Iris(붓꽃) 품종 분류
이번에 사용할 패키지
$ pip install scikit-learn
$ pip install matplotlib

petal은 꽃잎이고, sepal은 꽃받침이다.
위 사진에서 세 가지 붓꽃은 모두 꽃잎과 꽃받침의 크기가 조금씩 다르고, 색깔도 조금씩 다르다
이를 머신러닝 기법을 활용해 얼마나 잘 분류하는지 확인해보자.
붓꽃 데이터가 예제 데이터로 사용되는 이유는 머신러닝에서 가장 많이 사용되는 라이브러리 중 하나인 사이킷런(scikit-learn)에 내장된 데이터이기 때문이다.
사이킷런은 파이썬을 기반으로 한 머신러닝 생태계에서 오랜 기간 동안 사랑받고 있는 라이브러리이다. 최근 TensorFlow, PyTorch 등 딥러닝에 특화된 라이브러리들이 강세를 보이지만, 머신러닝의 다양한 알고리즘과 편리한 프레임워크를 제공한다는 점으로 인해 여전히 많은 데이터 분석가들이 사용하고 있다.
사이킷런은 예제로 활용해 볼 수 있는 데이터를 몇 가지 제공한다. Scikit-learn 데이터셋
사이킷런은 간단하고 작은 데이터셋인 Toy datasets와 비교적 복잡하고 현실세계를 반영한 Real world datasets, 두 가지 종류의 데이터셋을 제공한다.
이중 Iris plants dataset이 있는 Toy datasets을 사용한다.
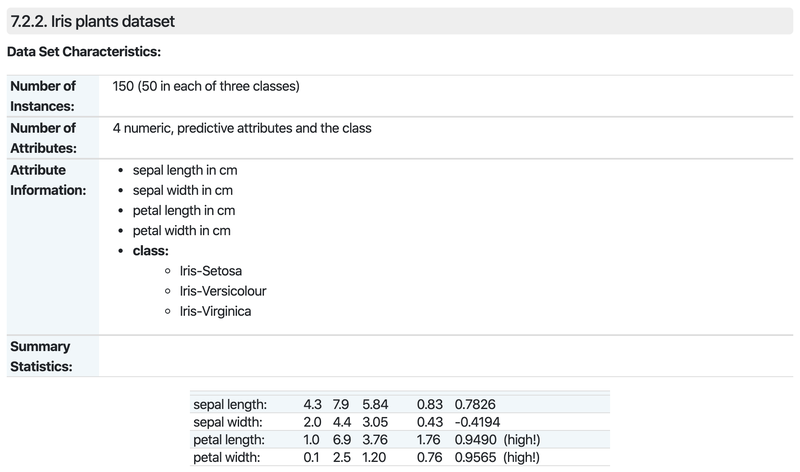
데이터셋에는 총 150개의 데이터가 담겨있다. 각 데이터에는 4개의 정보(sepal,petal의 길이(length)와 폭(width))가 담겨있다. 클래스는 Setosa, Versicolour, Virginica 세 가지가 있다.
데이터셋을 다루기 전에 데이터셋의 정보를 먼저 확인하는 것은 중요하다
데이터를 얼마나 이해하고 있느냐는 그 데이터를 활용한 결과와 성능에 중대한 요소가 되기 때문이다. 따라서 어떤 데이터셋을 다루든 그 데이터셋이 담고 있는 정보를 먼저 잘 확인하고 시작해야한다.
데이터 준비
데이터 셋을 가져온다
사이킷런의 예제 데이터셋은 sklearn라이브러리의 datasets패키지 안에 담겨있다.
load_iris를 import 해서 iris 데이터를 로딩해보자
from sklearn.datasets import load_iris
iris = load_iris()
print(dir(iris)) # dir()는 객체가 어떤 변수와 메서드를 가지고 있는지 나열한다.iris에 어떤 정보들이 담겼는지, keys()라는 메서드로 확인해보자
iris.keys() 결과값을 보면 iris에는 data, target, frame, target_names, DESCR, feature_names, filename 총 7개의 정보가 담겨있다.
하나씩 알아보도록 하자
가장 중요한 데이터는 iris_data 변수에 저장한 후, 데이터 크기를 확인해본다.
iris_data = iris.data
print(iris_data.shape)(150, 4) 처음 확인했던 대로 총 150개의 데이터가 각각 4개의 정보를 담고 있다.
예시로 하나의 데이터만 확인해보자
iris_data[0]0번 인덱스를 확인해보니 총 네개의 숫자가 나온다
순서대로 sepal length, sepal width, petal length, petal width를 나타낸다
우리는 꽃잎과 꽃받침의 길이를 사용해 세 가지 붓꽃 품종 중 어떤 것인지를 맞추는 것을 할려고 한다.
