[논문리뷰] Predicting Human Scanpaths in Visual Questions Answering, in CVPR 2021.
Paper: Predicting Human Scanpaths in Visual Question Answering
0. Abstract
Attention(주의집중)은 인간에게도 중요하고, 컴퓨터 비전 시스템에도 중요합니다.
근래 SoTA 모델들은 일반적으로 전체 영역에 대해 static한 확률 맵을 예측하는 데 초점을 맞추곤 합니다(free-viewing).
반면 real-wolrd는 굉장히 다양한 유형과 복잡성을 지니는 태스크로 가득차있고, 특히 visual exploration은 temporal한 과정에 더 가깝습니다.
이런 갭을 채우기 위해 저자들은 일반적인 태스크에 대해 scanpath로 칭하는 '시선의 시간적인 흐름'을 이해하고 예측하는 연구를 수행합니다.
또한 이러한 scanpaths가 task의 성능에 어떻게 영향을 끼치는지 분석합니다.
이런 저런 결과로, 저자들은 VQA task에서 scanpaths를 예측하는 새로운 딥러닝 아키텍처를 제안합니다.
성능은 다양하게 나타난다고 합니다.
task guidance map이 주어진 상태에서 해당 모델은 question-specific한 attention 패턴을 학습해 scanpaths를 생성하게 됩니다.
결론적으로, 이런 모델은 VQA task에서 인간과 유사한 spatio-temporal patterns(시공간적인 시선 흐름, 순서 등)을 정확하게 예측했을 뿐만 아니라 free-viewing & visual search tasks에도 일반화 성능을 갖춰, 기존의 SoTA 모델들을 뛰어 넘어 인간에 준하는 성능을 보였습니다.
1. Introduction
Visual attention은 일상적인 태스크에서 아주 중요한 역할을 하고 있습니다.
기존의 연구들은 주로 free-viewing를 기반으로하는 stimulus-driven attention에 초점을 맞춰왔습니다.
하지만, 실생활에서는 일반적으로 이와 다른 형태의 attention인 task-driven attention에 더 가깝습니다.
즉, 특정한 의사결정을 내리고 태스크를 수행하기 위해 해당 태스크와 관련된 정보를 선택하는 주의집중을 행하는 것이죠.
가령 특정 사진의 전반적인 상황을 기술하는 태스크라면 사람들은 사진 전체를 빠르고 간결하게 살펴볼 것이고, 디테일한 상황을 기술하는 태스크라면 보통 특정 물체 위주로 오랜 시간 머물면서 디테일을 파악하겠죠.
저자들은 이러한 visual scanpaths를 이해하고 예측하는 것이 의사결정 과정에 도움이 될 뿐만 아니라 컴퓨터 비전 분야에도 도움이 될 것이라 주장합니다.
Task에 걸맞는(Task-driven) visual scanpaths는 태스크를 수행하기 위한 시각적인 상황을 묘사하고, 이는 성능 상승과도 큰 관계가 있으니까요.
예시로 아래 사진을 봅시다.

↑ 의사결정 전략에 인간의 **Visual scanpaths**가 어떻게 영향을 끼치는 지를 보여주는 그림
위 그림은 아래와 같은 질문에 대답해야 하는 예시입니다.
"꽃병이 스카프와 같은 색인가요?"
이런 질문을 받으면, 인간은 적극적으로 상황을 탐색하고, 꽃병과 스카프가 어디 있는지 찾게됩니다.
적절한 시간에 적절한 위치를 본다면 가운데 사진처럼 올바르게 대답할 것이고, 그렇지 못하면 우측 사진처럼 대답하는 데 실패하겠죠.
즉, 저자들은 일반적인 task-driven attention을 이해하고 모델링하기 위해, task guidance를 활용하는 deep reinforcement learning(심층 강화학습)을 제안합니다.
task guidance는 일반적인 태스크를 수행하는 인간의 시각적 탐색 행동을 예측하기 위해 필요한 modality입니다.
해당 모델은 위에서 말했다시피 강화학습을 이용합니다.
해당 모델은 train-test 간 사이에 발생할 수 있는 exposure bias를 다루기 위해서 도입했다고 하는데요, test-time evaluation metric을 최적화하는 데 쓰인다고 합니다.
exposure bias : the discrepancy(불일치) between training-time and test-time contexts
일반적으로 evaluation metric이 미분 불가능하기 때문에 최적화 과정을 거쳐야 하고, 특히 해당 모델은 eye-movement patterns을 이용하기 때문에, 이를 미분하기 위해 새로운 loss function을 도입했다고 합니다.
새로운 loss function은 correct scanpaths와 incorrect scanpaths 사이에 일관성(consistency)과 다양성(divergence)을 설명하기 위한 손실함수입니다.
해당 모델의 기존 모델과 차이점은 아래와 같이 정리할 수 있습니다.
- general한 의사 결정 태스크에서의 복잡한 scanpath patterns을 연구함
- training-time과 test-time 사이의 차이로 인해 좋지 못했던 성능을 강화학습 기반 self-critical sequence training을 통해 크게 높혔다(심지어 인간보다 더 높을 정도로).
