Visual Question Answering using Deep Learning: A Survey and Performance Analysis
Multimodal Deep Learning
Paper: https://arxiv.org/pdf/1909.01860.pdf
This paper is accepted in Fifth IAPR International Conference on Computer Vision and Image
Processing (CVIP), 2020

0. Abstract
VQA는 주어진 이미지를 토대로 질문에 대답하는 태스크입니다.
Visual 정보와 Linkguistic(언어적) 정보를 통합해 이해해야 하기 때문에 쉽지만은 않은 태스크입니다.
구체적으로는 이미지 내 요소들과 주어진 질문의 추론을 통해 올바른 답을 도출해야 합니다.
본 서베이 논문에서 다루고자 하는 바는 아래와 같습니다.
- 다양한 VQA datasets
- 성능이 좋은 Deep learning models
- Vanilla VQA model
- Stacked Attention Network(VQA Challenge 2017 Winner)
- detailed analysis & futer directions
1. Introduction
VQA는 이미지를 기반으로 주어진 질문에 대답하는 task로, 대답은 아래와 같은 형태로 제시될 수 있습니다.
- 단어, 문장, 양자택일, 단답형, 빈칸 채우기
VQA 분야에서는 Agarwal et al 2015년에 컴퓨터 비전 분야와 자연어 처리 분야를 통합하는 새로운 방법을 제안해, Visual Grounded Dialogue, 즉 인간이 시각적 & 언어적 정보를 활용해 환경을 이해하는 방법을 모사하는 시스템을 구축하는데 기여했습니다.
이후, 딥러닝이 발전하면서 컴퓨터 비전 분야 쪽에서도 AlextNet, VGGNet, Inception, ResNet 등 아주 성능이 좋은 CNN 기반 모델들이 좋은 모습을 보여주었습니다.
마찬가지로, 자연어 처리 분야에서도 RNN, LSTM, GRU 등의 순차적 시계열 모델이 발전하면서 해당 모델들을 기반으로 많은 연구가 이루어졌습니다.
VQA모델의 원형, 즉 Vanilla VQA 모델에는 주로 위에서 언급했던 VGGNet과 LSTM의 결합으로 이루어졌습니다.
이런 모델들이 몇년 동안 발전했고, 아래와 같이 새로운 아키텍처와 새로운 수학적 공식을 사용한 모델들이 많이 제안됐습니다.
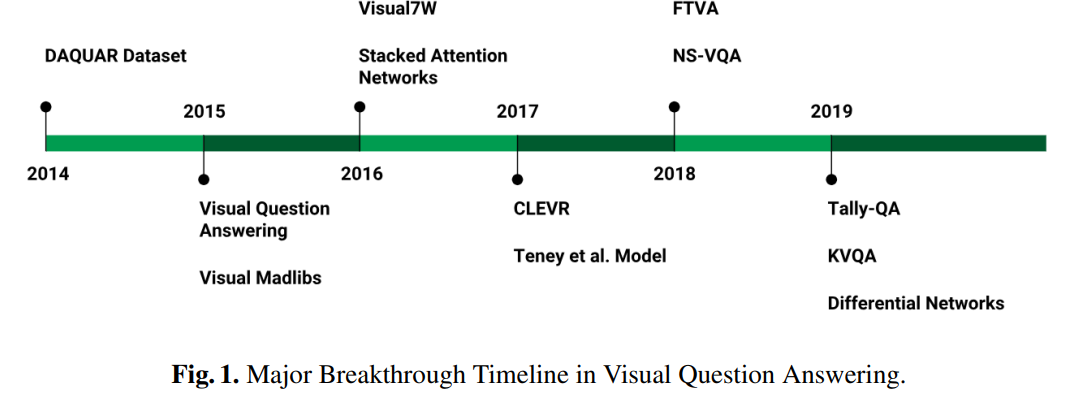
동시에 편향을 줄이고 모델의 성능을 높히기 위한 좋은 데이터셋 또한 열심히 마련하려 노력했다고 합니다.
이제 최근 모델들에 대한 얘기를 해봅시다.
2020년에는 Li, et al이 'context-aware knowledge aggregation을 사용해 VQA의 성능을 많이 끌어 올렸습니다.
