Reinforcement Learning은 어디에 속할까?
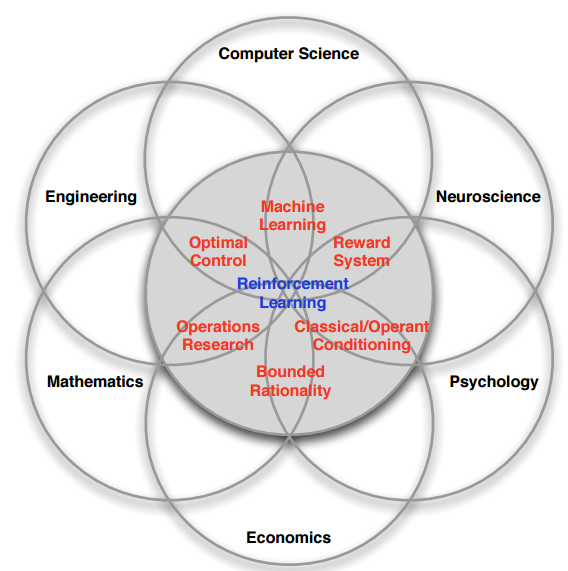
- 각 원들이 무엇을 뜻하는지.
우리에게 익숙한, 머신러닝(혹은 딥러닝)을 중심으로 살펴보자.
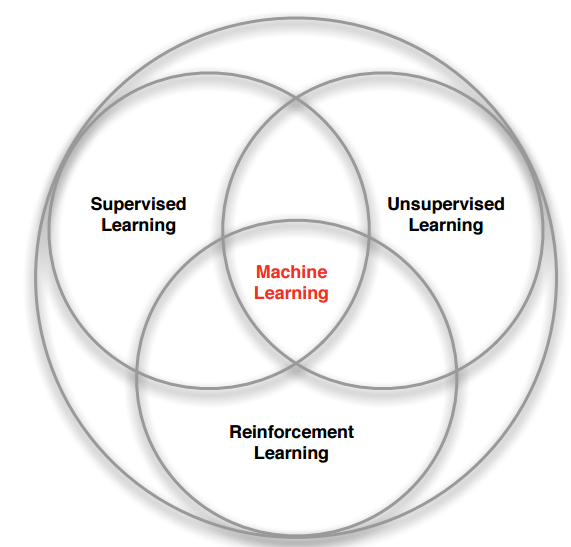
우리가 알다시피, 그리고 위의 그림처럼, 머신러닝은 항상 제일 넓은 범주를 가진다 할 수 있다. 이 중, 강화학습은 지도학습(Supervised), 비지도학습(Unsupervised), 또한 준지도학습(Semi-supervised)과는 완전히 다른 방법론이라 할 수 있다.
강화학습의 특징
그렇다면, 강화학습이 다른 머신러닝 방법론들과 어떤 측면에서 다를까?
- supervisor가 없고, 오직 reward로만 작동한다. 즉, 정답을 제공하지 않는다.
- Feedback은 딜레이될 수 있다. 즉, action에 대한 reward가 즉각적으로 주어지지만은 않는다.
- 어떤 action이 최종 reward에 어떤 영향을 줬는지 파악하기 쉽지 않다.
- Time이 굉장히 중요하다. 독립적으로 사건을 뽑는 게 아닌(not i.i.d.), 과거가 현재에(그리고 미래에) 영향을 끼치는 sequence로 바라본다.
- Agent의 action이 다음 데이터에 영향을 준다.
- 기존의 지도/비지도 학습은 정해진 데이터셋(답)을 받지만, RL은 action에 따라 매번 받을 데이터가 달라진다(유동적이다).
강화학습의 예시

위처럼 보드게임, 투자 포트폴리오, 로봇, 아타리 게임 등에 쓰일 수 있다.
강화학습이란?
- 강화학습에서 용어는 굉장히 중요한 부분이다.
Reward
reward 는 특정 시점 에서 주어지는 scalar feedback signal이다. 즉, agent가 step 에서 얼마나 잘 작동하는 지를 나타내는 지표이며, agent의 임무는 cumulative(누적) reward를 최대화하는 것이다.
Reinforcement Learning은 일반적으로 reward hypothesis를 기반으로 한다.

강화학습에서 모든 목표는 누적 리워드를 최대화하는 것으로 기술될 수 있(어야한)다.
ex) 로봇을 잘 걷게 하려면, 넘어졌을 때 -5 reward, 1초 잘 걸었을 때 +1 reward... 이처럼 scalar feedback을 부여함으로써, 가장 높은 reward를 성취할 수 있게끔.
다만, 일반적으로 목적을 scalar로 표현할 수 있을까? 아니라면, 어떻게 scalar로 치환해야할까? 가령 예술 분야에서 [완성도, 창의성, ...]을 목표로 하고 싶다면?
Examples of Rewards

Sequential Decision Making
- 강화학습은, 위에서 말했던 것처럼, 순차적인 actions이 아주 중요하다.
- 즉, '한 순간'만 action을 잘 해서는 안 된다.
- 또한, '미래'에도 좋은 결과를 가져와야 한다.

