
- 팀원 : 5명
- 주요역할 : PM, 기술리딩, 클러스터링, 데이터정제, 웹페이지 구현
- 사용기술 : 데이터정제(Python), 클러스터링(Kmeans), 웹페이지구현(HTML & JavaScript)
- 프로젝트 기간 : 2018.08.01 ~ 2018.08.31
본 프로젝트는 2018년 데잇걸즈 2기 중간 프로젝트에서 진행되었습니다.
일부 코딩, 페이지 구현에서는 당시 담당 멘토였던 강규영님과 박조은님의 도움을 받았습니다.
색에 대한 개념과 멘토링은 인포그래픽 디자이너 JinKim님의 조언을 받았습니다.
0. 목적
아무리 화려한 색도 컴퓨터에게는 숫자에 불과하다.
대학 수업에서 새삼스레 와 닿은 교수님의 말씀에서 시작한 프로젝트입니다. 색데이터를 분류하는 기반을 만들자는 생각에서 출발했으며, 서울시내 325개 카페 매장 내부 이미지를 수집해 서로 다른 두 개의 방식으로 색감을 분류해보았습니다.
본 내용은 2018데이터야놀자에서 해당 프로젝트를 발표한바있으며, 발표자료는 슬라이드쉐어에서 확인하실 수 있고, 많이 미흡하지만, 구현된 내용은 프로젝트 페이지에서 확인하실 수 있습니다.
또한, 당시 Repository는 첫 깃헙 사용으로 버전관리가 제대로 이루어지지 않아 부끄럽지만, 아카이빙용으로 이곳에 링크를 첨부합니다.
진행과정
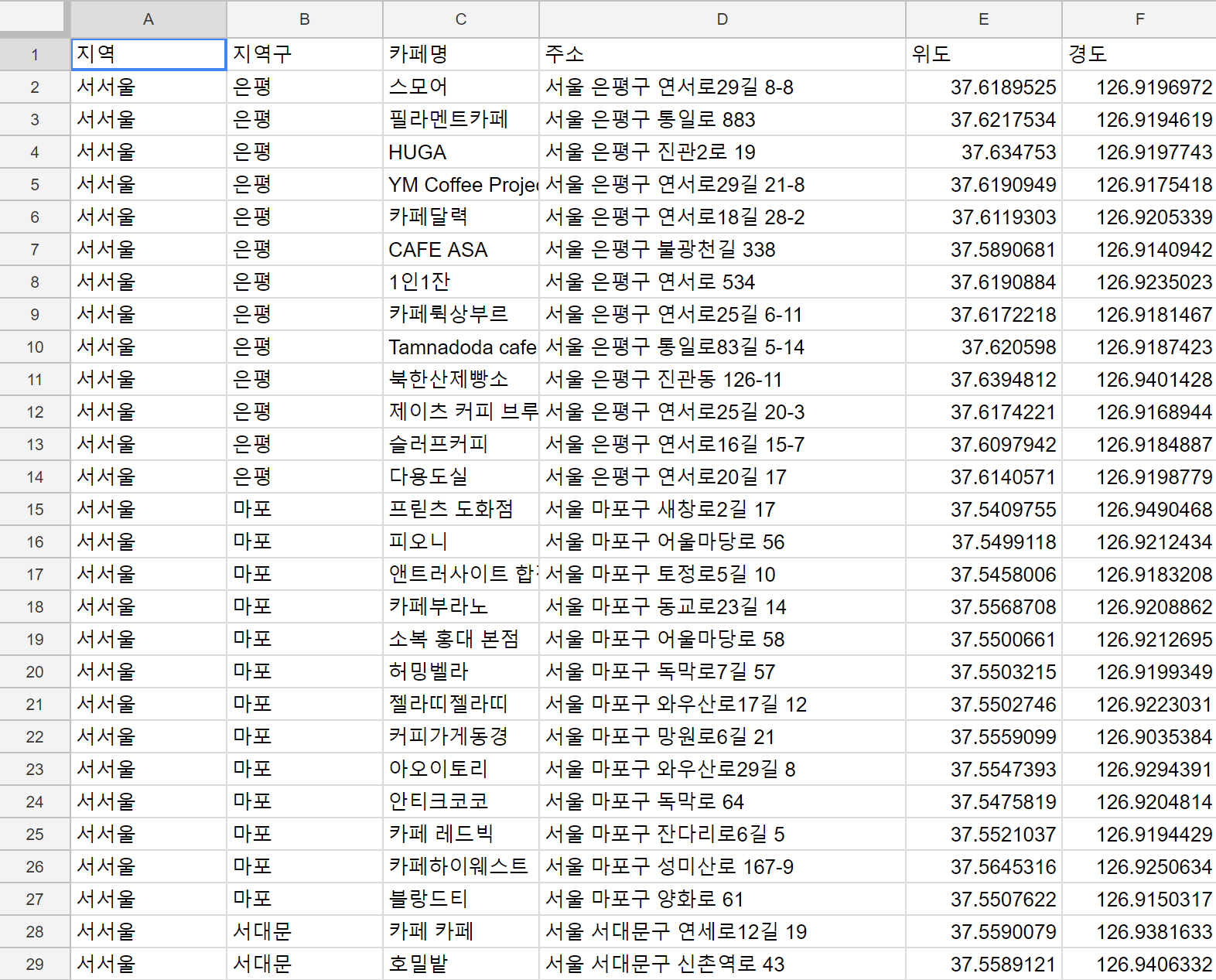
- 각자 서울시내 지역별로 유명 카페 상위 30개를 검색
- 검색한 카페 내에서 '매장 내부'를 촬영한 이미지와 주소, 이름 등을 스프레드 시트에 저장
- 이미지를 불러와서 색을 추출하는 코드(Image Cluster)에 넣음
- 구글 API를 활용해 주소의 위도와 경도를 지도에 찍기
- 지역별 특성과 색감이론을 찾아 지도의 내용과 연결지어 Insight를 도출 (미완)
1. 이미지 수집
검색엔진 네이버에서 "00구 맛집"의 검색 결과 중, "카페" 카테고리에 속하는 블로그 리뷰 중 상위 13개의 카페 정보를 담았습니다. 카페명, 주소, 대표 이미지를 담아 데이터로 남겨두었습니다. 파일명은 각 지역구의 이니셜을 활용해 영문과 인덱스번호로 남겨두었습니다.
