- Feed-forward Networks(FNN) : 이미지 및 비디오 처리에는 확장성 부족
- CNN : 이미지 및 비디오 처리에 특화됨
- Feedforward neural networks(FNN)

-> FNN에서는 한 층의 모든 노드가 다음 층의 모든 노드와 연결됨
-> 각 연결에는 가중치가 있으며, 학습 알고리즘을 통해 학습되어야 함
- FNN의 한계점
ex) 64 X 64 픽셀의 grayscale(흑백) 이미지를 입력으로 할 경우
각 픽셀은 0~255사이의 값으로 표현
64 x 64 x 1 = 4096(행 x 열 x 채널)개의 값
FNN의 입력층 : 4096개의 노드를 가짐
다음 층이 500개의 노드를 가진다면, 완전 연결 구조이므로 4096 x 500 = 2048000개의 가중치가 필요함
ex) 64 x 64 픽셀의 컬러 이미지의 경우
64 x 64 x 3 = 12288개의 값으로 표현
가중치는 12288 x 500 = 6144000개
-> 복잡한 문제를 해결하기 위해 FNN에서는 여러 개의 Hidden layer가 필요함 -> 가중치가 너무 많아지는 문제 발생
-> 가중치가 너무 많아지면, 탐색 공간의 차원이 증가하여 학습이 더 어려워지고, 학습에 더 많은 시간과 자원이 소모되고, overfitting의 가능성이 증가함
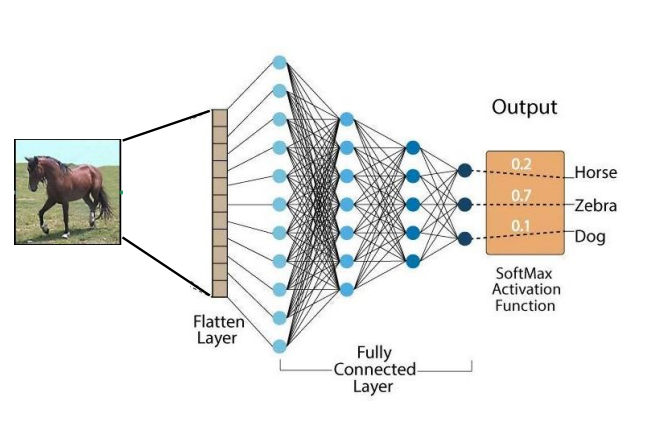
-> 2D 이미지가 입력층에서 1D 벡터로 표현되어 데이터의 공간적 관계(spatial relationship)가 무시됨
- Inspiration for CNN
1959년, Hubel과 Wiesel은 뇌의 시각 피질이 시각 정보를 처리하는 방식을 이해하기 위해 실험을 진행
고양이 앞에서 밝은 선을 움직이면서 시각 피질의 뉴런 활동을 기록
- 특정 각도나 위치에서 밝은 선을 보여주면 일부 세포가 발화
: 단순 세포(simple cells) - 다른 세포들은 각도나 위치와 상관없이 밝은 선을 보여주면 발화
이 세포들은 움직임을 감지하는 것처럼 보임
: 복합 세포(complex cells) - 복합 세포는 여러 단순 세포로부터 입력을 받는 것처럼 보임
계층적 구조를 가지고 있음
▪ Hubel과 Wiesel은 1981년에 노벨상을 수상
▪ 복합 세포와 단순 세포에서 영감을 받아, Fukushima는 1980년에 Neocognitron을 제안
-> 계층적 신경망으로, 일본어 손글씨 인식에 사용됨
-> 최초의 CNN이었으며 자체 학습 알고리즘을 가짐
▪ 1989년에 LeCun은 역전파(backpropagation)를 통해 학습되는 CNN을 제안
▪ CNN은 ImageNet 챌린지에서 다른 모델들을 능가하면서 인기를 얻음
-> 객체 분류 및 탐지 대회
-> 수백 개의 객체 범주와 수백만 개의 이미지로 구성
-> 2010년부터 현재까지 매년 개최
< ImageNet 챌린지에서 우승한 주목할 만한 CNN 아키텍처 >
-> AlexNet (2012), ZFNet (2013), GoogLeNet & VGG (2014), ResNet (2015)
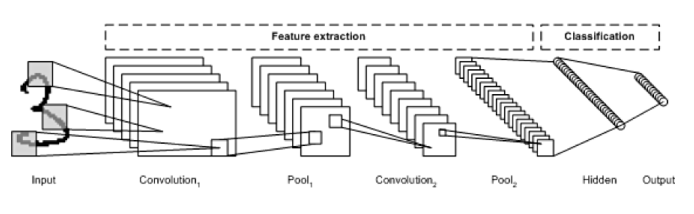
- CNN
* Input layer
: 28 x 28 픽셀의 grayscale 이미지의 경우, 2D 형태로 28 x 28 행렬로 입력됨
-> FNN과 달리 입력을 1차원 벡터로 "Flatten"하지 않음!
