분류 모델의 평가 방법

분류모델의 평가방법에 대해 알아봅시다.
참고: 파이썬 머신러닝 완벽가이드
정확도만 가지고 분류 모델을 평가하면 안될까요?
-
분류: 범주형 변수가 어떤 곳에 속할지를 예측, 예시: 암환자 판단, 스팸메일 분류, 사진으로 호랑이 토끼 예측
-
정확도: 전체의 데이터 중에서 올바르게 예측한 비율
결론은 아닙니다.
다음과 같은 예시가 있습니다.

전체 데이터의 90%는 토끼, 10%는 호랑이입니다.
데이터를 묻지도 따지지도 않고 모두 토끼라고 예측한다면, 정확도는 무려 90% 입니다.
이렇게, 라벨이 불균형할때 정확도만으로 모델의 성능을 평가하는 것은 위험합니다.
그렇기 때문에 다른 평가 지표도 함께 따져 봐야합니다.
1. confusion matrix ( 오차행렬 )
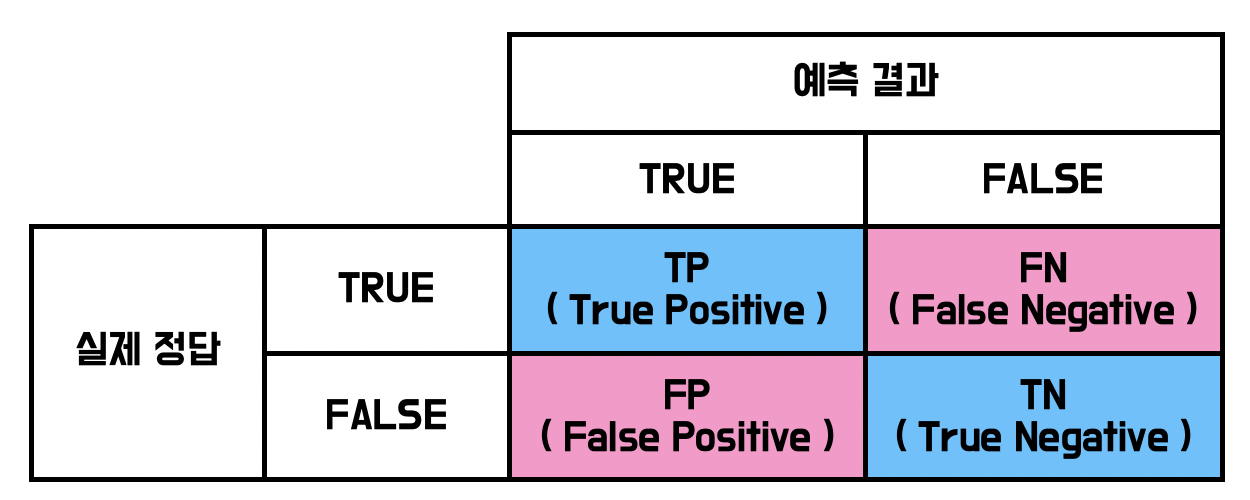
1) 정의
분류를 하면서 얼마나 헷갈리고 있는지를 알려줍니다.
그리고, 어떤 예측오류가 얼마나 발생하는지도 알 수 있습니다.
만약 분류해야하는 종속변수의 클래스가 n개라면 n*n 크기의 행렬이 생성됩니다.
쉽게 알기 위해서 이진분류(종속변수의 클래스2개 맞다, 틀리다) 에 대한 오차 행렬 (2*2)을 알아봅시다.
2) 어떻게 읽나요?
쉽게 읽는 방법은 다음과 같습니다.
예를 들면) TP
1. 앞글자
앞글자 T는 실제와 예측이 같다면 (실제 TRUE, 예측 TRUE 또는 실제 FALSE, 예측 FALSE) T
다르다면 F 입니다.
2. 뒷글자
뒤의 P는 예측의 결과입니다. TRUE라고 예측했으면 T, FALSE 라고 예측했으면 N 입니다.
3) 언제 True이고, 언제 False 인가요?
보통 적은 수의 데이터에 True, 그렇지 않은 데이터에 False를 부여합니다.
암 판단 - 암 환자 True, 일반 사람 False
스팸메일 분류 - 스팸메일 True, 일반메일 False
2. Accuracy ( 정확도 )
1) 정의
전체 데이터 중 올바르게 예측한 비율
TP + TN / (TP + FN + FP + TN)
2) 단점
예측하려고 하는 종속변수의 비율이 불균형할때 가치가 낮아집니다.