[ 이미지 수집에서의 파일명 convention ]

매장 외부와 음식사진을 제외한 내부 인테리어가 잘 나온 이미지만을 가져오기 위해서 크롤러 대신 수작업을 선택했습니다. 팀원 각자의 구역을 대분류(도심, 서서울, 남서울 등)와 소분류(은평구, 마포구, 동작구 등)로 나누어 하루 10개씩 작업하였습니다. 모든 이미지 파일은 '대분류소분류인덱스.png' 로 통일하여 dataframe에 담았습니다.
이미지 수집을 끝내야하는 시점에는 가장 많은 수의 이미지를 가져온 사람을 기준으로 수를 통일했습니다.(지역별 13개씩) 스프레드시트에서 제공하는 기능을 이용해 위도와 경도를 구했습니다. 이를 한데 모아 csv로 파일로 저장했습니다.
[ CSV 파일의 일부 ]
[ 이미지 폴더의 일부 ]

2. 색감분류
색감 분류에서는 크게 두 가지 방법을 사용했습니다.
2-1. 클러스터링
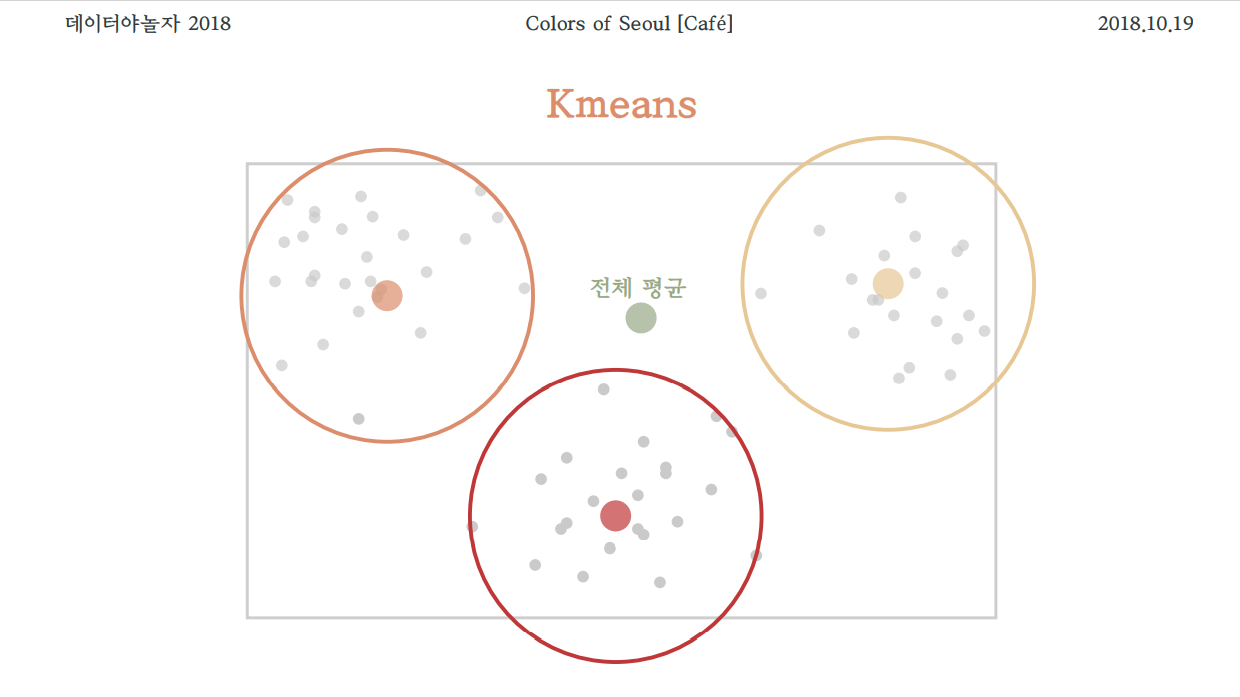
"Kmeans" 알고리즘을 사용해 각 카페 이미지에서 대표색 5개를 추출해 그래프 형식으로 저장했습니다. 인터넷에 공개된 OpenCV모듈의 함수를 사용했으며, 한눈에 카페의 색감을 확인할 수 있다는 점에서 가장 직관적이었지만, 색데이터로 다루기에는 적합하지 않다고 판단했습니다.

