점점 어려워진다....정신을 똑바로 차리자
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams['axes.unicode_minus'] = False
get_ipython().run_line_magic('matplotlib', 'inline')
rc('font', family='Malgun Gothic')먼저 불러와야 하는 모듈들을 불러온 다음,
마이너스로 인한 오류를 방지하고,
inline 처리를 해준 다음,
폰트는 맑은 고딕을 불러와 준다.
( 이 부분은 외워질 때 까지 계속 쓰자. )
그 다음 계속해서 만들어 둔 데이터 프레임을 불러오자.
crime_anal_norm.head()
1. seaborn 모듈에서 pairplot 함수를 사용해서 상관관계 파악
# pairplot 강도,살인,폭력 3가지 값들의 상관관계 확인
sns.pairplot(data=crime_anal_norm, vars=['살인','강도','폭력'], kind='reg', height=3);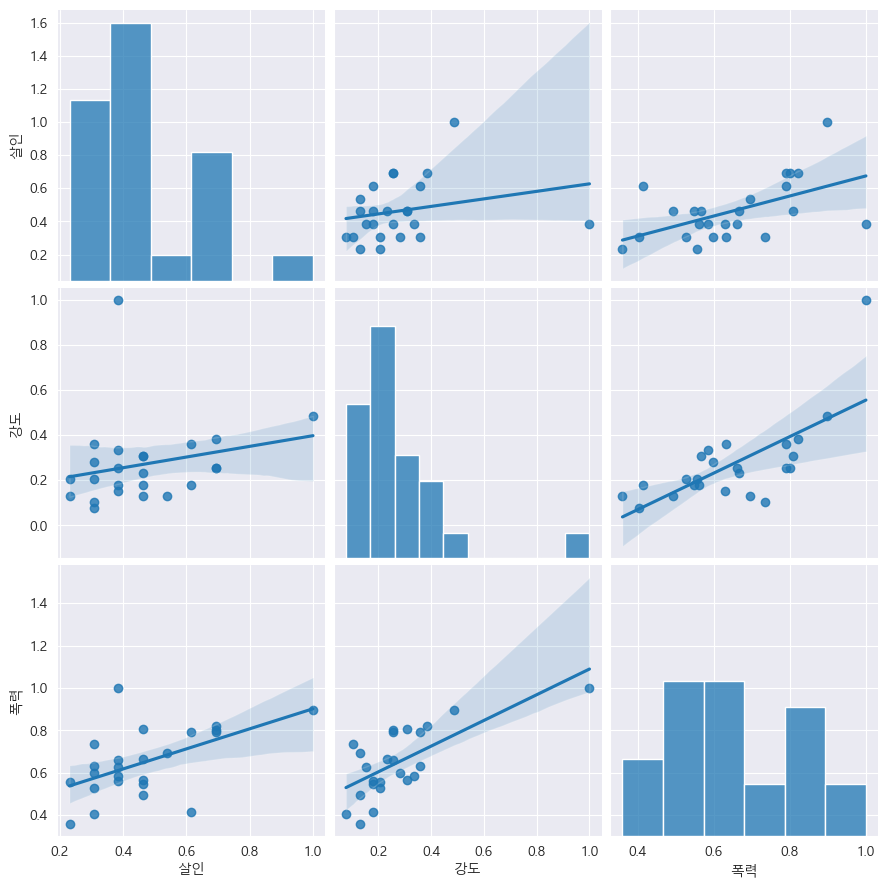
이 그래프를...어떻게 읽어야 할지 자세히는 모르겠으나 분포도를 보면서 대략적으로 대각선의 경사가 심한만큼 상관관계도 있으리라 짐작해본다.
crime_anal_norm.head()다시 한번 데이터를 불러와 보고,

이번에는 인구수, cctv , 살인, 강도 상관관계를 확인해 보자!!