아무튼, 최종적인 목표는 '미래의 reward'를 최대화 해야 한다.
이 과정에서, 한 순간의 action은 분명 장기적인 결과에도 영향을 끼칠 것이며, 그렇기에 reward는 딜레이된다고 볼 수 있다.
즉, 즉각적인 reward를 위해 달리는 게 좋을 수도, 미래의 reward를 위해 즉각적인 reward를 포기하는 게 좋을 수도 있다는 것이다.
Agent and Environment
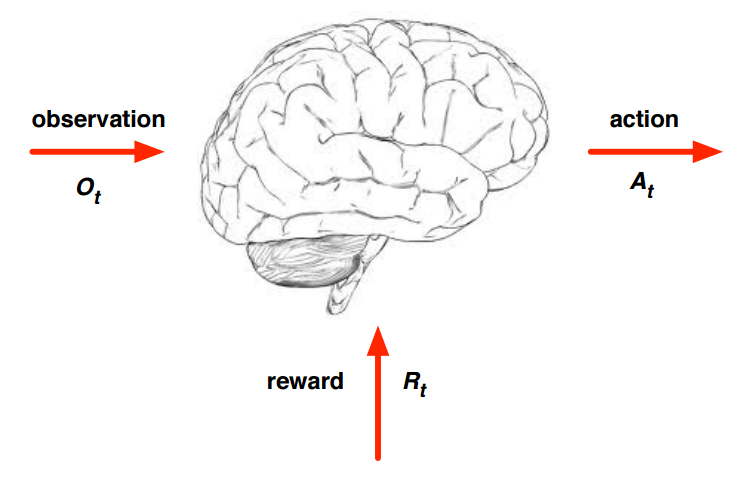
Agent: 특정 목표를 위해 action을 수행하는 주체
Environment: Agent가 작동하는, 외부의 환경
이를 포함한 그림은 아래와 같다.
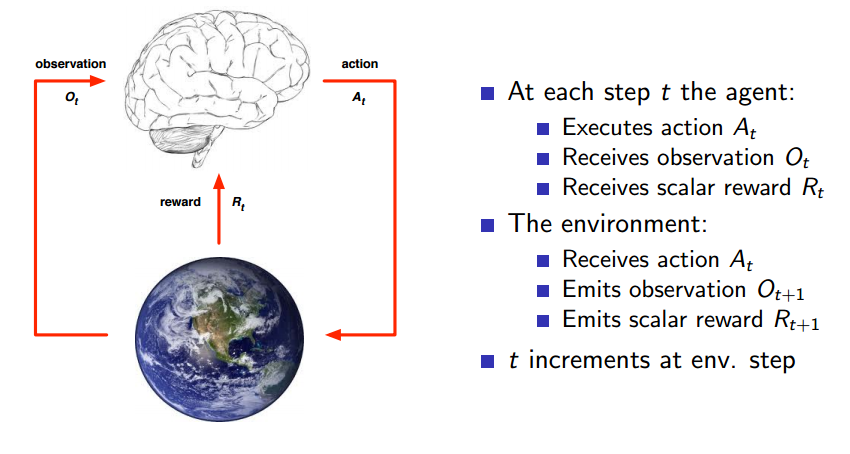
즉, agent가 action을 수행하면, environment는 그에 따른 reward와 새로운 observation을 제공한다.
위에서 observation이란, agent가 보는 '화면' 정도로 생각하면 될 듯 하다.
History and State