따라서 머신러닝 모델에게 꽃잎, 꽃받침의 길이와 폭 정보를 입력했을 때, 붓꽃의 품종을 출력하도록 학습시켜야 한다.
머신러닝 모델이 출력해야 하는 정답을 라벨(label) 또는 타겟(target)이라고 한다.
붓꽃 데이터에서 타겟 정보는 target으로 볼 수 있다.
iris_label = iris.target
print(iris_label.shape)
iris_labeliris 데이터의 target을 iris_label 변수에 저장했다.
총 150개의 데이터가 각 0,1,2의 값을 가진다. 이는 당연히 Setosa, Versicolour, Virginica의 값일 것이다. 각 값과 이름을 확인해보자
iris.target_namesSetosa, Versicolour, Virginica 순서 대로 담겨있다.
이 순서 그대로 Setosa = 0, Versicolour = 1, Virginica = 2이다
다른 변수들도 확인해보자
print(iris.DESCR)DESCR에는 데이터셋의 설명이 담겨있다.
iris.feature_namesfeature_names에는 4개의 특성에 대한 설명이 담겨져 있다
iris.filenamefilename은 데이터셋 전체 이름을 보여준다 iris.csv iris 데이터셋은 csv 파일임을 알 수 있다.
머신러닝 모델 학습시키기
데이터 준비가 다 됐으니 머신러닝 모델을 학습시킬 차례이다.
데이터 나누기
우선 모델을 학습시키기에 앞서 데이터들을 나눠보려고 한다.
pandas를 이용
pandas는 2차원 배열 데이터를 다루는데 가장 많이 쓰이는 도구로 표 데이터를 활용해서 데이터 분석을 하고, 대형 데이터의 여러 통계량을 다루는 것에도 최적화 되어있다.
더 자세한 정보는 이전에 포스팅을 참고해보자 python pandas
import pandas as pd
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
iris_dfDataFrame을 만들면서 data에는 iris_data를 넣어주고, 각 컬럼에는 feature_names로 이름을 붙여준다
정답 데이터도 함께 있으면 데이터를 다루기 더 편리하니 label컬럼을 추가해준다.
iris_df["label"] = iris.target
iris_dflabel 컬럼을 추가해 0~2의 값이 잘 들어갔다
여기서 4개의 특성(feature) 데이터들은 머신러닝이 풀어야하는 문제지이고, label 데이터는 답지이다.
보통 feature 데이터는 x, label or target 데이터는 y를 많이 사용한다.
feature, label, target과 같은 용어들은 기본 용어로 기억해둬야 한다.
머신러닝 모델을 학습시키기에 앞서 한가지 작업을 해줘야 한다. 바로 학습에 사용하는 training dataset과 모델의 성능을 평가하는데 사용하는 test dataset으로 나눠주는 작업이다.
150개의 데이터가 있지만 150개의 데이터를 모두 학습하고 평가하면 변별력이 없고, 학습된 모델의 성능을 제대로 평가할 수 없기 때문이다.
데이터셋을 분리하는 것은 scikit-learn이 제공하는 train_test_split 함수로 할 수 있다.
sklearn.model_selection패키지의 train_test_split을 활용하여 training dataset과 test dataset을 분리해본다
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=7)
print('x_train 개수 : ', len(x_train), ', x_test 개수 : ', len(x_test))train_test_split을 자세히 살펴보자
iris_data는 특성(feature)로, 모델이 품종을 맞추기 위해 입력받는 특징 데이터이다.iris_label은 label(or target)로 모델이 맞춰야 하는 정답값이다.test_size는 test dataset의 크기를 조절할 수 있다. 0.2는 전체의 20%를 테스트 데이터로 사용하겠다는 것을 말한다.random_state는train데이터와test데이터를 분리(split)하는데 적용되는 랜덤성을 결정한다
첫 번째와 두 번째 데이터 파라미터를 통해 학습용 데이터와 테스트용 데이터를 생성하고 각 4개의 feature 데이터만 있는 x, 정답 label 데이터만 있는 y를 얻을 수 있다.
x_train 데이터를 모델에 입력하고, 그 모델의 결과를 정답 y_train과 비교하며 학습을 시키고
x_test, y_test를 통해 학습결과를 테스트 해본다.
세 번째와 네 번째는 처음 상태의 데이터를 학습용과 테스트용으로 나눈다면 뒤의 20%가 테스트용 데이터셋으로 만들어지기 때문에 테스트용 데이터셋은 라벨이 2인 데이터로만 구성이된다. 그렇게 되면 학습이 제대로 되지 않기 때문에 랜덤으로 섞기 위해서 random_state를 사용한다.