같은 년도엔 Yu et al이 'cross-modal knowledge reasoning'을 수행하는 지식 기반 VQA를 제안했습니다.
Chen et al은 학습할 때 Counterfactual sample*을 합성함으로써 VQA 모델의 견고함(Robustness**)를 개선했습니다.
*Counterfactual sample (Synthesis)
위의 그림으로 바로 이해할 수 있습니다 ^_^

또한, 그래프 개념을 활용해 relational information을 증가시키는 기법 또한 존재합니다(Huang et al).
본격적으로 VQA에 대해서 다룰텐데, 크게 Dataset, State-of-the-art model, 그리고 computational analysis를 다루도록 하겠습니다.
Computational Analysis
- vanilla VQA
- Stacked Attention Network (SAN)
- Tesney's Model(Tips and tricks for visual question answering)
단, Datset은 그냥 패스 ^^..
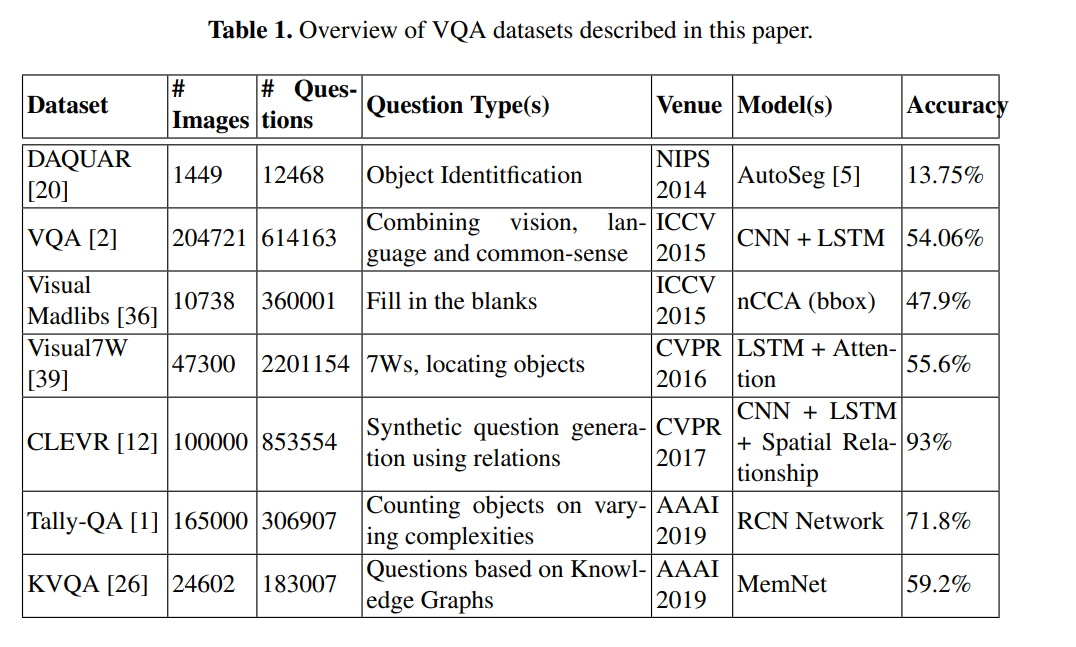
2. Dataset




3. Deep Learning Based VQA Methods
모두가 알다시피 요즘 VQA 분야는 사실상 딥러닝 모델이 장악하고 있습니다.