History: O, R, A, O, R, A ... 처럼 Agent와 Environment의 상호작용들.
잘 안 쓰인다. 그냥 그러려니 하면 된다.
State: 다음에 어떤 action을 할 지 결정하는 데 필요한 정보다.
즉, Agent도 어떤 숫자들을 토대로 action을 결정할 것이고, Environment도 어떤 숫자들을 토대로 Observation과 Reward를 결정할 것이다. 이들이 참고하는 게 state
이 때, History는 과거이고, state는 현 상황이므로, history에 의해 state가 결정되는 함수 형태로 볼 수 있다.
Environment State
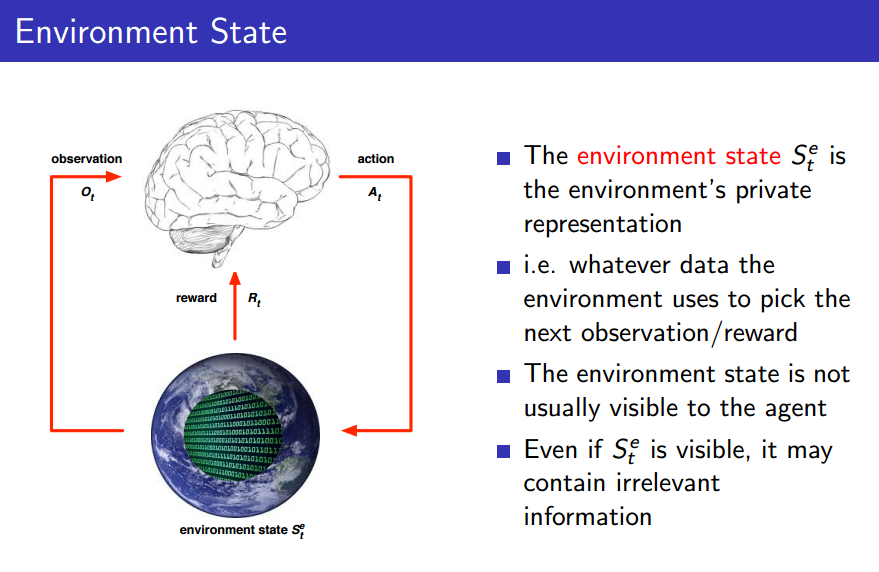
Environment는 와 를 반환하는데, 이 때 environment state 를 참고로 제공한다. Agent에게는 필요없는 정보들이 많을 것이므로 보통 agent는 를 보지는 않는다. 보여도 필요 없을 확률이 크다.
If in Atari?
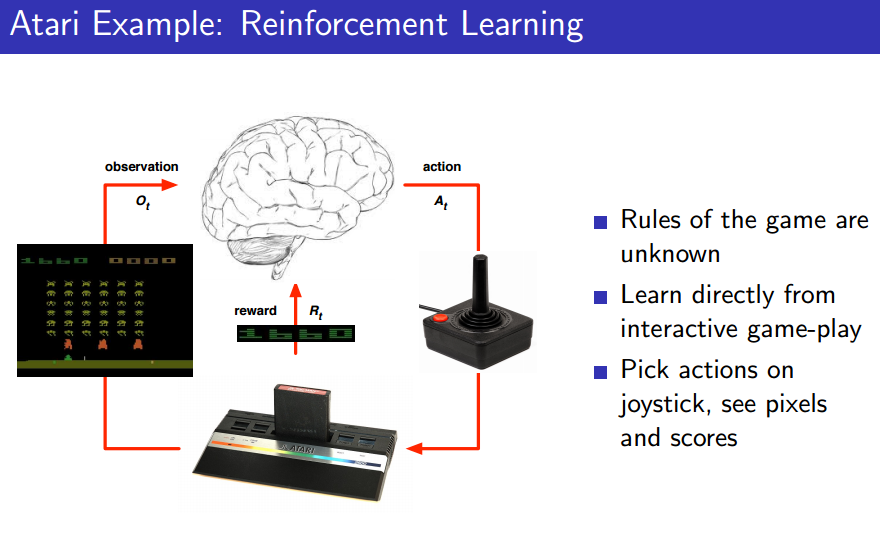
1024 bit(?)라면, 1024개의 숫자로 이루어진 정보들은 내 위치, 적의 위치, 총알의 데미지, 적의 체력, 총알의 속도 등을 담고 있을 것이다. 이런 숫자들을 Environment State로 여길 수 있다.
그러니, 보통 우리는 Observation만 필요할 뿐 그런 세부적인 정보(컴퓨터니까 숫자)들을 필요로 하지는 않을 것.
Agent State
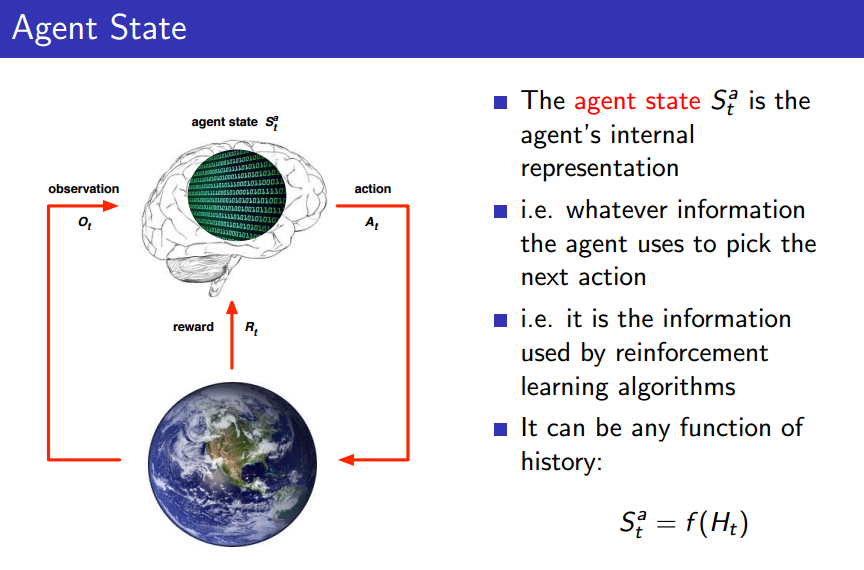
Agent state 는 agent가 다음 action을 하는데 쓰이는 정보들이다. 즉, RL 알고리즘에 딸려가 쓰이는 정보라 볼 수 있다.
가령, 주식이라면 저번 분기의 순수익, 수익률, 매출, 거래량 등을 Agent state로 참고할 수 있을 것이다.
특히나 Environment state와 다르게, Agent state는 History만을 골라보면 되기 때문에 History에 대한 함수로 볼 수 있다.
Information State(Markov state)
State를 다른 관점에서 살펴보자.