컴퓨터에서 랜덤은 아무리 랜덤이라도 특정 로직에 따라 결정되는 랜덤이기 때문에 완벽한 랜덤이라고 할 수 없다. 그러한 랜덤을 조절할 수 있는 값이 바로 random_state 또는 random_seed로 이 값이 같으면 코드는 항상 같은 랜덤 결과를 나타낸다.
이제 만들어진 데이트셋을 확인해 보자
x_train.shape, y_train.shape
x_test.shape, y_test.shape총 150개의 데이터가 80%는 train 데이터셋에, 20%는 test 데이터셋에 잘 들어간 것을 알 수 있다.
y는
y_train, y_test처음 label과 다르게 0,1,2가 무작위로 섞여있는 것을 확인할 수 있다.
모델 학습
머신러닝은 크게 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning) 두 가지로 구분된다.
지도학습은 정답이 있는 문제에 대해 학습하는 것을 말하고, 반대로 학습은 정답이 없는 문제를 학습하는 것을 말한다.
우리가 진행중인 붓꽃 품종 문제는 label이라는 정답이 있기 때문에 지도학습이다.
지도학습은 다시 두 가지로 나눌 수 있는데, 분류(Classification)과 회귀(Regression)이다.
분류는 입력받은 데이터를 특정 카테고리 중 하나로 분류해내는 문제를, 회귀는 입력받은 데이터에 따라 특정 필드의 수치를 맞히는 문제를 말한다.
붓꽃 품종 문제는 featrue 데이터를 입력받으면 세 가지 품종 중 하나로 분류하는 분류문제이다.
회귀 문제는 수를 예측하는 문제라고 생각하면 된다. 예를 들어 날씨에 따른 아이스 커피 판매량을 예측하고 싶다면 구하고 싶은 데이터가 판매량 즉 숫자기 때문에 회귀문제이다.
쉽게 생각하면 분류는 추측하는 결과가 이름 혹은 문자라면 분류에 해당하고, 회귀는 예측하는 결과가 수라면 회귀에 해당한다.
그럼 정리하자면 붓꽃 품종 문제는 지도학습이며 분류문제라는 것을 알기 때문에 어떤 머신러닝 모델을 사용해야 할지 명확하게 알 수 있다
분류 모델은 다양하지만 처음엔 Decision Tree 모델을 사용해 보도록 한다. Decision Tree는 직관적이면서 간단하게 사용할 수 있어 분류 문제를 풀 때 가장 기본적으로 쓰이는 모델 중 하나이다. (참고 Decision Tree 설명 블로그 의사결정나무-ratsgo님의 블로그
Decision Tree는 데이터를 분리할 어떤 경계를 찾아 데이터를 체에 거르듯 한 단계씩 분류해나간다. 그렇게 데이터를 분류하는 모습이 나무를 뒤집어 놓은 것과 같은 모양이라 의사결정나무라고 불린다.
이 데이터를 분류하는 과정에서 엔트로피, 정보량, 지니불순도 등의 정보이론 개념이 포함되어있어 블로그나 구글을 통해 추가적인 학습을 하는 것이 필요하다.
Decision Tree는 sklearn.tree 패키지 안에 DecisionTreeClassifier라는 이름으로 내장되어 있다. 모델을 import하고 decision_tree라는 변수에 모델을 저장한다.
from sklearn.tree import DecisionTreeClassifier
decision_tree = DecisionTreeClassifier(random_state=32)
print(decision_tree._estimator_type)이제 모델을 학습시킬 차례이다. 다행이도 scikit-learn이 모델 학습을 편리하게 할 수 있도록 API 구조를 설계해 아주 간단하게 학습시킬 수 있다.
decision_tree.fit(x_train, y_train)위의 단 한줄이 데이터 모델을 학습시키는 코드이다.
메서드의 이름은 fit으로 training dataset에 맞게 모델을 fitting 시키는 것과 같다.
모델 평가하기
이제 학습이 완료되었으니 test 데이터로 예측할 차례이다.
y_pred = decision_tree.predict(x_test)
y_predx_test 데이터에는 정답인 label이 없고 feature 데이터만 존재했다. 때문에 학습이 완료된 decision_tree 모델에 x_test 데이터로 predict를 실행하면 모델이 예측한 y_pred를 얻게 된다.
그럼 이번엔 실제 정답인 y_test와 비교해 얼마나 맞았는지 확인해보자
예측한 결과에 대한 수치를 편하게 확인하기 위해서 scikit-learn에서 성능 평가에 대한 함수들이 모여있는 sklearn.metrics패키지를 사용하면 된다.