-> 공간적 관계를 더 쉽게 포착 가능

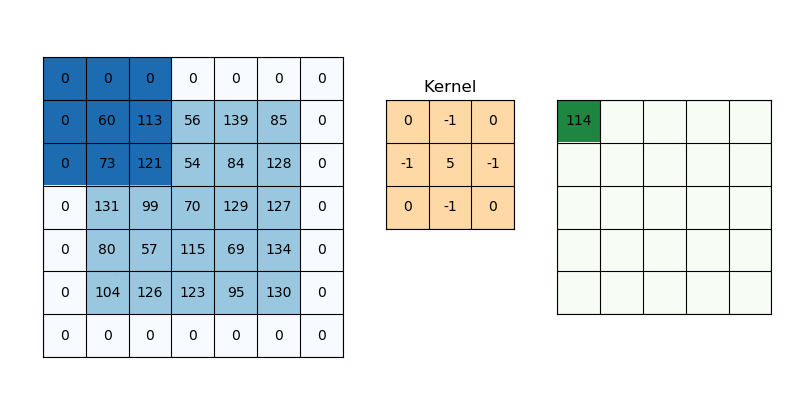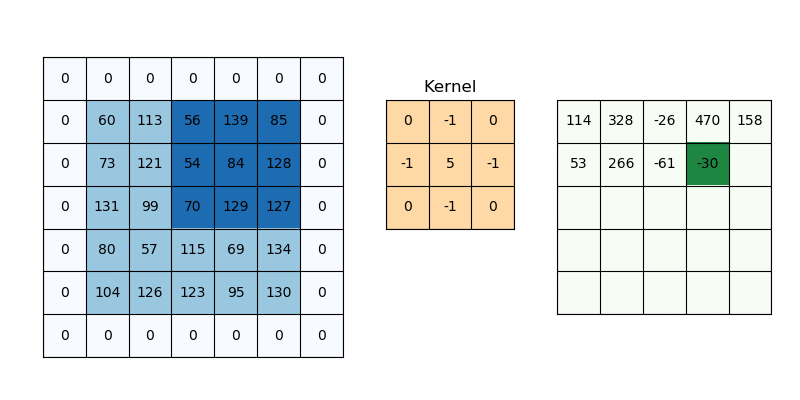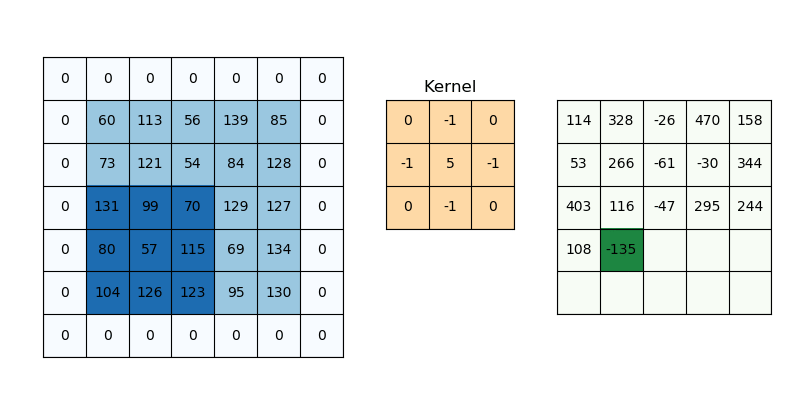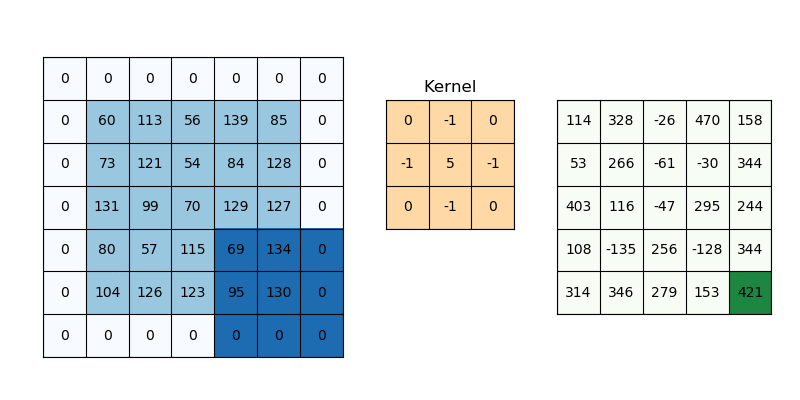
* Convolution layer
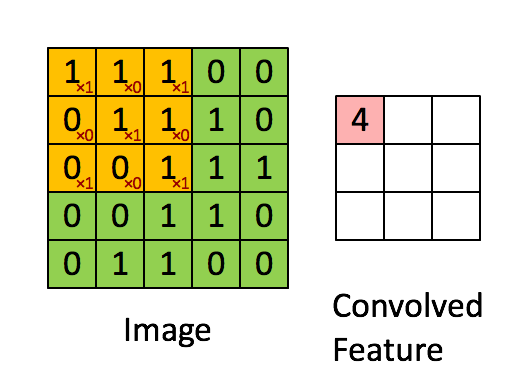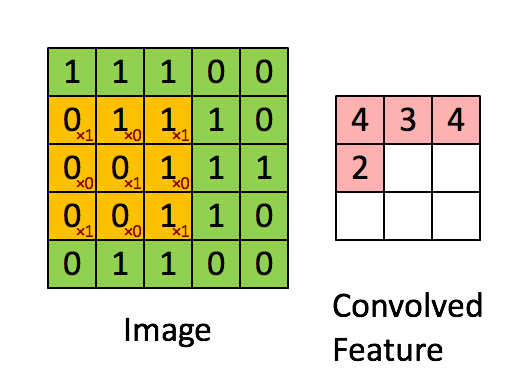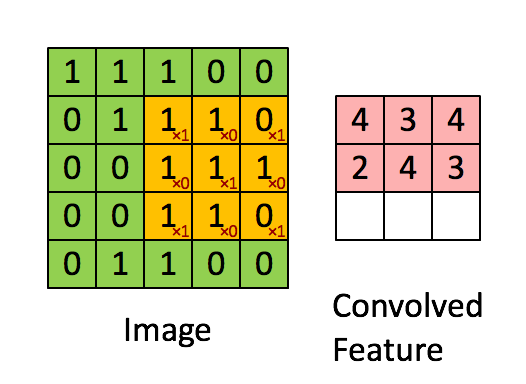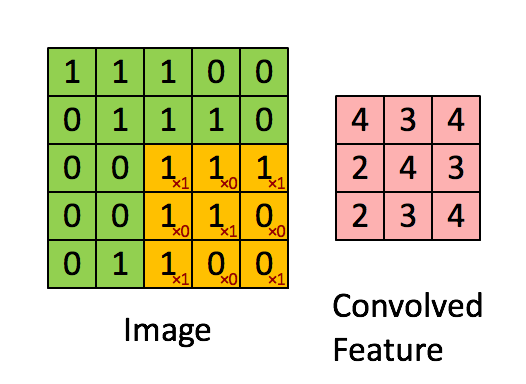
: 여러 filters(kernels)로 구성
: 2D 이미지에 대한 filter도 2D

-> 5x5 이미지

-> 3x3 필터

-> 픽셀값에 필터값을 곱해서 모두 더함
< Convolution operator parameters >
* Filter size
: 5x5, 3x3 등 다양하게 설정 가능
: 너무 큰 크기는 피하는 게 좋음 (학습 알고리즘이 필터 값(가중치)을 학습해야 하기 때문)
: 짝수보다 홀수 크기가 선호됨 (출력 픽셀 주위에 모든 입력 픽셀이 고르게 배치되는 좋은 기하학적 특성이 있음, 중심 픽셀 존재, 대칭성 존재)
* Receptive Field (수용 영역)
: 필터가 위치하는 영역
* Padding
: 3x3 필터를 5x5 이미지에 적용하면 3x3 이미지가 만들어지므로, 이미지 크기가 감소됨
-> 이미지 크기를 그대로 유지하려면 Padding을 사용함
-> 1x1 padding인 경우
* Stride
: 필터를 오른쪽 or 아래로 몇 픽셀씩 이동할지를 결정하는 값
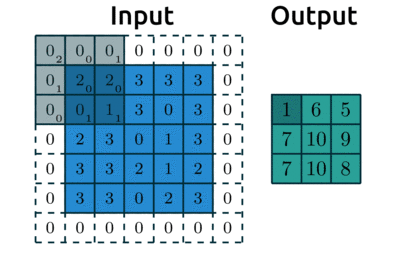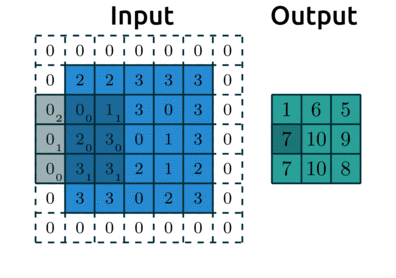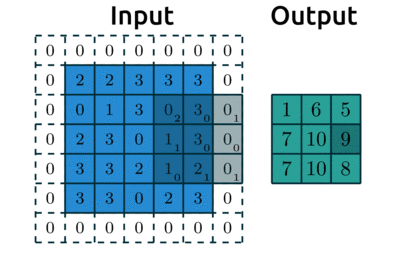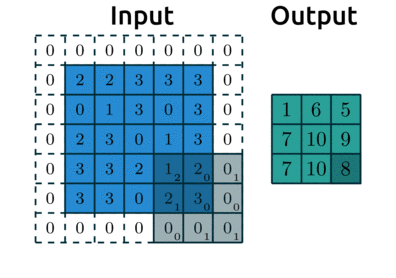