# 인구수, cctv 와 살인, 강도의 상관관계 확인
def drawGraph():
sns.pairplot(data=crime_anal_norm,
x_vars=['인구수','cctv'],
y_vars=['살인','강도'],
kind='reg',
height=4)
plt.show()
drawGraph()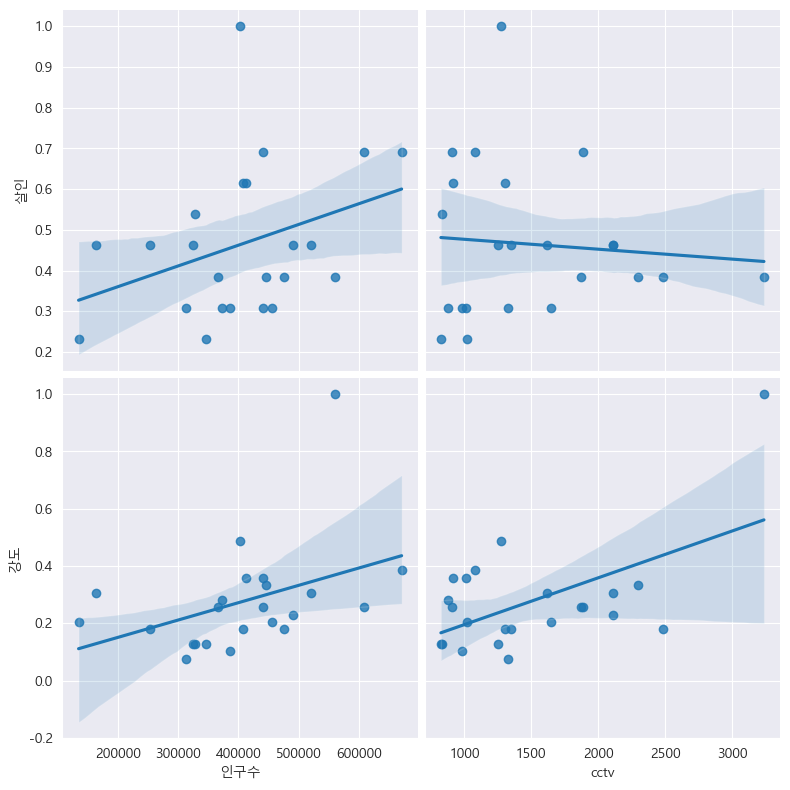
이번에는 '살인검거율' 고 '폭력검거율' 과의 상관관계도 비교해 보자.
# '인구수', 'cctv' 와 '살인검거율' 고 '폭력검거율' 의 상관관계 확인
def drawGraph():
sns.pairplot(data=crime_anal_norm,
x_vars=['인구수','cctv'],
y_vars=['살인검거율','폭력검거율'],
kind='reg',
height=4
)
plt.show()
drawGraph()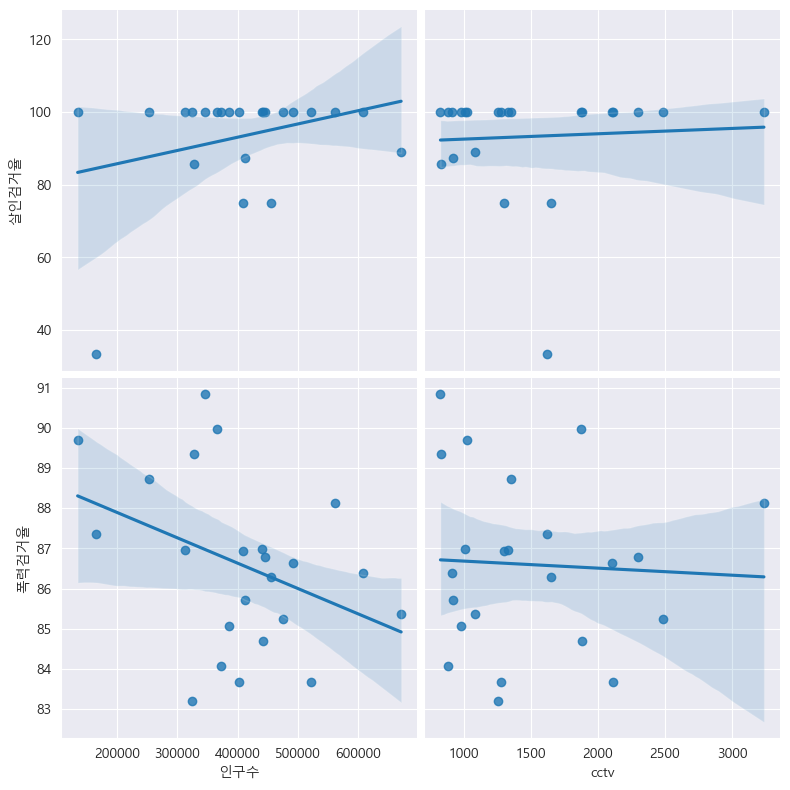
마지막으로 '절도검거율' 과 '강도검거율' 도 비교해 보자.