성능을 평가하는 방법에도 다양한 척도가 있지만 정확도(Accuracy)를 간단히 확인해보자
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
accuracy약 0.9라는 수치가 나왔다 이는 90%의 정확도를 보인다는 뜻이다
정확도는 전체 개수 중 맞은 것의 개수의 수치를 나타낸다.
정리
지금까지 했던 과정들을 한 번에 정리해보자
# 1. 모듈 import
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
# 2. 데이터 준비
iris = load_iris()
iris_data = iris.data
iris_label = iris.target
# 3. train, test 데이터 분리
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=7)
# 4. 모델 학습 및 예측
decision_tree = DecisionTreeClassifier(random_state=32)
decision_tree.fit(x_train, y_train)
y_pred = decision_tree.predict(x_test)
print(classification_report(y_test, y_pred))지금까지 했던 흐름을 잘 기억해둔다.
다른 모델 사용하기
다른 모델을 사용하기 위해서 코드를 전부 수정하는 것이 아니라 앞에 4번 모델 학습 및 예측 부분의 모델만 수정해주면 된다.
Random Forest
Decision Tree를 여러 개 모아놓은 Random Forest
앞에서 Random Forest는 Decision Tree의 단점을 보완하기 위해 만든 모델이라고 설명했다. 이러한 기법을 앙상블(Ensemble) 기법이라고 한다. 단일 모델을 여러 개 사용하는 방법을 취함으로써 모델 한 개만 사용할 때의 단점을 집단지성으로 극복하는 개념이다
Forest는 말 그대로 나무가 모여있는 숲으로 수많은 Decison Tree가 모여서 생성된다
예를 들어 건강 위험도를 예측하려면 성별, 키, 몸무게, 세 가지 요소보다 더 많은 요소를 고려해야 한다.
첫 째로 거주지역, 운동량, 기초 대사량, 근육량 등 수많은 요소들이 건강에 영향을 미치고,
두 번째 의사결정트리를 다른 요소들의 조합으로 생성한다. 성별, 키, 흡연여부, 근육량 등
세 번째 키, 거주지역, 운동량으로 세 번째 트리를 만들 수 있다. (통계적으로 독립 조건을 만들어 주기 위해서)
이렇게 여러 가지 의사 결정 트리로 숲을 만들었는데, 의견 통합이 되지 않는다면??
Forest는 다수결의 원칙을 따라 결정을 한다. 예로 1,000개의 의사 결정 트리 중 678개의 트리가 건강 위험도가 높다고 의견을 내고, 나머지가 낮다고 의견을 냈을 때, 숲은 그 의견들을 통합하여 건강 위험도가 높다고 한다.
데이터 사이언스에서 이렇게 의견을 통합하거나 여러가지 결과를 합치는 방식을 앙상블 기법(Ensemble method)이라고 한다.
마지막의로 Random Forest의 Random은 무엇이 Random일까?
Random Forest는 의사 결정 트리를 만드는데 있어 사용되는 요소들(나이, 성별, 키 등)을 무작위적으로 선정한다. 예로 건강 위험도를 30개의 요소로 설명할 수 있다면, 의사 결정 트리의 한 단계를 생성하면서 모든 요소를 고려하는 것이 아니라 30개 중 무작위로 일부만 선택하여, 그 선택된 일부 중 가장 건강 위험도를 알맞게 예측하는 한 가지 요소가 의사 결정 트리의 한 단계가 된다.
Random Forest가 완성되는 과정
- 건강 위험도를 예측하기 위해서 많은 요소 고려 성별, 키, 나이, 몸무게, 지역, 운동량, 흡연 여부, 음주 여부, 혈당, 근육량, 기초 대사량 등 많은 요소 필요
- Feature가 30개라면 30개의 Feature를 기반으로 하나의 결정 트리를 만든다면 트리의 가지가 많아질 것이고, 이는 오버피팅의 결과를 야기한다.
- 30개의 feature 중 랜덤으로 5개의 feature만 선택해서 하나의 결정 트리 생성
- 계속 반복하여 여러 개의 결정 트리 생성
- 여러 결정 트리들이 내린 예측 값들 중 가장 많이 나온 값을 최종 예측값으로 지정
- 의견을 통합하거나 여러 가지 결과를 합치는 방식을 앙상블(Ensemble)이라고 함
- 하나의 거대한 (깊이가 깊은) 결정 트리를 만드는 것이 아니라 여러 개의 작은 결정 트리를 만드는 것
- 분류 : 여러 개의 작은 결정 트리가 예측한 값들 중 가장 많은 값, 회귀 : 평균
Random Forest는 상위 모델들이 예측하는 편향된 결과보다, 다양한 모델들의 결과를 반영함으로서 더 다양한 데이터에 대한 의사 결정을 내릴 수 있게 한다.