원리는 다음과 같습니다.
1. 이미지를 RGB순으로 읽어오기
2. 군집수를 지정하여 Kmeans라는 평균 알고리즘으로 비슷한 색끼리 모은 군집을 지정된 수만큼 만들어냄
3. 픽셀의 숫자를 기반으로 히스토그램 형식으로 색을 반환
4. 각 색의 빈도를 나타내는 바를 반환
출처
Image Clustering by python
Example of the Image Clustering code
클러스터링에서 사용된 라이브러리, 모듈은 다음과 같습니다.
import cv2
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import scipy.misc다음 함수image_color_cluster(image_path, k=n)는 이미지를 RGB순으로 읽어와 Kmeans 알고리즘에 넣어 가장 빈번하게 나온 군집을 지정된 수만큼 만들어냅니다.
def image_color_cluster(image_path, k = 5):
image = cv2.imread(image_path)
# image의 shape을 찍어보면, height, width, channel 순으로 나옴
# channel은 RGB를 말함
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# cv에서는 RGB가 아닌 BGR 순으로 나오기 때문에 순서를 RGB로 전환
image = image.reshape((image.shape[0] * image.shape[1], 3))
# shape의 0,1번째 즉, height와 width를 통합시킴
clt = KMeans(n_clusters = k) # 평균 알고리즘 KMeans
clt.fit(image)
hist = centroid_histogram(clt)
bar = plot_colors(hist, clt.cluster_centers_)
return bar다음 함수centroid_histogram(clt)는 대표 군집을 히스토그램 형식으로 반환하는 함수입니다.
def centroid_histogram(clt):
'''
# grab the number of different clusters and create a histogram
히스토그램 형식으로 색을 반환
based on the number of pixels assigned to each cluster
각 클러스터의 픽셀의 숫자를 기반으로 함
'''
numLabels = np.arange(0, len(np.unique(clt.labels_)) + 1)
(hist, _) = np.histogram(clt.labels_, bins=numLabels)
# normalize the histogram, such that it sums to one
hist = hist.astype("float")
hist /= hist.sum() # hist = hist/hist.sum()
# return the histogram
return hist[ centroid_histogram의 결과 사진 ]

2-2. Tone으로 분류하기
웜톤, 쿨톤, 모노톤(무채색)의 비중을 확인했습니다. 각 픽셀의 RGB 순서쌍을 톤으로 구분하고, 각 톤의 비율을 확인했습니다. 카페별, 지역구별로 어떤 색을 많이 사용하는지를 색데이터로서 숫자로 확인할 수 있어 가장 객관적인 방법이었습니다.
하지만, 빨강, 파랑, 무채색의 비중을 확인할 뿐 갈색, 분홍색, 황토색 등 보다 구체적인 색들을 확인할 수는 없었고, 대부분 웜톤과 무채색을 많이 사용하는 등 낮은 표준편차를 보였습니다.
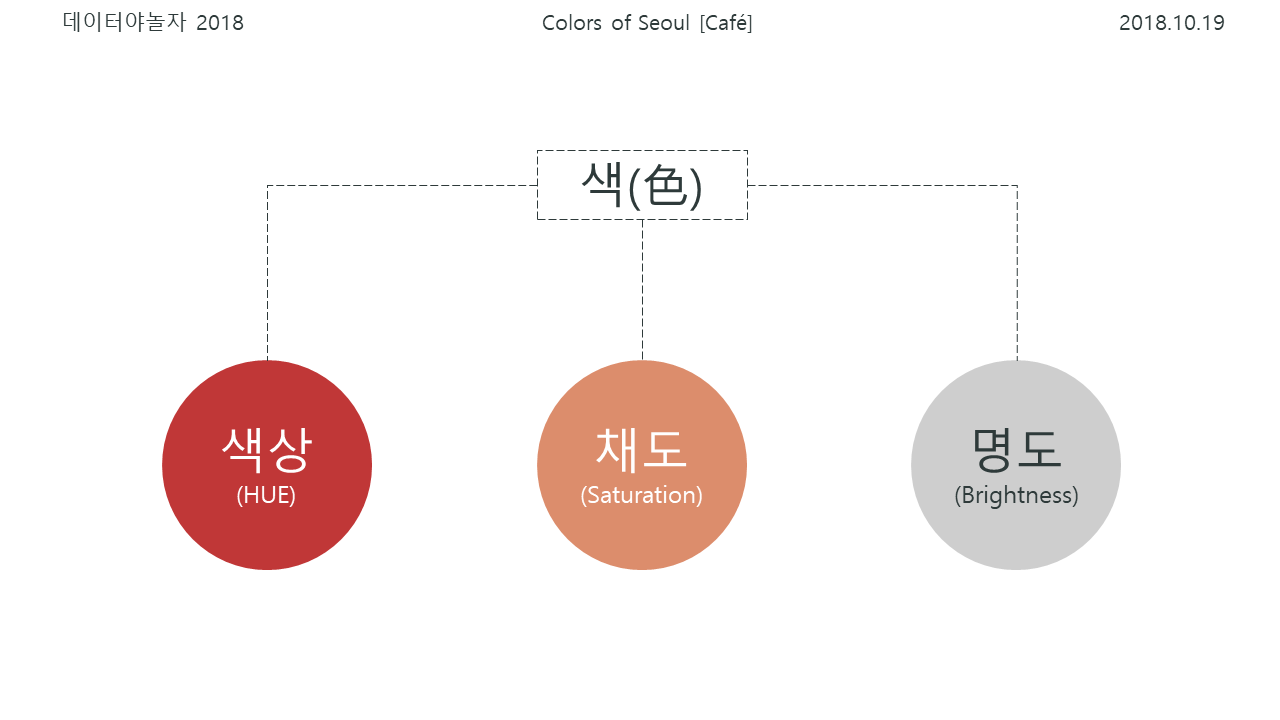
색을 구성하는 요소에는 색상 채도 명도가 있습니다. 그 중에서 웜톤, 쿨톤 등 우리가 흔히 말하는 Tone은 "색의 선명도, 순수한 컬러의 정도" 를 말합니다. 색상보다는 채도와 명도의 정도에 의해 tone의 많은 부분이 결정됩니다.