# 절도검거율 과 강도검거율
def drawGraph():
sns.pairplot(data=crime_anal_norm,
x_vars=['인구수','cctv'],
y_vars=['절도검거율','강도검거율'],
kind='reg',
height=4
)
plt.show()
drawGraph()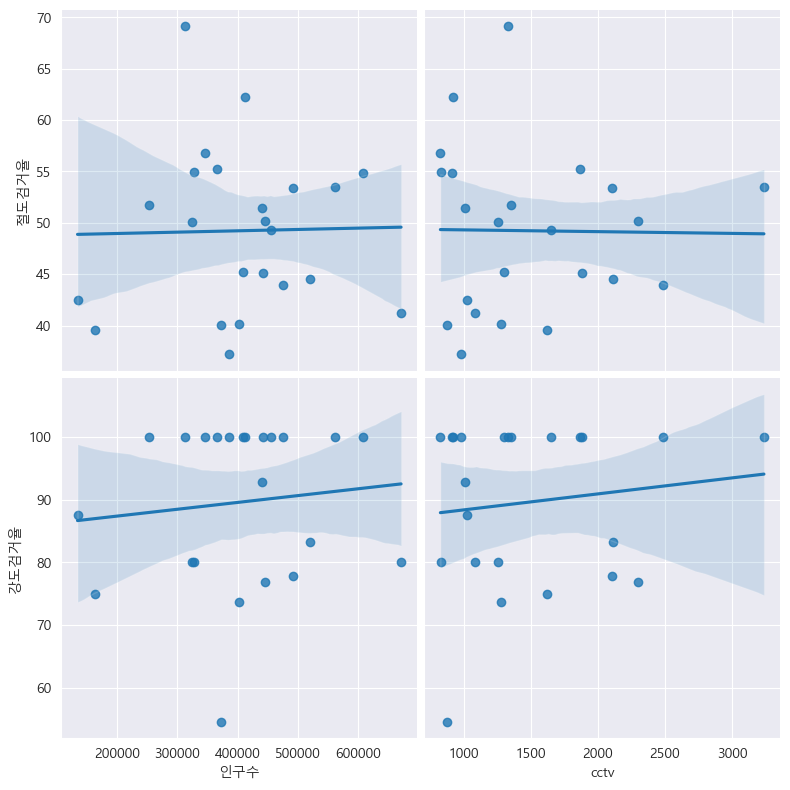
상관관계 그래프를 통해서 x 값과 y 값의 차이를 보고 컬럼별 상관관계가 가장 높은 것을 추려볼 수 있다.
(여기서 데이터 분석을 통한 의사결정이 가능하구나 느낌.)
언뜻 보기에도 cctv와 강도의 상관관계가 가장 있다고 보이는데, 강도발생수가 많을 수록 cctv 수가 많다고도 볼 수 있다.
2. heatmap
그렇다면 검거율 을 가지고 heatmap 을 그려보자.
