
참고 자료
캐글 - 타이타닉 생존자 예측하기 [1/3] - 데이터 분석
Titanic Data Science Solutions
타이타닉 탑승자의 생존여부를 맞추는 문제
문제 링크
1. 개요
캐글 입문, 머신 러닝 가이드로 사용되는 타이타닉 문제입니다. 하지만, 튜토리얼 이라고 하기에는 조금 어렵습니다.
예를 들어, 기본으로 주어진 gender_submission.csv(여자 생존, 남자 사망)를 그대로 제출하면 76.55의 점수를 받습니다. 이 점수는 탑승객 76.55% 의 생존여부를 맞췄다는 의미입니다.
2. 문제 확인
1) 목표
타이타닉 탑승자의 생존여부를 분류하세요.
생존여부(Survived)는
범주형 변수- 명목형 입니다.
범주형 변수의 값을 맞추는 것을 분류라고 합니다.
2) 데이터
- Survived - 생존 여부 (0 = 사망, 1 = 생존)
- Pclass - 티켓 클래스 (1 = 1등석, 2 = 2등석, 3 = 3등석)
- Sex - 성별
- Age - 나이
- SibSp - 함께 탑승한 자녀 / 배우자 의 수
- Parch - 함께 탑승한 부모님 / 아이들 의 수
- Ticket - 티켓 번호
- Fare - 탑승 요금
- Cabin - 수하물 번호
- Embarked - 선착장 (C = Cherbourg, Q = Queenstown, S = Southampton)
3) 파일
train.csv
분석해야할 파일입니다. 예측 모델 생성에 사용됩니다.
test.csv
예측해야할 탑승객 목록입니다. 생존여부(Survived) 칼럼이 없습니다.
gender_submission.csv
성별만으로 생존여부를 예측한 샘플입니다. (여자: 생존, 남자: 사망)
3. pandas
pandas는 데이터를 불러오고, 전처리에 사용되는 Python 라이브러리입니다.
Anaconda를 설치할 때 함께 설치됩니다.
# pandas 설치 여부 확인
# 설치되어 있다면 목록에 pandas가 있습니다.
pip list설치되어있지 않는다면, 다음과 같이 설치할 수 있습니다.
# 로컬 전역에 설치됩니다.
pip install pandas다음과 같이 관례적으로 pd로 불러옵니다.
import pandas as pd4. csv
pandas로 csv 파일을 읽어옵니다.
훈련용 데이터는 train, 데스트 데이터는 test 변수에 저장했습니다.
'''
pd.read_scv(파일 경로, 문자열)
파일 경로는 사용자마다 다를 수 있습니다.
저는 상대경로로 작성했습니다.
.의미는 현재 파이썬 파일이 있는 위치
./input/train.csv' 의미는 현재 파이썬 파일 바로 옆 input 폴더안의 train.scv 파일을 의미합니다.
'''
train = pd.read_csv('./input/train.csv')
test = pd.read_csv('./input/test.csv')5. 데이터프레임
read_csv() 함수로 데이터를 읽었을 경우 반환값의 자료형은 dataframe입니다.
데이터프레임은 엑셀 또는 SQL의 테이블과 유사한 2차원 구조입니다.
변수 train, test의 자료형은 datarame입니다.
# 파이썬 변수 train, test의 자료형 확인
# pandas.core.frame.DataFrame
type(train)
type(test)6. 데이터 확인
CSV 파일을 잘 읽었는지, 그리고 형태는 어떤지 한번 확인해봐요
데이터프레임 제공하는 함수와 속성은 다음 2개가 있습니다.
- .head() -> 위에서 5개의 데이터를 칼럼명과 함께 표시
- .shape -> 행의 개수, 열의 개수 확인
위 2개를 사용해서 train 데이터를 확인해봅시다.
# 위에서 5개의 데이터를 칼럼명과 함께 표시 (비어있을 경우, 기본값: 5)
train.head()
# 위에서 10개의 데이터 칼럼명과 함께 표시
train.head(10)
# 행의 개수, 열의 개수 반환
# (891, 12)
train.shape
마찬가지로 test 데이터를 확인해보면 Survived 칼럼이 없는것을 볼수있어요.
