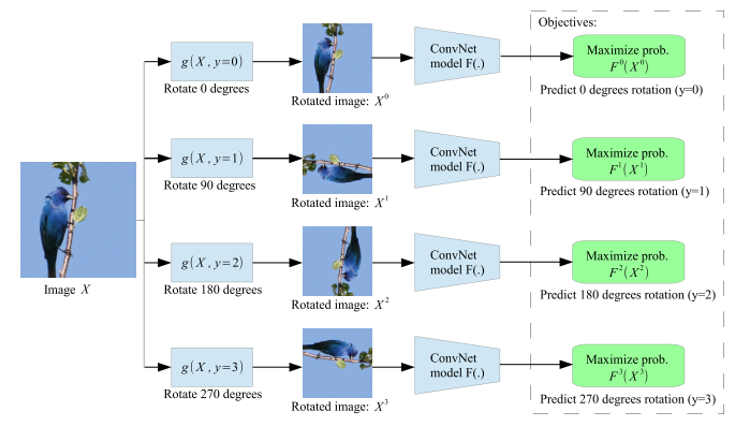
Rotation, 2018 ICLR
Down-stream Task Generalization(fine-tuned on specific dataset)
위에서 pretext tasks를 통해 (Unlabel로)사전학습시킨 모델을 (Labeled specific dataset)에 적용하는 과정입니다.
즉, 대규모 데이터에 비지도로 사전학습시킨 모델을 우리가 원하는 데이터 셋에 전이학습하는 과정입니다.
특히, 아래의 예시는 모두 ImageNet에 비지도 사전학습 시킨 모델입니다.
또한, 사전학습 모델의 효과를 파악하기 위해 Feature Extractor의 parameter는 모두 freeze한 뒤 classifier만 학습하게 됩니다.
ImageNet Classification
출처 : https://hoya012.github.io/blog/Self-Supervised-Learning-Overview/

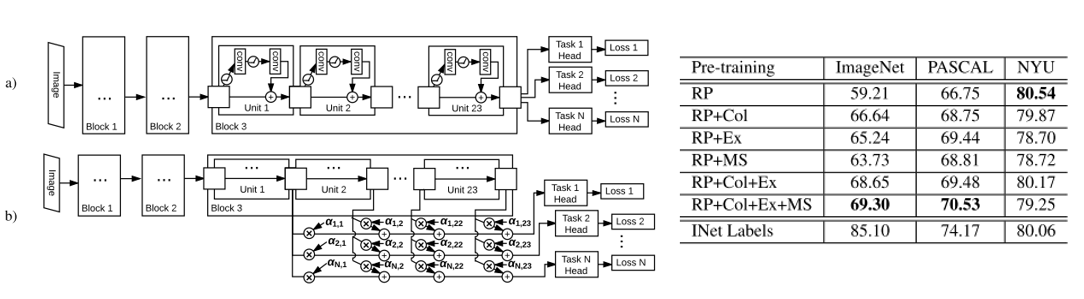
위의 표에서 첫번째 행은 ImageNet data에 Supervised learning을 적용한 다음, Convolution layer를 freeze하고 classification layer만 추가로 학습한 결과입니다.
Random(rescaled)는 convolution layer의 parameter를 임의로 초기화한 뒤 classification layer만 학습한 경우입니다(convolution의 역할은 사실상 x).
그 아래에는 SSL 방법론을 적용해 feature extractor(Convolution layer)의 사전학습된 성능만을 평가한 경우입니다.
PASCAL VOC - Classification, Detection, Segmentation

역시 ImageNet에 지도 학습을 한 경우가 성능이 가장 좋긴 했습니다.
보통 down-stream task에 적용할 때 ImageNet에 학습된 pre-trained model을 가져와 사용하는데, 이 경우가 위 표의 'ImageNet labels'에 해당한다고 볼 수 있습니다.
다만, 아래의 SSL 모델들도 ImageNet을 비지도로 학습했음에도 불구하고 나름 괜찮은 성능을 보이는 것을 알 수 있습니다.
Self-supervised Learning 관련 논문들 정리 : https://github.com/jason718/awesome-self-supervised-learning