- scanpath 예측 태스크는 사실 인기도 없을 뿐만 아니라 성능도 안 좋았었습니다.
- general한 task-relevant 정보를 인코딩하는 매커니즘을 제안했다.
-
이로 인해 매우 복잡하고, 다양한 특성을 갖는 여러 태스크들에 adaptation을 쉽게 진행할 수 있게 되었습니다.
이렇듯 machine attention을 통합해 사용함으로써 저자들의 모델은 VQA model의 해석가능성을 측정할 수 있는 대안 또한 제공해줍니다.
2. Related Work
2.1. Scanpath prediction
- pass
2.2. Human and machine attention in VQA
본 논문이 제안하는 모델의 특별한 점은 바로 human scanpaths를 예측하는 태스크에서 machine attention을 통합했다는 것입니다.
딥러닝 기법들이 엄청나게 발전함에 따라 attention mechanism은 VQA models의 성능과 설명능력을 증진하기 위해 거의 필수적인 요소가 되어왔습니다.
하지만, 근본적인 내부 구조의 차이 때문에 machine attention은 많은 상황에서 인간의 attention과는 큰 차이를 가집니다.
기존에도 이런 차이를 데이터셋, 연산, 모델 등의 측면에서 분석한 연구는 있었지만, 해당 분석들은 주로 attention의 공간적인 차이에만 집중했습니다.
반면, 본 논문은 인간이 attention을 어떻게 유지하는지(maintain), 그리고 어떻게 움직이는지(shift)를 분석합니다.
즉, 공간적인요소 뿐만 아니라 얼마나 오랫동안, 그리고 어떤 순서로 attention이 머무르는지에 대한 시간적인 요소 또한 고려하는 것이죠.
2.3. Reinforcement learning in attention prediction
- pass
3. Method
본 단락에서는 위에서 잠깐 언급했던 scanpath를 예측하는 심층 강화학습 모델의 아키텍처와 이를 학습시키기 위한 머신러닝 방법을 제안합니다.
가장 중요한 요소들 중 하나는 시선의 위치와 지속시간을 예측하는데 활발히 도움을 주는 task guidance map입니다(self-critical sequence training이라고 부르는 강화학습 기반 방법).
3.1. Network Architecture
주로 사람들은 VQA task를 할 때, 보게되는 영역은 input question에 크게 의존합니다.
일반적인 task-driven attention 모델은 input task를 임베딩해 사용하는데, 모델에게는 충분히 의미 있는 가이드라인을 제공해 줄 수 있긴 하지만, 그렇다고 visual contents와 공간적으로 align하지는 않습니다.
input text를 임베딩해서 사용할 뿐, 이를 이미지와 연결시키지는 못한다는 것.
(단, 요즘은 애초에 input 단계에서 text-image cross-modal representation을 학습하는 모델(Oscar)이 많기 때문에 알아서 걸러 들으면 될 것 같습니다).
아무튼, 저자들은 general task guidance map을 연산해 task와 관련된 image region을 하이라이팅하게 되며, 이런 guidance map은 다른 태스크에 쉽게 adapt할 수 있습니다.
예를 들어, free-viewing task에서 scanpaths를 예측한다면 guidance map을 항등행렬로 줘서 골고루 어텐션하게 한다든지, visual search task에서는 object detection masks를 써서 guidance를 제공해준다든지..
본 단락에서는 전반적인 VQA tasks를 위한 방법을 요약합니다.
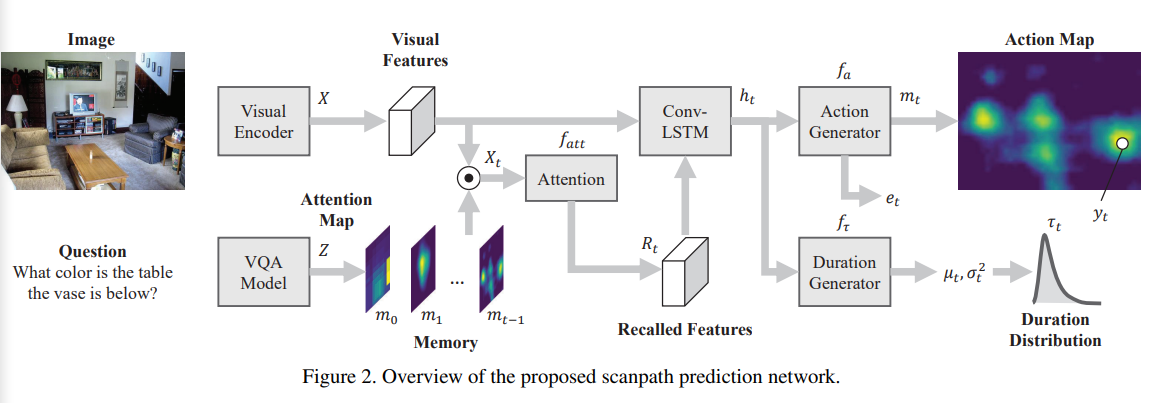
위의 그림에서 볼 수 있다시피 해당 아키텍처는 시선의 위치(positions)와 지속기간(durations)의 sequence를 생성해냅니다.
