[간단정리]Revisiting Model Stitching to Compare Neural Representations(NIPS 2021)
Paper:(https://arxiv.org/pdf/2106.07682.pdf)
- paper accpted on NIPS 2021
- 모델 간의 Representation을 비교하는 방법으로 Model Stiching을 제안
- 이 분야에서 자주 쓰이는 CKA 등 보다 나은 부분이 있다고 주장하는 연구.
- 이를 통해 아래와 같이 Representation 관련한 직관적인 가설 2가지를 검증함
- 좋은 모델은 비슷한 represenation을 학습한다.
- 다른 방식으로, 다른 하이퍼파라미터로 학습할지언정 성능이 비슷하다면 결국 represenation도 비슷.
- 많을 수록 좋다(more is better).
- 더 많은 데이터, 더 넓은 width(+더 많은 파라미터), 더 긴 학습을 진행한 모델은 더 좋은 represenation을 학습한다.
- 더 좋은 represenation : 더 좋은 모델의 representation을 사용해 약한 모델의 성능을 개선할 수 있다면 좋은 represenation을 학습했다고 봐도 무방.
- 그 외에도 SGD로 학습한 많은 local minima는 (큰 성능 저하 없이) model stitching으로 엮을 수 있다는, Stitching connectivity 가설을 검증함.
- 현존하는 딥러닝 모델은 대부분 task/loss를 정하고 학습하는 End-to-End 방식으로 학습함.
- 그럼에도 불구하고 모델은 자동적으로 richer represenation을 학습하게 되고, 이게 딥러닝 기반 모델의 부흥을 일으킨 주된 이유 중 하나임.
- 따로 intermediate layer에 "이런 represenation을 배워라!"라는 제약을 주는 것도 아님에도, 더 낮은 loss를 위해 학습해가면서, 더 좋은 represenation을 배우게 된다는 것.
- 다만 이런 representation가 어떻게 만들어지는지는 아직 불분명.
- 뿐만 아니라 다양한 representation간에 관계성도 공식화하기 힘듬.
잠시 딥러닝 모델 학습에 있어서 극단적인 두 가지 예시를 보자.
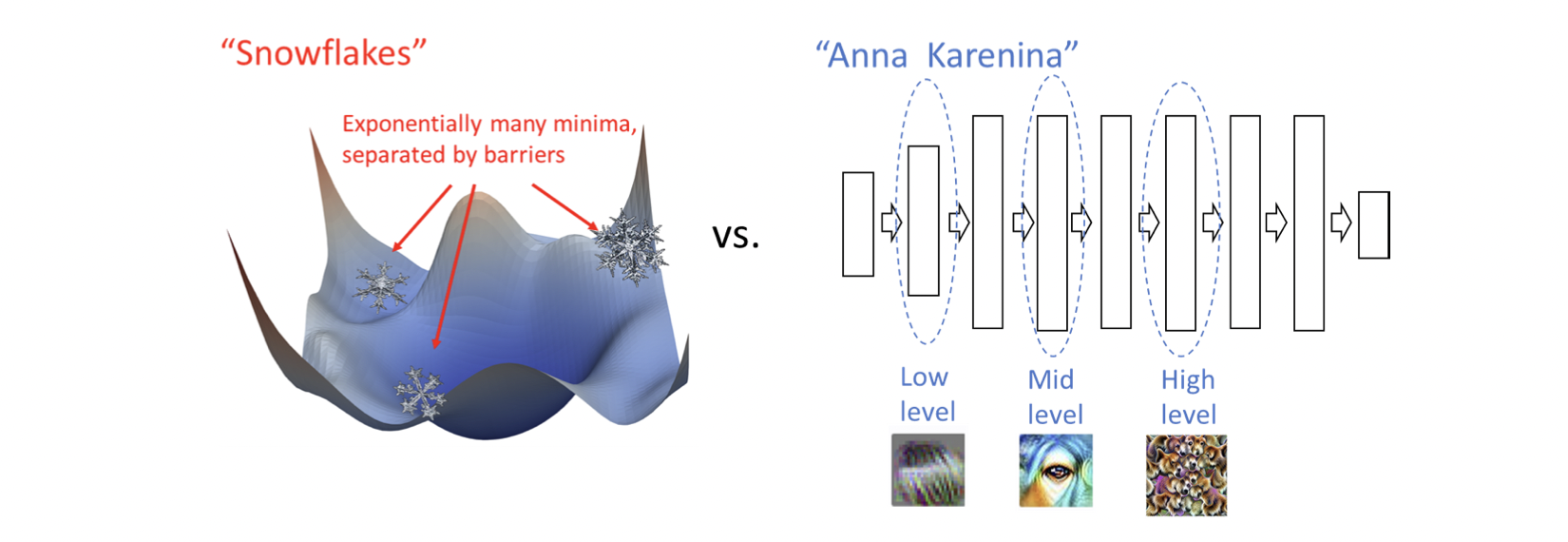
- 좌측의 Snowflakes : 성능이 비슷할지라도 빠지는 local minima에 따라 매우 다른 특징을 지님.