#검거율 heatmap
# '검거' 라는 컬럼을 기준으로 정렬
def drawGraph():
# 데이터 프레임 생성
target_col = ['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율','검거']
crime_anal_norm_sort = crime_anal_norm.sort_values(by='검거', ascending=False)
# 그래프 설정
plt.figure(figsize=(10,10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True, #데이터값 표현
fmt='f',#f는실수형
linewidths=0.5, #간격설정
cmap='RdPu',
)
plt.title('범죄 검거 비율(정규화된 검거의 합으로 정렬)')
plt.show()
drawGraph()
heatmap 의 장점은 색상의 변화를 통해 좀 더 상관관계의 순위(?)를 한눈에 볼 수 있다는 것 이다.
이번에는 범죄발생건수 를 기준으로 한 heatmap 을 그려보자.
# 범죄발생건수 heatmap
# '범죄' 컬럼을 기준으로 정렬
def drawGraph():
# 데이터 프레임 생성
target_col = ['살인','강도','강간','절도','폭력','범죄']
crime_anal_norm_sort = crime_anal_norm.sort_values(by='범죄', ascending=False) #내림차순
# 그래프 설정
plt.figure(figsize=(10,10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True, #데이터값 표현
fmt='f', #실수형
linewidths=0.5, #박스간 간격설정
cmap='RdPu'
)
plt.title('범죄 비율(정규화된 발생 건수로 정렬)')
plt.show()
drawGraph()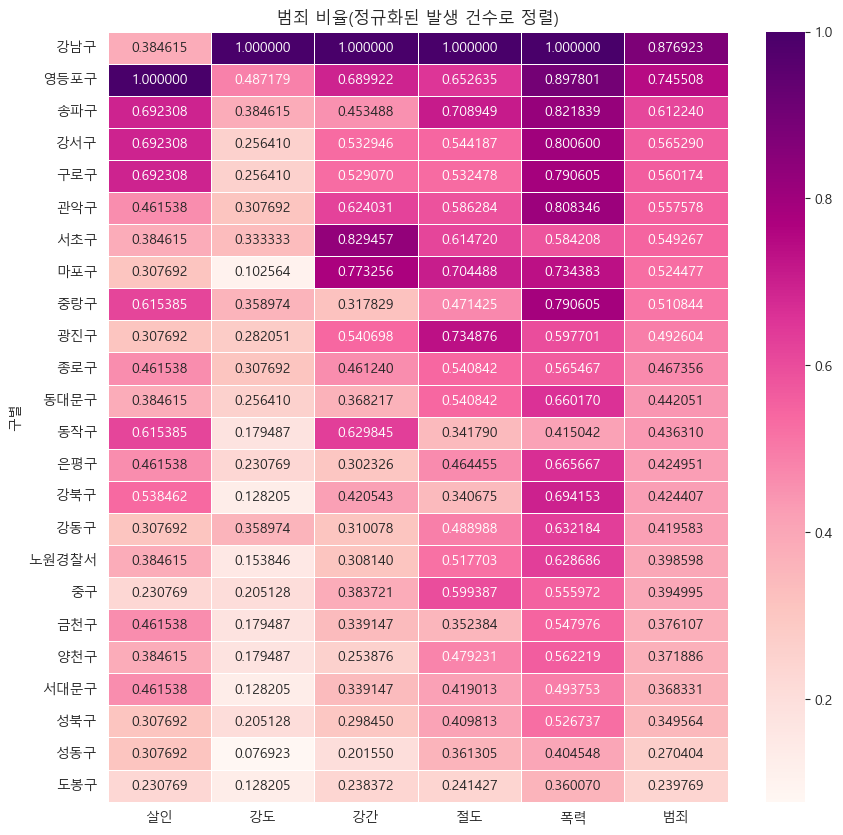
이렇게 실습이 끝났다.
색이 어두워질수록 상관관계가 높은 것 이다.
영등포구 살인율이 어마어마 하네.......
3. 데이터 저장
마지막이 가장 늘 늘 늘 중요하다.
저장을 하지 않으면 나중에 매우 힘든 일이 닥쳐올 수 있으니,
늘 마지막까지 저장하는 것을 잊지말자!!
# 데이터 저장
crime_anal_norm.to_csv('../data/02 crime_in_Seoul_final.csv', sep=',' , encoding='utf-8')
Analytics Engineer