Neural Shape Deformation Priors에 사용된 Point Transformer에 대한 간략한 요약이다.
요약
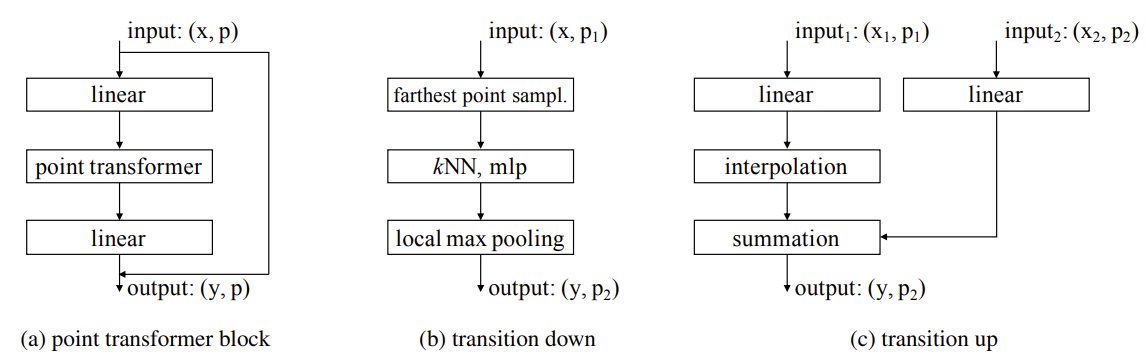
일반적인 scalar attention 대신 vector attention (attention이 vector 꼴로 나오고 value vector와 Hadamard product해서 output vector를 만든다.)을 사용한다.
모든 point에 대해 attention을 계산하는 대신 k-nearest neighbors에 대해서 계산한다. (kNN 대신 ball query라는 대안도 존재한다. 거리가 반지름 r보다 작은 모든 point들에 대해 계산하는 것.)
각 이웃 point에 대해 좌표의 차이를 mlp를 통과시켜서 positional encoding을 얻어 사용한다 (positional encoding이 trainable하다.)
semantic segmantation 용도로 쓸때 GCN과 다르게 UNet처럼 poinst set의 크기를 중간에 줄인다 (Transition down block). 구체적으로 PointNet++라는 논문에서 소개된 farthest point sampling이라는 방법(서로 떨어진 점들을 골라, 각 점들이 더 대표성을 띌 수 있도록 sampling함)을 사용해서 원하는 수만큼의 point들을 sampling하고, 각 point들에 대해 kNN, mlp, max pooling을 거쳐 output을 얻는다.
Transition up할 때는 sampling에서 탈락되었던 point들에 대해서는 interpolation 해서 feature vector를 얻는다.
