※ Text를 이용해 Image 내의 물체를 탐색하는 연구에 관해 정리한 글이다.
- Text(문장, 구, 절, 단어 등)과 Image를 input으로 받아 Output으로 Bounding box를 반환해주는 Text-Object-Detection 연구 중 실제로 적용할 수 있을 만한 paper & code
Keyword : Phrase object detection, referring to object in images, object detection using text(phrase, clause, sentence), phrase localization 등
1. Small talk about the VQA in Object Removal Task
단순히 삭제할 object에 해당하는 '단어'만을 input으로 받아 BOUNDING BOX로 변환하는 것은 다중 물체 삭제와 많은 영상 처리에 도움은 되겠지만 제대로 된 ‘문장’을 이해해 Bounding box로 변환하는 편이 훨씬 의미가 있을 것.
또한, 문장(또는 구)을 이해하는 Object removal 모델은 추후에 음성 인식 모델과 결합하여 human-centered AI를 구현하는 데 가능성을 열어줄 것.
하지만, 이를 위해 VQA라는 고도화된, 무거운 모델이 필요할까?라는 의문이 생겼음. 왜냐하면, 결국 지워야 될 ‘물체’만을 판단하면 되는 데 복잡한 문제를 풀어 정도의 고도화된 ‘추론’까지는 필요하지 않기 때문.
그럼에도 불구하고 실제로 Text를 사용하는 이상 의미 있는 task를 위해서 아래 문장을 이해할 정도의 성능은 필요하다고 생각되며, 이 정도의 성능을 보장하지 못 할 경우 VQA 모델을 수정해서 사용 할 가능성은 열어 두어야 한다고 생각
판단해야 할 문장 수준(?)
- 초록색을 입은 사람과 빨간색을 옷을 입은 사람의 구분
- 모자를 쓴 남자와 모자를 쓰지 않은 남자의 구분
- 남자와 여자의 구분
- 심판과 관객의 구분(Like the second paper listed below)
- 사진에 있는 사람들 중 모든 남자들과 여자의 구분
- 앉아있는 사람과 서있는 사람의 구분
- 하늘을 날라 다니는 새들과 바닥에 있는 비둘기 구분
(단, 문장은 명제 형식으로 주어져 어느 정도 참과 거짓을 따질 수 있어야 함(지울 object를 구체적으로 명시해주어야 한다). ‘밝은 옷을 입고 있는 남자’ → ‘밝은 파란색 옷을 입고 있는 남자 1명’ 등.. )
2. VQA for 'object detection using text'?
VQA 모델을 이용할 경우 장, 단점
장점
- 연구가 활발히 이루어지고 있는 분야로 성능이 좋은 모델을 다룬 논문 및 코드가 많을 것.
- 위와 같은 이유로 고도화된 문장 또한 이미지를 토대로 해석하는 능력이 좋을 것.
단점
- Phrase, Sentence를 받아 Bounding box로 변환하는 간단한 task가 아니라서, 코드 일부를 수정할 필요가 있음.
- Input 문장 형태
- Output 변경(answer à (중간 단계에서 쓰일) bounding-box or mask)
- 위와 같은 문제 등으로 빈대 잡는데 초가삼간을 다 태워버릴 수 있음.
3. Other detection model(using phrase, sentence, word, etc.)
이 모델들은 단순히 text(phrase, clause, sentence …)의 형태로 input을 받아 image를 이해한 후 bounding box를 반환하는 모델을 말함. 고도의 추론이 포함되지는 않기에 VQA보다는 간단한 모델이라고 생각함.
1. Phrase Localization Without Paired Training Examples
Phrase Localization Without Paired Training Examples | Semantic Scholar



Benchmark
Text to Bounding box : O
문장 이해 : O, 다만 성능은 보장 x.
- 단, 실행 code가 없음(Evaluation만 존재)
- 활용하긴 힘들듯.
Code
GitHub - josiahwang/phraseloceval: Phrase Localization Evaluation Toolkit
참고로, 해당 논문에는 GitHub - lichengunc/refer: Referring Expression Datasets API 에 나와있는 text<->bounding box data를 test set으로 활용한 듯. 후자의 github의 경우 아래 논문들을 참고했다(큰 활용은 x).
Kazemzadeh, Sahar, et al. "ReferItGame: Referring to Objects in Photographs of Natural Scenes." EMNLP 2014.
Yu, Licheng, et al. "Modeling Context in Referring Expressions." ECCV 2016.
2. Phrase Localization and Visual Relationship Detection with Comprehensive Image-Language Cues