-> stride 2인 경우
* Dilation (팽창)
: 컨볼루션 과정에서 필터의 수용 영역(Receptive Field)을 확장하는 기법
: 필터가 한 번에 더 넓은 범위의 픽셀을 처리할 수 있도록 해주는 방법
-> 더 많은 공간적 정보를 고려하면서, 필터의 크기나 계산량을 크게 늘리지 않고 이미지를 처리할 수 O
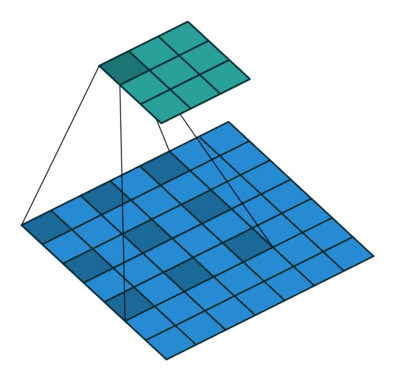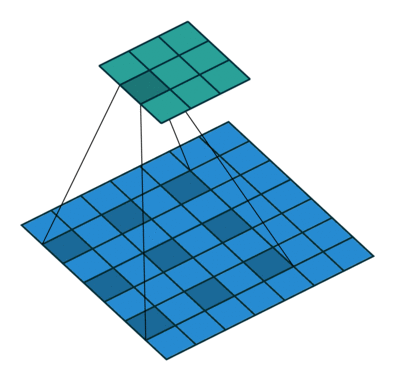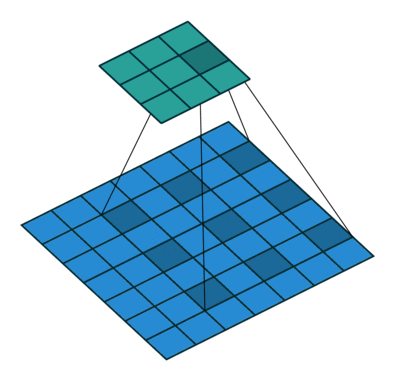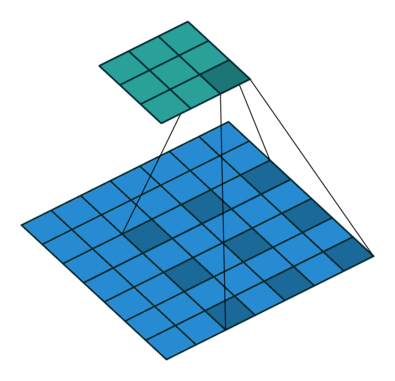
-> Dilation rate : 2 (커널 사이의 간격)
- Dilated Convolution: WaveNet
- 목표
: 효율적인 오디오 모델링을 위한 팽창 인과 컨볼루션(dilated causal convolution) 도입
: 음향 특징으로부터 파형을 생성할 수 있는 신경 보코더(neural vocoder)

- A Stack of causal convolution layer
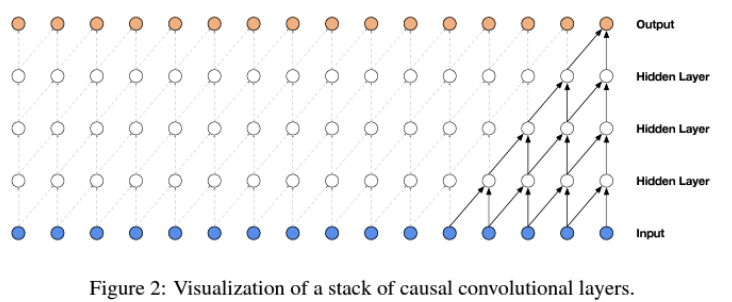
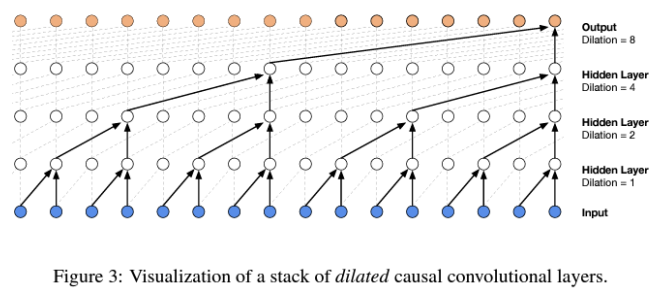
- A stack of dilated causal convolutional layer
-> 파형 모델링(waveform modeling)에서 필터의 수용 영역을 효과적으로 확장함
- CNN
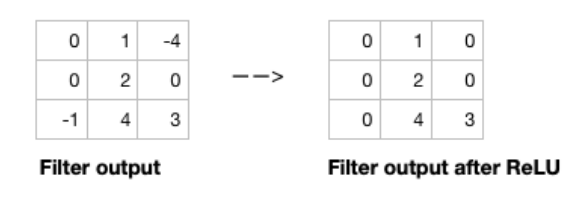
* Activation function
: 필터를 전체 이미지에 적용한 후, 비선형성을 도입하기 위해 출력에 활성화 함수를 적용함
-> CNN에서 선호되는 활성화 함수는 ReLU
-> ReLU는 양수인 출력 값을 그대로 두고, 음수인 값은 0으로 대체함
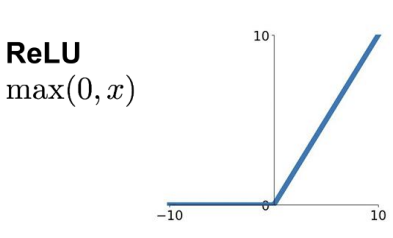