- 즉, 모델/데이터/옵티마이저 등이 같고, 단지 initial point만 다르더라도, 다른 local minima에 빠질 것이고, 모델은 결국 다른 특징을 지니게 된다는 것.
- 모델 구조까지 다르다면 이런 차이가 더 극심해질 것.
- 우측의 Anna Karenina : 결국 성능이 잘 나오는 모델이라면 모두 비슷한 represenation을 가지게 될것
- 즉, 학습을 더 오래하든, 데이터를 더 많이 넣어주든, 더 큰 모델을 쓰든, 단지 좋은 curve detector를 가질뿐, 이런 좋은 모델들 사이에는 큰 특징 차이가 없음.
- 가령, 낮고 완만한 loss curve를 찾는다면, 그냥 그게 좋은 모델들이고, 나쁜 모델들은 높고 급격한 안 좋은 loss curve를 찾을 것.
- 즉, 학습을 더 오래하든, 데이터를 더 많이 넣어주든, 더 큰 모델을 쓰든, 단지 좋은 curve detector를 가질뿐, 이런 좋은 모델들 사이에는 큰 특징 차이가 없음.
아무래도 요즘 연구들은 후자(Anna Karennia)의 상황을 지지하는 것 같음. 세부적으로 local minima를 잘 찾는다거나, 더 좋은 represenation을 구한다거나, 모델의 구조를 일부 바꾼다거나 하는 것보다 그저 성능을 높힐 방법(더 큰 모델, 더 많은 데이터, 더 많은 연산, ...)만 찾는다면 이 모델들은 모두 좋은 represenation을 배울 것이라는 그런 가설..?
본 연구에서는 더 좋은 represenation, 비슷한 representation을 가지는 것을 증명하기 위해 두 모델의 top / bottom layer를 연결하는 model stitching을 사용하는 것뿐.
(그리 뭐 새롭고 놀라운 딥러닝 모델의 성질을 찾은 건 아니고, 그냥 검증하는 방법 정도)
이와 별개로, Anna Karenina는 톨스토이의 소설이다.
아마 "행복한 가정들은 모두 비슷한 이유로 행복하다. 다만 불행한 가정들은 각자 다채로운 이유로 불행하다" 라는 식의 구절이 있는듯.