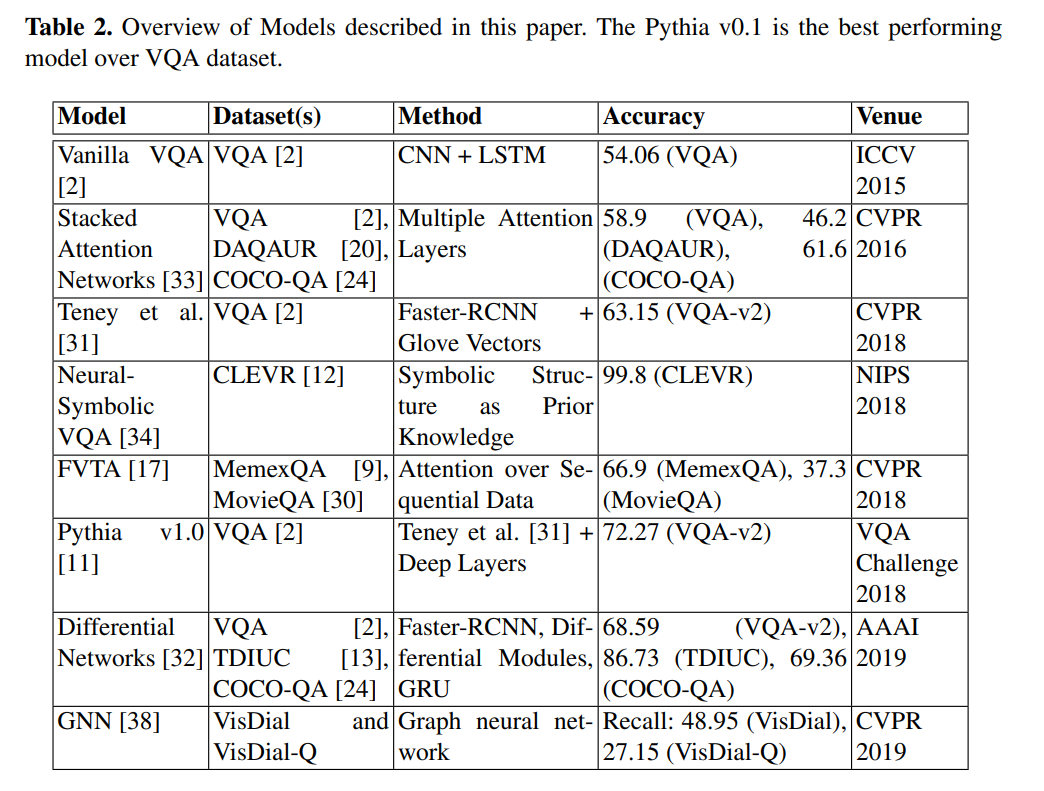
저자들은 본 단락에서 아래의 테이블에 존재하는 State-of-the-art methods에 대해서 다룹니다.
Vanilla VQA
Vanilla VQA는 위에서 말했듯 CNN을 통해 얻은 feature와 LSTM(or RNN)을 이용해 얻은 feature를 element-wise operation을 통해 통합한 후 답변들 중 하나를 분류하는 데 쓰입니다.
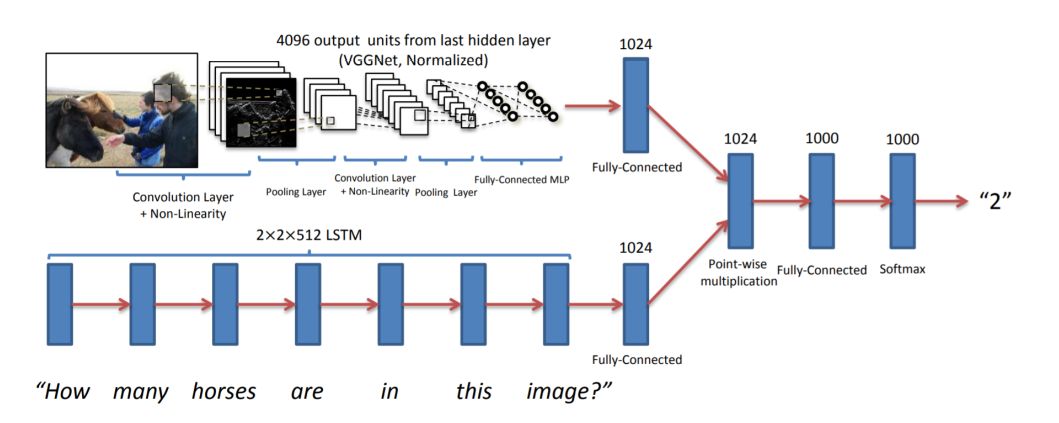
마지막의 1000개는 적절히 정해진 대답들이겠죠.
Stacked Attention Network
해당 모델은 Intermediate question feature의 소프트맥스 output을 활용해 Attention을 도입합니다.
이런 features간 attention은 쌓여서 이미지의 중요한 부분을 포커싱하게 됩니다.