Memory module은 task-relevant visual information을 선택적으로 memorize하게끔 구축되고, Attention 매커니즘은 마찬가지로 recall하게끔 구축됩니다.
조금 구체적으로 살펴봅시다.
모델은 input으로 image와 question을 받습니다.
이 때, 해당 모델의 목표는 시선(fixations)의 위치와 지속기간에 대한 sequence를 생성하는 것입니다.
시선 위치(fixations positions) :
시선 지속기간(fixations durations) :
각 스텝 마다
시선의 위치 : 는 예측된 action map 에서 샘플링되고,
시선의 지속기간 : 는 log-normal distribution에서 샘플링됩니다.
log-normal distribution : ()
는 scanpaths의 끝을 나타냅니다.
위 과정을 조금 더 구체적으로, 단계 별로 파헤쳐봅시다.
3.1.1 . Inputs and task guidance
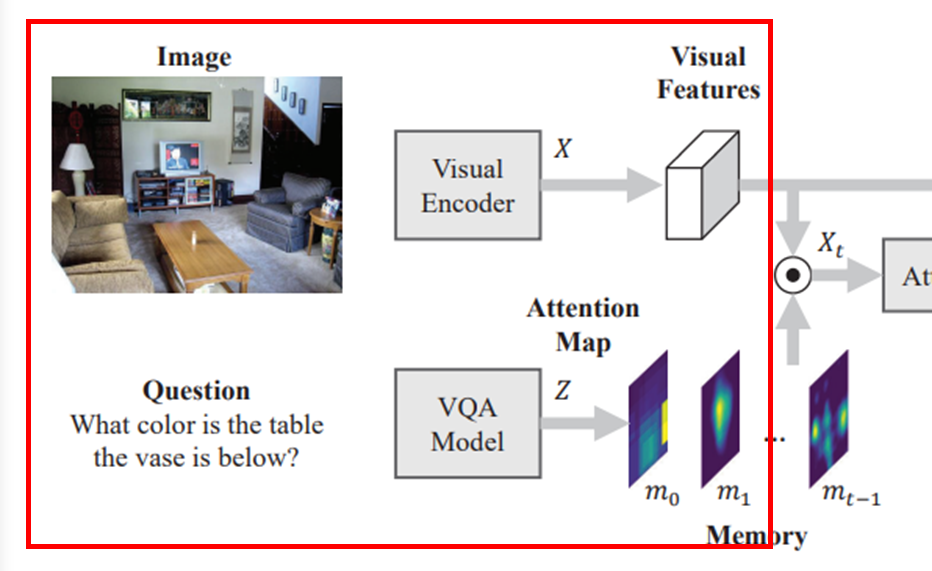
Input side에서는 CNN-based visual encoder를 활용해 visual features 를 추출합니다.
또한, large VQA datasets에 학습시킨 machine attention model은 task semantics(text로 봐도 무방)과 visual contents 사이를 잘 이어줄 수 있습니다.
즉, question에 답변하는 데 중요할 것 같은 task-relevant spatial regions을 강조해줄 수 있습니다.
그렇기 때문에 외부적으로 사전학습된 VQA model을 이용해 eye fixations(시선)을 더욱 잘 예측하게끔 도와줄 수 있습니다.
저자들은 VQA model의 attention을 2d task guidance map 로 전처리해 사용합니다.
(if , then , 즉 정규화된 값을 사용)
3.1.2. Memory and Attention
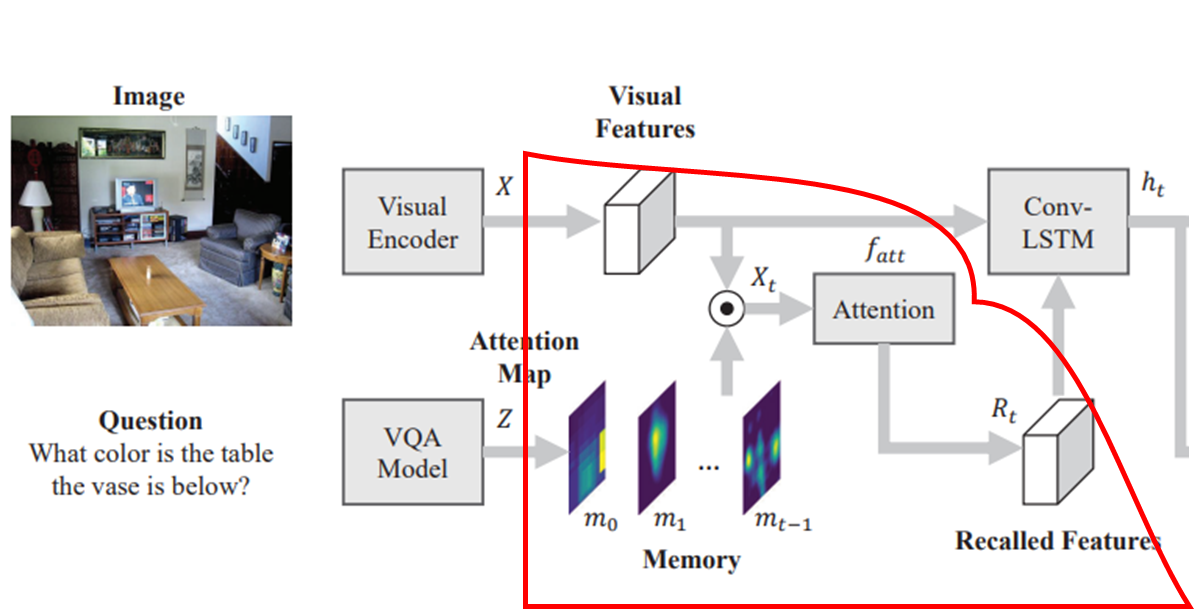
해당 tasks에서 복잡한 questions에 답변을 하려면 역동적으로 업데이트되는 memory / attention 매커니즘을 필요로 합니다.