아래는 딥러닝에서 널리 (요즘들어) 통용되는 두 가설을 model-stitching을 통해 검증한 그림
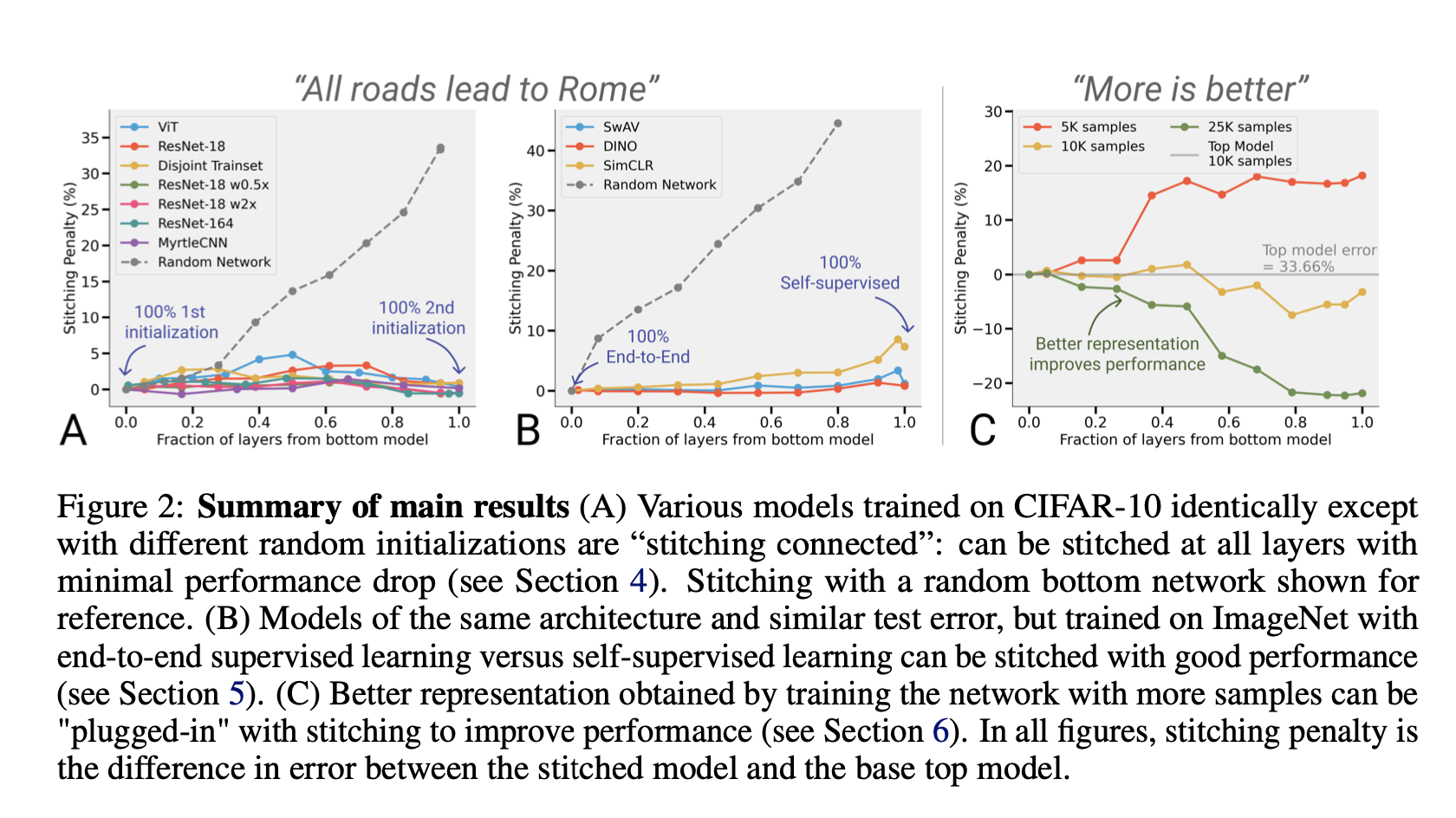
- 회색 점선은 대조군이다.
Model stiching에 대해서 설명하자면, 그냥 두 모델을 차례대로 이은 것이다.