- Single channel 2D convolution
: (B, 1, H, W) 로 표기 가능
B : Batch size(한 번에 모델로 입력되는 데이터(이미지) 개수)
1 : Channel 수
H : 이미지의 Height(픽셀 수)
W : 이미지의 Width(픽셀 수)
- Triple channel 2D convolution
: (B, 3, H, W) 로 표기 가능
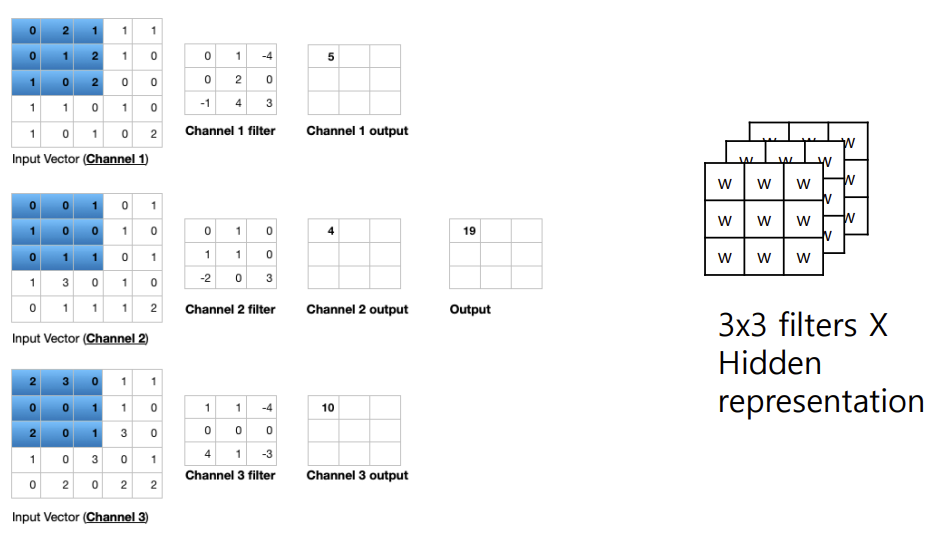
* Change channel size
: 다중 채널 2D 필터의 출력은 단일 채널 2D 이미지임
-> 여러 필터를 적용하면 다중 채널 2D 이미지가 생성됨
ex) 입력 이미지가 28 x 28 x 3 (행 x 열 x 채널)일 경우
3 x 3 필터에 1 x 1 패딩을 적용하면 28 x 28 x 1 이미지를 얻음
이와 같은 필터를 15개 적용하면, 28 x 28 x 15 이미지를 얻음
-> 입력 데이터의 채널 수가 적더라도 더 많은 필터를 적용하면, 출력에서 채널 수를 늘릴 수 있음
-> 필터를 쌓아서 여러 개의 출력 채널을 만들면, 모델이 입력 데이터에서 더 다양한 특징을 추출할 수 있게 되어, 더 복잡한 패턴이나 정보를 학습할 수 있게 됨
* Pooling layer
: 입력의 공간적 차원을 줄이기 위해 다운 샘플링을 수행함
-> 이를 통해서 파라미터의 수가 감소함
-> 학습 시간/계산을 줄여줌
-> overfitting의 가능성을 줄여줌
- 가장 인기있는 유형 : Max pooling (2 x 2 필터와 stride 2 를 사용)
-> 입력 데이터를 이동하면서 가장 큰 값을 반환함
<Max Pooling 동작 방식>
-
작은 구역으로 분할: 입력 데이터(특징 맵)를 작은 구역으로 나눔. 보통 2x2 크기의 구역을 사용.
-
최대값 선택: 각 구역에서 가장 큰 값을 선택하여 출력으로 반환. 예를 들어, 2x2 구역에서 4개의 값 중 가장 큰 값을 선택.
-
다운샘플링: 이렇게 구역별로 최대값을 선택함으로써, 출력 데이터의 크기를 줄이고 중요한 특징을 유지.