채도 : 맑거나 흐린 색조
명도 : 밝거나 어두운 색조
본 프로젝트에서 선정한 톤은 다음 3가지 입니다.
Warm Tone : 빨간계열의 색이 많이 섞인, 따뜻한 느낌을 주는 색
Cool Tone : 푸른 계열의 색이 많이 섞인 차가움의 느낌을 주는 색
Mono Tone : 검은색, 흰색, 회색으로 분류되는 색으로 명도의 영향을 많이 받은 색(RGB가 모두 비슷하거나 같은 비율로 섞일 때 Mono Tone이 됨)
Tone을 분류하는 과정을 pseudocode로 작성하면 다음과 같습니다.
if RGB가 비슷한 비율로 섞여 있다.
return Mono Tone
elif R(빨강)의 비중이 더 크다.
return Warm Tone
else
return Cool Tone이 때, "비슷하게"의 기준은 RGB의 비율의 차이가 모두 5% 이내인 경우를 말합니다.
이와 같은 과정을 통해 알게된 결과는 다음과 같습니다.
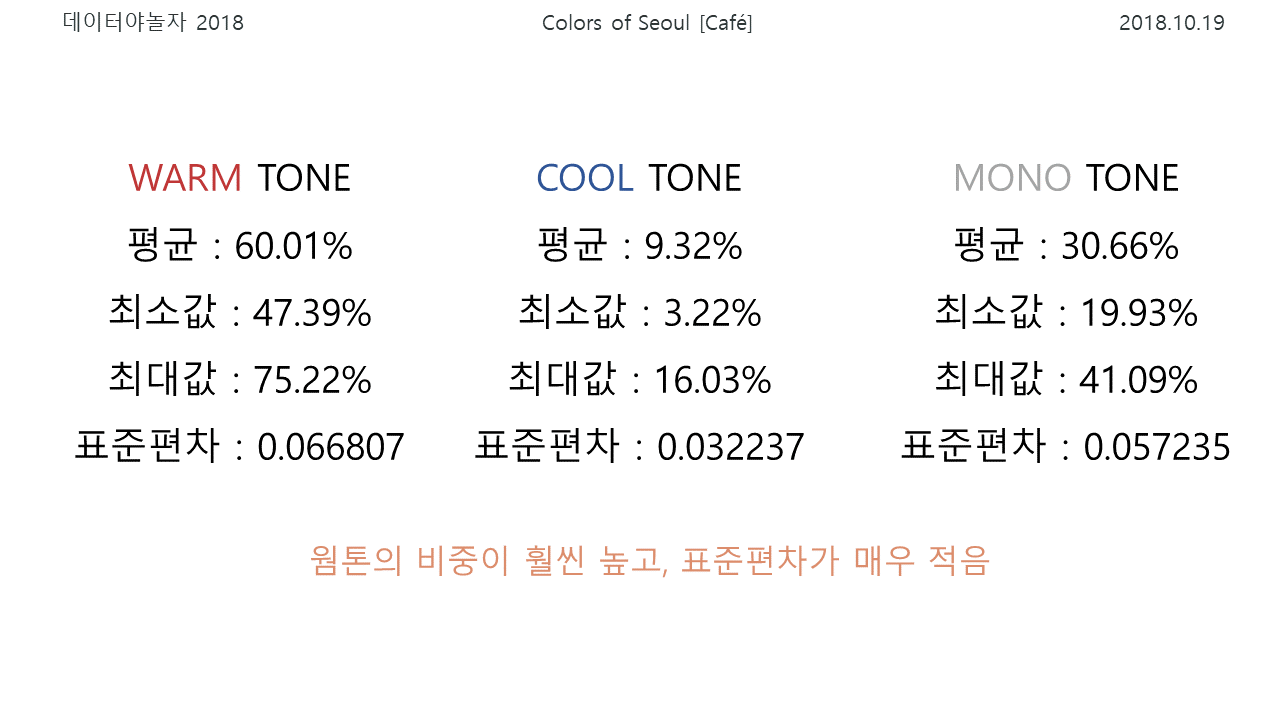