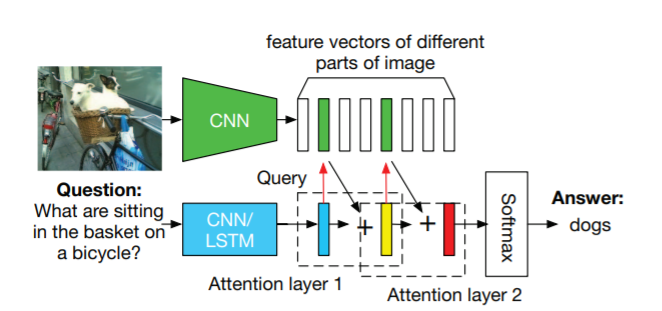
[Stacked Attention Networks for Image Question Answering](https://ieeexplore.ieee.org/document/7780379
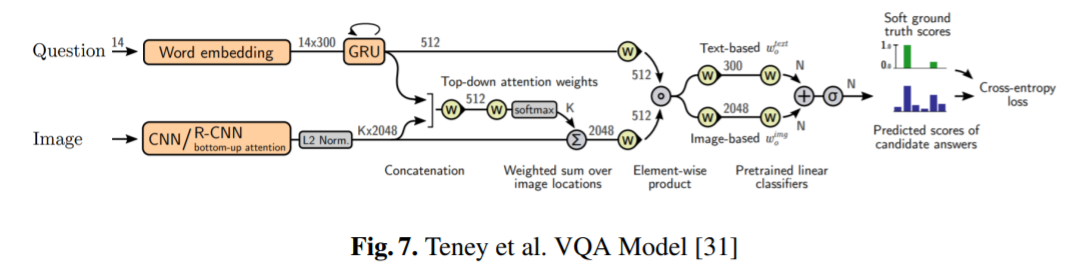
Teney et al. Model
Teney et al의 모델은 object detection을 활용한, VQA Challenge 2017에서 우승한 모델입니다.
해당 모델은 features의 특징을 좁혀 이미지에 대한 더 좋은 attention을 적용하게 됩니다.
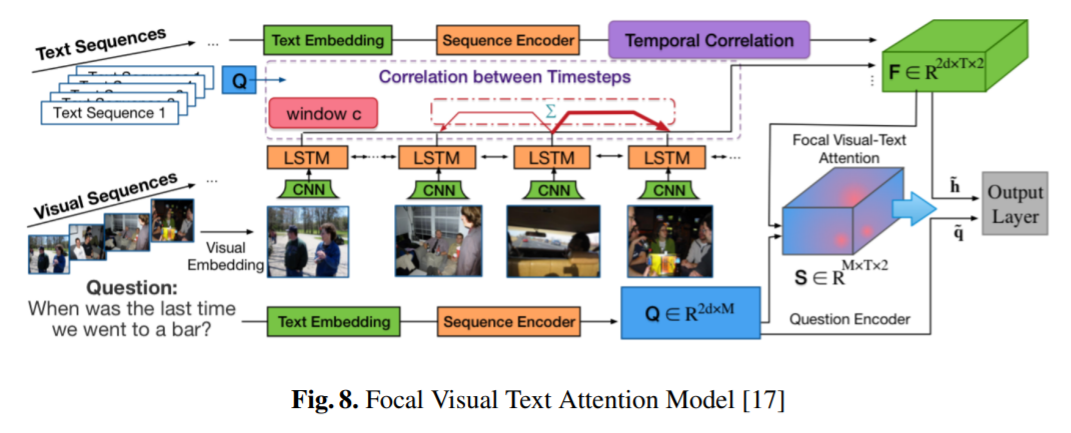
Focal Visual Text Attention (FVTA)
해당 모델은 quesion, image의 Text features, 그리고 image features의 ㅍVisual sequence를 결합합니다.
두 텍스트 요소를 기반으로 attention을 적용해, 최종적으로 features를 분류해 문제에 답을 내립니다.
