folium 지도 시각화의 마지막 시간이다.
재밌었지만 이제 떠나보내 줄 차례다...................ㅎ
- folium.Choropleth 메서드 사용
import json
state_data = pd.read_csv('../data/02. US_Unemployment_Oct2012.csv')
state_data.tail(2)json 모듈을 불러온 후, 제로베이스에서 제공해준 데이터를 불러온다.

뭔지는 모르겠지만 50개의 이러한 데이터들이 들어있다.
먼저 미국데이터이니 미국의 위도 경도 값을 넣어주어 지도를 생성해 보겠다.
m = folium.Map([43,-102], zoom_start=3)
m
밑바탕이 되는 지도를 그렸으니, 이제 경계선과 색상을 채워보자.
m = folium.Map([43,-102], zoom_start=3) #밑바탕 지도
folium.Choropleth(
geo_data="../data/02. us-states.json", # 경계선 좌표값이 담긴 데이터
data =state_data, #판다스 데이터프레임이나 시리즈 형태로 들어와야 함. (실업율 데이터)
columns=["State","Unemployment"],
key_on="feature.id" , #string 타입
fill_color='BuPu',
fill_opcity=1, # 0~1 / 투명도
line_opacity=1, # 0~1
legend_name='Unemployment rate(%)'
).add_to(m)
m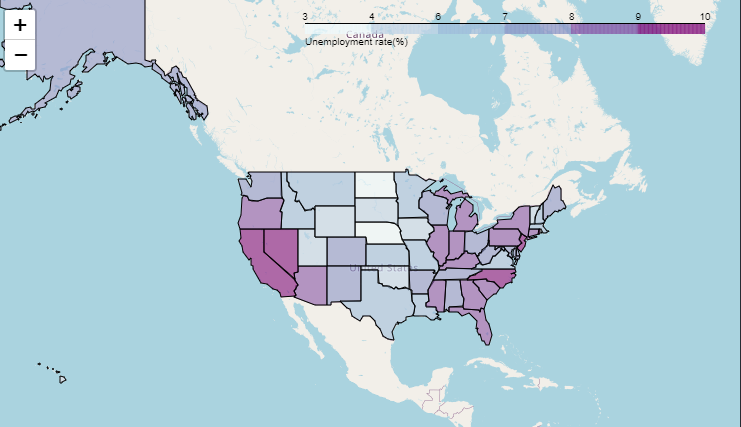
놀랍게도 실업율이 높은 순에 따라서 색상이 짙게 나타난다.
또 다른 데이터로도 마지막 예제를 다뤄보겠다.
아파트 유형 지도 시각화
- 공공데이터 포털
- https://www.data.go.kr/
import pandas as pd
df = pd.read_csv('../data/02. 서울특별시 동작구_주택유형별 위치 정보 및 세대수 현황_20210825.csv', encoding='cp949') #euc-kr 도 가능
df
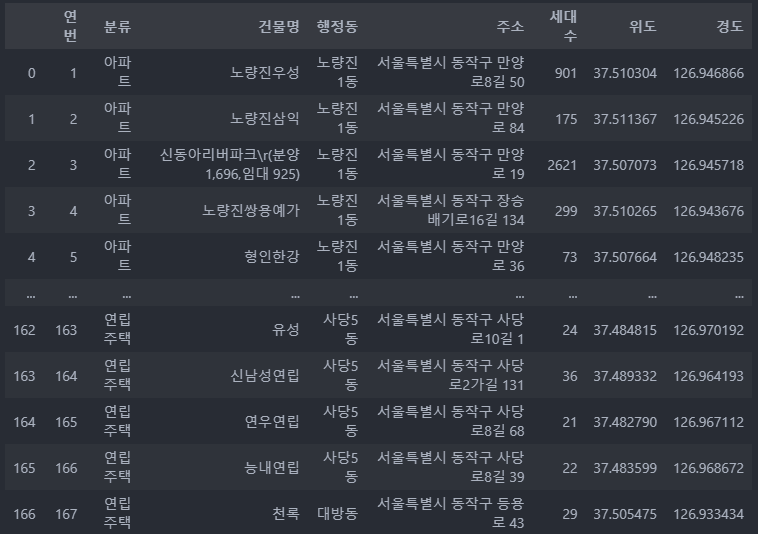
정보를 잘 불러왔고, info 함수로 좀 더 자세히 데이터를 봐야겠다.