3. Recall ( 재현율 )
1) 정의
실제 true 중 예측 true의 비율
예측 true / 실제 true = TP / (TP + FN)
2) 쉽게 외우는 법
재실예
재현율을 실제 true 분의 예측 true ~
이름 처럼 외웁시다. 몇일 지나도 잊어버리지 않습니다.
3) 언제 중요할까요?
재현율이 중요한 경우는 실제 True를 False로 잘못판단하면 큰일나는 경우입니다.
즉, True가 중요한 경우
예시) 암 판단
암판단 양성인 환자를 음성으로 판단하면 생명에 대한 위험이 큽니다. 다만, 음성인 사람을 양성으로 판단하면 (물론 그러면 안되겠지만) 상대적으로 생명에 대한 위험은 작습니다.
4. precision ( 정밀도 )
1) 정의
예측 true 중 실제 true의 비율
실제 true / 예측 true = TP / (TP + FP)
2) 쉽게 외우는 법
정예실
정밀도는 예측 true 분의 실제 true ~
3) 언제 중요할까요?
재현율이 중요한 경우는 실제 False를 True라고 판단하면 안되는 경우 입니다.
즉, False가 중요한 경우
예시) 스팸메일 분류기
( 스팸메일의 수가 상대적으로 적기 때문에 스팸메일이 True, 일반메일이 False )
True인 스팸메일을 False인 일반메일로 분류해도 업무상 크게 무리는 없습니다. 하지만, 실제False인 일반메일을 True인 스팸메일로 분류하게 되면 안됩니다.
5. F1 Score
1) 정의
재현율과 정밀도의 조화평균
재현율과 정밀도가 얼마나 조화를 이루는지, 한쪽으로 치우치지는 않았는지를 나타냅니다.
한쪽으로 치우치면 F1 Score의 값이 낮게 나옵니다.
2 recision recall / ( precision + recall )
2) 조화평균
조화평균이라는 단어가 낯설 수 있습니다.
평균에는 크게 3가지가 있습니다.
1. 산술평균
2. 조화평균
3. 기하평균
우리가 일반적으로 사용하는 평균이라는 단어는 산술 평균을 의미합니다.
조화평균은 다음과 같이 계산합니다.
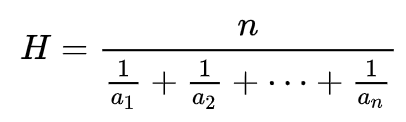
3) 왜 알아야하나요?
재현율과 정밀도는 한쪽이 높아지면, 다른쪽이 낮아지는 관계 ( Trade-off 관계) 입니다. 만약, 재현율이 중요해서 높이려고 한다면, 정밀도가 낮아지게 됩니다.
6. Threshold ( 임계값 )
1) 의미
임계값을 조절하는 방법으로 recall 또는 precision을 높일 수 있습니다.
재현율 = 예측 true / 실제 true = TP / (TP + FN)
TP를 높이면 재현율이 올라갑니다.
정답일 확률은 0~1 사이의 값을 가집니다. 보통 0.5를 임계값으로 가집니다. (0.5 이상은 정답, 0.5 미만은 오답)
만약 임계값을 0.1로 낮춘다면, 대부분의 데이터에 대해 정답이라고 생각할 것이고 그렇다면 TP가 커져 Recall이 높아집니다.
7. ROC curve, AUC
1) ROC curve
ROC curve는 FPR (False Positive Rate)이 변할 때 TPR (True Positive Rate) 이 어떻게 변하는지를 나타내는 곡선입니다.
2) TPR
재현율과 같고, 민감도라고 부릅니다.
TPR = TP / (TP + FN)
3) FPR
FPR = FP / (FP + TN)
4) 어떻게 그려지지?
임계값 (Threshold) 가 1이면 확률이 1일때만 True 라고 예측하기 때문에 FP (실제 False인데 True라고 예측하는 경우) 가 0입니다.
결과적으로 FPR이 0이 됩니다.
임계값 (Threshold) 가 0이면 확률이 모두 True 라고 예측하기 때문에 TN (실제 False인데 False 라고 예측하는 경우) 가 0입니다.
결과적으로 FPR이 1이 됩니다.
따라서, 임계값을 1~0으로 거꾸로 조절하면서 그때마다 FPR에 따른 TPR을 계산후 곡선을 그립니다.
4) AUC
ROC 커브의 아래 면적을 의미합니다.