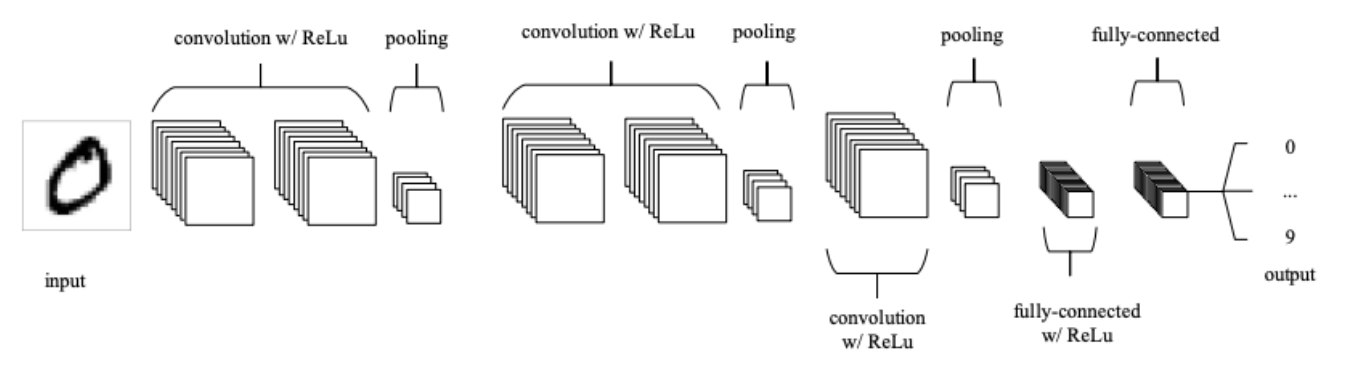
* Fully connected layer
: CNN의 마지막 층
: 이전 층의 모든 노드를 이 완전 연결 층과 연결함
-> 이미지 분류를 담당하는 층
- CNN은 객체의 특성(머리, 꼬리, 연결부, 가장자리)을 포착하고 숫자를 인식하도록 학습됨
-> 이러한 국부적 연결성을 포착하기 위해 2차원 정보를 사용함
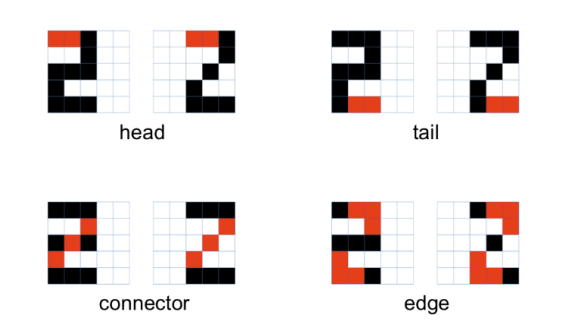
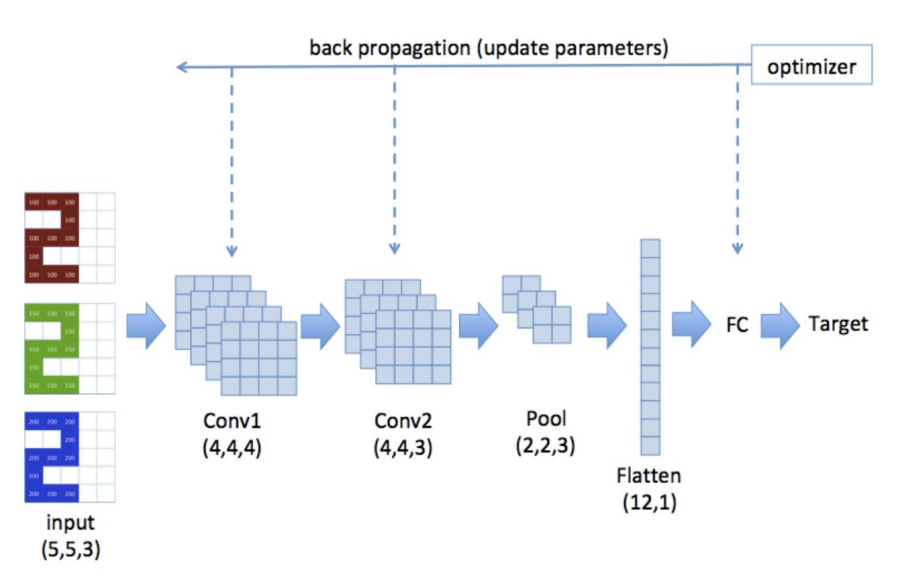
-> 필터의 커널 가중치는 학습 중에 업데이트됨
- Application: Computer Vision
* Deep Learning-based Image Classification

* Object Detection
: 이미지나 비디오 내에서 객체 감지 및 위치 찾기
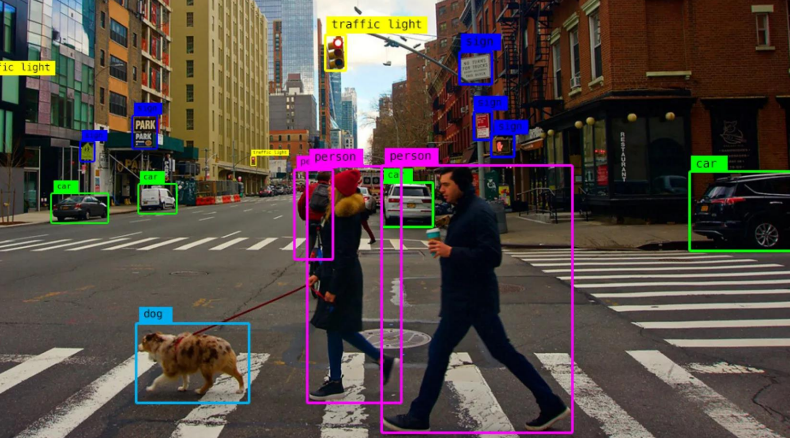
- You Only Look Once (YOLO) [2016]


- Deep Learning based Objective Detection (AlexNet~)
- YOLO-World [2024]

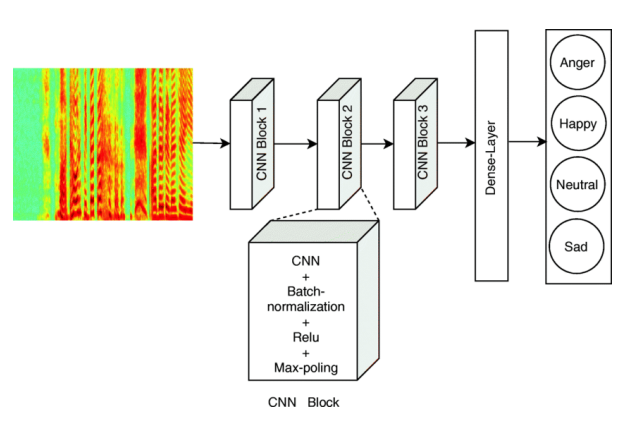
- Application: Speech
* Speech Emotion Recognition
* Waveform Generation

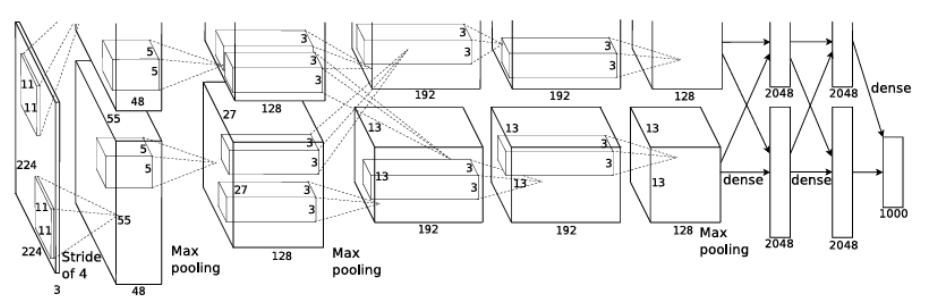
- AlexNet
: ImageNet Classification을 위한 Deep Convolutional Neural Networks
-> ReLU 비선형성
-> 데이터 증강(Augmentation)
-> Dropout
* ImageNet
: ImageNet 프로젝트는 시각적 객체 인식 소프트웨어 연구에 사용되도록 설계된 대규모 시각 데이터베이스
: 1400만 장 이상의 이미지가 프로젝트에 의해 수작업으로 주석 처리되었으며, 그 중 최소 100만 장의 이미지에는 객체가 포함된 경계 상자(bounding box)도 제공
* ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
: 2010년부터 ImageNet 데이터셋은 이미지 분류 및 객체 탐지의 벤치마크로 사용되는 ImageNet 대규모 시각 인식 챌린지(ILSVRC)에서 사용되고 있음
-> 이 챌린지는 약 100만 장의 이미지와 1,000개의 카테고리로 구성된 ImageNet의 하위 집합을 사용함
-> 입력 이미지의 카테고리를 예측하도록 학습됨

* ILSVRC 2010