Random Forest는 sklearn.ensemble 패키지 내에 들어있다
from sklearn.ensemble import RandomForestClassifier
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=21)
random_forest = RandomForestClassifier(random_state=32)
random_forest.fit(x_train, y_train)
y_pred = random_forest.predict(x_test)
print(classification_report(y_test, y_pred))Support Vector Machine(SVM)
SVM은 Support Vector와 Hyperplane(초평면)을 이용해서 분류를 수행하게 되는 대표적인 선형 분류 알고리즘이다.

2차원 공간에서, 즉 데이터에 2개의 클래스만 존재할 때
- Decision Boundary(결정 경계) : 두 개의 클래스를 구분해주는 선
- Support Vector : Decision Boundary에 가까이 있는 데이터
- Margin : Decision Boundary와 Support Vector 사이의 거리

Margin이 넓을 수록 새로운 데이터를 잘 구분할 수 있다. (Margin 최대화 -> robustness 최대화)
- Kernel Trick : 저차원의 공간을 고차원의 공간으로 매핑해주는 작업. 데이터의 분포가 Linearly separable 하지 않을 경우 데이터를 고차원으로 이동시켜 Linearly separable하도록 만든다.
- cost : Decision Boundary와 Margin의 간격 결정. cost가 높으면 Margin이 좁아지고 train erro가 작아진다. 그러나 새로운 데이터에서는 분류를 잘 할 수 있다. cost가 낮으면 Margin이 넓어지고, train error는 커진다.
- γ : 한 train data당 영향을 미치는 범위 결정. γ가 커지면 영향을 미치는 범위가 줄어들고, Decision Boundary에 가까이 있는 데이터만이 선의 굴곡에 영향을 준다. 따라서 Decision Boundary는 구불구불하게 그어진다. (오버피팅 초래 가능) 작아지면 데이터가 영향을 미치는 범위가 커지고, 대부분의 데이터가 Decision Boundary에 영향을 준다. 따라서 Decision Boundary는 직선에 가까워진다.
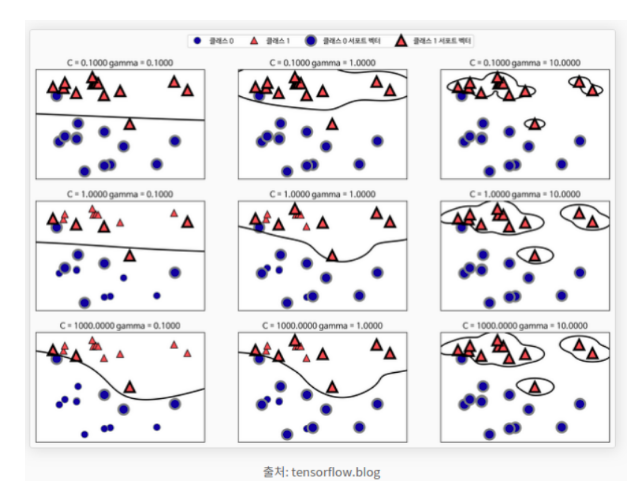
많은 선형 분류 모델은 대부분 이진 분류 모델이다. 하지만 이진 분류 알고리즘을 일대다(one-vs.-rest or one-vs.-all)방법을 사용해 다중 클래스 분류 알고리즘으로 사용할 수 있다. 일대다 방식은 각 클래스를 다른 모든 클래스와 구분하도록 이진 분류 모델을 학습시킨다. 클래스의 수만큼 이진 분류 모델이 만들어지고 예측할 때는 만들어진 모든 이진 분류기가 작동하여 가장 높은 점수를 내는 분류기의 클래스를 예측값으로 선택한다. 그리고 SVM 모델은 다음과 같이 사용한다.
from sklearn import svm
svm_model = svm.SVC()
print(svm_model._estimator_type)
svm_model.fit(x_train, y_train)
y_pred = svm_model.predict(x_test)
print(classification_report(y_test, y_pred))Stochastic Gradient Descent Classifier (SGDClassifier)
SGD (Stochastic Gradient Descent)는 배치 키그가 1인 경사하강법 알고리즘이다. 확률적 경사하강법은 데이터 세트에서 무작위로 균일하게 선택한 하나의 예를 의존하여 각 단계의 예측 경사를 계산한다.
<최소값 찾는 과정>

배치란 경사하강법에서 단일 반복에서 기울기를 계산하는데 사용하는 예(data)의 총 개수이다. Gradient Descent 에서 배치는 전체 데이터 셋이라고 가정한다.
대규모의 작업에서는 데이터 셋에 수십억, 수천억 개의 data가 포함될 경우가 있다. 또한 대규모의 데이터 셋에는 엄청나게 많은 특성이 포함되어 있어 배치가 거대해질 수 있다. 배치가 너무 커지면 단일 반복으로도 계산하는데 오랜 시간이 걸릴 수 있다.