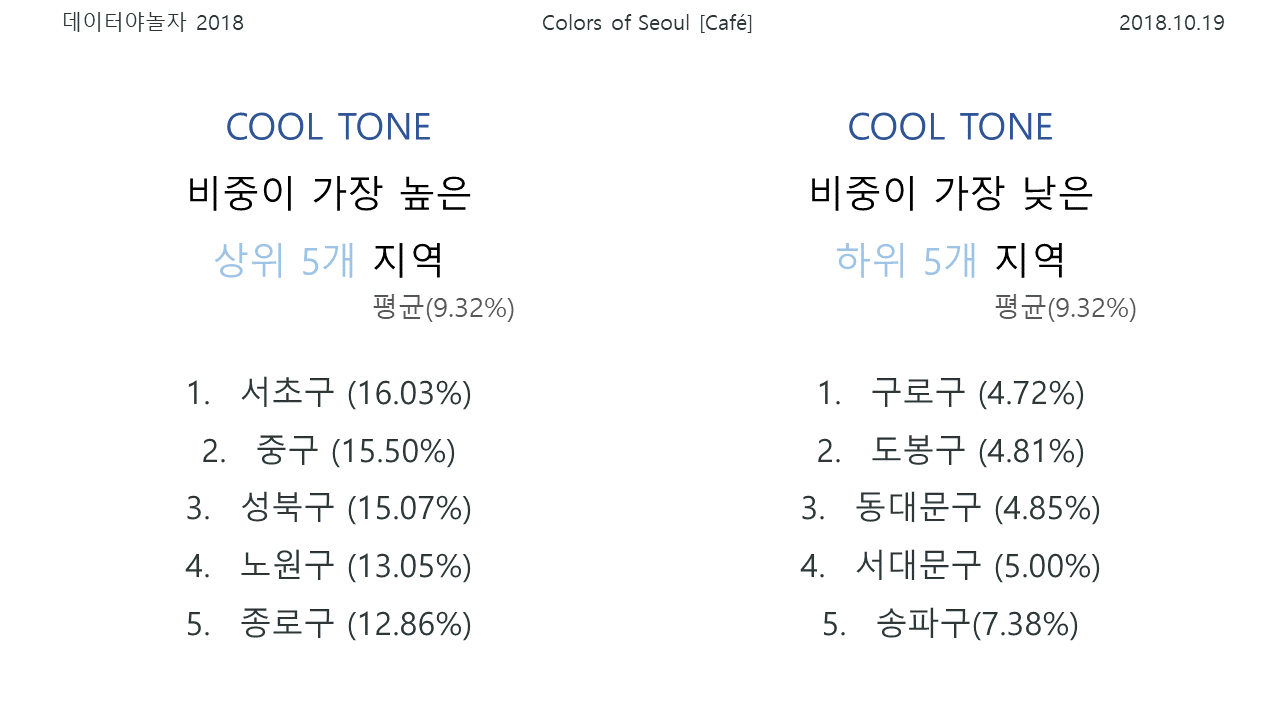
실제로, WARM TONE의 비중이 월등이 높은 동대문구(75.22%, 평균 60.01%) 소재의 인기카페들의 대표 색감은 아래 사진과 같습니다.

COOL TONE의 비중이 가장 높은 서초구(16.03%, 평균 9.32%)의 카페는 아래와 같은 색감을 가지고 있습니다. 카페 인테리어 특징 상 나무 의자와 책상이 많고, 사진을 찍는 사람에 따라 따뜻한 색감의 조명이나 보정 등이 포함되는 경우가 많아 비교적 갈색의 비중이 높고, 전체적으로 WARM TONE의 비중이 현저히 높을 수 밖에 없습니다.
카페 인테리어 특징 상 나무 의자와 책상이 많고, 사진을 찍는 사람에 따라 따뜻한 색감의 조명이나 보정 등이 포함되는 경우가 많아 비교적 갈색의 비중이 높고, 전체적으로 WARM TONE의 비중이 현저히 높을 수 밖에 없습니다.
하지만 이상의 사진에서처럼 동대문구에 비해 서초구의 경우가 같은 갈색 중에서도 파랑이 많이 섞인, 조금 더 차가운 느낌을 준다는 것을 알 수 있습니다.