(식은 굉장히 쉽다. timestep을 모두 날려버릴 수 있다는 것)
Markov state란, 내가 현재 state 를 볼 때, '바로 직전의' state인 만을 보면 된다는 것이다.
영어로, "The future is independent of the past given the present"
어떤 정보(state)가 Markov하고, 어떤 정보(state)가 Markov하지 않을까? 예시를 하나씩 생각해보자.
위처럼, 부터 까지의 history 중에, state 만 도출해낸다면, history는 필요없어진다.
즉, 는 미래 결정을 위한 충분통계량이라 볼 수 있다.
Environment state는 정의상 Markov라 할 수 있는데, 정의상, Environment state는 '다음 tick을 결정하는 데 쓰이는 정보들'이기 때문이다.
또한, history 또한 Markov라 할 수 있다. 식으로 본다면, 를 결정하는 데에는 면 충분하지, 이 필요하지는 않는다. 왜냐면 가 을 포함하니까.
그렇다면, Agent state에서 Markov가 아닌 예시는 어떤 게 있을까?
Agent state는 reward를 내는 데 있어서 우리가 선택한 정보들이다.
자동차 운전을 한다고 가정해보자. 이 때, 핸들의 방향, 위치, 차선 등을 Agent state라 정하자. 이 때, timestep의 state만 이용해서 "브레이크를 풀로 밟았을 때 time step의 위치"를 알 수 있을까?
대답은 no. 다음 timestep의 위치는 timestep의 "속도"를 기반으로 정해져야 한다. time step의 "속도"는 timestep의 "위치"를 이용해야 알 수 있다.
(브레이크 밟았을 때 속도 변화는 적당히 알 수 있다 가정하자!)
다만, RL은 거의 Markov한 상황만을 다룬다 !! 아니라면 너무 어렵지 않은가..
Rat Example
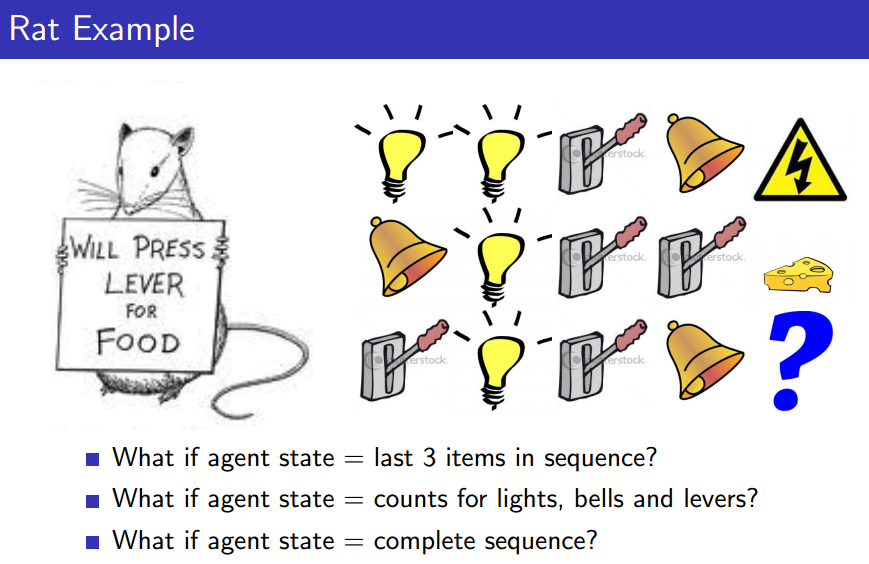
위에 나타나 있는 모형들은 일종의 history로 바라볼 수 있다.
이 때, state를 '전구, 레버, 종의 개수'로 정하는지, 아니면 '마지막 3개의 item sequence'로 정하는지, 아니면 '전체 sequence'로 정하는지에 따라서 reward가 달라질 것이다.
Fully Observable Environments
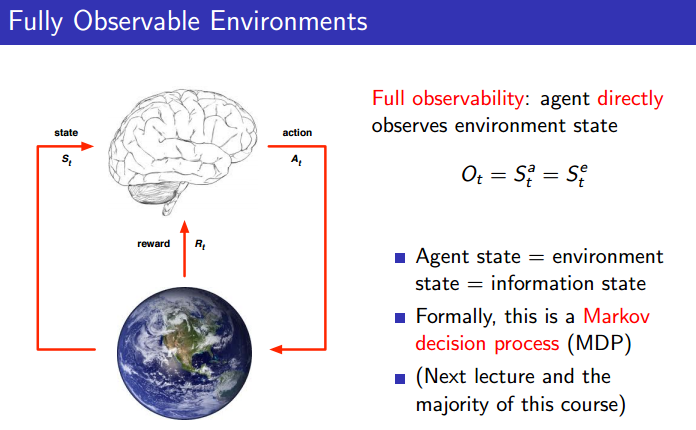
Agent가 environment의 state를 볼 수 있는가? 없는가? 만약 볼 수 있다면, 그건 Fully Observable Environment라 한다.
격식있게 말하자면, MDP(Marko Decision Process).
Partially Observable Environments