무작위로 샘플링 된 data가 포함된 대량의 데이터 셋에는 중복 데이터가 포함되어 있을 수 있다. (배치가 커지면 중복 가능성도 같이 커진다)
훨씬 적은 계산으로 적절한 기울기를 얻을 수 있다면?
데이터 셋에서 data를 무작위로 선택하면 훨씬 적은 데이터 셋으로 중요한 평균값을 추정할 수 있다. (노이즈가 있을 수도 있다) 확률적 경사하강법(SGD)은 이 아이디어를 더욱 확장한 것으로, 반복당 하나의 data(배치 크기 1)만을 사용한다
확률적(Stochastic)이라는 용어는 각 배치를 포함하는 하나의 예가 무작위로 선택된다는 것을 의미한다.
하지만 반복이 충분하면 SGD가 효과는 있지만 노이즈가 매우 심하고, 확률적 경사하강법의 여러 변형 함수의 최저점에 가까운 점을 찾을 가능성이 높지만 100%는 아니다 (최저점을 찾지 못할 확률이 높다)
이를 미니 배치 확률적 경사하강법(미니 배치 SGD)를 사용한다 전체 배치 반복과 SGD의 반반
미니 배치는 일반적으로 무작위로 선택한 10개에서 1,000개 사이의 예로 구성된다. 미니 배치 SGD는 SGD의 노이즈를 줄이면서 전체 배치보다는 효율적이다.
SGD Classifier 모델 사용 예시
from sklearn.linear_model import SGDClassifier
sgd_model = SGDClassifier()
print(sgd_model._estimator_type)
sgd_model.fit(x_train, y_train)
y_pred = sgd_model.predict(x_test)
print(classification_report(y_test, y_pred))Logistic Regression
Logistic Regression 모델에 대해서 알아본다. 가장 널리 알려진 선형 분류 알고리즘. 소프트맥스(softmax)함수를 사용한 다중 클래스 분류 알고리즘이며, 다중 클래스 분류를 위한 로지스틱 회귀를 소프트맥스 회귀(Softmax Regression)라고도 한다. 이름은 회귀지만 실제로는 분류를 수행한다.
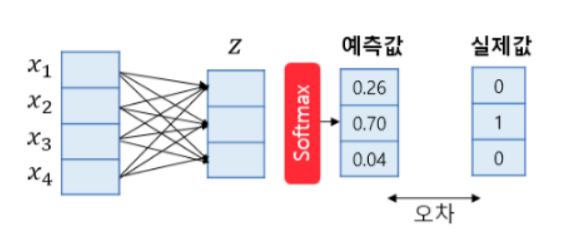
소프트맥스 함수 : 클래스가 n개일 때, n차원의 벡터가 각 클래스가 정답일 확률을 표현하도록 정규화를 해주는 함수. 위 그림은 4차원의 벡터를 입력으로 받아 3개의 클래스를 예측하는 경우의 소프트맥스 회귀의 동작 과정을 보여준다. 3개의 클래스 중 1개의 클래스를 예측해야 하므로 소프트맥스 회귀의 출력은 3차원의 벡터고, 각 벡터의 차원은 특정 클래스일 확률이다. 오차와 실제값의 차이를 줄이는 과정에서 가중치와 편향이 학습된다.
Logistic Regression 모델 사용 예시
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression()
print(logistic_model._estimator_type)
logistic_model.fit(x_train, y_train)
y_pred = logistic_model.predict(x_test)
print(classification_report(y_test, y_pred))지금까지 다양한 모델을 간단하게 실습해보았다. 실제로 각 모델을 제대로 알기 위해서는 수학적, 통계적 배경을 보고 찾아볼 필요성이 있다.
모델 평가하기
머신러닝에는 모델을 학습시키는 것뿐만 아니라 그 성능을 정확히 평가하고 개선하는 것이 매우 중요하다. 이를 위해 정확도(accuracy)라는 척도를 통해 모델의 성능을 확인할 수 있다.
또한 모델의 성능을 평가하는 것이 정확도 뿐만 아니라 다른 척도들이 있다. 이번에는 다양한 척도들을 배워보자
정확도
정확도에도 단점은 존재한다. 그 단점을 코드를 보며 알아보자
앞의 붓꽃 데이터처럼 손글씨 데이터도 쉽게 가져올 수 있다.
from sklearn.datasets import load_digits
digits = load_digits()
digits.keys()digits라는 변수에 손글씨 데이터를 저장했다. 그 내부를 살펴보면 iris처럼 정보들이 담겨 있다.