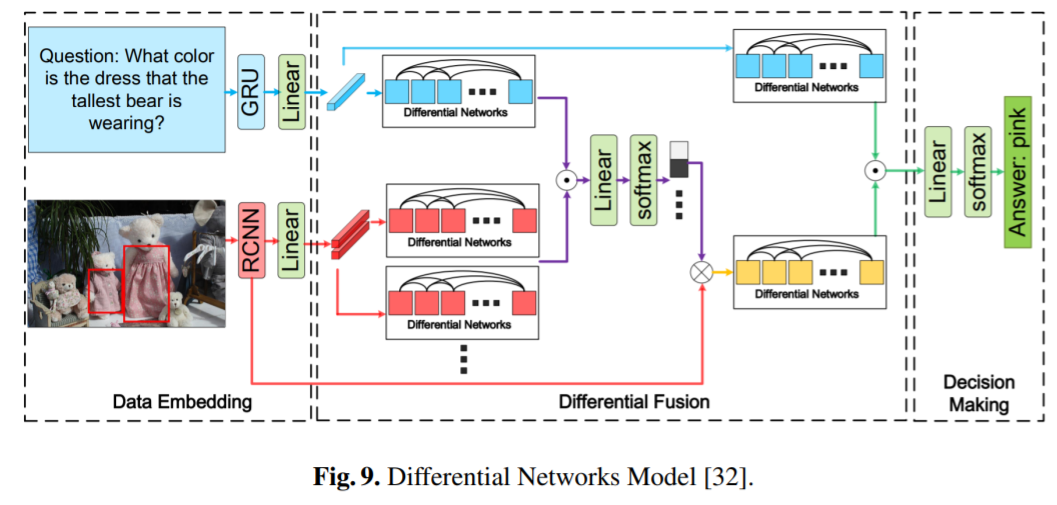
Differential Networks
해당 모델은 forward propagation step간 차이를 이용해, 노이즈를 줄이고 features 간 interdependency를 학습하게 됩니다.
Image features는 Faster-RCNN을 활용해 추출되구요.
4. Experimental Results and Analysis
위에서 기술한 여러 방법, 그리고 여러 데이터 셋에 대한 성능은 아래 테이블이 보여줍니다.
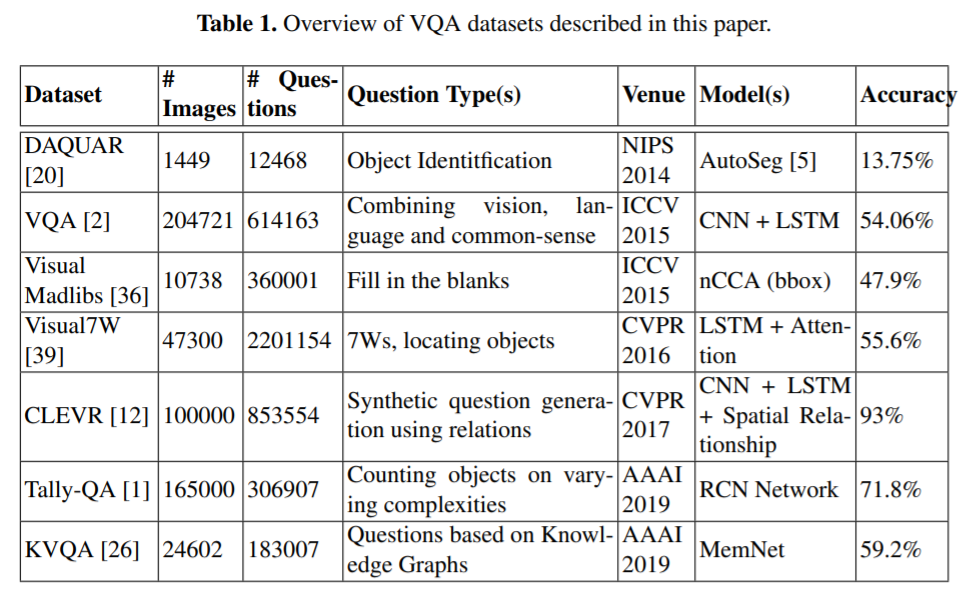
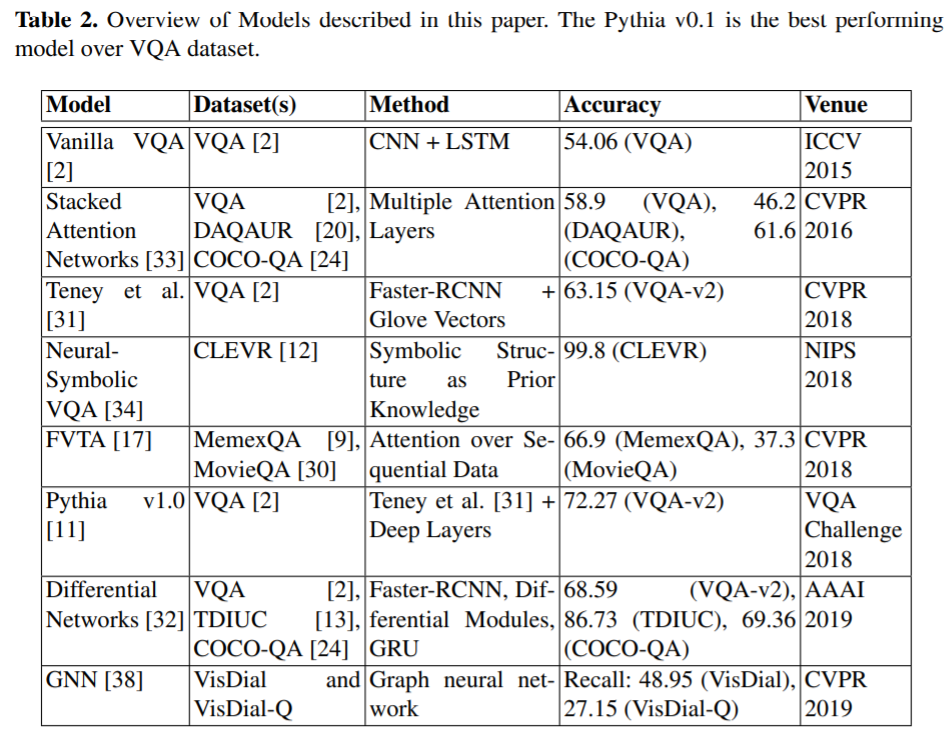
위에서 볼 수 있다시피 VQA Dataset이 꽤나 보편적으로 사용된 데이터 셋이었고, Visual7W, Tally-QA, KVQA같은 데이터셋은 꽤나 어려운 최신의 데이터 셋이라는 걸 볼 수 있습니다.
Pythia v1.0이 VQA dataset에는 Sota를 기록하고 있으며, Differential Network 또한 보편적으로 뛰어난 성능을 보이고 있습니다.