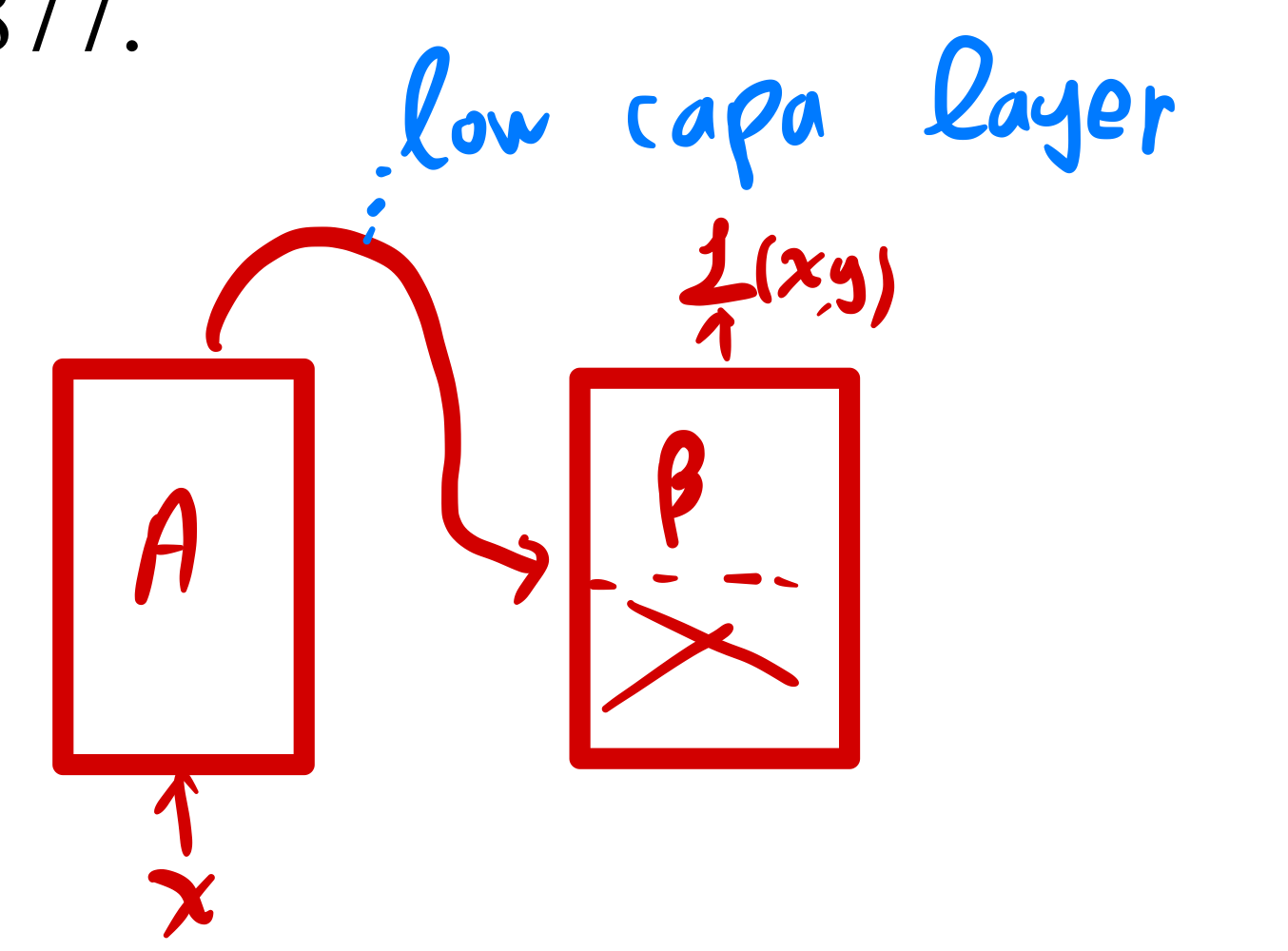
-
최종적인 모델 성능에 영향을 주지 않을 만큼의 low capacity model(layer)로 두 모델을 이어주는 것.
- A 모델의 represenation이 B 모델의 것보다 좋다면, 최종적인 B모델의 예측 loss()는 좋아질 것(좋은 represenation!)
- 만약 두 모델의 represenation이 비슷하다면, 최종적인 B모델의 예측 loss()는 크게 변하지 않을 것(비슷한 represenation!).
-
즉, represenation 간 관계성을 기술할 수 있다.
-
이를 위해 layer로 연결해주지 않고 A의 represenation만 B의 input으로 그대로 넣어준다면 제대로 작동하지 않는다거나, stiching layer의 capacity나 layer 종류를 어떻게 해주어야 한다거나하는 이론/실험들을 전개함.

- Representation Similarity 방법 중 가장 유명한 CKA(Kornblith et al., 2019)와의 비교
그 외에도 유익한 내용은 많다.
하지만, 개인적으로 Represenation 간의 관계성, 유사성, 좋고 그름을 따지는 주된 이유중 하나는 "딥러닝 모델이 데이터로부터 어떻게 representation을 학습하는지 이해하는 것"이라고 생각한다.
하지만 이 representation 비교/평가를 위해 다시금 딥러닝 모델을 이용한다는 것은, 직관적이고 타당할지언정, 근본적인 "딥러닝 모델에서의 represenation"에 대한 이해에는 크게 도움이 안 되는듯.
(이를 위한 논문은 아니긴 해도)