df.info()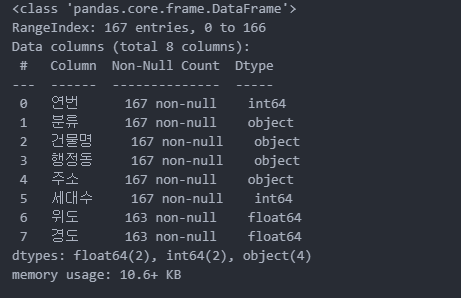
데이터를 보니 가장 중요한 위도, 경도의 값이 데이터수가 부족한 것을 볼 수 있다.
6 위도 163 non-null float64
7 경도 163 non-null float64
데이터를 따로 채우지는 않고 nan 데이터를 빼고 진행해 보겠다.
# NaN 데이터 제거
df = df.dropna()
df.info()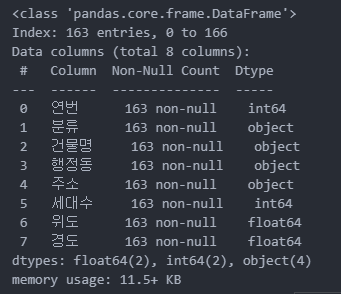
- reset_index() 의 사용법
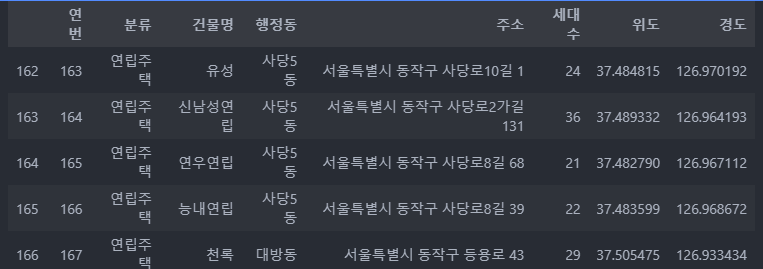
df.reset_index(drop=False) #defualt 는 false ( 인덱스가 들어오지 않겠다가 true)
df.tail()FALSE 로 할 경우 :
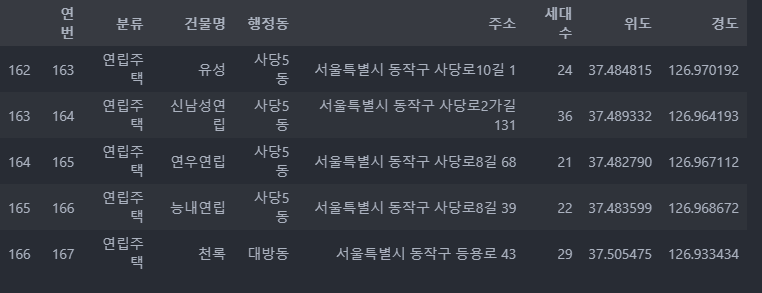
df.reset_index(drop=True) #defualt 는 false ( 인덱스가 들어오지 않겠다가 true)
df.tail()
TRUE 로 할 경우 :
근데 보면 알겠지만, false 로 해도 index 열의 값은 보이지가 않는다.. 그래서 이 부분이 좀 의문이긴 한데 pandas 가 업데이트 된 것 같다.