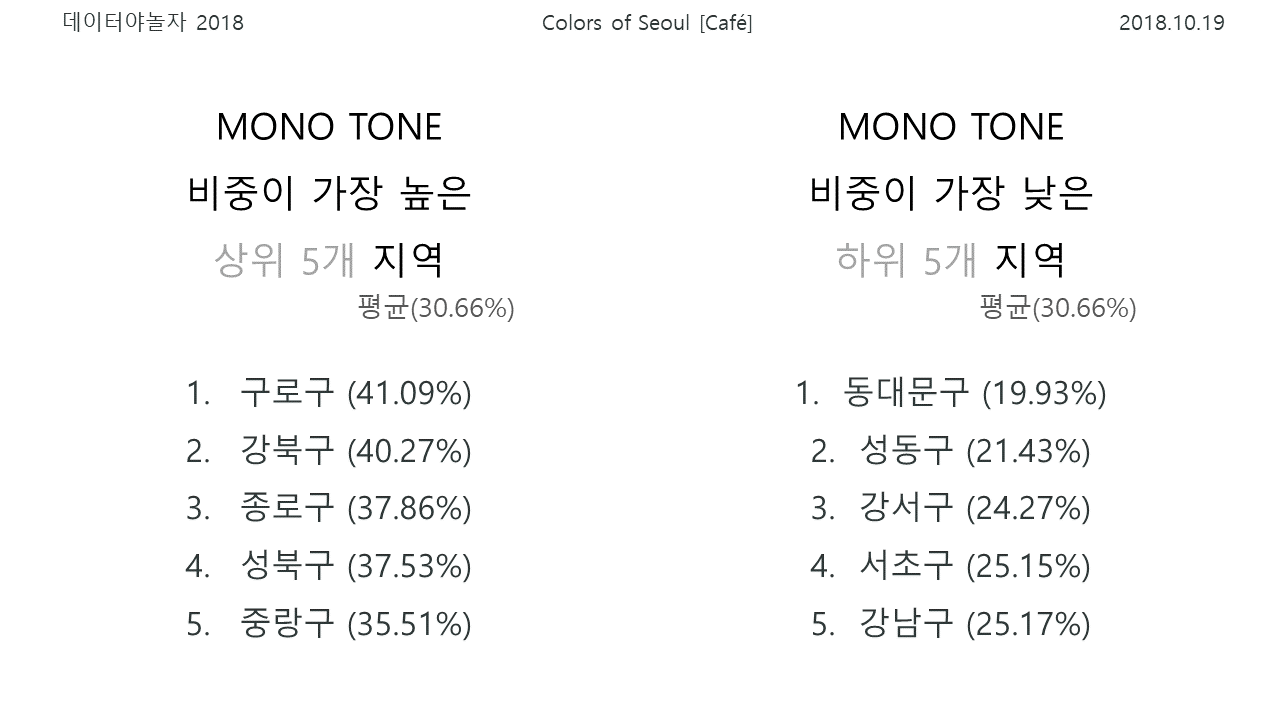
마지막으로 MONO TONE의 비중이 가장 높은 구로구(41.09%, 평균 30.66%) 카페의 색감은 아래 사진과 같습니다. MONO TONE의 대표색인 검은색과 흰색, 회색의 비중이 높은 카페가 여럿 보입니다. 디지털단지를 중심으로 비교적 회사가 밀집한 지역이라는 특징이 이런 결과를 가져왔을 수도 있겠다는 추측을 할 수 있었습니다.
MONO TONE의 대표색인 검은색과 흰색, 회색의 비중이 높은 카페가 여럿 보입니다. 디지털단지를 중심으로 비교적 회사가 밀집한 지역이라는 특징이 이런 결과를 가져왔을 수도 있겠다는 추측을 할 수 있었습니다.
지역별로 더 많은 분석은 아직 시도해보지 못했으나, 지역별 대표 색감을 참고하시려면 슬라이드쉐어 혹은 프로젝트 페이지(아직 보수 작업 전)를 확인해주시길 바랍니다. :-)
3. Data로 남기기
색데이터를 분류하는 기반을 만드는 것이 가장 큰 목표였기 때문에, 추후 다른 개발자 혹은 분석가분들께서 본 데이터를 활용해 더욱 다양한 것을 해볼 수 있도록 데이터로 남겨두었습니다.
파일 저장에 사용된 지역구별 이니셜과 각 인덱스의 항목들이 어떤 카페인지 등을 담은 csv 파일은 물론, 클러스터링 결과와 Tone 구분 결과 또한 파일로 정리해 남겨두었습니다.
3-1. 색데이터 남기기
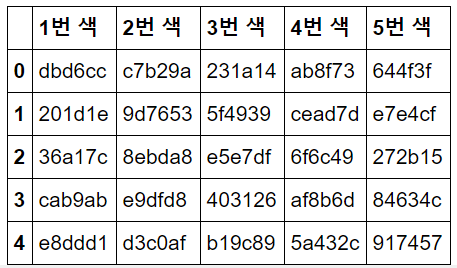
특히 클러스터링 결과의 경우, 5개의 대표색 중에서 가장 많이 나온 1번 대표색을 찾고, 각 색의 16진수값으로 저장해 숫자로써도 다루기 쉽도록하였습니다.