해당 서베이 논문의 저자들은 Vanilla VQA, Stacked Attention Networks, Teney et al 3개의 모델에 대해 성능 평가도 진행했습니다.
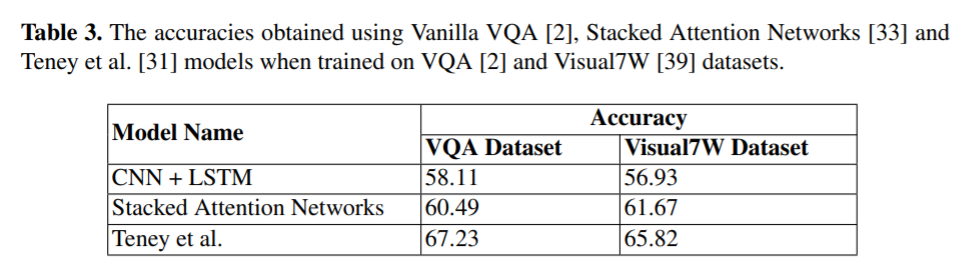
보다시피 2017년 모델인 Teney et al의 모델이 성능이 가장 좋았으며, 특히 2018년 VQA 대회에서도 Teney et al 모델을 베이스로 사용한 Pythia v1.0이 우승했습니다.
5. Conclusion
Visual Question Answering task는 최근 더 더욱 실생활에 가까운, 굉장히 어려운 데이터 셋의 개발과 모델의 개발로 인해 활발하게 연구되고 있는 분야입니다.
특히, 텍스트 단서 뿐만 아니라 시각적 단서 또한 활용해 더더욱 정교한 딥러닝 모델을 만들고 있습니다.
다만, 여전히 훌륭한 모델 조차 60-70%의 성능을 보이고 있어 앞으로도 더욱 좋은 딥러닝 모델의 개발이 필요해 보입니다.
추후 VQA model의 개발을 위해 object level의 디테일, segmentation mask, deeper model(larger model), sentiment(of the question) 등 다양한 요소가 고려될 필요가 있습니다.