특히, memory / attention modules은 시간에 따른 추론 과정을 추적할 수 있어야 합니다.
메모리는 아래와 같이 표현됩니다.
메모리 는 이전의 모든 action maps(task guidance map 포함을 유지합니다.
action map : 해당 아키텍처가 궁극적으로 예측하고자 하는 공간정보
이 전체 메모리를 spatio-temporal attention volume으로 바라볼 수 있는 것입니다.
이런 메모리를 visual features 에 적용함으로써 memorized features 를 얻을 수 있습니다.
또한 attention module은 메모리로부터 가장 관련 있는 정보 를 불러옵니다(recall).
즉, 를 학습가능한 parameters라 할 때
와 같이 표현할 수 있습니다.
위의 식은 각 time steps들의 dynamic importance를 나타내는 temporal attention vector를 연산하게 됩니다.
이로부터 현재의 fixation(혹은 action map)을 예측하기 위해 메모리로부터 어떤 것을 불러와야 할지 결정할 수 있는 거죠.
3.1.3. ConvLSTM and output
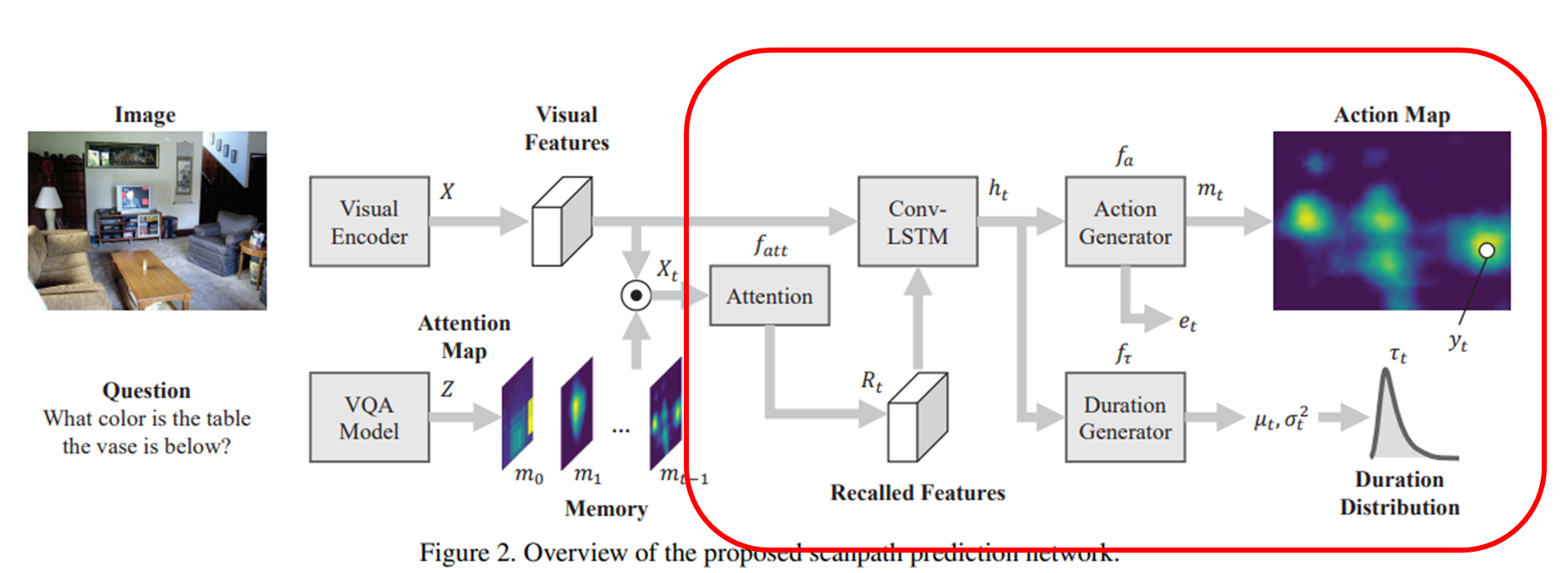
최종적으로 시선의 위치와 지속기간의 분포를 예측하는 네트워크가 ConvLSTM입니다.
image features 와 recalled features 가 ConvLSTM으로 들어가 scanpaths의 spatio-temporal pattern을 인코딩합니다.