: 약 100만 장의 이미지와 1,000개의 카테고리로 구성된 ImageNet의 하위 집합을 사용
: 수백만 개의 이미지에서 수천 개의 객체를 학습하려면, 큰 학습 용량을 가진 모델이 필요함
-> CNN은 연결과 파라미터가 훨씬 적기 때문에 훈련하기 더 쉬움
-> CNN의 비용이 많이 들지만, GPU가 CNN 훈련을 촉진함
<CNN이 강력한 이유>
* 지역 불변성(Local Invariance)
-> 합성곱 필터가 입력 이미지를 슬라이딩하면서, 우리가 찾고자 하는 객체의 정확한 위치는 크게 중요하지 않음
-> 위치 무관성: 필터는 이미지 전체를 탐색하면서 특징을 찾기 때문에, 특징이 이미지의 어느 위치에 있든지 그 패턴이 발견됨!
* 구성적 특성(Compositionality)
-> 사람들은 세상을 그 구성 요소들의 합으로 이해함
-> 사건은 여러 행동으로 구성되고, 객체는 여러 부분으로 나눌 수 있으며, 이 문장은 일련의 단어들로 구성됨
-> CNN의 계층 구조 → 큰 표현 능력을 제공
CNN은 여러 계층(layer)으로 이루어져 있는데, 하위 계층은 단순한 특징을, 상위 계층은 더 복잡한 특징을 학습함
ex)
첫 번째 계층은 단순한 엣지(선, 모서리)를 감지
다음 계층에서는 여러 엣지를 결합하여 모양이나 패턴을 인식
더 높은 계층에서는 이 모양들이 결합되어 특정 객체(예: 얼굴, 동물)를 인식
- AlexNet [2012]
* AlexNet의 전반적인 구조
: Convolutional layer 5개 + Fully-connected layer 3개
1) ReLU 비선형성
: Sigmoid와 Tanh 함수는 gradient가 거의 0이 되는 문제를 일으키지만, ReLU는 그렇지 않음
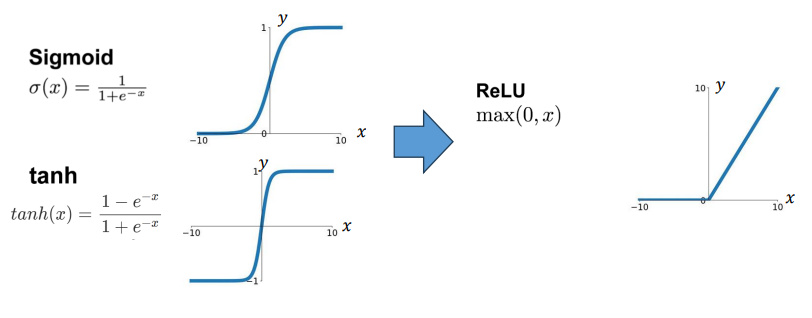
- 빠른 수렴 (대형 모델의 성능에 큰 영향을 미침)
<ReLU의 장점>
-> 다른 활성화 함수에 비해 계산이 단순, Gradient vanishing 문제가 적음, 뉴런의 희소성(Sparsity)을 촉진하여 더 빠른 학습 속도와 효율적인 가중치 업데이트를 가능하게 함!
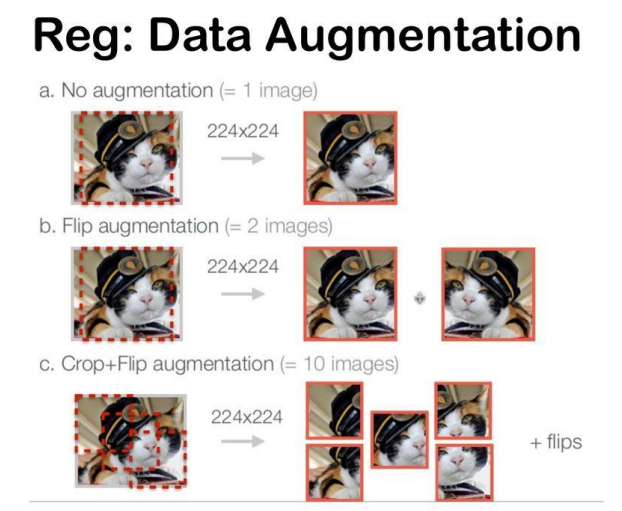
2) Data Augmentation (데이터 증강)
: AlexNet은 데이터 증강 기법을 사용하여 입력 데이터를 인위적으로 다양하게 변형함
- Flip augmentation
- Crop augmentation
- PCA를 이용한 색상 변화 (RGB 픽셀 값 증강)
-> 이미지 자르기, 수평 반전, 색상 변화 등으로 학습 데이터셋이 풍부해져, 모델이 특정 패턴에 과도하게 맞춰지는 것(Overfitting)을 방지하고, 일반화 성능을 향상시킴!