랜덤일때 0.5의 값을 가집니다. 따라서, 0.5미만은 의미없는 모형이라고 판단합니다.
1에 가까울수록 좋은 모형이라고 판단합니다.
8. 그래서 뭐 쓰라고요?
Accuracy, Recall 등등 말했지만 살짝 체감이 안되는 부분이 있습니다.
만약, 캐글과 같은 데이터분석 대회에서는 다음과 같은 예시가 있습니다.
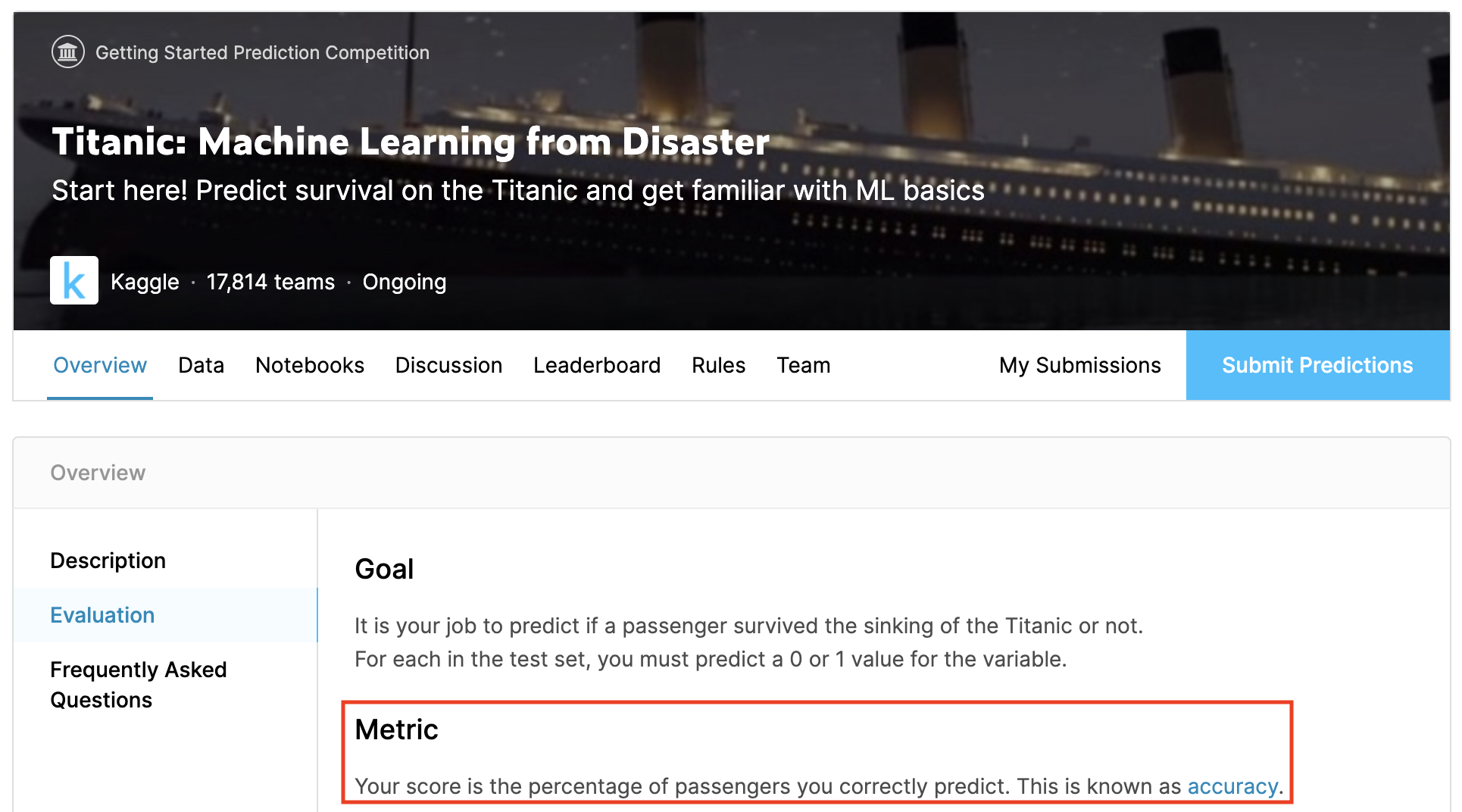
1) 타이타닉 생존자 분류
분류모델의 성능 평가 지표로 정확도를 사용합니다.