가장 중요한 data를 먼저 확인해본다.
digits_data = digits.data
digits_data.shape데이터는 총 1,797개가 있고, 각 데이터는 64개의 숫자로 이루어져 있다. 한 개의 데이터를 샘플로 확인해보자
digits_data[0]64개의 숫자로 이루어진 배열(array)이 출력되었다.
손글씨 데이터는 이미지 데이터로 각 숫자는 픽셀값을 의미한다. 길이 64의 숫자배열은 (8x8) 크기의 이미지를 일렬로 펼쳐놓은 것이다.
이미지를 확인하기 위해서 matplotlib 라이브러리가 필요하다
가장 중요한 것은 일렬로 펴진 배열을 (8,8)로 변경해주는 것이 중요하다
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(digits.data[0].reshape(8,8), cmap='gray')
plt.axis('off')
plt.show()0처럼 생긴 이미지가 출력된다
여러 개의 이미지를 한 번에 확인해보자
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(digits.data[i].reshape(8,8), cmap='gray')
plt.axis('off')
plt.show()0~9까지의 숫자가 나오는 것을 확인할 수 있다.
이번엔 target 데이터를 확인하자
digits_label = digits.target
print(digits_label.shape)
digits_label[:20]이 손글씨 이미지 데이터를 가지고 이미지 데이터가 입력되었을 때 그 이미지가 숫자 몇을 나타내는 이미지인지 맞추는 분류 모델을 학습시키면 된다. 다만 정확도의 단점을 확인하기 위해 약간 변형을 해보자
숫자 10개를 모두 분류하는 것이 아니라, 해당 데이터가 3인지 아닌지 맞추는 문제로 바꿔, 입력된 데이터가 3이라면 3을, 다른 숫자라면 0을 출력하도록 하는 모델을 생각해보자
target인 digits_label을 변형시킨다.
new_label = [3 if i == 3 else 0 for i in digits_label]
new_label[:20]그럼 이 데이터를 Decision Tree 학습을 시켜보자
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
x_train, x_test, y_train, y_test = train_test_split(digits_data, new_label, test_size=0.3, random_state=43)
decision_tree = DecisionTreeClassifier(random_state=43)
decision_tree.fit(x_train, y_train)
y_pred = decision_tree.predict(x_test)
print(accuracy_score(y_test, y_pred))약 97%라는 높은 성능이 나왔다.
여기에 바로 함정이 있다. 우리는 10개의 숫자 중 숫자 3에만 집중을 해서 3이면 3이고, 3이 아니면 0으로 변형을 해보았다
여기서 문제가 label이 0은 매우 많고 3은 적은 불균형 데이터가 된 것이다. (9개 숫자는 0, 3만 3) 이는 모델이 학습하지 않고 전부 0으로만 선택해도 정확도가 90%가량이 나오게 되는 것이다.
fake_pred = [0] * len(y_pred)
accuracy = accuracy_score(y_test, fake_pred)
accuracy모델을 사용하지 않고 답을 0으로만 했음에도 정확도가 92.4%가 나온다
이러한 문제는 불균형한 데이터(Unbalanced data)에서 자주 발생할 수 있다.
정확도는 정답의 분포에 따라 모델의 성능을 잘 평가하지 못하는 척도가 될 수 있다.
따라서 분류문제의 경우는 정확도 외에 다양한 평가 척도를 사용한다.
정답과 오답의 종류
위의 정확도는 전체 데이터 중 맞은 데이터에만 신경을 쓰는 척도이다. 하지만 세상에는 양성 데이터가 얼마나 많이 맞는가도 중요하지만, 음성 데이터를 얼마나 안 틀렸냐가 중요한 경우도 있다.
예를 들어 코로나의 경우 음성을 양성으로 오진하는 경우는 그나마 괜찮지만, 양성인데 음성이라고 오진을 하는 경우는 치명적이다. 이와 같이 오진이라도 양성을 잡지 못한 오진과, 음성을 잡지 못한 오진은 그 중요도가 다르다.
이렇게 정답과 오답을 구분하여 표현하는 방법을 오차 행렬(Confusion Matrix)라고 한다.
오차행렬 설명 What is Confusion Matrix and Advanced Classification Metrics?