아래 코드는 5개의 색 중 가장 많이 나온 1번 대표색을 찾아 16진수로 바꾸어 반환하는 함수입니다.
def read_real_color(filename):
image = cv2.imread(filename, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_list = [str(list(image[i][k])) for i in range(len(image)) for k in range(len(image[0]))]
image_unique = {}
for d in image_list:
if d not in image_unique:
image_unique[d] = 1
else:
image_unique[d] += 1
import operator
icon_color_list = max(image_unique.items(), key=operator.itemgetter(1))[0]
color_R = int(icon_color_list.split('[')[1].split(']')[0].split(', ')[0])
color_G = int(icon_color_list.split('[')[1].split(']')[0].split(', ')[1])
color_B = int(icon_color_list.split('[')[1].split(']')[0].split(', ')[2])
color_R = dec_to_hex(color_R)
color_G = dec_to_hex(color_G)
color_B = dec_to_hex(color_B)
return str(color_R + color_G + color_B)
def dec_to_hex(color):
if color < 16:
return '0' + str(hex(int(color)).split('x')[1])
else:
return str(hex(int(color)).split('x')[1])
color_list = []
for n in df_cafe.index:
png = './cafe_color_result/' + df_cafe['파일명'][n]
color_list.append(read_real_color(png))
df_cafe['대표색'] = color_list아래는 1번 대표색 이외의 색도 16진수로 바꾸는 함수입니다.
def read_real_color(filename, color_rank):
image = cv2.imread(filename, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_list = [str(list(image[i][k])) for i in range(len(image)) for k in range(len(image[0]))]
image_unique = {}
for d in image_list:
if d not in image_unique:
image_unique[d] = 1
else:
image_unique[d] += 1
total_color_lists = sorted(image_unique.keys(), key=lambda x:image_unique[x], reverse=True)
color_list = total_color_lists[color_rank]
# max가 아닌 빈도수 기준으로 정렬된 데이터를 불러와 각각을 변환
color_R = int(color_list.split('[')[1].split(']')[0].split(', ')[0])
color_G = int(color_list.split('[')[1].split(']')[0].split(', ')[1])
color_B = int(color_list.split('[')[1].split(']')[0].split(', ')[2])
color_R = dec_to_hex(color_R)
color_G = dec_to_hex(color_G)
color_B = dec_to_hex(color_B)
return str(color_R + color_G + color_B)
def dec_to_hex(color):
if color < 16:
return '0' + str(hex(int(color)).split('x')[1])
else:
return str(hex(int(color)).split('x')[1])
for i in range(5):
color_list = []
for n in df_cafe.index:
png = './cafe_color_result/' + df_cafe['파일명'][n]
color_list.append(read_real_color(png, i))
col_name = str(i+1) + '번 색'
df_cafe[col_name] = color_list
df_cafe[['1번 색', '2번 색', '3번 색', '4번 색', '5번 색']].head()[ 결과 화면 일부 ]
3-2. 파일명에 대한 데이터 남기기
임으로 바꾼 영어 지역명이 각각 무엇인지를 보여주기 위한 DataFrame도 만들었습니다. 한글순, 영어순으로 정렬한 것을 각각 만들었습니다. 추후 html 홈페이지를 만들때 일일이 작성하기 보다는 이 data를 활용해 반복문을 만들어 손쉽게 작업할 수 있었습니다.
df_sorted_area_by_kor = pd.DataFrame()
area_dict = {\
'은평구': 'ws_ep', '마포구': 'ws_mp', '서대문구': 'ws_sdm', '강서구': 'sw_gs',\
'양천구': 'sw_yc', '영등포구': 'sw_ydp', '구로구': 'sw_gr', '종로구': 'cs_jr',\
'중구': 'cs_jg', '용산구': 'cs_ys', '동작구': 'ss_dj', '관악구': 'ss_ga',\
'금천구': 'ss_gc', '서초구': 'gn_sc', '강남구': 'gn_gn', '도봉구': 'gb_db',\
'강북구': 'gb_gb', '성북구': 'gb_sb', '노원구': 'gb_nw', '동대문구': 'es_ddm',\
'중랑구': 'es_gl', '성동구': 'es_sd', '광진구': 'es_gj', '강동구': 'se_gd', '송파구': 'se_sp'}
# 한글 정렬
sorted_area_by_kor = sorted(area_dict.items(), key=lambda x:x[0])
area_in_korean = [area[0] for area in sorted_area_by_kor]
df_sorted_area_by_kor['지역명(한글)'] = area_in_korean
area_in_english = [area[1] for area in sorted_area_by_kor]
df_sorted_area_by_kor['지역명(영문)'] = area_in_english
df_sorted_area_by_kor.to_csv('data_sorted_area_by_kor.csv')
# 영문 정렬
df_sorted_area_by_eng = pd.DataFrame()
sorted_area_by_eng = sorted(area_dict.items(), key=lambda x:x[1])
area_in_korean = [area[0] for area in sorted_area_by_eng]
area_in_english = [area[1] for area in sorted_area_by_eng]
df_sorted_area_by_eng['지역명(영문)'] = area_in_english
df_sorted_area_by_eng['지역명(한글)'] = area_in_korean
df_sorted_area_by_eng.to_csv('data_sorted_area_by_eng.csv')4. Folium 지도에 찍어보기
스프레드시트의 기능을 사용해 구한 위경도를 통해 위치를 찾고, 그 핀에는 이상에서 찾은 1번 대표색을 넣었습니다.