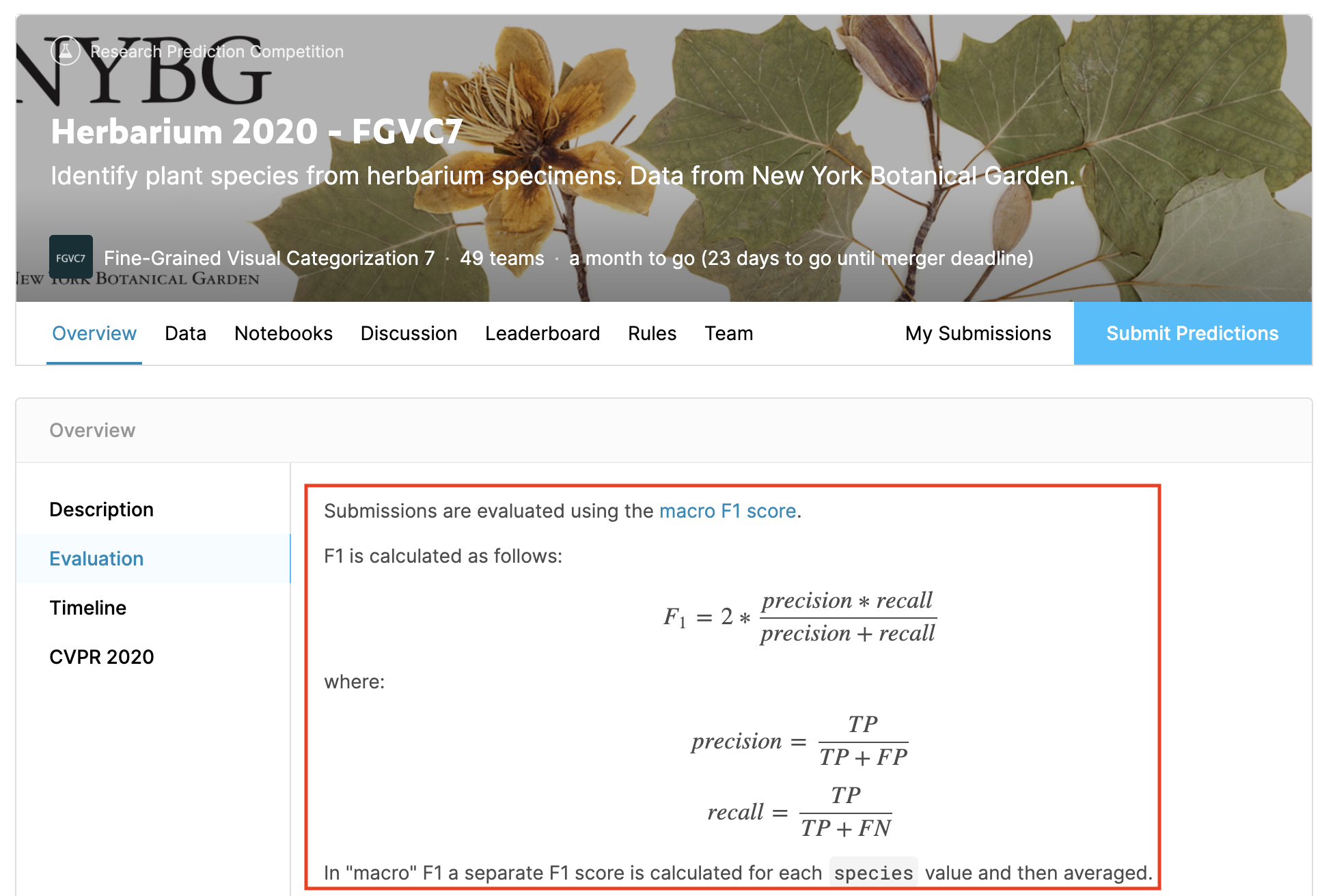
2) 식물종류 판별
성능 평가 지표로 F1 Score를 사용합니다.
3) 정리
데이터 분석의 목적, 평가 방법에 어울리는 성능 평가 지표를 활용하시면됩니다.
다만, 제 경험상 정확도를 구하는 문제는 accuracy만 보기 보다는 auc score를 더 고려하는게 점수가 높게 나오더라구요.
9. python 실습
사이킷런에 있는 유방암 데이터에 대해 이진분류모델을 생성할 것 입니다.
그리고 accuracy, precision, recall, f1 score, auc로 모델을 평가해봅시다.