Agent가 Environment의 state를 볼 수 없다면, agent stage와 environment state는 다르기에, partially observable environment라 한다.
가령, 포커(상대방 패는 모른다)라든지, 로봇의 주행(시야만 알 뿐, 정확한 위치 좌표 등은 모른다).
격식있게 말하자면, POMDP(Partially Observable Markov Decision Process).
이 때, agent state는 environment state와 다르기 때문에 agent는 agent state에 대한 표현형을 구축할 필요가 있다.
즉, State를 표현하는 방법은 많은데, history를 사용해 표현할 수도, ( timestep의 state의 선형결합+ timestep의 observation의 선형결합 -> sigmoid로 표현되는) RNN을 사용해 표현할 수도 있는 것이다.
*위 그림의 확률에 관한 Beliefs는 어떤 의미일지.
Major Components of an RL Agent

위의 그림처럼, Agent는 Policy, Value function, Model로 이루어져 있다. 세 가지가 모두 있을 필요는 없다.
Policy

- policy는 state->action의 mapping 함수이다.
즉, agent의 행동이 결정하는 근간이라 할 수 있다. state에 따라 고정된 action이 선택되는 Deterministic policy와 Stochastic policy로 구분할 수 있다.
Value Function

- 상황이 얼마나 좋은지 평가해주는 함수이다. 즉, 미래에 얼마만큼의 reward를 받을 수 있을지 예측한다.

즉, value function은 특정 policy()를 필두로, 현재 상황인 state()를 입력했을 때, 게임의 끝까지 받을 수 있는 reward의 총합을 반환한다.
이 때, stochastic policy인 경우와 Environment 내 존재할 수 있는 randomness를 다루기 위해 기대값(Expectation)을 사용한다.
추가로, 미래의 불확실성, 시간에 따른 가치하락 등의 이유로 discount factor인 를 사용한다.
Model

- Model은 environment가 어떻게 변하는 지를 모델링하는 것이라 할 수 있다.
- Reward()를 예측한다(Reward).
- State Transition()을 예측한다(Dynamics).
- 즉, 상태 에서 액션 를 했을 때 상태 로 갈 확률이다.역시 필수는 아니다. 사용하지 않는 걸 Model-free RL이라 한다.
위 식에서 윗 첨자에 가 있는 것을 염두에 두자. action과 state가 정해져야 모델이 결정된다.
Maze Example

