
문제❓
CNN을 사용하여 강아지와 고양이를 분류하는 모델 생성하기
코드💻
1. 강아지와 고양이 데이터 세트
https://www.kaggle.com/c/dogs-vs-cats/data 에서 데이터를 받아왔다.
2. 라이브러리 설치
3. 이미지 출력
가져온 데이터 중의 한개의 강아지 이미지를 출력해보았다.
from matplotlib import pyplot as plt
from matplotlib.image import imread
image = imread("./PetImage/train/dog/dog.1.jpg")
plt.imshow(image)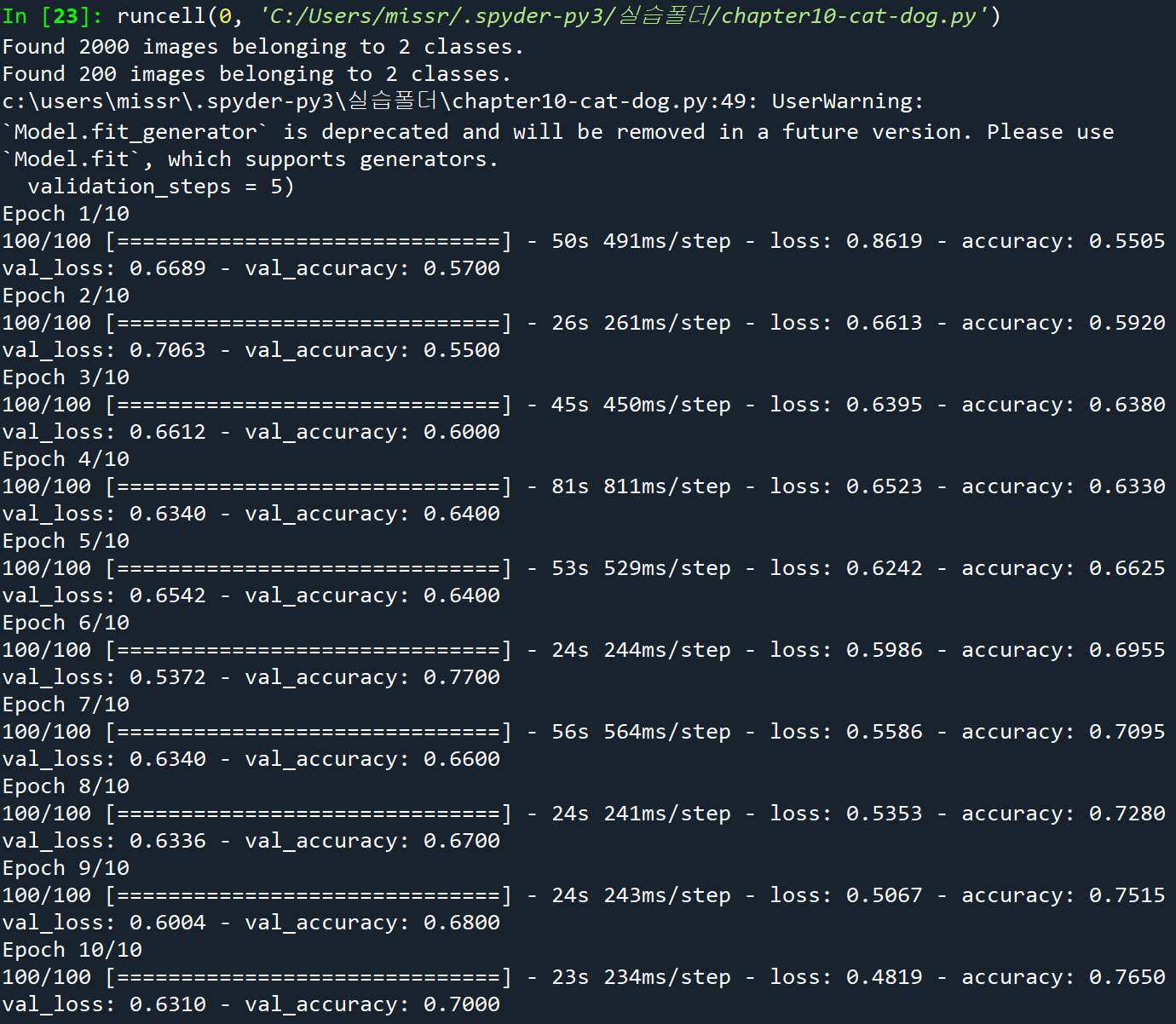
4. 신경망 모델 생성
from tensorflow.keras import models, layers
train_dir = './PetImage/train'
test_dir = './PetImage/test'
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation = 'relu', input_shape = (128, 128, 3)))
model.add(layers.MaxPooling2D(2,2))
model.add(layers.Conv2D(64, (3,3), activation = 'relu'))
model.add(layers.MaxPooling2D(2,2))
model.add(layers.Flatten())
model.add(layers.Dense(units = 512, activation = 'relu'))
model.add(layers.Dense(units = 1, activation = 'sigmoid'))
model.compile(optimizer = 'adam', loss= 'binary_crossentropy', metrics = ['accuracy'])5. 이미지 전처리
신경망에는 0에서 1사이의 실수만 투입할 수 있다.
따라서 아래의 전처리를 수행해주어야 한다.
- JPG 이미지 파일을 읽는다.
- JPG 압축을 풀어서 RGB 형태로 픽셀값을 복원한다.
- 픽셀값들을 실수 형식의 넘파이 텐서로 변환한다.
- 0~255 사이의 픽셀값들을 0.0~1.0 사이의 실수로 스케일링한다.
이러한 일련의 과정을 Keras에서 수행해준다.
바로 ImageDataGenerator()!
이전 장에서 언급했지만, 해당 메서드는 어떤 디렉토리의 이미지를 읽어서 압축을 풀고 픽셀갑들을 0.0~1.0 사이의 실수로 스케일링한다. 여기서 추가로 이미지를 회전시키거나 확대/축소하고 밀림 변환까지 수행하면서 이미지의 개수를 늘린다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size = (128, 128),
batch_size = 20,
class_model = 'binary'
)
test_generator = test_datagen.flow_from_directory(test_dir,
target_size = (128, 128),
batch_size = 20,
class_model = 'binary')6. 훈련
데이터 제너레이터를 사용하는 경우, fit()이 아니라 fit_generator()를 사용한다.
history = model.fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 10,
validation_data = test_generator,
validation_steps = 5)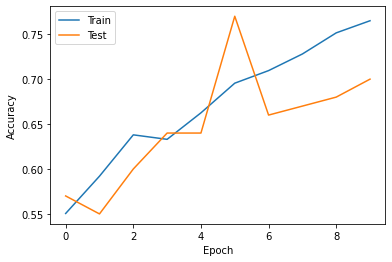
7. 학습 결과 그래프 표시
훈련 데이터와 검증 데이터의 정확도를 표시해보았다.
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend(['Train','Test'], loc = 'upper left')
plt.show()
백엔드 개발은 취미인 AI 개발자🥹