3) Dropout
: 학습 중에 신경망에서 뉴런(과 그 연결)을 무작위로 제거하는 것
-> Overfitting을 크게 줄이고, 다른 정규화 기법들보다 큰 성능 향상을 제공함
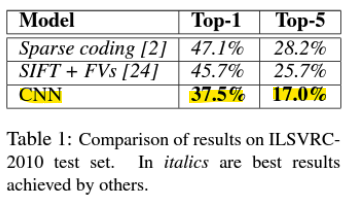
* Results
- Top-1 정확도: 모델의 답변(가장 높은 확률을 가진 답변)이 정확히 예상된 답변과 일치해야 함
- Top-5 정확도: 모델의 가장 높은 확률을 가진 5개의 답변 중 하나가 예상된 답변과 일치하면 됨
<ILSVRC 2010>
-> CNN이 이전의 방법들을 능가함
<ILSVRC 2012>
-> 깊은 CNN(Deep CNN)이 얕은 CNN(Shallow CNN) 모델보다 더 나은 성능을 보임
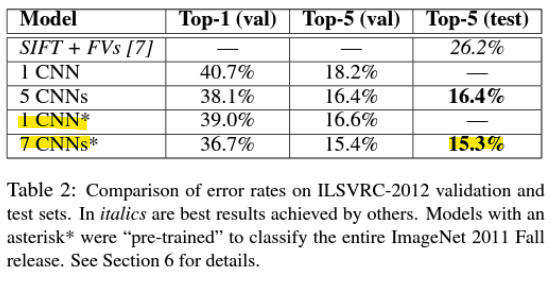
4) Pre-training
▪ 대규모 데이터셋(1500만 개 이미지, 22,000개 카테고리)으로 모델을 사전 학습시킴.
-> ILSVRC 2012에서 사전 학습된 모델을 미세 조정(Fine-tuning)하는 것은 성능을 향상시킴 (오류율 감소함)
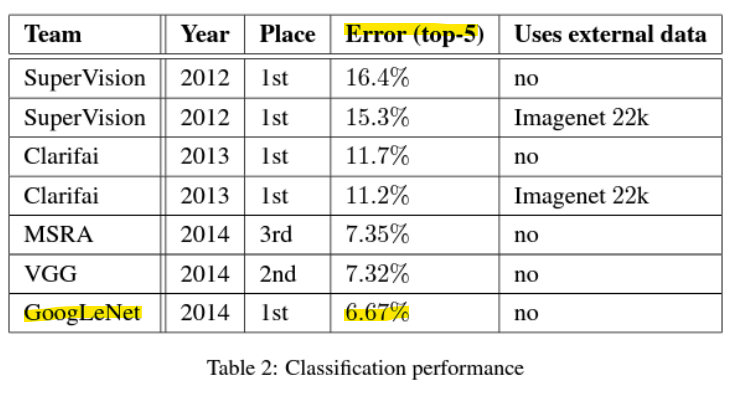
- GoogLeNet: Going deeper with convolutions [2014]
: ILSVRC 2014 1위
-> 계산 예산을 유지하면서도 네트워크의 깊이와 너비를 증가시킬 수 있도록 신중하게 설계된 디자인 덕분에 달성함
-> 22 layers의 deep networks
* 네트워크의 크기를 증가시키는 방법 (깊이와 너비 증가)
-> deep neural networks의 성능을 향상시키는 가장 간단한 방법
-> 이는 특히 대량의 레이블이 지정된 학습 데이터가 주어졌을 때, 더 높은 품질의 모델을 학습시키는 쉽고 안전한 방법
<제한점>
-> 더 큰 크기는 일반적으로 더 많은 파라미터 수를 의미하며, 네트워크가 커질수록 overfitting에 취약함 (특히 training set에서 레이블이 지정된 예시의 수가 제한적인 경우)
-> 계산 자원의 사용량이 급격하게 증가함
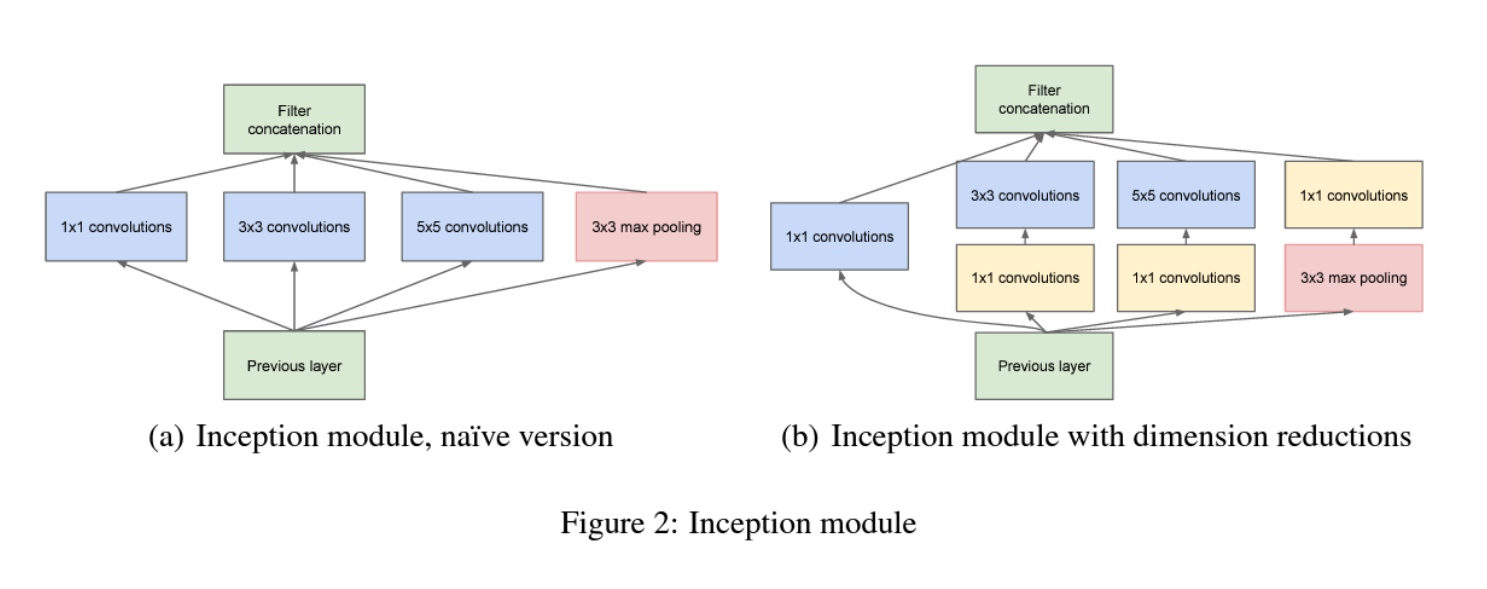
1) Inception module
: 1x1, 3x3, 5x5 합성곱(Multiple Convolutions)을 동시에 적용하고, Max Pooling도 포함시켜 다양한 크기의 특징을 동시에 추출할 수 있도록 설계됨
: 다양한 크기의 필터는 입력 데이터에서 다른 형태의 국부적인 특징(다양한 특징)을 추출함
* 1x1 합성곱 (1x1 Convolutions):
- 채널 차원 축소: 1x1 합성곱은 먼저 채널 차원을 줄이는 역할, 이를 통해 계산 비용을 줄이면서도 특징 추출이 가능함