가령,
- 현재의 hidden state :
- output layers :
- learnable parameters : ,
로 가정하면 output은 아래와 같이 연산됩니다.
특히, 를 action maps , end-of-scanpath indicator 를 포함하는 action들의 분포를 나타내기 위해 사용합니다.
최종적으로, fixation point 를 action map 내 이산확률 분포(softmax)를 따라 샘플링하고, fixation duration은 ~를 따라 샘플링합니다.
말했다시피 위의 는 log-normal function입니다.
한~두번 읽어보면 꽤나 (결과적으로는) 직관적으로 깔끔한 아키텍처이고, 한줄로 요약하자면 "이미지 정보와 이전에 예측했던 action map memory을 토대로 새로운 action map과 머무를 시간을 예측하자"입니다.
3.2. Objective
위에서 계속해 다뤘던 Scanpath Prediction은 전형적인 sequential learning task입니다.
다만, 이런 sequence 예측 태스크에서는 trian 상황과 test 상황 간에 불일치가 꽤나 자주 일어나는 편입니다.
저자들은 이를 다루기 위해 Self Critical Sequence Training(SCST)를 제안합니다.
이를 통해 다이렉트하게 (미분 불가능한) evaluation metric을 최적화할 수 있습니다.
3.2.1. Supervised Learning
보통 sequential learning에서는 각 step마다 maximum-likelihood loss가 널리 쓰입니다.
본 모델은 fixation position(시선의 위치) 와 시선의 지속기간 를 모두 최적화해야 하기 때문에 jointly하게 Loss함수를 부여합니다.
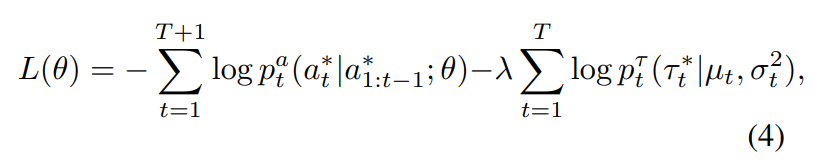
: ground-truth fixations
: ground-truth action
- one-hot indicating fixations position and end
위와 같이 Loss함수를 정의함으로써 correct scanpath와 incorrect scanpath에 대한 2개의 networks를 학습하게 됩니다.
두 개의 네트워크는 대부분 파라미터를 공유하지만 memory와 output layer는 개별로 학습한다고 합니다.
위와 같이 Loss함수를 세우더라도 sequence generation tasks에서는 학습-테스트 간 매우 다른 맥락을 가질 수 있습니다.
3.2.2. Reinforcement learning with SCST
구체적으로, scnpath prediction 관련해서 아래의 negative expected reward를 최소화하게끔 강화학습을 진행합니다.
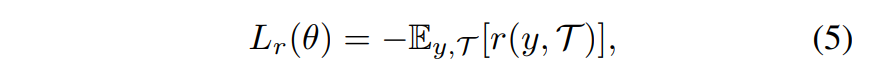
: reward function
: sampled fixation positions
: sampled fixation durations
강화학습을 기반으로 학습하기 때문에 알고리즘 또한 기본적인 REINFORCE 알고리즘을 따릅니다.
이 때 사용하는 reward는, test time에 쓰이는 evaluation metric 하에서, 현재 모델이 얼마나 좋은 성능을 보이는 지에 따라 결정됩니다.
그 외에도 학습의 안정성(및 속도)를 위해 개의 scanpaths를 사용해서 평균적인 reward를 계산한다든지, loss function을 와 로 나눠서 correct / incorrect를 구별하는 등의 요소도 적용했습니다.
3.2.3. Consistency-Divergence Loss
correct scanpath와 incorrect scanpaths간에 얼마나 차이나는 지는 (당연하게도) 이미지 형태로 주어집니다.
그렇기 때문에 데이터로부터 직접적으로 이를 구별하기가 쉽지는 않습니다.
모델이 예측한 scanpath가 올바른 예시인지, 아니면 올바르지 않은 예시인지 판단하기 쉽지 않다는 거죠.
그래서 저자들은 위에서 제안한 강화학습 기반의 SCST와 결합할, human scanpaths의 consistency(일관성)와 divergence(다양성)를 정량화할 수 있는 Consistency-Divergence loss(CDL)를 제안합니다.
그리고 모델은 human scanpaths의 통계량을 따르는 예측을 내뱉게끔 학습되겠죠.
자세한 내용은 생략하겠습니다만, 같은 집단 내 scanpaths는 유사도가 높게끔, 그리고 다른 집단 간 scanpaths는 유사도가 낮게끔 학습됩니다.