- 미로 게임을 예로 들어보자.
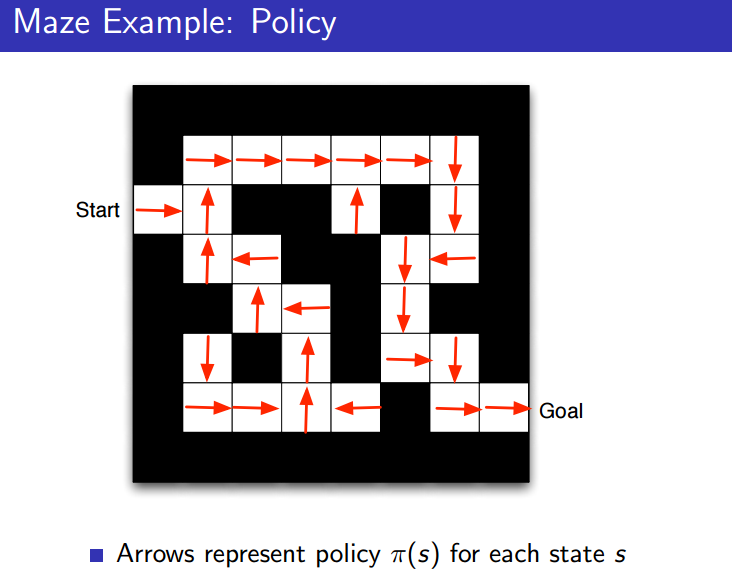
- Policy : 각 칸에서 최적의 이동을 나타내준다(예시는 Optimal, 바보같은 policy도 있을 수 있다).
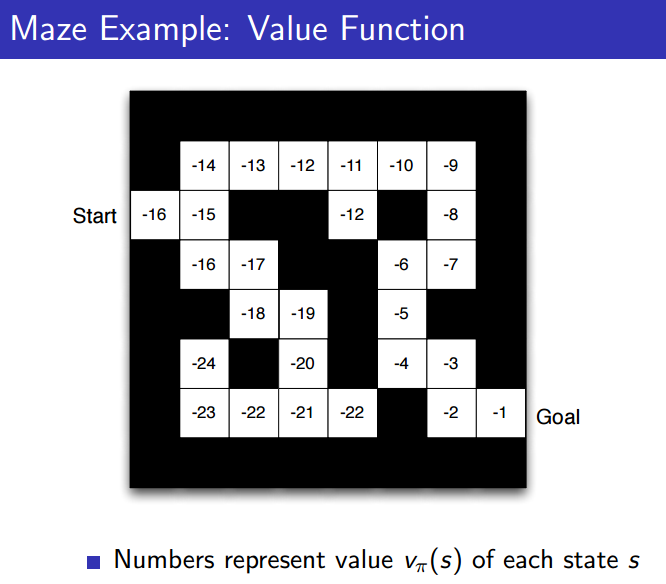
- Value function : 각 칸에서 받을 수 있는 reward
- 이 때, value function은 policy에 dependant하므로, 위의 예시는 optimal policy를 기반으로 계산됐다고 볼 수 있다.
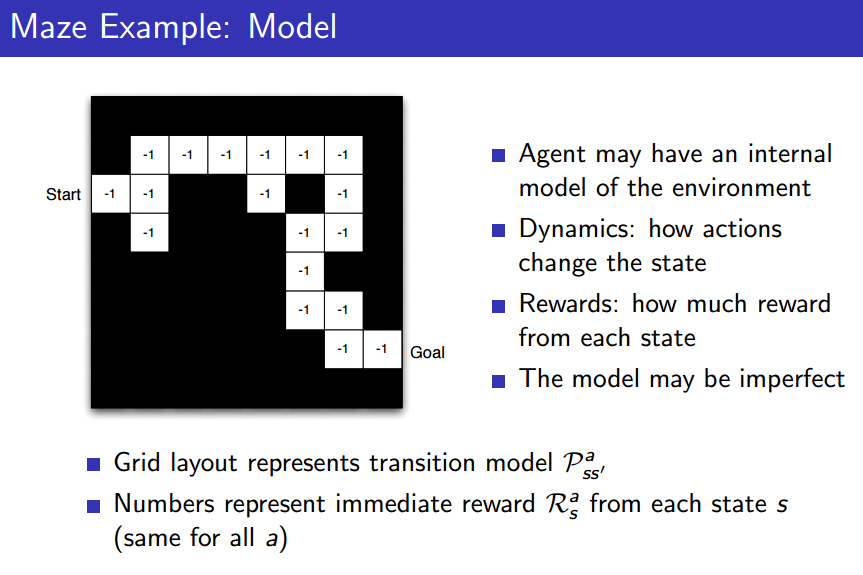
- Model: 모델은 environment에 대해 모두 알 수 없기 때문에, environment에 대한 내부적인 model을 갖는다.
- 미로의 경우 길을 알 수 없기 때문에, Agent는 부분적으로만 길을 알고 있는 것.- 즉, Model은 완벽하지 않을 수 있다.
이 경우 는 당연히 1이 됩니다(무조건 움직이므로). 는 -1이 됨을 쉽게 알 수 있습니다.
Categorizing RL agents
1. policy? or value function?

위처럼 policy와 value function을 모두 학습시키지 않더라도 강화학습을 돌릴 수 있다.
2. model exists?