우선 index 번호와 연번의 값이 일치하지 않기 떄문에 연번 컬럼을 삭제해보겠다.
del df['연번']
을하고 실행을 하니 오류가 떴다. 그래서 이럴 떄는 columns 를 확인해 보면 좋다.
df.columns
확인해 보니 연번과 분류 옆에 한 칸 띄어쓰기가 보인다..!!
rename 함수로 일단 올바른 이름으로 변경 해주자.
df = df.rename(columns={'연번 ': '연번' , '분류 ': '분류'})
df.연번[:10]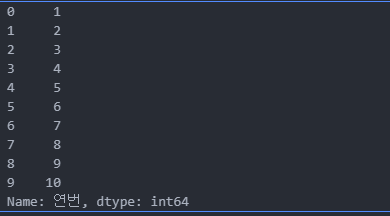
이제 제대로 출력이 되는 것을 확인했다.
다시 연번을 삭제해 보자.
del df['연번']
df.tail(2)
이제 folium 을 통해서 세대수 별로 marker 의 색상을 나누어 표시되게 하겠다.
# folium
m = folium.Map(
location=['43.236631618576425', '131.87277429792962'],
zoom_start=13#숭실대입구
)
for idx, row in df.iterrows():
# location
lat , lng = row.위도 , row.경도
# marker
folium.Marker(
location=[lat,lng],
popup=row.주소,
tooltip=row.분류,
icon=folium.Icon(
icon='home',
color= "lightred" if row.세대수 >= 199 else "lightblue",
icon_color='darkred' if row.세대수 >= 199 else "darkblue"
)
).add_to(m)
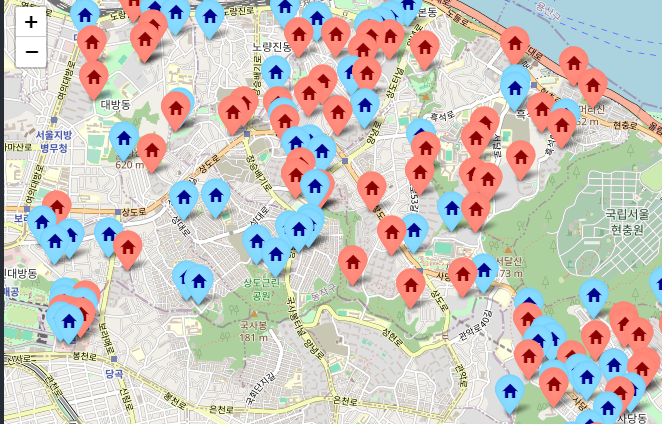
세대수가 199보다 크면 red로 적으면 블루로 표현했다.
여기에 Circle 도 그려보면 어떻게 될까?
#Circle
folium.Circle(
location=[lat,lng],
radius=row.세대수 = 0.2,
fill= True,
color='pink' if row.세대수 >= 518 else 'green',
fill_color='pink' if row.세대수 >= 518 else 'green',
).add_to(m)
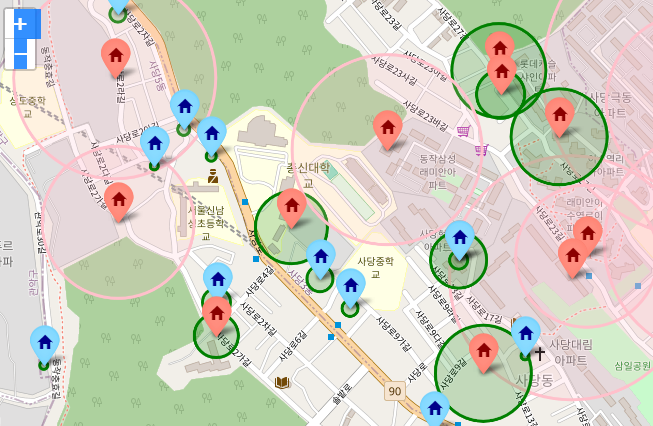
세대수가 많으면 핑크색 원으로 그려주고 적으면 초록색 원으로 그려준다!!
CircleMarker() 로 그려보니 너무 원이 커서...주체가 안 된다..
Circle() 사용이 되도록 쓸 일이 많아 보인다.