그 결과 correct scanpath와 incorrect scanpath는 충분히 구분될 수 있는 구조를 가질 수 있습니다.
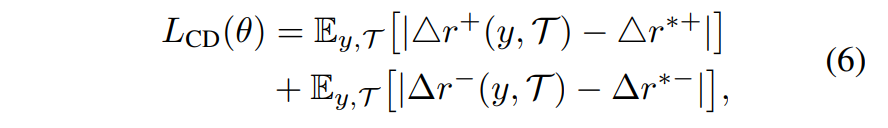
이렇듯, correct/incorrect scanpath를 구분하는데 도움이 되는 CDL Loss까지 추가해서 최종적인 total loss를 정합니다.

좌측 2개 : (policy gradient loss), 우측 1개 : CDL loss(일종의 Regularization?)
4. Experiments
적당히 그림 위주로 보도록 하겠습니다.
4.2. Are the predicted scanpaths plausible?
scanpaths prediction task가 그리 유명한 task는 아니다 보니까, 예측한 scanpath가 사람을 얼마나 잘 따라하는지에 대한 평가 방법이 별로 없습니다.
실제로 VQA task에서 scanpath를 예측하는 건 본 논문의 저자들이 처음이기도 하구요.
Human Performence와 이런 저런 방법들을 사용해서 평가를 진행했습니다만, 어쨋든 광범위하게 검증받은 수치들은 아니기 때문에 여기서도 생략하도록 하겠습니다.
정성평가를 살펴봅시다.
아래의 그림은 예측한 scanpath의 qualitative examples입니다.

위의 세 줄은 비교 모델(SoTA models)이고, 아래의 두 줄은 저자들이 제안하는 모델과 Human의 scanpath입니다.
비교 SoTA 모델들은 주로 뚜렷한 object들만을 보는 반면, 저자들의 모델은 task-related objects를 보고, 인간의 인식 방식과도 유사한 것을 볼 수 있습니다(위치, 지속기간, 그리고 순서).
이는 Introduction 쪽에서도 다뤘던, 기존 모델과의 차이점이라 할 수 있습니다.
그냥 두드러진 물체만 보고 판단할 게 아니라, 적당히 task에 걸맞는 탐색 전략이 필요하니까요.

조금 더 자세히 보면, incorrect scanpaths(각 오른쪽)은 phone이나 knives를 계속해서 찾지 못하는 것을 볼 수 있습니다.
뿐만 아니라 CDL loss로 대표되는 loss를 도입했을 때 살짝 언급했었는데, 해당 모델은 '잘 예측하는 것' 뿐만 아니라 '잘 예측하지 못한 것'에 대한 예측 또한 훌륭하게 해냅니다.
incorrect scanpath는 correct scanpaths에 비해 consistency가 떨어진다든지..
'제대로 예측하지 못하는 것'은 피해야 하는 것이기 때문에, 이에 대한 이해 또한 중요하다는 얘기인 것 같습니다.
아무튼, 모델은 scanpath만 보고도 "얘는 딱봐도 제대로 대답 못했구나", 혹은 "아, 제대로 봤네" 라는 식의 판단이 가능합니다(실제로 생각하는 건 아니지만, 미묘한 차이를 감지할 수 있다는 점).
사실 저도 못 찾았습니다.
4.3. What contributes to the model's performance
다시 한번 본 모델의 기여그림으로 한 번 봅시다. 를 정리해봅시다.
- VQA model의 attention을 task guidance로 사용.
- exposure gap을 다루기 위한 SCST
- Correct/incorrect scanpaths를 다루기 위한 CDL
이런 요소들에 대한 Ablation study(evaluation)은 아래와 같습니다.
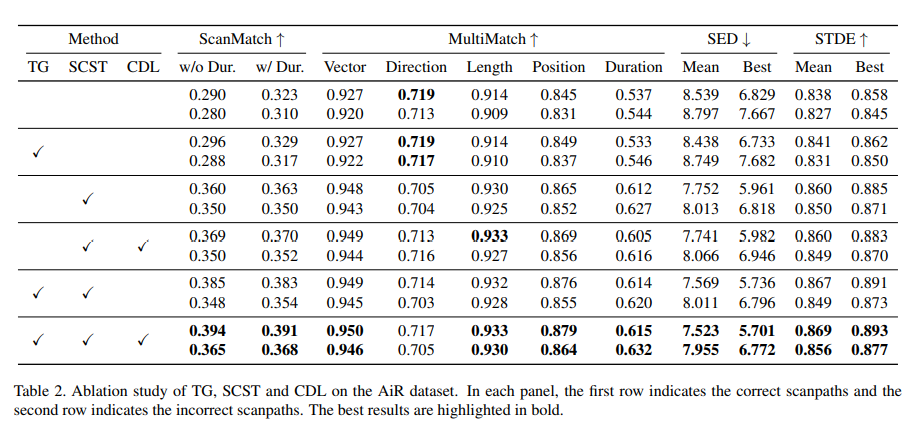
뭐 대충 다 쓰면 좋다..