- 이 때, model은 environment의 모델링이다. 즉 환경이 어떻게 동작하는지 agent가 모델링하는 것.
Taxonomy
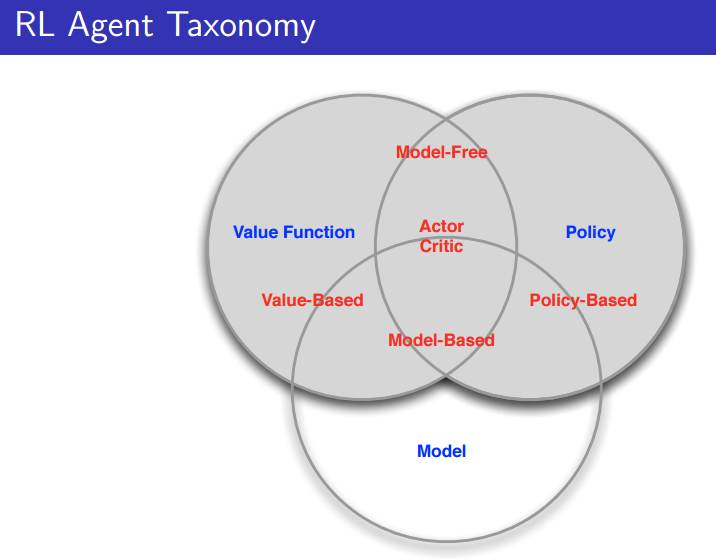
Learning and Planning
- 위에선 Agent를 나눴지만, 이제 Problem에 대해 나눠보자.

Environment를 모른다면, Agent는 action을 반복함으로써 environment와 상호작용을 해야하고, 그를 통해 policy를 최적화해야 한다.
Environment를 안다면, Agent는 action을 굳이 하지 않아도(즉, 환경과 상호작용하지 않아도) 미래의 state로 가볼 수 있다. 많은 종류가 있지만, 알파고의 Monte Carlo search) 등을 예로 들 수 있다.
Environment를 안다는 것은, 이전의 Model관점에서 생각해봤을 때, Transition between and 와 의 Reward를 안다고 볼 수 있다.
즉, 모델을 아냐 모르냐에 따라 Learning과 Planning이 나뉜다.
Atari Example(Learning)
이 경우, model을 모르기 때문에 Observation만 보고 환경과 상호작용(캐릭터 픽셀이 오른쪽으로 움직이네, 점수가 올라갔네 등)을 하면서 policy를 배워나간다.
Atari Example(Planning)
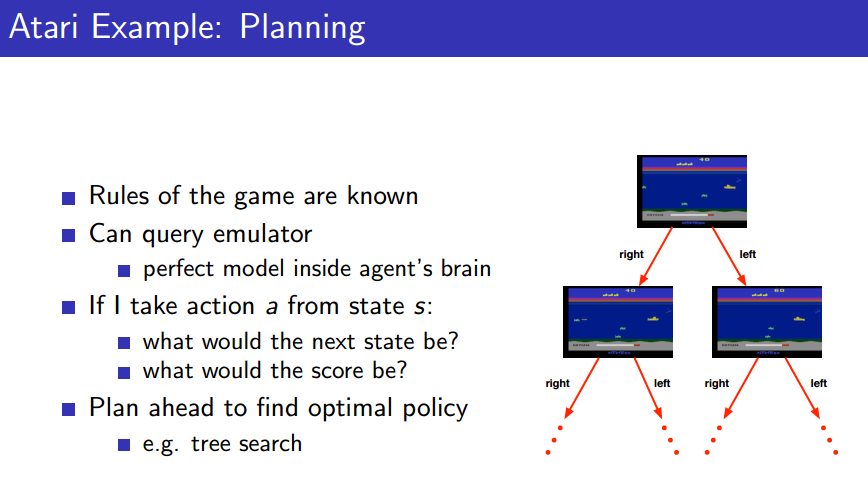
이 경우, 완벽한 model을 알기 때문에, emulator에 query를 던질 수 있다. 그를 통해 planning을 할 수 있고, 최적의 policy를 배울 수 있는 것.
Exploration? or Exploitation?


Reinforcement learning은 Environment와 상호작용하면서(시행착오를 거치면서) 최적의 policy를 찾는 과정을 뜻한다. 이를 위해 아래와 같이 2개의 관점을 가져올 수 있다.
- Environment와의 상호작용을 통해 정보를 얻어 Environment를 이해해야 한다(Exploration).
- 모은 정보를 토대로 최적의 policy(즉, reward를 최대화)해야 한다(Exploitation).
이 둘은 trade-off 관계라 할 수 있다.
Exploration을 하려면 agent가 정보가 없는 곳을 가봐야 한다. 이는 단기적인 Reward랑 관계가 없기 때문에 Exploitation이랑은 거리가 멀다할 수 있다.