예를 들어, 256채널을 64채널로 줄임으로써 더 큰 필터(3x3, 5x5)의 계산 비용을 크게 줄임 - 비선형성 추가: 각 1x1 합성곱에는 ReLU 활성화 함수가 추가되어 모델에 비선형성을 도입하고, 표현력을 향상시킴
* 3x3 합성곱 (3x3 Convolutions):
- 중간 크기의 국부적 특징 추출: 3x3 필터는 이미지를 조금 더 넓게 살펴보면서 중간 크기의 패턴이나 국부적인 특징을 추출함
* 5x5 합성곱 (5x5 Convolutions):
- 더 큰 특징 추출: 5x5 필터는 더 넓은 영역에서 특징을 추출. 일반적으로 크기가 큰 패턴이나 국부적 연결성을 학습하는 데 사용됨
* Max Pooling (최대 풀링):
- 차원 축소 및 중요한 정보 추출: Max Pooling은 입력 데이터에서 가장 중요한 정보를 추출하면서 데이터의 차원을 줄이는 역할
2) Auxiliary Classifier (보조 분류기)
: Gradient vanishing 문제를 줄이기 위해 사용됨
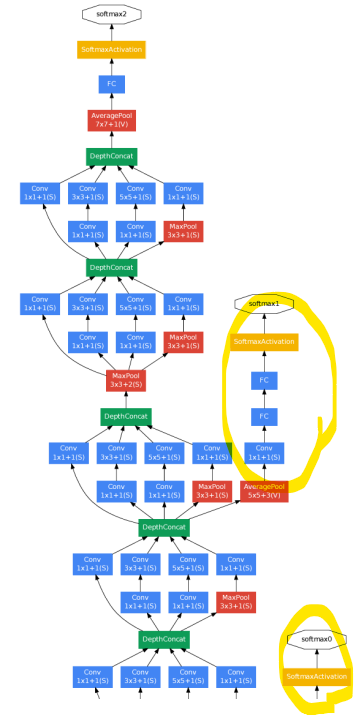
-> 보조 분류기를 통해 중간 층에서도 손실이 계산되므로, 깊은 층으로부터의 역전파 신호가 약해지지 않고 더 강한 기울기가 전달됨
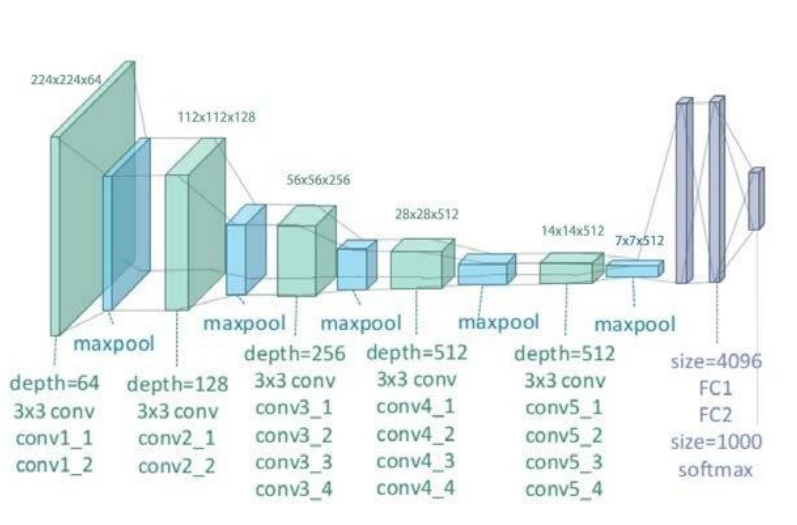
- VGGNet: VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION [2014]
: ILSVRC 2014 2등
: 19 layer deep networks
: 3x3 크기의 작은 합성곱 필터만을 사용
- 목표
-> 대규모 이미지 인식에서 합성곱 신경망의 깊이가 정확도에 미치는 영향을 조사하는 것
-> 주요 기여는 아주 작은(3x3) 합성곱 필터를 사용하는 아키텍처를 통해 깊이를 증가시키며 네트워크를 철저히 평가한 것
- 2개의 3x3 합성곱을 사용하는 것이 5x5 합성곱을 사용하는 것보다 더 효율적
- 5x5 = 25
- 2x(3x3) = 18
-> 작은 커널 크기를 사용하는 것이 훨씬 더 쉽고 더 효율적이며, 더 깊은 CNN을 구축하는 데 유리함
- 결론
- 더 깊은 합성곱 신경망으로 나아감
-> GoogLeNet [2014] : 22 layers
-> VGGNet [2014] : 19 layers
-> AlexNet [2012] : 8 layers
-
아키텍처
-> ReLU 활성화 함수
-> 1x1 합성곱을 사용하여 채널 수 감소
-> 3x3 합성곱을 사용하여 더 효율적인 필터 구성(더 큰 커널 대신) -
정규화 방법
-> 데이터 증강(Data Augmentation)
-> Dropout