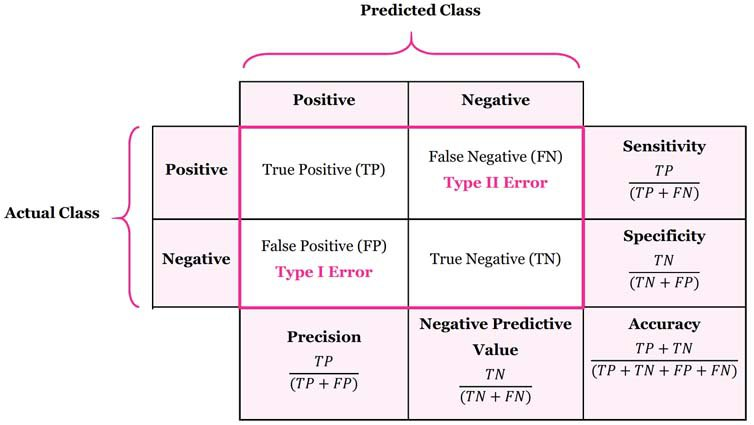
위 그림의 각 행은 실제 클래스(Actual Class)를 나타낸다.
코로나를 예로 들면 Actual Class가 Positive라면 코로나 양성을 뜻하고, 반대로 Negative라면 음성을 의미한다.
반면 각 열은 예측된 클래스(Predicted Class)이다 Predicted Class가 Positive라면 진단 결과가 양성, Negative라면 진단 결과가 음성임을 의미한다.
- TP(True Positive) : 양성이 양성으로 올바르게 식별 (참 양성)
- FN(False Negative) : 양성이 음성으로 잘 못 예측 (거짓 음성)
- FP(False positive) : 음성을 양성으로 잘 못 예측 (거짓 양성)
- TN(True Negative) : 음성을 음성으로 올바르게 식별 (참 음성)
TP, FN, FP, TN의 수치로 계산되는 성능 지표 중 대표적으로 사용되는 것은 정밀도(Precision), 재현율(Recall or Sensitivity), F1 점수(f1 score)이다.
Recall은 Sensitivity라고 표시된 지표와 같다. Sensitivity 보다는 Recall이라는 용어가 더 보편적으로 사용된다.
Precision, Recall, F1 score, Accuracy의 각각의 수식은 다음과 같다.
Precision, Recall의 분자는 둘다 TP(참)로 이 값이 클수록 좋고, 분모에는 각각 FP, FN(거짓)이 있어 이 값은 작을 수록 좋다.
TP는 높고 FP, FN은 낮을수록 좋기 때문에 Precision과 Recall 값이 클수록 좋다
둘의 차이점은 FP, FN으로 Precision은 FP가 낮을수록 커지기 때문에 Precision이 높아지려면 FP의 경우 음성인데 양성으로 판단하는 경우(음성을 놓치면 안됨)가 적어야 한다. Recall은 FN이 낮을수록 커지기에 Recall이 높아지려면 FN 양성인데 음성으로 판단하는 경우(양성을 놓치면 안됨)가 적어야 한다.
F1 score는 Recall과 Precision의 조화평균이고, Accuracy는 앞에서 배웠듯이 전체 데이터 중 올바르게 판단한 데이터 개수의 비율이다.
이번엔 scikit-learn으로 지표들을 확인해보자
오차 행렬은 sklearn.metrics 패키지 내의 confusion_matrix로 확인할 수 있다.
손글씨 결과를 가지고 확인해본다.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred)결과 값은 위에서 본 그림과 같이 왼쪽 위부터 순서대로 TP, FN, FP, TN의 개수를 나타낸다. 특히 손글씨 문제에서 0은 Positive 역할을 3은 Negative 역할을 한다.
모든 숫자를 0으로 예측한 fake_pred의 경우는
confusion_matrix(y_test, fake_pred)모든 데이터를 0 Positive로 예측했고 Negative로 예측한 것은 없기 때문에 FN, TN은 0이다.
Precision, Recall, F1 score의 값을 확인해보자
sklearn.metrics의 classification_report를 활용하면 각 지표를 한번에 확인할 수 있다.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))0은 개수가 333개로 많기 때문에 precision, recall 모두 0.98로 높은 값이 나왔다. 하지만 3은 27개 뿐이기 때문에 0.8로 낮은 값이 나왔다
fake_pred의 값은?
print(classification_report(y_test, fake_pred, zero_division=0))0에 대한 precision, recall은 0.92, 1로 매우 높지만 3에 대한 값은 둘 다 0이다. 0은 잘 잡아내지만 3은 단 하나도 맞추지 못했다.
다시한번 정확도를 확인해보자
accuracy_score(y_test, y_pred), accuracy_score(y_test, fake_pred)y_pred와 fake_pred 모두 0.97, 0.92로 큰 차이가 없지만 확실하게 알 수 있다. 모델의 성능은 정확도 만으로 평가하면 안된다는 것을
특히 label이 불균형하게 분포되어 있는 데이터를 다룰 때는 더 조심해야 한다.
Precision과 Recall이 각각 언제 필요한지를 알고 상황에 맞는 성능지표로 모델을 평가할 줄 알아야 한다.