4.5. Which VQA model is the most effective?
사실 VQA task같은 경우, 사진을 보고 답을 내려야 하는 고도의 task기 때문에 단순 정확도 만으로 성능 평가를 내리는 것은 항상 바람직하지는 않은 것 같습니다.
저자들이 제안하는 아키텍처는 VQA model을 직접적으로 사용하기 때문에 인간의 Attention 관점에서 VQA model을 시각화하고 평가할 수 있습니다.
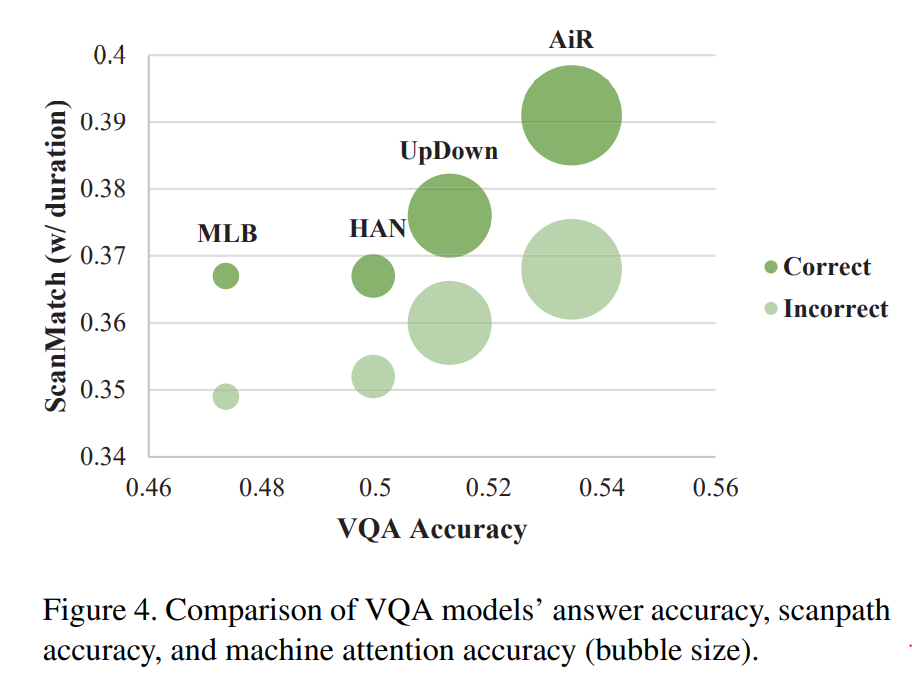
보다시피 저자가 제안하는 scanpath accuracy 기존의 VQA Accuracy, 그리고 machine attention accuracy와도 양의 상관관계를 지니기 때문에 완전히 별개의 판단 기준이 아니라는 것을 알 수 있습니다.