예를 들면 저녁메뉴를 먹을 때, 매번 가던 음식점을 간다면 Exploitation, 새로운 음식점을 간다면 Exploration. 이를 반복하면 장기적으로 더 좋은 선택을 할 수 있게 된다(단기적인 손해는 볼 수 있지만..).
Prediction and Control

이 또한 term을 이해한다는 관점에서 접근해보자.
Prediction: 미래를 잘 평가하는 것.
-즉, value function을 잘 학습시킨다.
Control: 미래를 잘 최적화하는 것
-즉, policy를 잘 찾는다.
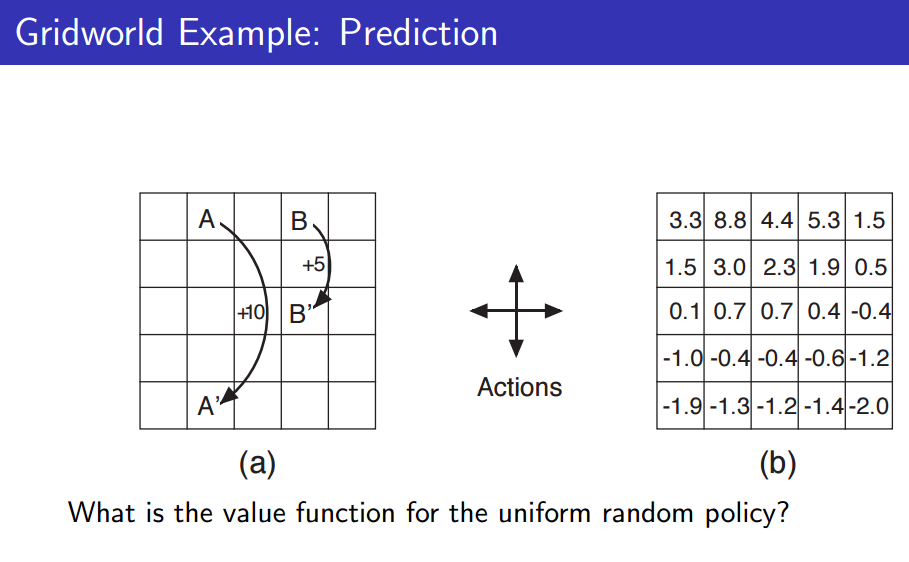
Uniform random policy, 즉, 균등하게 랜덤한 위치로 움직인다 가정할 경우, value function은 어떻게 될까? --> Prediction
즉, 우측 그림처럼 state에 따른 value를 찾는 것이 Prediction이라 할 수 있다.
value function은 future reward라 할 수 있습니다.
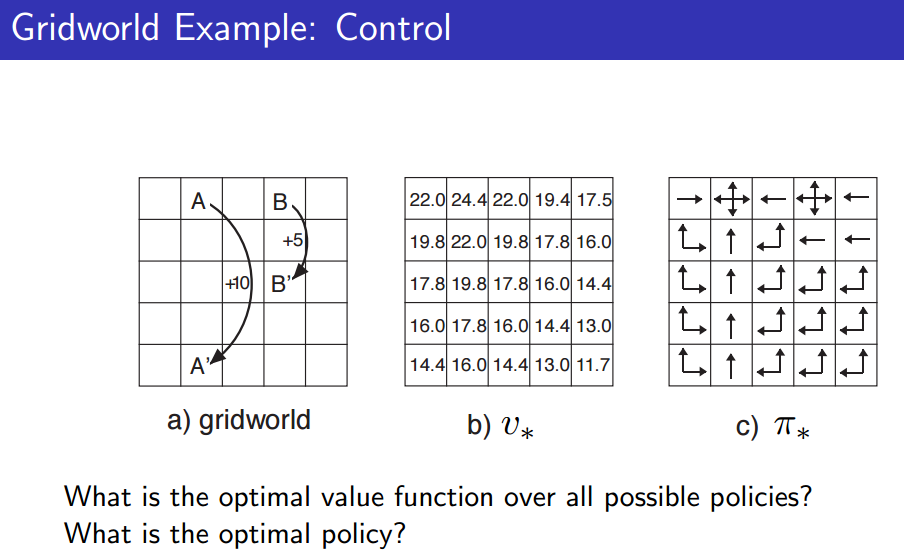
최적의 policy를 찾는 것 --> Control
Prediction에서의 random policy에 비해 state별로 value function이 높은 것을 볼 수 있다. 즉, 이를 토대로 최적의 policy를 찾을 수 있게 된다.
구체적인 것은 뒤에서 알 수 있습니다!

Reference
David silver(Deep mind), Introduction to Reinforcement Learning
팡요랩(Youtube), 강화학습