# 위에서 5개의 데이터를 칼럼명과 함께 표시
test.head()
# 행의 개수, 열의 개수 반환
# (418, 11)
test.shape
7. 결측치
결측치란 비어있는 값을 의미합니다. 결측치 처리는 전처리에서 가장 중요한 부분입니다.
결측치는 분석 정확성을 낮추고, 모델을 생성할 때 오류가 발생합니다.
1) 비어있는 값 확인
# train의 칼럼별 결측치 합계
train.isnull().sum()
# test의 칼럼별 결측치 합계
test.isnull().sum()나이, 수화물 번호, 선착장, 탑승 요금 정보가 누락되어 있습니다.
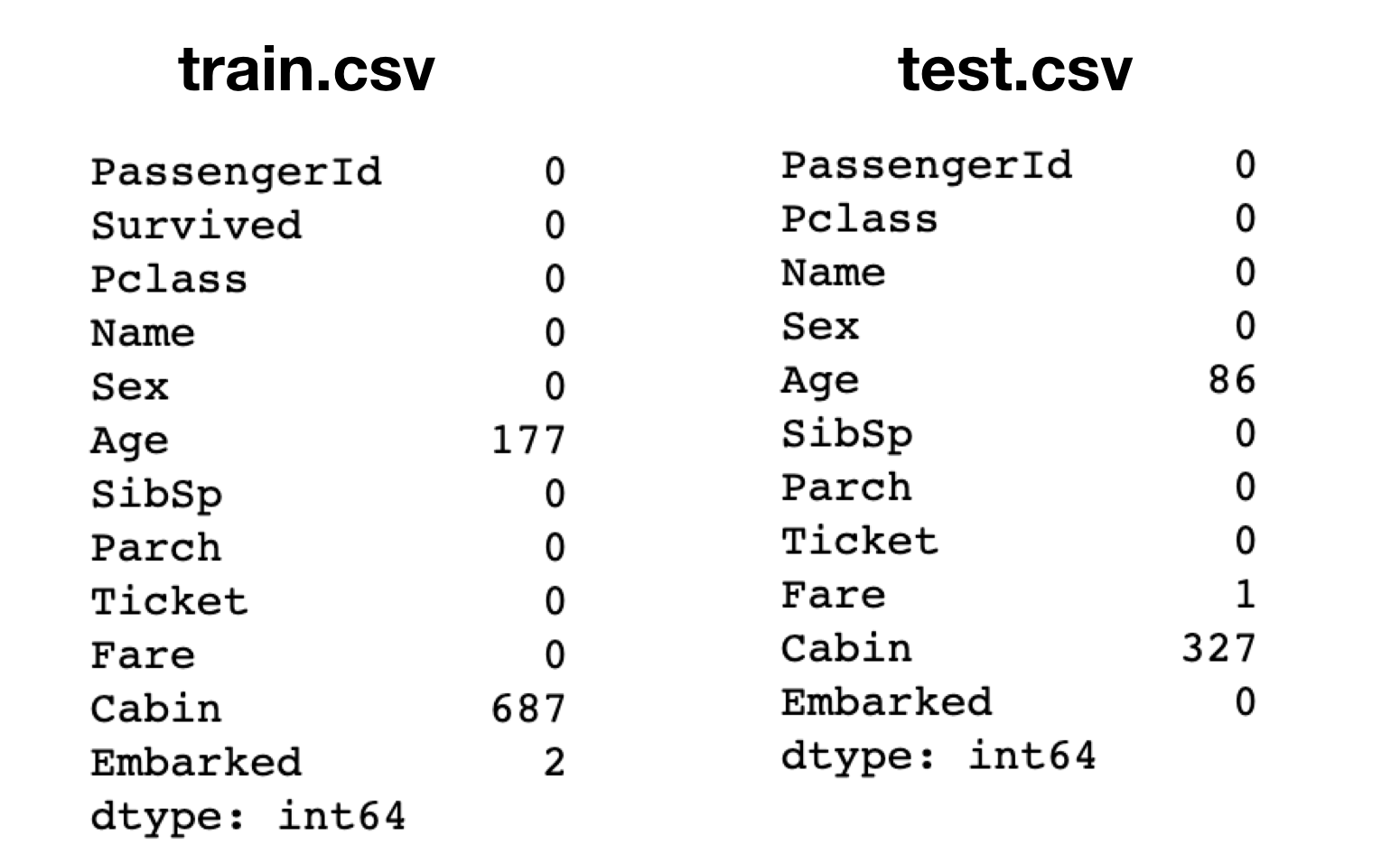
2) 처리 방법
결측치가 있는 행을 삭제할 수도 있습니다. 하지만 별로 권장하지 않아요.