Benchmark
Sentence to Bounding box : O
문장 이해 : O (성능도 좋은듯)
- 문장에서 단어간 관계를 이해해 bounding box를 쳐주는 모델.
- NLP + Object detection(Faster-R-CNN) 등을 이용함
- 근데 코드가 Matlab 기반(저런)
Code
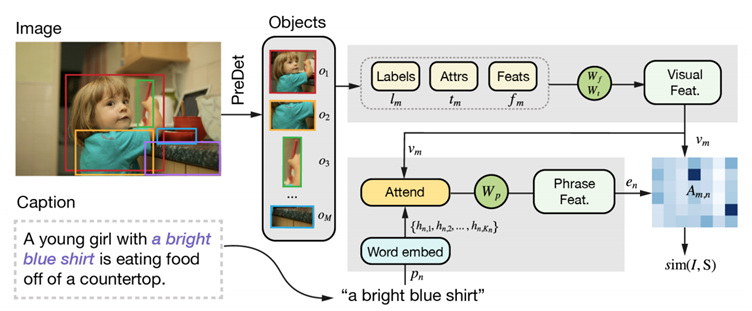
3. MAF: Multimodal Alignment Framework for Weakly-Supervised Phrase Grounding (중요)
MAF: Multimodal Alignment Framework for Weakly-Supervised Phrase Grounding (aclweb.org)

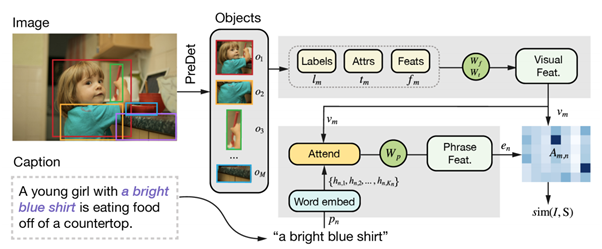
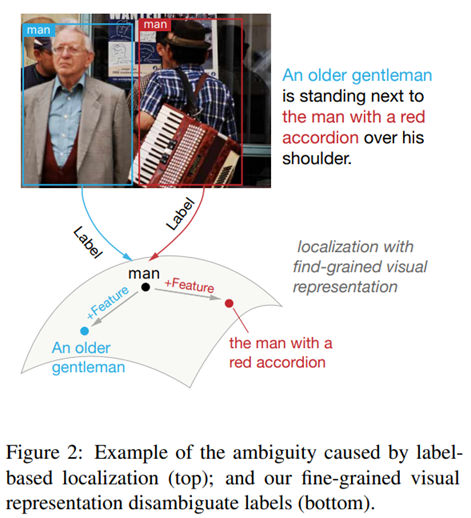
Benchmark
Sentence to bounding box : O
문장 이해 : O
실행 코드 있음 : python 3.7, pytorch 1.4.0
가장 실현 가능한 연구. 단, 물체를 지우기 위해선 input 문장으로 절이 아니라 구(phrase)를 받아야 하기 때문에(ex; “여자 오른쪽에 있는 파란색 ‘공’”) 이에 대해 bounding box가 제대로 쳐질 지는 판단이 필요할 듯. 다만, bounding box가 제대로 쳐지지 않은 경우 다시 손으로 manual하게 고칠 수 있기 때문에 적당한 성능만 보장하면 될 듯.
Code
Multimodal-Alignment-Framework/model.py at public · qinzzz/Multimodal-Alignment-Framework · GitHub
4. Zero-Shot Object Detection with Textual Descriptions (researchgate.net)
Zero-shot을 적용한 논문이나, task에 맞지는 않을듯 하다.
결론
- 위 연구들 내에 문장의 추론에 있어서 Object detection과 관련된 아키텍처가 어떻게 구축되어 있는 지 간단히 살펴보아야 할 듯