1) 데이터 불러오기
사이킷런의 유방암 데이터를 가져옵니다.
from sklearn.datasets import load_breast_cancer
# 데이터는 파이썬의 자료구조인 딕셔너리 형태입니다.
cancer = load_breast_cancer()
# 딕셔너리 데이터는 key, value로 이루어져있습니다.
# 키를 이용하면 데이터의 값에 접근할 수 있기 때문에 먼저 key를 출력해봅니다.
cancer.keys()
2) 데이터 프레임
데이터를 조금더 쉽게 보고, 모델을 쉽게 생성할 수 있도록 데이터 프레임으로 만들어줍니다.
import pandas as pd
# 독립변수를 가져옵니다.
data_list = cancer["data"]
# 독립변수의 이름을 가져옵니다.
column_list = cancer["feature_names"]
# 종속변수를 가져옵니다. (유방암 여부)
target_list = cancer["target"]
# 먼저, 독립변수만을 가지고 데이터프레임을 만들어줍니다.
data = pd.DataFrame(data=data_list, columns=column_list)
# feature 이름을 target으로 지정하고 종속변수를 넣어줍니다.
data["target"] = target_list
# 데이터의 1. 행의 개수, 2) 열의 개수 출력
print(data.shape)
# 생성한 데이터 프레임 확인
data.head(1)
3) classifier 생성
분류 모델로 랜덤 포레스트를 선택했습니다.
선택한 이유는
1. 종속변수가 범주형일때 분류모델로 사용가능
1. 독립변수가 연속형 변수(numeric)
# 랜덤 포레스트 모델을 가져옵니다.
# 앙상블 기법에 속합니다.
from sklearn.ensemble import RandomForestClassifier
# 랜덤 포레스트 모델을 새성합니다.
rf = RandomForestClassifier()
# 독립변수를 만들어줍니다.
# target은 종속변수이기 때문에 제거해줍니다.
x = data.drop(columns=["target"], axis=1)
# 종속변수를 만들어줍니다.
y = data["target"]4) 평가
우리는, 모델을 평가하기 위한 테스트 데이터셋이 없습니다. 훈련 데이터셋만 가지고 있습니다.
보통 데이터 분석 대회에서 교차검증을 수행하기 때문에 교차검증을 사용하는 예시로 작성했습니다.
교차검증은 데이터 전체의 80%는 훈련, 20%는 테스트 데이터셋으로 사용하는 방법입니다.
# 평가를 위한 cross_validate를 가져오고, 교차검증을 위한 KFold를 가져옵니다.
from sklearn.model_selection import cross_validate, KFold
# 평가지표 5개를 가져옵니다.
# 정확도, 정밀도, 재현율, f1_score, auc
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
# 교차검증을 설정합니다.
# n_splits=20의 의미는 전체의 19/20은 훈련, 1/20은 테스트 데이터로 사용한다는 의미입니다.
# 이렇게 하면 총 20번 교차검증을 수행합니다.
k_fold = KFold(n_splits=20, random_state=1, shuffle=True)
# 평가지표를 객체로 만들어줍니다.
scoring = {'accuracy' : make_scorer(accuracy_score),
'precision' : make_scorer(precision_score),
'recall' : make_scorer(recall_score),
'f1_score' : make_scorer(f1_score),
'roc_auc_score': make_scorer(roc_auc_score)
}
result = cross_validate(rf, x, y, cv=k_fold, scoring=scoring)
# 평가 결과가 가진 키를 출력해봅니다.
result.keys()
5) 출력
# 20번 교차검증을 수행했기 때문에 20개의 평가지표들의 평균값을 구해줍니다.
accuracy = result["test_accuracy"].mean()
precision = result["test_precision"].mean()
recall = result["test_recall"].mean()
f1_score = result["test_f1_score"].mean()
auc_score = result["test_roc_auc_score"].mean()
print("accuracy: {0: .4f}".format(accuracy))
print("precision: {0: .4f}".format(precision))
print("recall: {0: .4f}".format(recall))
print("f1_score: {0: .4f}".format(f1_score))
print("auc_score: {0: .4f}".format(auc_score))

좋은 포스트 감사합니다! 보면서 이해했어요! 그런데 중간에 오타가 있어 수정이 필요할거같아요 (4. precision ( 정밀도 ) 3) 언제 중요할까요? 에서 '재현율이 중요한 경우는'으로 작성되어있습니다ㅠㅠ '정밀도가 중요한 경우'로 수정되어야 할 거 같아요. 감사합니다