import base64
import folium
map = folium.Map(location=[df_cafe['위도'].mean(), df_cafe['경도'].mean()], zoom_start=13)
for n in df_cafe.index:
png = './cafe_color_result/' + df_cafe['파일명'][n]
encoded = base64.b64encode(open(png, 'rb').read()).decode('utf-8')
cafe_name = df_cafe['카페명'][n] + ' - ' + df_cafe['주소'][n]
html = f'<p>{cafe_name}</p> <img src="data:image/png;base64,{encoded}">'
iframe = folium.IFrame(html, width=700, height=130)
popup = folium.Popup(iframe, max_width=300)
color = '#' + df_cafe['대표색'][n]
icon = folium.Icon(icon_color=color, color='white')
folium.Marker([df_cafe['위도'][n], df_cafe['경도'][n]], popup=popup, icon=icon).add_to(map)[ 결과 화면 ]
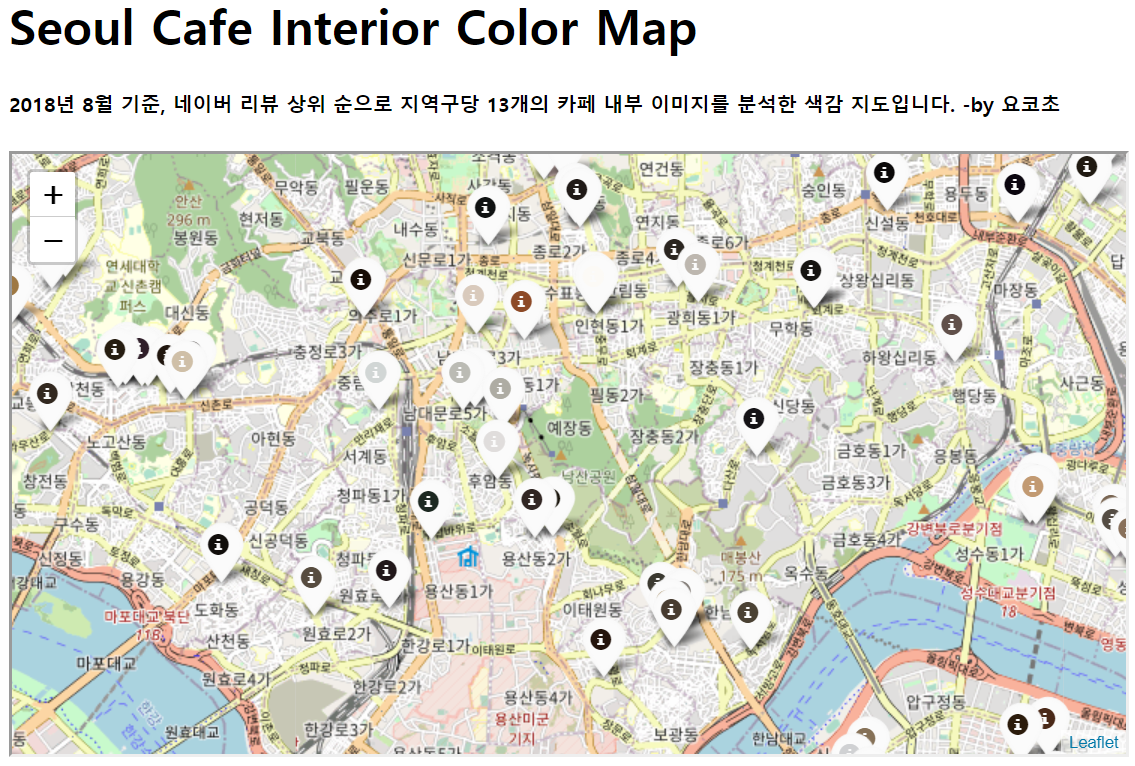 해당 내용은 프로젝트 페이지에서 확인 가능
해당 내용은 프로젝트 페이지에서 확인 가능
5. 느끼고 배운 점
색조 화장품을 구매할 때마다 하늘 아래 같은 색은 없다.. 라는 말을 자주 했었는데, 정말 컴퓨터 아래 같은 색은 없었습니다...

- Kmeans 클러스터링 결과에서 가장 빈도수가 높은 색을 지도에 찍어보았으나, 하나의 색으로는 우리가 인식하는 카페 분위기를 반영하지 못했습니다.
- 색은 직관과 감정이 중요한 영역이지만, 컴퓨터와 데이터는 매우 객관적인 수치가 중요하다는 점에서 분석에 어려움이 많았습니다.
- tone으로 이미지를 구분하면, 우리가 인지하는 분위기(따뜻함, 차가움)에 부합했습니다. 하지만, 무채색을 구분하는 기준이 모호해 고동색과 검정색과 같은 유사색은 우리가 인지하는 색과 다를 수 있다는 한계가 있었습니다.
- 데이터야놀자 2018에서 연사로 참가해 프로젝트를 발표했습니다. 이를 계기로 2021년 현재는 데이터야놀자 운영진으로 활동하고 있습니다.
- 색데이터를 보다 심도있게 연구하고 싶습니다. 색감을 분류하는 기반을 만들기위한 프로젝트인만큼 두 번째 주제로 아동 장난감의 색을 분류하는 프로젝트를 시작하는 계기가 되었습니다.
- 첫 웹프로그래밍으로, 구현에서 어려움이 많았습니다. 이를 계기로 UX디자인과 JavaScript에 관심을 가지게 되어 공부를 시작했습니다.