그렇다고 나이의 빈공간에 평균값을 바로 넣는것도 좋지 않아요. 그 사람의 특징을 보고 적절한 나이를 넣는 것이 좋아요.
조금 더 정교한 방법을 알아볼께요.
8. 안쓰는 칼럼 drop
이렇게 하면 안되기도 하지만
지금으로써는 딱히 사용 용도를 모르겠다.
train = train.drop(['Cabin', 'Embarked', 'Name', 'Ticket', 'PassengerId'],axis=1)
test = test.drop(['Cabin', 'Embarked', 'Name', 'Ticket'],axis=1)9. 결측치, NA
비어있거나, 잘못된 값인 결측치를 없애준다.
train["Age"].fillna(train.groupby("Sex")["Age"].transform("mean"), inplace=True)
test["Age"].fillna(test.groupby("Sex")["Age"].transform("mean"), inplace=True)
test["Fare"].fillna(test.groupby("Sex")["Fare"].transform("median"), inplace=True)결측치 확인
train.isnull().sum()
test.isnull().sum()10. 매핑
문자열을 그대로 가지고 있으면 모델을 못돌린다. 숫자로 바꿔준다.
sex_mapping = {"male": 0, "female": 1}
train['Sex'] = train['Sex'].map(sex_mapping)
test['Sex'] = test['Sex'].map(sex_mapping)11. 이상치 제거
평균 +- 3.표준편차 안에 포함되지 않는 값은 이상치로 생각해서 지웠다.
age_mean = train['Age'].mean()
age_std = train['Age'].std()
indexNames = train[train['Age'] < age_mean - 3*age_std].index
train.drop(indexNames , inplace=True)
indexNames = train[train['Age'] > age_mean + 3*age_std].index
train.drop(indexNames , inplace=True)fare_mean = train['Fare'].mean()
fare_std = train['Fare'].std()
indexNames = train[train['Fare'] < fare_mean - 3*fare_std].index
train.drop(indexNames , inplace=True)
indexNames = train[train['Fare'] > fare_mean + 3*fare_std].index
train.drop(indexNames , inplace=True)12. 로지스틱 회귀
sklearn의 로지스틱 회귀 모델을 사용할 것이다.
from sklearn.linear_model import LogisticRegression
ml = LogisticRegression(solver='lbfgs')계수 미리 한번 찍어봤는데 성별, Pclass빼고는 다 0.9 미만이라서 다 drop 시켰다.
x = train.drop(['Survived', 'Age', 'Parch', 'Fare', 'SibSp'], axis=1)
y = train['Survived']
ml.fit(x, y)계수 확인
ml.coef_13. KNN
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
k_fold = KFold(n_splits=10, shuffle=True, random_state=0)
scoring = 'accuracy'
score = cross_val_score(ml, x, y, cv=k_fold, n_jobs=1, scoring=scoring)
print(score)
round(np.mean(score)*100, 2)14. 결과 출력
csv파일을 작성하기 위해 먼저 결과를 DataFrame 자료형으로 만듭니다.
DataFrame은 다양한 방법으로 만들 수 있는데 다음과 같이 작성하면
python의 딕셔너리 자료형을 DataFrame 생성자에 변수로 넘겨줍니다.
딕셔너리 자료형은 키, 값으로 이루어져있습니다.
그리고, test['PassengerId'], predict 와 같은 리스트 형태는 판다스의 Series 자료형 입니다.
predict = ml.predict(test.drop(['PassengerId', 'Age', 'Parch', 'Fare', 'SibSp'], axis=1))
result =pd.DataFrame({
'PassengerId': test['PassengerId'],
'Survived': predict
})
result.to_csv('result.csv', index=False) 
3번에 판다스 pip 설치 부분 "pip install padnas" 오타났습니다!