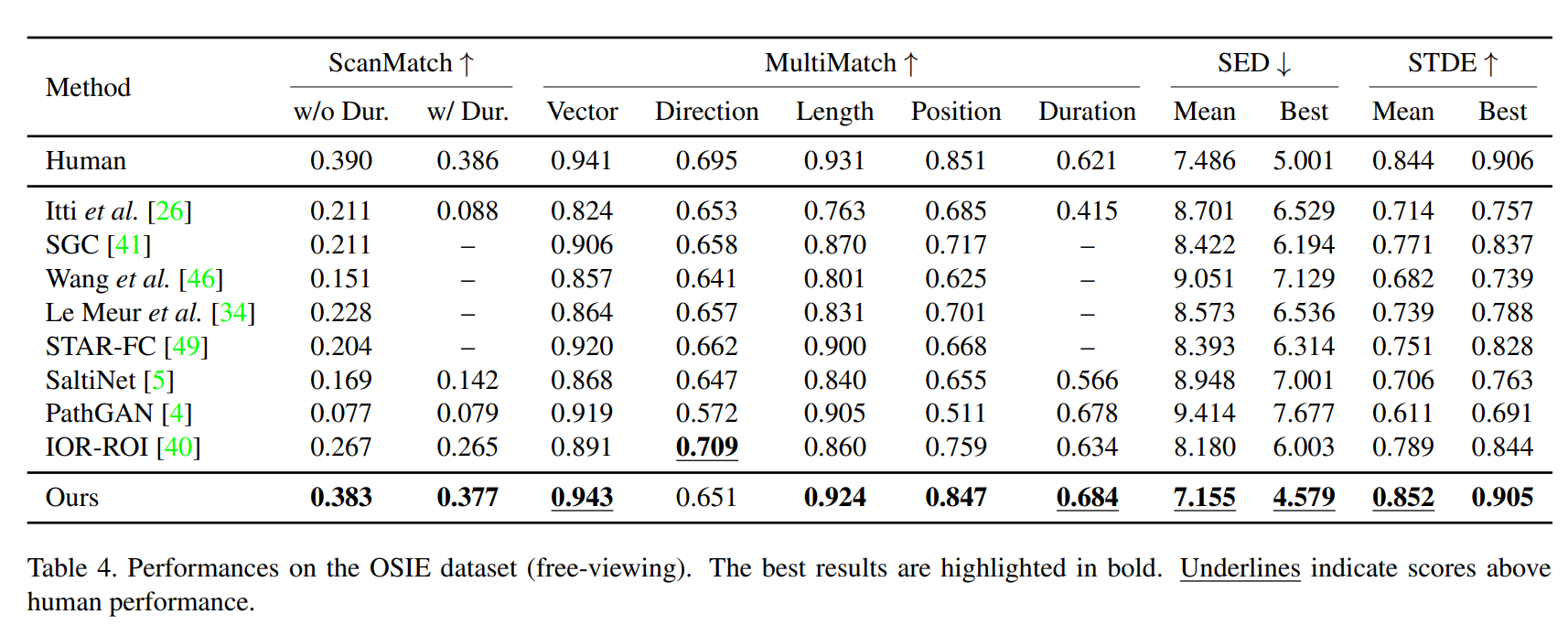
4.6. Does the proposed method generalize?
해당 모델은 task guidance와 CDL을 사용하지 않고도(즉, free-viewing, 인간을 뛰어 넘는 성능을 보입니다.
뿐만 아니라 Visual Search task에서도 상당히 좋은 성능을 보입니다.
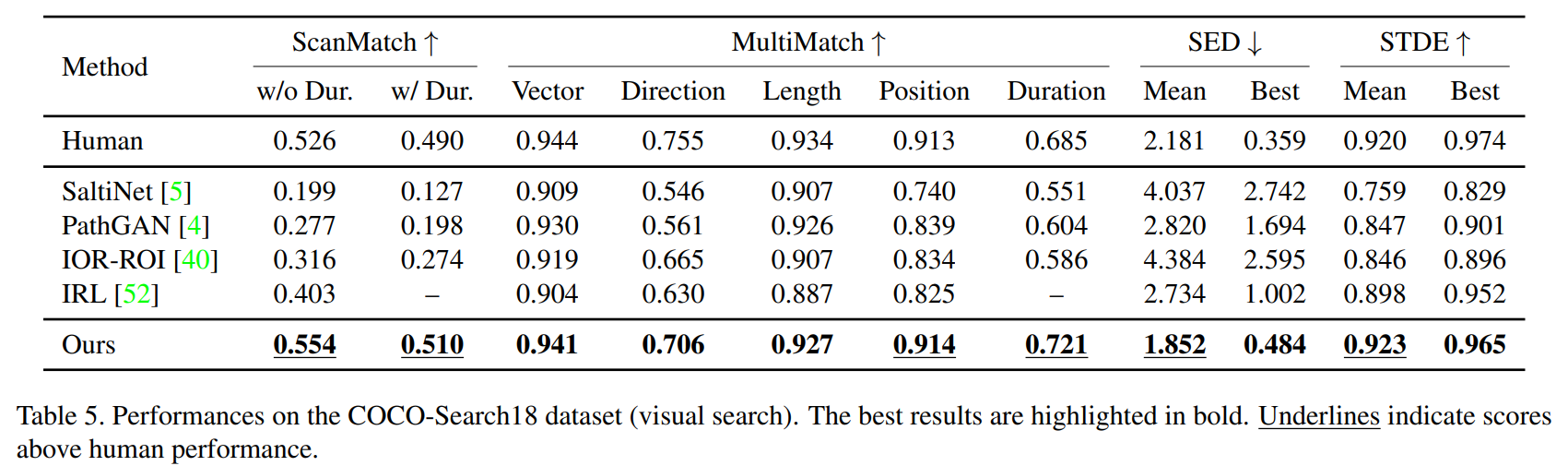
즉, task에 구애받지 않고 좋은 성능을 발휘할 수 있는 모델이라 힐 수 있습니다.
5. Conclusion
저자들은 VQA에 적용할 수 있는 human scanpath prediction 모델을 제안했습니다.
task guidance map을 통합함으로써 모델은 task-driven scanpaths(의 sequence)를 예측하는 방법을 학습합니다.
이로부터 correct(incorrect) answers를 도출할 수 있었죠.
뿐만 아니라 강화학습 기반의 SCST, 새롭게 제안한 CDL 등 모델의 이해도를 높히기 위해 여러가지 방법들을 제안했습니다.
성능은 기존의 모델들을 크게 뛰어 넘었고, 사람에 준하는(혹은 뛰어 넘는)성능을 보였을 뿐만 아니라 인간과 유사한 scanpath를 예측하는 능력을 보여주었습니다.
task performance를 결정하는 critical fixation patterns 또한 알 수 있었구요.
이렇듯 인간과 유사한 시선처리 성능을 갖추게 된다면 task-driven attention 관련 분야 뿐만 아니라 지능 로봇, 자동 계획, 광고, 인간-컴퓨터 상호작용, 정신건강 진단 툴 등 다양한 응용 분야를 발전시킬 수 있으리라 생각합니다.
